






本文转自:Coggle数据科学
随着大规模语言模型(LLM)在性能、成本和应用前景上的快速发展,越来越多的团队开始探索如何自主训练LLM模型。然而,是否从零开始训练一个LLM,并非每个组织都适合。本文将根据不同的需求与资源,帮助你梳理如何在构建AI算法应用时做出合适的决策。
训练LLM的三种选择
https://wandb.ai/site/articles/training-llms/
在构建AI算法应用时,首先需要决定是使用现有的商用API,还是开源模型,或者选择完全自主训练一个LLM。每种选择有其独特的优势与劣势。
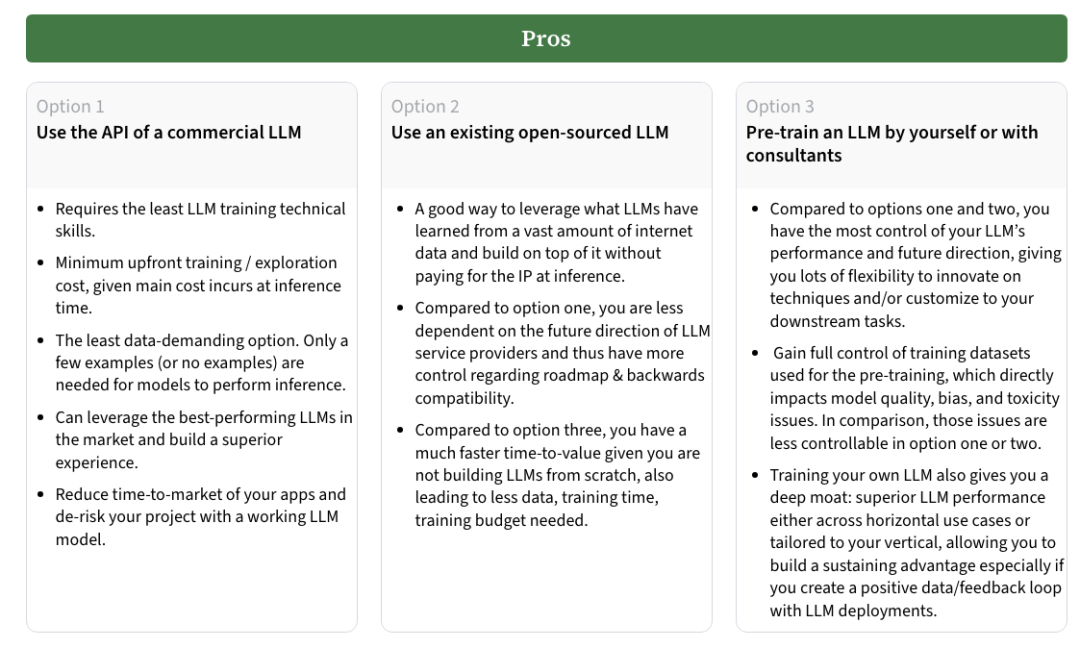
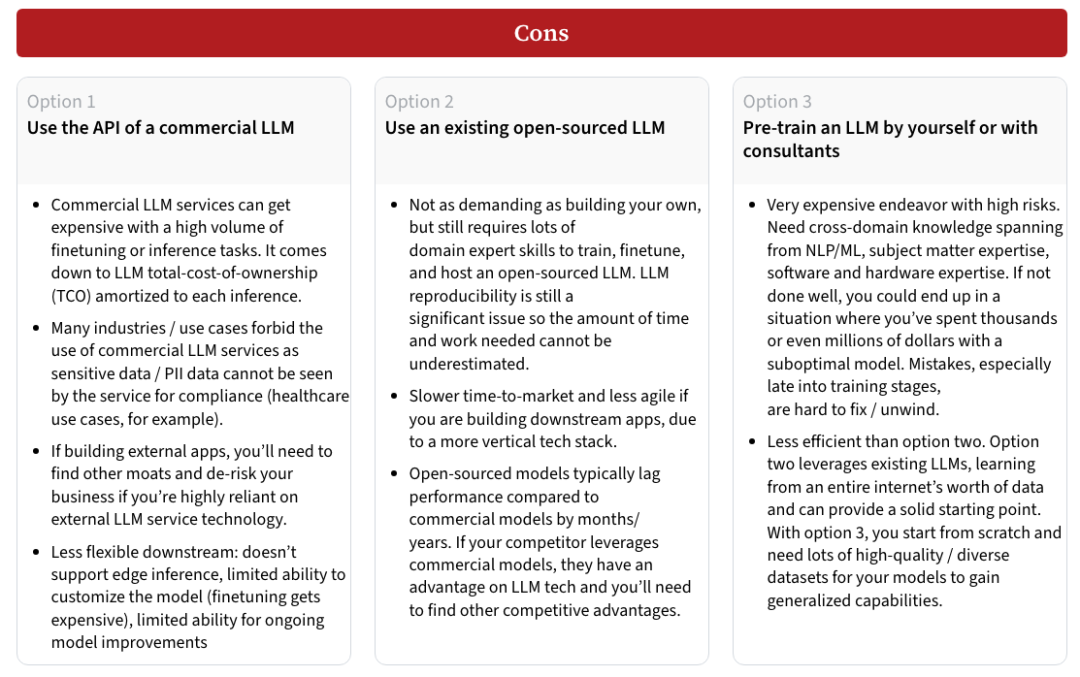
选项一:使用商用LLM API
这种方法最适合缺乏深厚技术背景的团队,或者希望尽快构建应用的组织。商用API的优点在于,无需进行繁琐的模型训练,团队可以直接使用现成的、高性能的LLM服务来执行推理任务。它还允许使用最先进的LLM技术,节省了大量的开发时间与成本。通过API,你只需为推理计算付费,且不需要处理数据集和模型训练过程中的复杂性。
然而,这种方法也有明显的缺点。首先,成本问题是一个关键考量,高频次的推理任务或微调可能导致不小的费用。其次,数据隐私和合规性也是商用API的限制之一,某些行业(如医疗健康、金融等)可能无法将敏感数据上传至外部服务。此外,商用API的定制性较差,模型微调的空间有限,如果需求有所变化,灵活性较低。
选项二:使用开源LLM
与商用API相比,开源LLM提供了更多的定制和控制权。你可以基于开源模型进行微调,或者在此基础上继续进行预训练。这种方法适合有一定技术实力的团队,尤其是当项目的数据隐私要求较高时。使用开源模型,你可以完全控制训练数据和模型的演化方向,避免了商用API服务带来的依赖风险。
然而,开源LLM的性能通常落后于商用模型,有时需要几个月甚至更长时间才能赶上最新的商业技术。训练和微调开源模型也需要投入较大的计算资源与专业知识,因此时间和资源的成本不可忽视。
选项三:完全自主训练LLM
当组织拥有强大的技术团队并且预算充足时,完全从零开始训练一个LLM可以提供最大的灵活性。自主训练不仅可以让你定制模型架构(如选择不同的tokenizer、调整模型维度、头数、层数等),还可以完全控制训练数据,以最大限度地减少模型偏差和毒性问题。这种方法适合那些将LLM作为核心技术和竞争优势的公司,尤其是在数据和算法方面有显著创新的情况下。
但与此同时,完全自主训练LLM也是最昂贵且风险较高的选择。模型训练需要大量的计算资源和跨领域的技术能力,若不慎,可能导致训练失败,尤其是在训练的后期,错误难以修正。而且,与开源模型相比,完全从头开始训练需要更为庞大的高质量、多样化的数据集,否则难以获得具备广泛能力的模型。
规模法则(Scaling Laws)
https://wandb.ai/site/articles/training-llms/the-scaling-laws/
LLM规模的历史演变
自2020年OpenAI首次提出LLM规模法则以来,关于如何提高模型性能的观点经历了显著的变化。OpenAI的研究表明,增加模型的规模比增加数据量更为重要。这一理论在一定时间内是成立的,尤其是在模型训练初期。然而,随着研究的深入,尤其是2022年DeepMind提出的新见解,关于模型规模和数据规模的关系发生了根本性的转变。
DeepMind提出,之前的LLM模型训练还远远不够,它们的数据量和计算资源未能达到最佳水平。具体来说,现有的LLM模型并没有在足够的数据上进行充分的训练。这一观点通过DeepMind提出的模型——Chinchilla得到了验证。Chinchilla的规模只有Gopher模型的四分之一,但它的训练数据量却是Gopher的4.6倍。在这种缩小模型规模的情况下,Chinchilla却取得了更好的性能,超过了Gopher和其他同类模型。
新的规模法则:模型大小与数据量的平衡
基于Chinchilla的实验结果,DeepMind提出了一个新的规模法则:模型大小和训练数据的大小应该按相同的比例增加,才能获得最佳的模型表现。如果你的计算资源增加了10倍,你应该将模型的大小增加3.1倍,并且数据量也要增加3.1倍;如果计算资源增加了100倍,模型和数据的大小都应当增加10倍。这种方式能够更好地平衡计算资源、模型复杂度和训练数据量,从而实现更优的训练效果。
简而言之,当前的最佳实践建议,在选择训练数据集时,首先要根据数据的大小来确定最适合的模型规模。DeepMind称为Chinchilla-Optimal模型的训练方法,是根据训练数据量来优化模型的大小。对于数据规模和模型规模的组合,最佳做法是基于训练计算预算和推理延迟需求来做出决策。
过小或过大的模型:何时调整?
在规模法则中,存在着一个最优点,即模型的大小和训练数据的大小之间的最佳平衡。当模型的大小太小(即处于曲线的左侧)时,增加模型的规模并减少数据量的需求是有益的。而当模型太大(处于曲线的右侧)时,减少模型的规模并增加数据量反而会带来更好的效果。最佳的模型通常位于曲线的最低点——即Chinchilla-Optimal点。
在实际训练过程中,你可能会面临以下几种情形:
模型过小:如果模型规模过小,而你有充足的训练数据,那么扩展模型的规模并且增加数据量,会提升性能。
模型过大:如果模型规模过大,且数据量相对不足,则缩小模型规模并增加数据量可能会带来更好的性能提升。
训练FLOPs和训练tokens的最佳配置
DeepMind的研究还提供了一些数据,展示了不同模型规模下,训练所需的计算量(FLOPs)和训练tokens的最优配置。这些数据为开发者提供了一个参考框架,帮助他们根据实际计算资源和数据集的规模,选择最适合的模型。
通过这些数据,你可以更清晰地理解,不同大小的模型在计算资源与训练数据的需求之间的平衡。训练FLOPs(每次操作所需的浮点运算数)与训练tokens(经过token化处理后的训练数据量)之间的关系,能够帮助你更好地预测训练的需求,合理分配计算资源。
如何应用这些Scaling Laws到训练中?
理解了这些理论后,如何在实际训练中应用这些Scaling Laws呢?以下是几个关键步骤:
选择合适的数据集:首先需要明确你的应用场景和数据集。如果数据集很小,可能不适合训练一个大规模的模型;如果数据集庞大,可以考虑训练更大规模的模型,以充分利用数据的潜力。
确定模型规模:根据数据集的大小和计算预算,使用Chinchilla-Optimal方法来决定模型的规模。确保你的模型规模与数据量之间保持一致,避免过度或不足的训练。
计算资源预算:在决定模型规模和数据量之后,你需要确保有足够的计算资源来支持训练过程。这涉及到计算能力的选择——从硬件设备(如TPU或GPU)到实际训练过程中的分布式计算能力。
推理延迟的考虑:如果你的应用需要低延迟推理,模型的大小与推理时间之间的关系也是需要考虑的。通常,大模型的推理速度较慢,因此可能需要对模型进行优化或采用更小的模型。
持续监控与调优:训练过程中,需要实时监控模型的性能,确保在训练的各个阶段都保持最优的计算资源和数据规模配置。如果发现性能没有预期的提升,可以调整模型的规模或增加数据量进行优化。
高效使用硬件资源
https://wandb.ai/site/articles/training-llms/hardware/
数据并行(Data Parallelism)
数据并行是处理无法装入单一计算节点的数据集时最常见的方式。具体来说,数据并行将训练数据划分为多个数据分片(shards),并将这些分片分配到不同的计算节点上。每个节点在其本地数据上训练一个子模型,然后与其他节点通信,定期合并它们的结果,从而获得全局模型。
数据并行的参数更新可以是同步的或异步的。同步数据并行中,各个节点会在每个步骤后同步梯度,并将更新后的模型参数发送回所有节点。而异步数据并行则允许各个节点在不同步的情况下更新模型,通常可以加速训练,但也可能引入更多的不一致性,导致模型收敛较慢。
数据并行的优点在于它提高了计算效率,并且相对容易实现。然而,缺点在于反向传播时,需要将整个梯度传递给所有其他GPU,这会导致较大的内存开销。同时,模型和优化器的复制会占用较多的内存,降低内存效率。
张量并行(Tensor Parallelism)
张量并行是将大模型的张量运算分割到多个设备上进行的一种并行方式。不同于数据并行在数据维度上的划分,张量并行通过分割模型的不同层或张量来并行化计算。每个GPU只计算模型的一部分(例如,一层神经网络或一个张量片段),然后通过跨设备通信将其结果汇总。
张量并行能够有效解决单个GPU内存不足以加载完整模型的问题,但它的挑战在于跨设备的通信开销较大。随着模型尺寸的增加,模型并行的开销也随之增加,这要求更加高效的算法和硬件架构。
Megatron-LM是张量并行的一个典型应用,通过将模型的张量分布到多个GPU上,从而能够训练大规模模型,如GPT-3、PaLM等。结合数据并行和张量并行的方式,模型的训练效率和规模都得到了显著提升。
流水线并行(Pipeline Parallelism)
流水线并行是一种将模型的不同阶段分布到多个设备上进行训练的策略。不同于数据并行和张量并行,流水线并行将模型划分为不同的部分,每个设备只处理某个阶段的任务,并将输出传递给下一个阶段的设备。这样,多个设备可以并行工作,每个设备处理不同的任务,但最终目标是加速模型的训练过程。
例如,如果一个模型有5个阶段,流水线并行会将每个阶段分配到一个GPU上,允许GPU并行工作,每个GPU处理模型的一部分任务。这种方法在长时间的训练过程中非常有效,尤其是在非常深的网络架构中。
流水线并行的挑战在于,需要有效地同步不同阶段之间的数据流,而且每个设备只能在前一个设备完成计算后才开始工作,这可能会带来延迟。然而,通过合理设计流水线,延迟可以降到最低,从而提高训练效率。
训练优化策略
在训练LLM时,除了并行化策略,硬件和算法的优化同样至关重要。以下是一些重要的训练优化策略:
梯度累积(Gradient Accumulation)
梯度累积是一种将训练批次分割为微批次,并在每个微批次的训练过程中累积梯度,直到所有微批次完成后再进行一次参数更新的技术。这种方式可以有效降低内存需求,并使得大批次的训练成为可能,从而加速模型训练。混合精度训练(Mixed Precision Training)
混合精度训练使用16位和32位浮动精度的结合来训练神经网络。通过使用低精度的计算,可以显著减少内存占用和计算开销,同时又不会损失太多的模型精度。这种技术在处理大规模模型时尤其有用。动态学习率(Dynamic Learning Rates)
在训练过程中,根据模型的表现动态调整学习率,可以提高收敛速度并减少过拟合的风险。常见的学习率调整策略包括基于训练轮次的衰减、基于梯度的自适应调整等。模型剪枝与蒸馏(Model Pruning and Distillation)
在训练后期,通过剪枝减少不必要的模型参数,或者通过蒸馏技术将大模型的知识转移到小模型中,从而提升推理效率。这些技术可以帮助减轻大模型部署的资源压力,并加速推理。
数据集收集
https://wandb.ai/site/articles/training-llms/dataset-collection/
“坏数据导致坏模型。” 这一点在训练大型语言模型(LLM)时尤为重要。高质量、具有高多样性和大规模的训练数据集,不仅能提高下游任务的模型表现,还能加速模型的收敛过程。
数据集的多样性对于LLM尤其关键。这是因为数据的多样性能有效提升模型在跨领域的知识涵盖能力,从而提高其对各种复杂任务的泛化能力。通过训练多样化的示例,能够增强模型在处理各种细微任务时的表现。
在数据集收集过程中,一般的数据可以由非专家收集,但对于特定领域的数据,通常需要由专业领域的专家(SMEs,Subject Matter Experts)来进行收集和审查。
NLP工程师在这个阶段也应当深度参与,原因在于他们熟悉LLM如何“学习表示数据”的过程,因此能发现专家可能遗漏的数据异常或缺口。专家和NLP工程师之间的协作非常重要,可以确保数据的质量和代表性。
数据预处理
https://wandb.ai/site/articles/training-llms/dataset-pre-processing/
数据采样(Data Sampling):
某些数据组件可以进行过采样(up-sampling),以获得更平衡的数据分布。例如,一些研究会对低质量的数据集(如未过滤的网页爬取数据)进行下采样(down-sampling)。而其他研究则会根据模型目标对特定领域的数据进行过采样。
对于预训练数据集而言,其组成通常来源于高质量的科学资源,例如学术论文、教科书、讲义和百科全书。数据集的质量通常非常高,并且会根据任务需要进行特定的筛选,比如使用任务特定的数据集来帮助模型学习如何将这些知识融入到新的任务上下文中。
数据清理(Data Cleaning):
通常在训练之前,需要对数据进行清理和重新格式化。一些常见的清理步骤包括去除样板文本(boilerplate text)、去除HTML代码或标记。对于某些项目,还需要修复拼写错误、处理跨领域的同形异义词(homographs),或者去除有偏见或有害的言论,以提高模型的表现。
非标准文本组件的处理(Handling Non-Standard Textual Components):
在某些情况下,将非标准的文本组件转换成标准文本非常重要。例如,emoji表情可以转换为其对应的文本表示:❄️可以转换为“snowflake”。这种转换通常可以通过编程实现。
数据去重(Data Deduplication):
一些研究者发现,去重训练数据能够显著提高模型的表现。常用的去重方法包括局部敏感哈希(LSH, Locality-Sensitive Hashing)。通过这种方法,可以识别并移除重复的训练数据,从而减少模型学习到的冗余信息。
预训练
https://wandb.ai/site/articles/training-llms/pre-training-steps/
训练一个数十亿参数的LLM(大规模语言模型)通常是一个高度实验性的过程,充满了大量的试验与错误。通常,团队会从一个较小的模型开始,确保其具有潜力,然后逐步扩展到更多的参数。需要注意的是,随着模型规模的扩大,会出现一些在训练小规模数据时不会遇到的问题。
模型架构
为了减少训练不稳定的风险,实践者通常会选择从流行的前身模型(如GPT-2或GPT-3)中借鉴架构和超参数,并在此基础上做出调整,以提高训练效率、扩展模型的规模(包括深度和宽度),并增强模型的性能。
正如前面提到的,预训练过程通常涉及大量的实验,以找到模型性能的最佳配置。实验可以涉及以下内容之一或全部:
权重初始化(Weight Initialization)
位置嵌入(Positional Embeddings)
优化器(Optimizer)
激活函数(Activation)
学习率(Learning Rate)
权重衰减(Weight Decay)
损失函数(Loss Function)
序列长度(Sequence Length)
层数(Number of Layers)
注意力头数(Number of Attention Heads)
参数数量(Number of Parameters)
稠密与稀疏层(Dense vs. Sparse Layers)
批量大小(Batch Size)
Dropout等。
通常,人工试错与自动超参数优化(HPO)相结合,用来找到最优的配置组合。常见的超参数包括:学习率、批量大小、dropout率等。超参数搜索是一个高昂的过程,尤其是对于数十亿参数的模型来说,往往过于昂贵,不容易在完整规模下进行。通常会根据先前的小规模实验结果和已发布的工作,来选择超参数,而不是从零开始。
此外,某些超参数在训练过程中也需要进行动态调整,以平衡学习效率和训练收敛。例如:
学习率(Learning Rate):在训练的早期阶段可以线性增加,之后再衰减。
批量大小(Batch Size):通常会从较小的批量大小开始,逐步增加。
硬件故障与训练不稳定
硬件故障(Hardware Failure):在训练过程中,计算集群可能会发生硬件故障,这时需要手动或自动重启训练。在手动重启时,训练会暂停,并进行一系列诊断测试来检测有问题的节点。标记为有问题的节点应该被隔离,然后从最后保存的检查点继续训练。
训练不稳定(Training Instability):训练不稳定性是一个根本性的挑战。在训练过程中,超参数(如学习率和权重初始化)直接影响模型的稳定性。例如,当损失值发散时,降低学习率并从较早的检查点重新启动训练,可能会帮助恢复训练并继续进行。此外,模型越大,训练过程中发生损失峰值(loss spikes)的难度也越大,这些峰值可能在训练的后期出现,并且不规则。尽管没有很多系统性的方法来减少这种波动,但以下是一些行业中的最佳实践:
批量大小(Batch Size):通常,使用GPU能够支持的最大批量大小是最好的选择。
批量归一化(Batch Normalization):对mini-batch中的激活进行归一化可以加速收敛并提高模型性能。
学习率调度(Learning Rate Scheduling):高学习率可能会导致损失波动或发散,从而导致损失峰值。通过调整学习率的衰减,逐步减小模型参数更新的幅度,可以提高训练稳定性。常见的调度方式包括阶梯衰减(step decay)**和**指数衰减(exponential decay)。
权重初始化(Weight Initialization):正确的权重初始化有助于模型更快收敛并提高性能。常见的方法包括随机初始化、高斯噪声初始化以及Transformers中的T-Fixup初始化。
模型训练起点(Model Training Starting Point):使用在相关任务上预训练过的模型作为起点,可以帮助模型更快收敛并提高性能。
正则化(Regularization):使用dropout、权重衰减(weight decay)和L1/L2正则化等方法可以减少过拟合并提高模型的泛化能力。
数据增强(Data Augmentation):通过对训练数据应用转换,可以帮助模型更好地泛化,减少过拟合。
训练过程中热交换(Hot-Swapping):在训练过程中根据需要更换优化器或激活函数,帮助解决出现的问题。
模型评估
https://wandb.ai/site/articles/training-llms/model-evaluation/
通常,预训练的模型会在多种语言模型数据集上进行评估,以评估其在逻辑推理、翻译、自然语言推理、问答等任务中的表现。机器学习领域的实践者已经对多种标准评估基准达成共识。
另一个评估步骤是n-shot学习。它是一个与任务无关的维度,指的是在推理时提供给模型的监督样本(示例)数量。n-shot通常通过“提示(prompting)”技术来提供。评估通常分为以下三类:
零样本(Zero-shot):不向模型提供任何监督样本进行推理任务的评估。
一-shot(One-shot):类似于少样本(few-shot),但n=1,表示在推理时向模型提供一个监督样本。
少样本(Few-shot):评估中向模型提供少量监督样本(例如,提供5个样本 -> 5-shot)。
偏见与有害语言
https://wandb.ai/site/articles/training-llms/bias-and-toxicity/
在基于网页文本训练的大规模通用语言模型中,存在潜在的风险。这是因为:人类本身有偏见,这些偏见会通过数据传递到模型中,模型在学习这些数据时,也会继承这些偏见。除了加剧或延续社会刻板印象之外,我们还需要确保模型不会记住并泄露私人信息。
仇恨言论检测(Hate Speech Detection)
社会偏见检测(Social Bias Detection)
有害语言生成(Toxic Language Generation)
对话安全评估(Dialog Safety Evaluations)
截至目前,大多数对现有预训练模型的分析表明,基于互联网训练的模型会继承互联网规模的偏见。此外,预训练模型通常容易生成有害语言,即使给出相对无害的提示,且对抗性提示也容易找到。
那么,如何修复这些问题呢?以下是一些在预训练过程中以及训练后缓解偏见的方法:
训练集过滤(Training Set Filtering)
训练集修改(Training Set Modification)
训练后偏见缓解方法
提示工程(Prompt Engineering)
微调(Fine-tuning)
输出引导(Output Steering)
Instruction Tuning(指令微调)
https://wandb.ai/site/articles/training-llms/instruction-tuning/
假设我们现在拥有一个预训练的通用大型语言模型(LLM)。如果我们之前的工作做得足够好,那么模型已经能够在零-shot和少量-shot的情况下执行一些特定领域的任务。然而,尽管零-shot学习可以在某些情况下有效,许多任务(如阅读理解、问答、自然语言推理等)中,零-shot学习的效果通常要逊色于少量-shot学习的表现。一个可能的原因是,在没有少量示例的情况下,模型很难在格式与预训练数据不同的提示下取得好的表现。
为了应对这个问题,我们可以使用指令微调(Instruction Tuning)。指令微调是一种先进的微调技术,它通过对预训练模型进行微调,使其能更好地响应各种任务指令,从而减少在提示阶段对少量示例的需求(即显著提高零-shot性能)。
指令微调在2022年大受欢迎,因为这一技术能显著提高模型性能,同时不会影响其泛化能力。通常,预训练的LLM会在一组语言任务上进行微调,并通过在微调过程中未见过的任务来评估其泛化能力和零-shot能力。
与预训练–微调和提示的比较
预训练–微调(Pretrain–Finetune):在预训练模型的基础上,进行特定任务的微调。模型通常在特定领域数据上进行微调,能显著提升该任务的性能,但对其他任务的泛化能力可能较差。
提示(Prompting):使用适当的提示词(prompt)引导模型执行特定任务,但在某些任务中(如阅读理解和问答),零-shot学习的效果往往较差。
指令微调:通过对模型进行全面微调,使其能够更加有效地理解和执行各种任务指令,从而减少了对少量示例的依赖,并显著提升零-shot性能。
思维链(Chain-of-Thought)在指令微调中的作用
思维链是一种技术,通过这种方式,模型在执行任务时会显式地推理每一个步骤,帮助模型更好地理解问题的背景并给出合理的推理过程。对于某些复杂的推理任务,使用思维链的示例可以显著提高模型的推理能力,并提升其在这些任务上的表现。
在指令微调过程中,若包含思维链示例(例如步骤分解、推理过程的写作等),模型会学会按照逻辑推理的步骤逐步完成任务,而非直接给出答案。这对像数学推理、常识推理等复杂任务尤其有效。
提高零-shot能力:通过对预训练模型进行指令微调,模型能更好地理解和执行未见过的任务,提升其在零-shot任务上的表现。
泛化性强:与只针对特定任务微调的模型相比,指令微调的模型具有更强的泛化能力,能够适应多种下游任务。
减少对少量示例的需求:经过指令微调的模型在零-shot和少-shot任务中表现更为优秀,减少了对示例输入的依赖。
强化学习与人类反馈 (RLHF)
https://wandb.ai/site/articles/training-llms/rlhf/
RLHF(Reinforcement Learning with Human Feedback) 是一种在指令微调的基础上,通过引入人类反馈来进一步提升模型与用户期望对齐的技术。
预训练的LLM(大型语言模型)通常会表现出一些不良行为,例如编造事实、生成偏见或有毒的回复,或者由于训练目标和用户目标之间的错位,未能按照指令执行任务。RLHF 通过利用人类反馈来对模型的输出进行精细调整,从而解决这些问题。
例如,OpenAI 的 InstructGPT 和 ChatGPT 就是 RLHF 的实际应用案例。InstructGPT 是在 GPT-3 上使用 RLHF 进行微调的,而 ChatGPT 基于 GPT-3.5 系列,这些模型在提升真实度和减少有毒输出方面取得了显著进展,同时性能回归(也称为“对齐税”)保持在最低水平。
以下是 RLHF 流程的概念图,展示了三个主要步骤:
监督微调(SFT):对预训练模型进行指令微调。
奖励模型(RM)训练:通过人类反馈训练奖励模型。
通过近端策略优化(PPO)进行强化学习:使用奖励模型优化模型的行为策略。
参考文献
What Language Model Architecture and Pre-training Objective Work Best for Zero-Shot Generalization?
GPT-3 Paper – Language Models are Few-Shot Learners
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
OPT: Open Pre-trained Transformer Language Models
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
How To Build an Efficient NLP Model
Emergent Abilities of Large Language Models
Beyond the Imitation Game Benchmark (BIG-bench)
Talking About Large Language Models
Galactica: A Large Language Model for Science
State of AI Report 2022
Finetuned Language Models are Zero-Shot Learners
Scaling Instruction-Fine Tuned Language Models
Training Language Models to Follow Instructions with Human Feedback
Scalable Deep Learning on Distributed Infrastructures: Challenges, Techniques, and Tools
New Scaling Laws for Large Language Models by DeepMind
New Scaling Laws for Large Language Models
Understanding the Difficulty of Training Transformers
END
欢迎加入Imagination GPU与人工智能交流2群

入群请加小编微信:eetrend77
(添加请备注公司名和职称)
推荐阅读

Imagination Technologies 是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作 场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech!


















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









