







本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本文章来自腾讯云 作者:Python进阶者
想要学习Python?有问题得不到第一时间解决?来看看这里“1039649593”满足你的需求,资料都已经上传至文件中,可以自行下载!还有海量最新2020python学习资料。
点击查看
1 前言
前几天小编发布了Python爬虫:爬取西刺代理数据,讲解处理反爬措施(上篇),木有赶上车的小伙伴,可以戳进去看看。今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下。
2 首页分析及提取
首先进入网站主页,如下图所示。
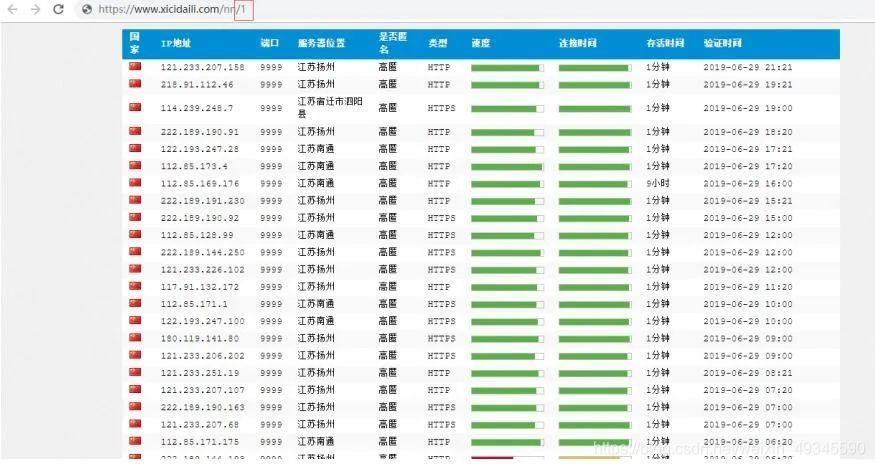
简单分析下页面,其中后面的 1 是页码的意思,分析后发现每一页有100 多条数据,然后网站底部总共有 2700+页 的链接,所以总共ip 代理加起来超过 27 万条数据,但是后面的数据大部分都是很多年前的数据了,比如 2012 年,大概就前 5000 多条是最近一个月的,所以决定爬取前面100 页。通 过网站 url 分析,可以知道这 100 页的 url 为:

规律显而易见,在程序中,我们使用一个 for 循环即可完整这个操作:

其中 scrapy 函数是爬取的主要逻辑,对应的代码为:
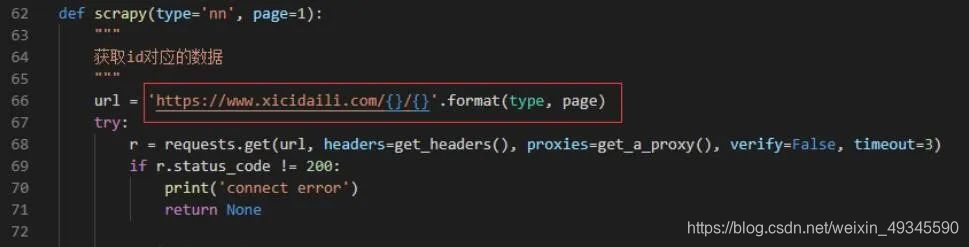
通过这个方式,我们可以得到每一页的数据。
3 网页元素分析及提取
接下来就是对页面内的元素进行分析,提取其中的代理信息。
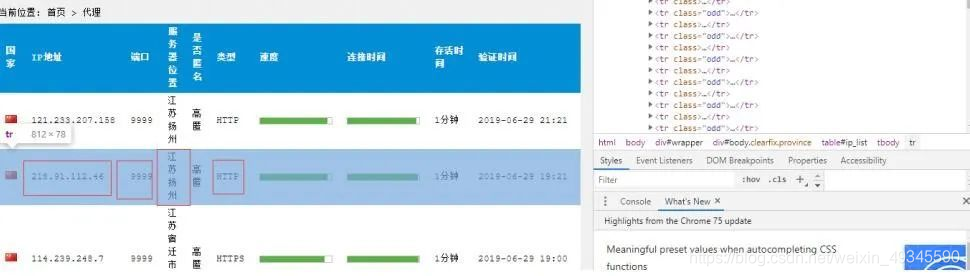

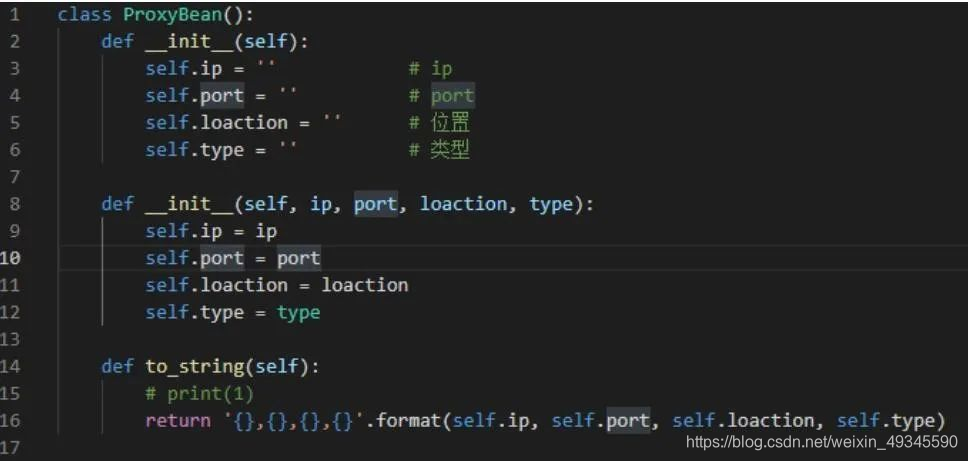

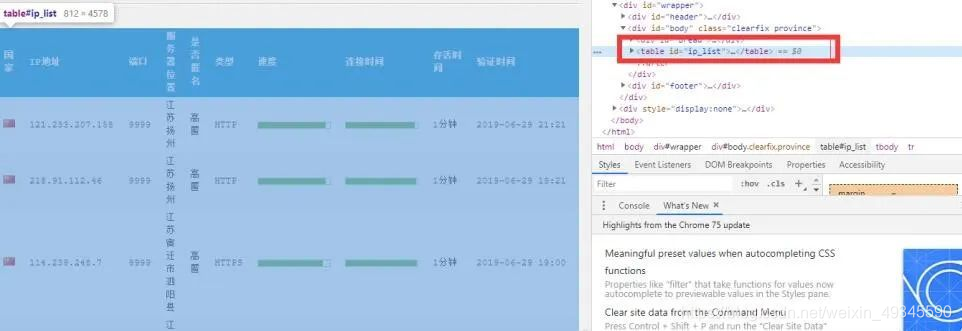
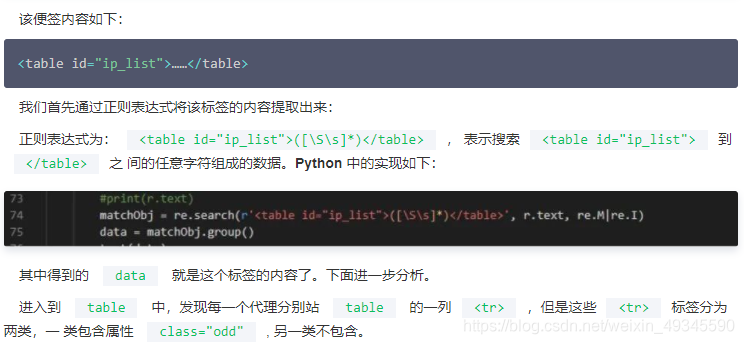
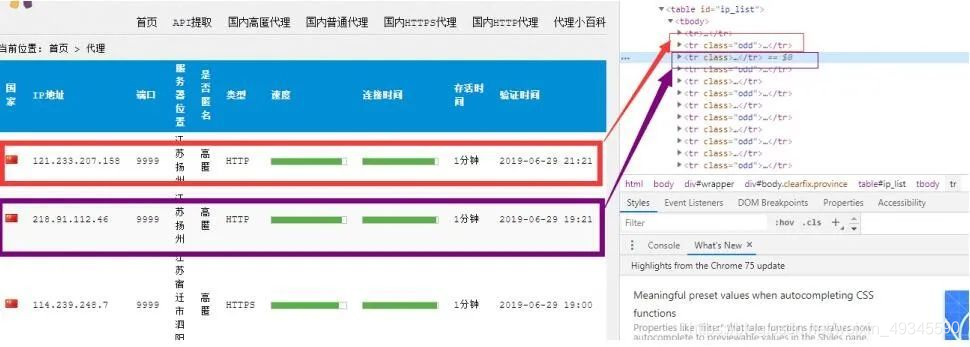

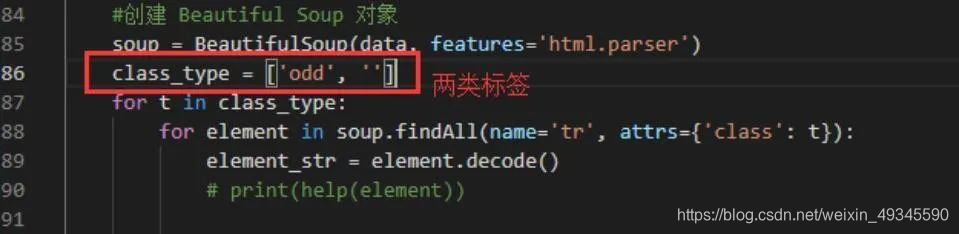
通过这种方式,就能获取到每一个列的列表了。
接下来就是从每个列中获取 ip、端口、位置、类型等信息了。进一步分析页面:
1、IP 字段:
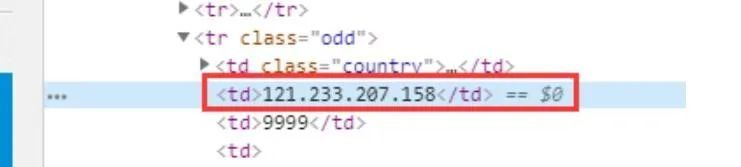
我们使用正则表达式对 IP 进行解析,IP 正则如下:
** (2[0-5]{2}|[0-1]?\d{1,2})(.(2[0-5]{2}|[0-1]?\d{1,2})){3}**

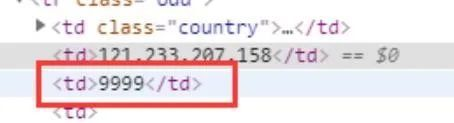
2、 端口字段


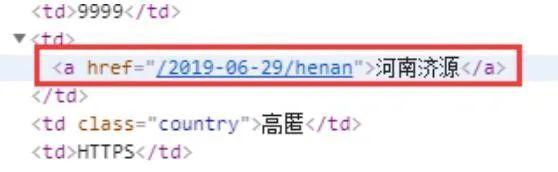
3、 位置字段
位置字段如下:


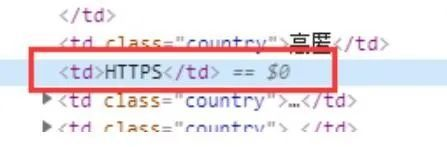
4、类型字段
类型字段如下:


数据全部获取完之后,将其保存到文件中即可:

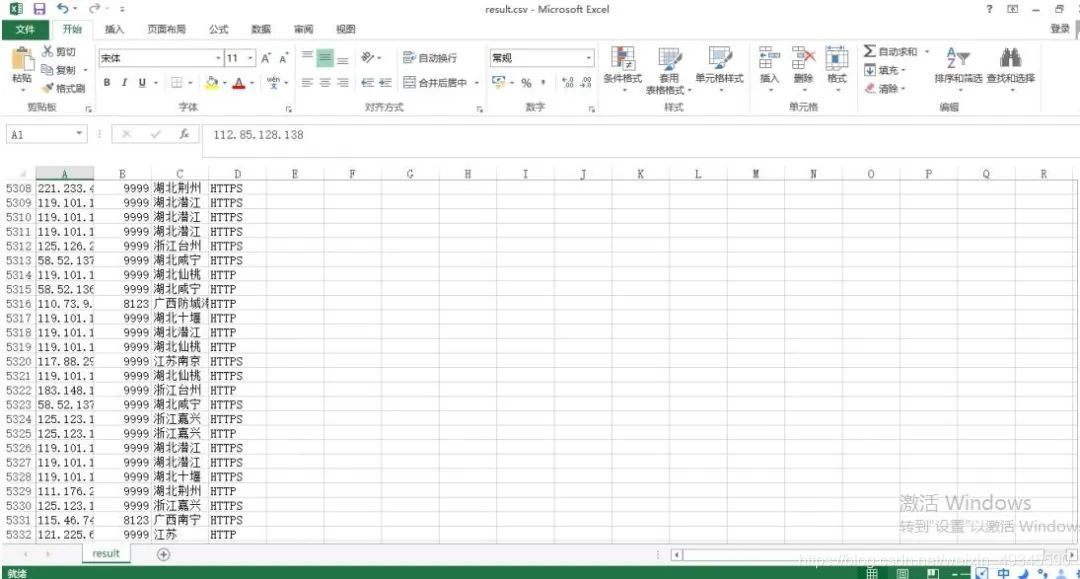
最后爬取的数据集如下图所示:















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









