







我自己的原文哦~ https://blog.51cto.com/whaosoft/11577973
一、大模型能自己优化Prompt了
人类设计 prompt 的效率其实很低,效果也不如 AI 模型自己优化。
2022 年底,ChatGPT 上线,同时引爆了一个新的名词:提示工程(Prompt Engineering)。
简而言之,提示工程就是寻找一种编辑查询(query)的方式,使得大型语言模型(LLM)或 AI 绘画或视频生成器能得到最佳结果或者让用户能绕过这些模型的安保措施。现在的互联网上到处都是提示工程指南、快捷查询表、建议推文,可以帮助用户充分使用 LLM。在商业领域,现在也有不少公司竞相使用 LLM 来构建产品 copilot、自动化繁琐的工作、创造个人助理。
之前在微软工作过的 Austin Henley 最近采访了一些基于 LLM 开发 copilot 产品或服务的人:「每一家企业都想将其用于他们能想象到的每一种用例。」这也是企业会寻求专业提示工程师帮助的原因。
但一些新的研究结果表明,提示工程干得最好的还是模型自己,而非人类工程师。
这不禁让人怀疑提示工程的未来 —— 并且也让人越来越怀疑可能相当多提示工程岗位都只是昙花一现,至少少于当前该领域的想象。
自动微调的提示很成功,也很怪
当面对奇怪的提示工程技术时,LLM 的表现常常很怪异又不可预测。加州的云计算公司 VMware 的 Rick Battle 和 Teja Gollapudi 也为此感到困惑。举个例子,人们发现如果让模型自己一步步地解释自己的推理过程(即思维链技术),其在许多数学和逻辑问题上的性能都能得到提升。更奇怪的是,Battle 发现,如果为模型提供正向的 prompt,比如「这会很有趣」或「你和 ChatGPT 一样聪明」,有时候模型的性能也会提升。
Battle 和 Gollapudi 决定系统性地测试不同的提示工程策略会如何影响 LLM 解决小学数学问题的能力。他们使用 60 种不同的 prompt 组合分别测试了 3 种不同的开源语言模型。
- 论文标题:The Unreasonable Effectiveness of Eccentric Automatic Prompts
- 论文地址:https://arxiv.org/pdf/2402.10949.pdf
他们得到的结果呈现出了惊人的不一致性。甚至思维链 prompt 设计方法也不总是好的 —— 有时候有用,有时候却有害。
「唯一的趋势就是没有趋势,」他们写道:「对于任意给定模型、数据集和提示工程策略的某个特定组合而言,最好的方法很可能都非常具有针对性。」
有一种方法可以替代这种常常导致不一致结果的试错风格的提示工程:让语言模型自己设计最优的 prompt。最近,人们已经开发出了一些自动化这一过程的新工具。给定一些示例和定量的成功指标,这些工具可迭代式地找到输送给 LLM 的最优语句。Battle 及同事发现,在几乎所有案例中,这种自动生成的 prompt 的表现都优于通过试错方法找到的最佳 prompt。而且自动方法的速度还快得多 —— 只需一两个小时,而不是好几天。
另外,算法输出的这些最优 prompt 往往非常怪异,人类基本不可能想出来。Battle 说:「我简直不敢相信它生成的一些东西。」
举个例子,有一个 prompt 就是直接把《星际迷航》的说话风格搬过来了:「指挥官,我们需要您绘制一条穿过这股湍流的路线并定位异常源。使用所有可用数据和您的专长引导我们度过这一困境。」很显然,如果以对待柯克舰长的态度对待这个特定的 LLM,就可以帮助它更好地解答小学数学问题。
Battle 表示,以算法方法优化 prompt 在原理上是可行的,毕竟语言模型本就是模型。「很多人将这些东西拟人化,因为它们『说英语』,」Battle 说,「不,它不是说英语,而是做大量数学运算。」
事实上,根据其团队的研究成果,Battle 表示:人类再也不应该人工优化 prompt。
「你就坐在那里,试图找到单词的某种神奇组合,从而让你的模型在你的任务上得到最佳的可能表现。」Battle 说,「但这个研究结果却会告诉你『别费心了』。你只需开发一个评分指标,让系统可以自己判断一个 prompt 是否比另一个好,然后让模型自己去优化就行了。」
自动微调的提示也能让图像变好看
图像生成算法也能受益于自动生成的 prompt。
近日,Vasudev Lal 领导的一个英特尔实验团队做了一个类似的研究项目,不过他们是优化图像生成模型 Stable Diffusion 的 prompt。「如果只能让专家来做提示工程,那看起来就更像是 LLM 和扩散模型的一个 bug,而不是功能。」Lal 说,「所以,我们想看看能否自动化这种提示工程。」
Vasudev Lal 的团队开发了一种工具:NeuroPrompts。
- 论文标题:NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation
- 论文地址:https://arxiv.org/pdf/2311.12229.pdf
该工具可以自动改进简单的输入 prompt,比如「骑马的男孩」,从而得到更好的图像。为此,他们一开始使用了一些人类提示工程专家设计的 prompt。然后训练了一个语言模型来将简单 prompt 转换成这些专家级 prompt。在此基础上,他们继续使用强化学习来优化这些 prompt,从而得到更加美观的图像。这里的美观程度又是由另一个机器学习模型 PickScore 判断的(PickScore 是近期出现的一个图像评估工具)。

左图是使用一般的 prompt 生成的图像,右图是 NeuroPrompt 优化 prompt 之后再生成的图像。
这里也一样,自动生成的 prompt 的表现优于人类专家给出的 prompt(用作起点),至少根据 PickScore 指标是这样的。Lal 并不认为这出人意料。「人类只会使用试错方法来做这件事。」Lal 说,「但现在我们有了这种完全机器式的、完整回路的方法,再辅以强化学习…… 因此我们可以超过人类提示工程。」
由于审美是非常主观的,因此 Lal 团队希望让用户可以在一定程度上控制 prompt 优化的方式。在他们的工具中,用户除了可以指定原始 prompt(比如骑马的男孩),也能指定想要模仿的艺术家、风格、格式等。
Lal 相信随着生成式 AI 模型的发展,不管是图像生成器还是大型语言模型,对提示工程的奇怪依赖就会消失。「我认为研究这些优化方法非常重要,最后它们可以被整合进基础模型本身之中,这样你就无需复杂的提示工程步骤了。」
提示工程将以某种形式继续存在
Red Hat 软件工程高级副总裁 Tim Cramer 表示:就算自动微调 prompt 变成了行业规范,某种形式的提示工程岗位依然不会消失。能够满足行业需求的自适应生成式 AI 是一个非常复杂、多阶段的工作,在可预见的未来里都需要人类的参与。
「我认为提示工程师将会存在相当长一段时间,还有数据科学家。」Cramer 说,「这不仅仅只是向 LLM 提问并确保答案看起来不错。提示工程师其实要有能力做很多事情。」
「做出一个原型其实很容易。」Henley 说,「难的是将其产品化。」Henley 表示,当你在构建原型时,提示工程就是拼图中的相当大一部分,但当你开始构建商业产品时,还需要考虑其它许多因素。
开发商业产品的难题包括确保可靠性(比如在模型离线时得体地应对);将模型的输出调整成合适的格式(因为很多用例需要文本之外的输出);进行测试以确保 AI 助理不会在少数情况下做出有害的事情;还要确保安全、隐私与合规。Henley 表示,测试与合规尤其困难,因为传统的软件开发测试策略不适合非确定性的 LLM。
为了完成这大量的任务,许多大公司都正在推出一个新的工作岗位:大型语言模型运营(LLMOps)。该岗位的生命周期中就包含提示工程,但也包含其它许多部署产品所需的任务。Henley 表示,机器学习运营工程师(MLOps)是最适合这个岗位的,这是 LLMOps 的前身。
不管这个职位是叫提示工程师、LLMOps 工程师还是其它新名词,其特性都会不断快速变化。「也许我们现在是叫他们提示工程师,」Lal 说,「但我认为其互动的本质会不断变化,因为 AI 模型就在不断变化。」
「我不知道我们是否会将其与另一类工作或工作角色结合起来,」Cramer 说,「但我认为这些岗位不会很快消失。现在这一领域实在太疯狂了。每个方面都变化很大。我们无法在几个月内就搞明白这一切。」
Henley 表示,在某种程度上,现在正处于该领域的早期阶段,唯一压倒性的规则似乎就是没有规则。他说:「现在这个领域有点像是狂野西部。」
原文链接:https://spectrum.ieee.org/prompt-engineering-is-dead
二、下一个 token 预测任务
自香农在《通信的数学原理》一书中提出「下一个 token 预测任务」之后,这一概念逐渐成为现代语言模型的核心部分。最近,围绕下一个 token 预测的讨论日趋激烈。
然而,越来越多的人认为,以下一个 token 的预测为目标只能得到一个优秀的「即兴表演艺术家」,并不能真正模拟人类思维。人类会在执行计划之前在头脑中进行细致的想象、策划和回溯。遗憾的是,这种策略并没有明确地构建在当今语言模型的框架中。对此,部分学者如 LeCun,在其论文中已有所评判。
在一篇论文中,来自苏黎世联邦理工学院的 Gregor Bachmann 和谷歌研究院的 Vaishnavh Nagarajan 对这个话题进行了深入分析,指出了当前争论没有关注到的本质问题:即没有将训练阶段的 teacher forcing 模式和推理阶段的自回归模式加以区分。
- 论文标题:THE PITFALLS OF NEXT-TOKEN PREDICTION
- 论文地址:https://arxiv.org/pdf/2403.06963.pdf
- 项目地址:https://github.com/gregorbachmann/Next-Token-Failures
读完此文,也许会让你对下一个 token 预测的内涵有不一样的理解。
研究背景

然而,这种简单粗暴的想法并不妨碍我们认为 token 预测模型的规划能力可能是很糟糕的。很重要的一点是,在这场争论中人们并没有仔细区分以下两种类型的 token 预测方式:推理阶段的自回归(模型将自己之前的输出作为输入)和训练阶段的 teacher-forcing(模型逐个对 token 进行预测,将所有之前的真值 token 作为输入)。如果不能对这两种情况做出区分,那当模型预测错误时,对复合误差的分析往往只会将问题导向至推理过程,让人们觉得这是模型执行方面的问题。但这是一种肤浅的认知,人们会觉得已经得到了一个近乎完美的 token 预测模型;也许,通过一个适当的后处理模型进行验证和回溯后,可以在不产生复合错误的情况下就能得出正确的计划。
在明确问题之后,紧接着我们就需要想清楚一件事:我们能放心地认为基于 token 预测的学习方式(teacher-forcing)总是能学习到准确的 token 预测模型吗?本文作者认为情况并非总是如此。
以如下这个任务为例:如果希望模型在看到问题陈述 p = (p_1, p_2 ... ,) 后产生基本真实的响应 token (r_1, r_2, ...) 。teacher-forcing 在训练模型生成 token r_i 时,不仅要提供问题陈述 p,还要部分基本事实 toekn r_1、...r_(i-1)。根据任务的不同,本文作者认为这可能会产生「捷径」,即利用产生的基本事实答案来虚假地拟合未来的答案 token。这种作弊方式可以称之为 「聪明的汉斯 」。接下来,当后面的 token 在这种作弊方法的作用下变得容易拟合时,相反,前面的答案 token(如 r_0、r_1 等)却变得更难学习。这是因为它们不再附带任何关于完整答案的监督信息,因为部分监督信息被「聪明的汉斯 」所剥夺。
作者认为,这两个缺陷会同时出现在 「前瞻性任务 」中:即需要在前一个 token 之前隐含地规划后一个 token 的任务。在这类任务中,teacher-forcing 会导致 token 预测器的结果非常不准确,无法推广到未知问题 p,甚至是独立同分布下的采样问题。
根据经验,本文作者证明了上述机制会导致在图的路径搜索任务中会产生分布上的问题。他们设计了一种能观察到模型的任何错误,并都可以通过直接求解来解决的方式。
作者观察到 Transformer 和 Mamba 架构(一种结构化状态空间模型)都失败了。他们还发现,一种预测未来多个 token 的无教师训练形式(在某些情况下)能够规避这种失败。因此,本文精心设计了一种易于学习的场景。在这种场景下会发现不是现有文献中所批评的环节,如卷积、递归或自回归推理,而是训练过程中的 token 预测环节出了问题。
本文作者希望这些研究结果能够启发未来围绕下一个 token 预测的讨论,并为其奠定坚实的基础。具体来说,作者认为,下一个 token 预测目标在上述这个简单任务上的失败,为其在更复杂任务(比如学习写故事)上的应用前景蒙上了阴影。作者还希望,这个失败的例子和无教师训练方法所产生的正面结果,能够激励人们采用其他的训练范式。
贡献总结如下:
1. 本文整合了针对下一个 token 预测的现有批评意见,并将新的核心争议点具体化;
2. 本文指出,对下一个 token 预测的争论不能混淆自回归推断与 teacher-forcing,两者导致的失败的原因大相径庭;
3. 本文从概念上论证了在前瞻任务中,训练过程中的下一个 token 预测(即 teacher-forcing)可能会产生有问题的学习机制,甚至产生分布上的问题;
4. 本文设计了一个最小前瞻任务。通过实证证明,尽管该任务很容易学习,但对于 Transformer 和 Mamba 架构来说,teacher-forcing 是失败的;
5. 本文发现,Monea et al. 为实现正交推理时间效率目标而提出的同时预测多个未来 token 的无教师训练形式,有望在某些情况下规避这些训练阶段上的失败。这进一步证明了下一个 token 预测的局限性。
方法介绍
自回归推理导致的问题
本文的目标是更系统地分析并细致区分下一个 token 预测的两个阶段:teacher forcing 和自回归。本文作者认为,现有的论证没有完全分析出 token 预测模型无法规划任务的全部原因。
- 正方:概率链规则永远滴神
支持者对下一个 token 预测最热的呼声是:概率链规则总能推出一个能够符合概率分布的 token 预测。
- 反方:误差会像雪球一样越滚越大
反对者认为,在自回归的每一步中都有可能出现微小的错误,而且一旦出错就没有明确的回溯机制来挽救模型。这样一来,每个 token 中的错误概率,无论多么微小,都会以指数级的速度越滚越大。
反方抓住的是自回归在结构上的缺点。而正方对概率链规则的强调也只是抓住了自回归架构的表现力。这两个论点都没有解决一个问题,即利用下一个 token 预测进行的学习本身可能在学习如何规划方面存在缺陷。从这个意义上说,本文作者认为现有的论证只捕捉到了问题的表象,即下一个 token 预测在规划方面表现不佳。whaosoft开发板商城 测试设备
teacher forcing 导致的问题
token 预测模型是否会在测试期间无法高精度地预测下一个 token?从数学上讲,这意味着用 teacher forcing 目标训练的模型在其训练的分布上误差较大(从而打破了滚雪球模式的假设)。因此,任何后处理模型都无法找到一个能用的计划。从概念上来说,这种失败可能发生在「前瞻性任务」中,因为这些任务隐含地要求在更早的 token 之前提前计算未来的 token。
为了更好地表述本文的论点所在,作者设计了一个图的简单寻路问题,深刻地抓住了解决前瞻性问题的核心本质。这项任务本身很容易解决,所以任何失误都会非常直观地体现出来。作者将这个例子视为其论点的模板,该论点覆盖了 teacher forcing 下的前瞻性问题中的更一般、更困难的问题。
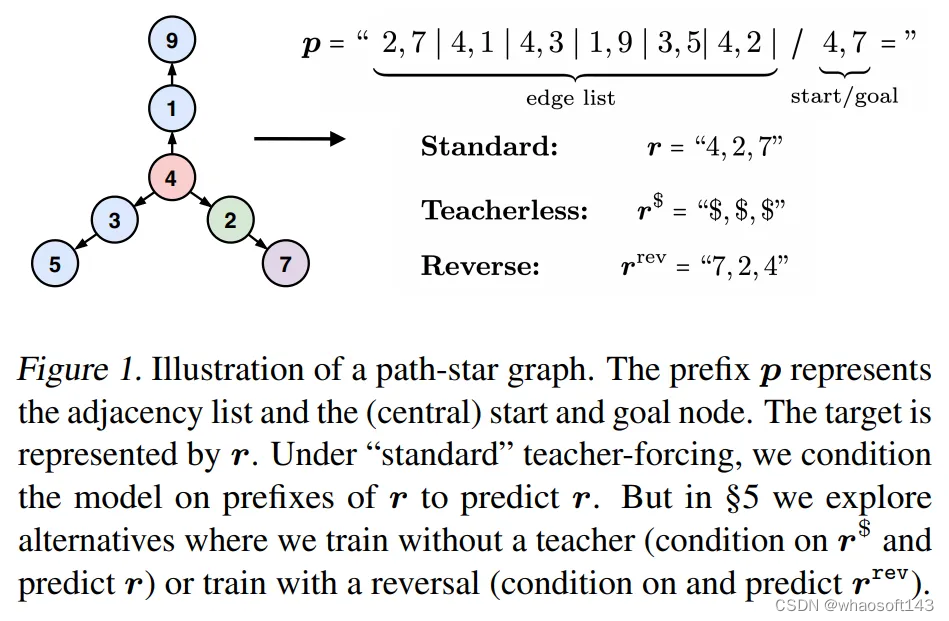
这个论点就是,本文作者认为 teacher-forcing 可能会导致以下问题,尤其是在前瞻性问题中。
- 问题 1:由于 teacher forcing 产生的「聪明的汉斯」作弊行为
尽管存在着一种机制可以从原始前缀 p 中恢复每个 token r_i,但也可以有多种其他机制可以从 teacher forcing 的前缀(p,r<i)中恢复 token r_i。这些机制可以更容易地被学习到,相应地就会抑制模型学习真正的机制。
- 问题 2:由于失去监督而无法加密的 token
在训练中解决了「聪明的汉斯」作弊行为后,模型被剥夺了一部分监督(尤其是对于较大的 i,r_i),这使得模型更难,甚至可能难以单独从剩余的 token 中学习真正的机制。
实验
本文通过图路径搜索任务的实践,演示了一种假设的故障模式。本文在 Transformer 和 Mamba 中进行了实验,以证明这些问题对于 teacher-forced 模型来说是普遍的。具体来说,先确定 teacher-forced 模型能符合训练数据,但在满足数据分布这个问题上存在不足。接下来,设计指标来量化上述两种假设机制发生的程度。最后,设计了替代目标来干预和消除两种故障模式中的每一种,以测试性能是否有所改善。
模型配置
本文对两种模型家族进行了评估,以强调问题的出现与某种特定体系结构无关,而是源于下一个 token 预测这个设计目标。对于 Transformer,使用从头开始的 GPT-Mini 和预训练的 GPT-2 大模型。对于递归模型,使用从头开始的 Mamba 模型。本文使用 AdamW 进行优化,直到达到完美的训练精度。为了排除顿悟现象(grokking),本文对成本相对较低的模型进行了长达 500 个 epoch 的训练。
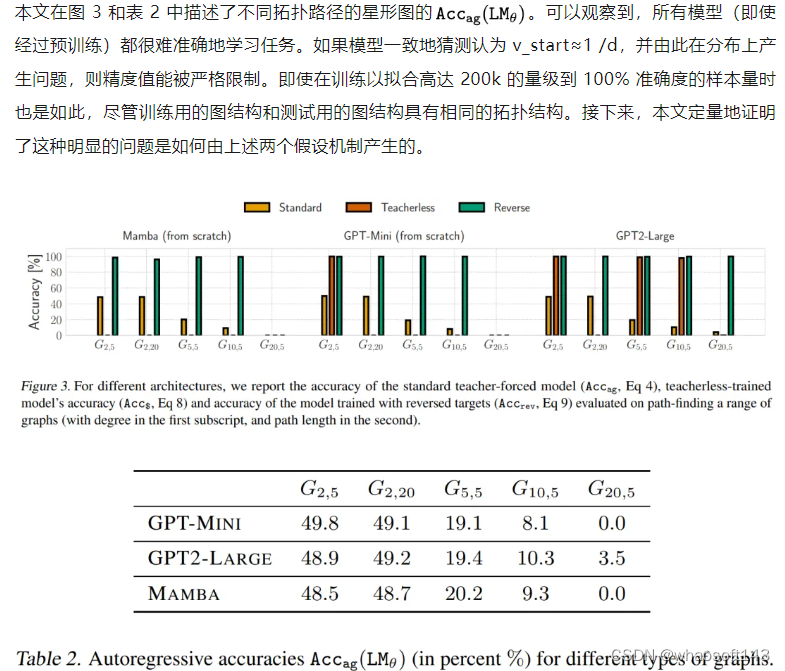
通过表 1 可以发现,为了拟合训练数据,teacher-forced 模型利用了「聪明的汉斯」作弊方法。
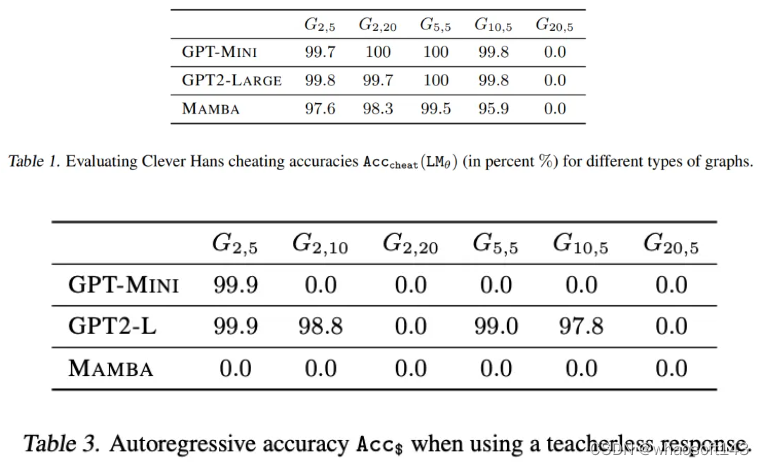
图 3 和表 3 显示了无教师模型的准确率。不幸的是,在大多数情况下,无教师的训练目标对模型来说太难了,甚至无法拟合训练数据,这可能是因为缺乏简单有效的欺骗手段。然而,令人惊讶的是,在一些更容易的图结构上,模型不仅适合于训练数据,而且可以很好地泛化到测试数据。这个优秀的结果(即使在有限的环境中)验证了两个假设。首先,「聪明的汉斯」作弊方法确实是造成原有 teacher-forcing 模式失败的原因之一。其次,值得注意的是,随着作弊行为的消失,这些模型能够拟合第一个节点,而这个节点曾经在 teacher-forcing 模式下是不可破译的。综上所述,本文所提出的假设可以说是得到了验证了,即「聪明的汉斯」作弊方法抹去了对学习第一个 token 的至关重要的监督。whao开发板商城 测试设备
三、下一离职谷歌的Transformer作者创业,连发3个模型
去年 8 月,两位著名的前谷歌研究人员 David Ha、Llion Jones 宣布创立一家人工智能公司 Sakana AI,总部位于日本东京。其中,Llion Jones 是谷歌 2017 年经典研究论文《Attention is all you need》的第五作者,该论文提出了深度学习架构 transformer。transformer 对整个机器学习领域产生了重要影响,并且是 ChatGPT 等生成式 AI 模型的基础。
论文于 2017 年 6 月首次发表后,随着全球对生成人工智能人才竞争不断升温,论文作者陆续离开谷歌,自立门户创业。Llion Jones 是八位作者中最后一个退出谷歌的人。
David Ha、Llion Jones 成立的初创公司 Sakana AI 致力于构建生成式 AI 模型。最近,Sakana AI 宣布推出一种通用方法 ——Evolutionary Model Merge。该方法使用进化算法来有效地发现组合不同开源模型的最佳方法,这些开源模型具有不同功能。Evolutionary Model Merge 方法能够自动创建具有用户指定功能的新基础模型。
为了测试其方法的有效性,研究团队用 Evolutionary Model Merge 方法演化出能够进行数学推理的日语大语言模型(LLM)和日语视觉语言模型(VLM)。实验结果表明这两个模型在没有经过明确优化的情况下,在多个 LLM 和视觉基准上都取得了 SOTA 结果。
特别是,其中进行数学推理的日语 LLM 是一个 7B 参数模型,它在大量日语 LLM 基准上取得了顶级性能,甚至超过了一些 SOTA 70B 参数 LLM。
最终,研究团队应用 Evolutionary Model Merge 方法演化出 3 个强大的基础模型:
1. 大语言模型(EvoLLM-JP)
2. 视觉语言模型(EvoVLM-JP)
3. 图像生成模型(EvoSDXL-JP)
值得注意的是,Evolutionary Model Merge 方法能够自动生成新的基础模型,而不需要任何基于梯度的训练,因此需要相对较少的计算资源。
Sakana AI 团队认为:受自然选择启发的进化算法可以解锁有效的开源方法合并解决方案,以探索广阔的可能性空间,发现传统方法和人类直觉可能错过的新颖且不直观的组合。
技术详解
技术报告介绍了 Evolutionary Model Merge 这种通用进化方法。
报告地址:https://arxiv.org/pdf/2403.13187.pdf
本文的目标是创建一个统一的框架,能够从选定的基础模型中自动生成合并模型,以确保该合并模型的性能超过集合中任何个体的性能,方法的核心是进化算法。研究者首先将合并过程剖析成两个不同的、正交的配置空间,并分析它们各自的影响。基于此分析,他们随后引入了一个无缝集成这些空间的内聚框架。图 1 为示意图。
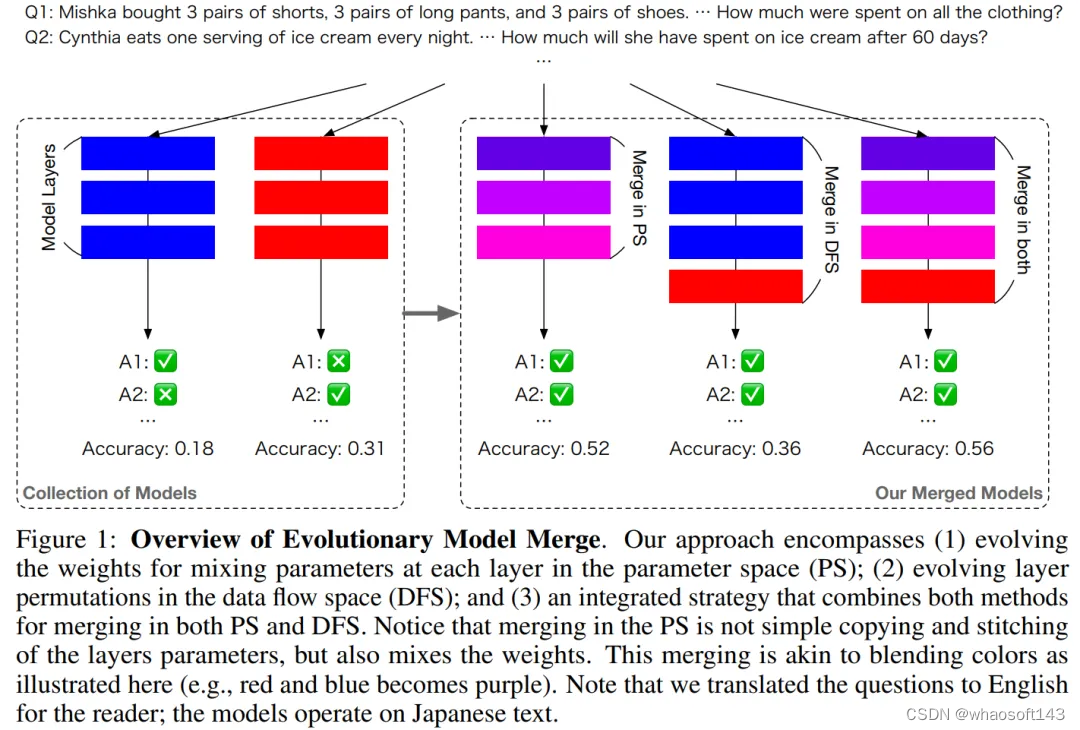
Evolutionary Model Merge 结合了:(1)合并数据流空间(Data Flow Space)中的模型,以及(2)合并参数空间(权重)中的模型。
数据流空间:是通过进化来发现不同模型各层的最佳组合以形成新模型。下面是这种方法的一个示例:
视频都发不了....
参数空间:第二种方法是开发混合多个模型权重的新方法,混合不同模型的权重以形成新的模型。下面视频为两种不同模型混合权重的过程说明:
数据流空间和参数空间这两种方法也可以结合在一起来开发新的基础模型:
该研究希望通过进化的方法来帮助找到更好的模型合并方法,通过实验,研究者证明了该方法能够创建具有以前不存在的、新的、具有新兴组合功能的新模型。实验中,研究者使用这种自动化方法生成了两个新模型:一个日语数学 LLM 和一个支持日语的 VLM,它们都是使用这种方法演化而来的。
具有 SOTA 性能的基础模型
该研究提出了三种模型:大型语言模型(EvoLLM-JP)、视觉语言模型(EvoVLM-JP)以及图像生成模型(EvoSDXL-JP)。
EvoLLM-JP
EvoLLM-JP 是一个可以用日语解决数学问题的 LLM。为了构建这样的模型,该研究使用进化算法来合并日语 LLM(Shisa-Gamma)和特定于数学的 LLM(WizardMath 和 Abel)。
实验过程中,研究者允许模型不断的进化迭代,最终模型采用的是在 100-150 次的进化中表现最好的模型。研究者在 MGSM 数据集上进行了评估,以下是评估结果:该表格比较了不同 LLM 用日语解决数学问题的表现,MGSM-JA 列显示正确答案的百分比。模型 1-3 为原始模型,模型 4-6 为优化后的合并模型。模型 7-10 是用于比较的 LLM 得分。
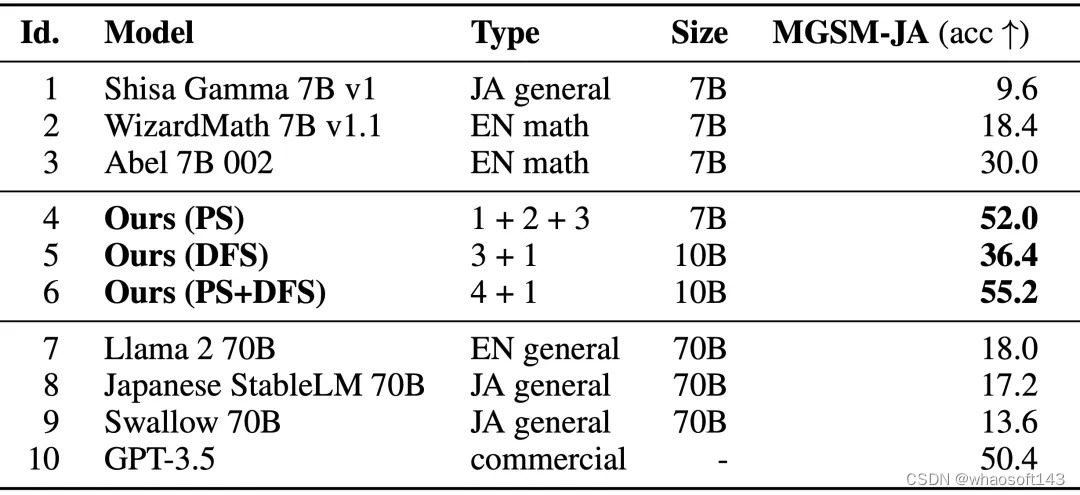
上表为进化后的 LLM 结果。其中模型 4 在参数空间中进行了优化,模型 6 使用模型 4 在数据流空间中进行了进一步优化。这些模型的正确响应率明显高于三个源模型的正确响应率。
不过研究者表示根据以往的经验,手动将日语 LLM 与数学 LLM 结合起来非常困难。但经过迭代努力,进化算法能够有效地找到一种将日语 LLM 与数学 LLM 结合起来的方法,成功地构建了一个兼具日语和数学能力的模型。
除了数学能力外,研究者还评估了模型的日语能力。令人惊讶的是,该研究发现这些模型在一些与数学无关的任务上也取得了高分。值得注意的是,模型并没有经过特定优化,但实际效果还不错。
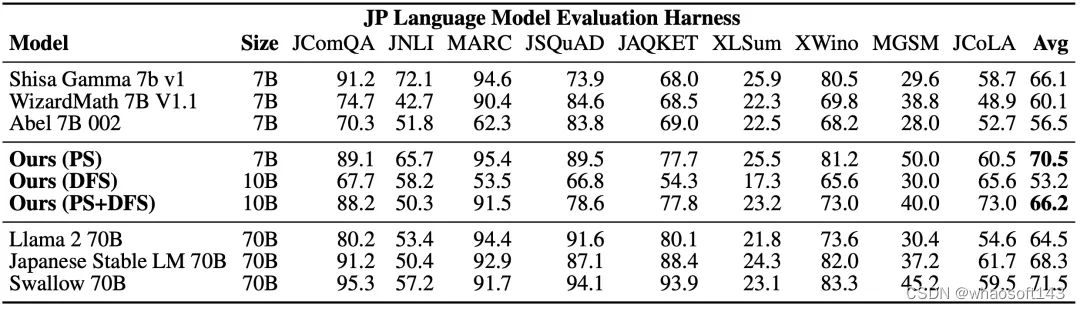
LLM 日语整体能力比较,其中 Avg 栏是 9 个任务得分的平均值,数值越高,代表 LLM 日语整体能力越高。
EvoVLM-JP
该研究发现,进化算法还可以进化成不同架构的模型。他们通过应用进化模型合并生成了一个日语视觉语言模型 (VLM)。
在构建日语 VLM 时,该研究使用了流行的开源 VLM (LLaVa-1.6-Mistral-7B) 和功能强大的日语 LLM (Shisa Gamma 7B v1)。研究者表示,这是合并 VLM 和 LLM 的第一次努力,其证明了进化算法可以在合并模型中发挥重要作用。以下是评估结果。

VLM 性能比较。
上表中,JA-VG-VQA-500 和 JA-VLM-Bench-In-the-Wild 都是关于图像问答的基准。分数越高,表示用日语回答的答案越准确。
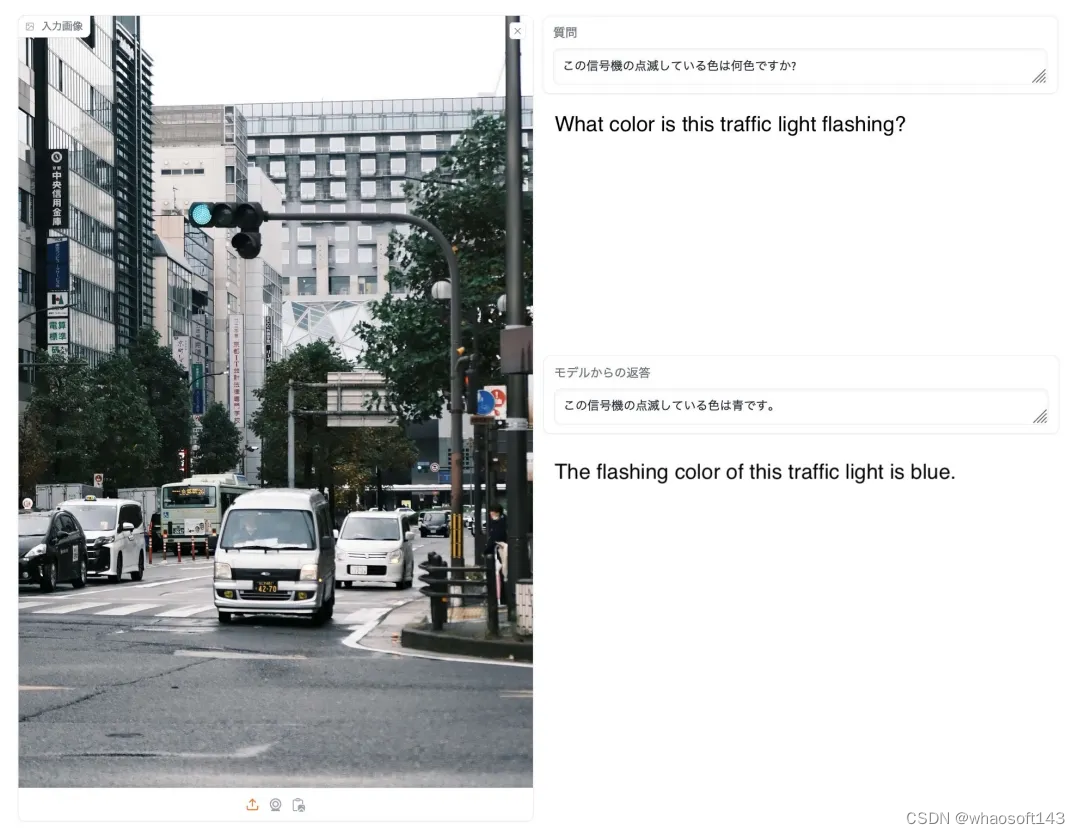
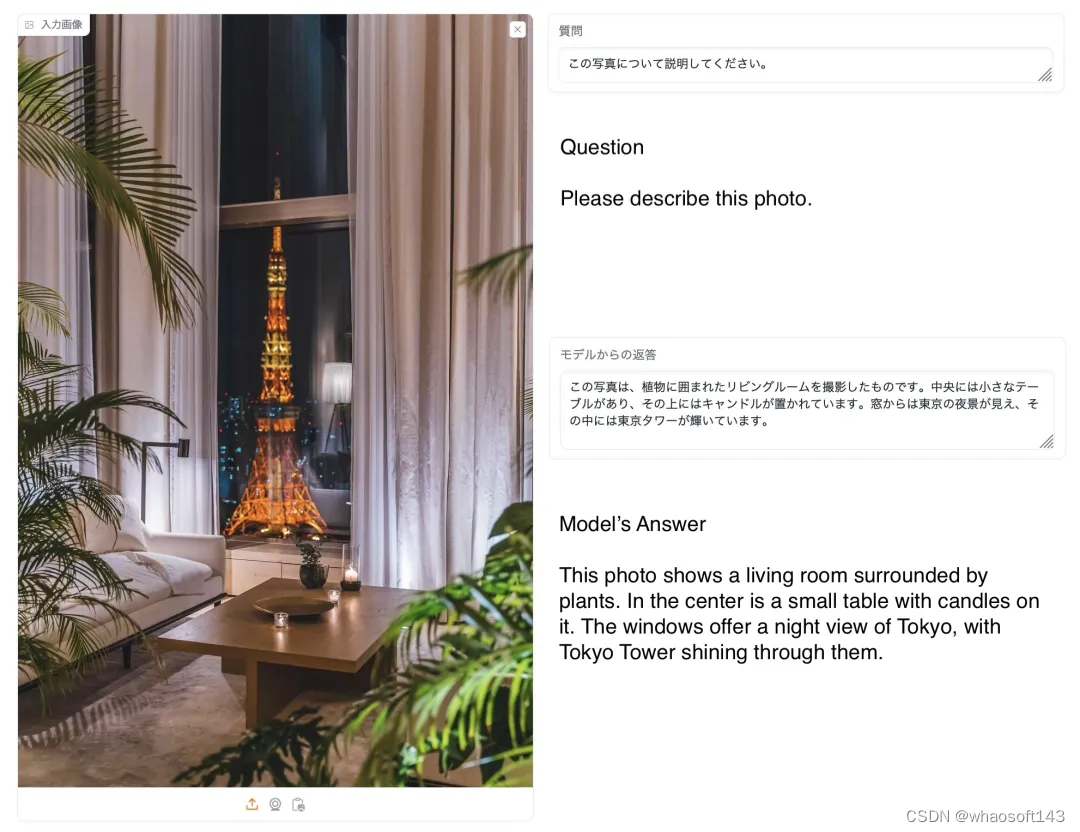
以下为模型在回答有关图像问题的示例展示。两种基线模型经常给出错误的答案,而 EvoVLM-JP 给出正确的答案。
例如用户询问交通信号灯现在是什么颜色时,通常来讲,正确答案是绿色,但是在日语习惯中,都会说成蓝色。可以看出 EvoVLM-JP 比较贴合日语习惯。
EvoSDXL-JP
该研究发现,进化也可以自动发现合并不同扩散模型的方法。

EvoSDXL-JP 根据提示生成图片。
参考链接:
https://sakana.ai/evolutionary-model-merge/
四、大模型微调综述
大型模型代表了多个应用领域的突破性进展,能够在各种任务中取得显著成就。然而,它们前所未有的规模带来了巨大的计算成本。这些模型通常由数十亿个参数组成,需要大量的计算资源才能执行。特别是,当为特定的下游任务定制它们时,特别是在受计算能力限制的硬件平台上,扩展的规模和计算需求带来了相当大的挑战。
参数有效微调(PEFT)通过在各种下游任务中有效地调整大型模型,提供了一种实用的解决方案。特别是,PEFT是指调整预先训练的大型模型的参数,使其适应特定任务或领域,同时最小化引入的额外参数或所需计算资源的数量的过程。当处理具有高参数计数的大型语言模型时,这种方法尤其重要,因为从头开始微调这些模型可能计算成本高昂且资源密集,在支持系统平台设计中提出了相当大的挑战。
在这项调查中,我们对各种PEFT算法进行了全面的研究,检查了它们的性能和计算开销。此外,我们还概述了使用不同PEFT算法开发的应用程序,并讨论了用于降低PEFT计算成本的常用技术。除了算法角度之外,我们还概述了各种现实世界中的系统设计,以研究与不同PEFT算法相关的实施成本。这项调查是研究人员了解PEFT算法及其系统实现的不可或缺的资源,为最新进展和实际应用提供了详细的见解。
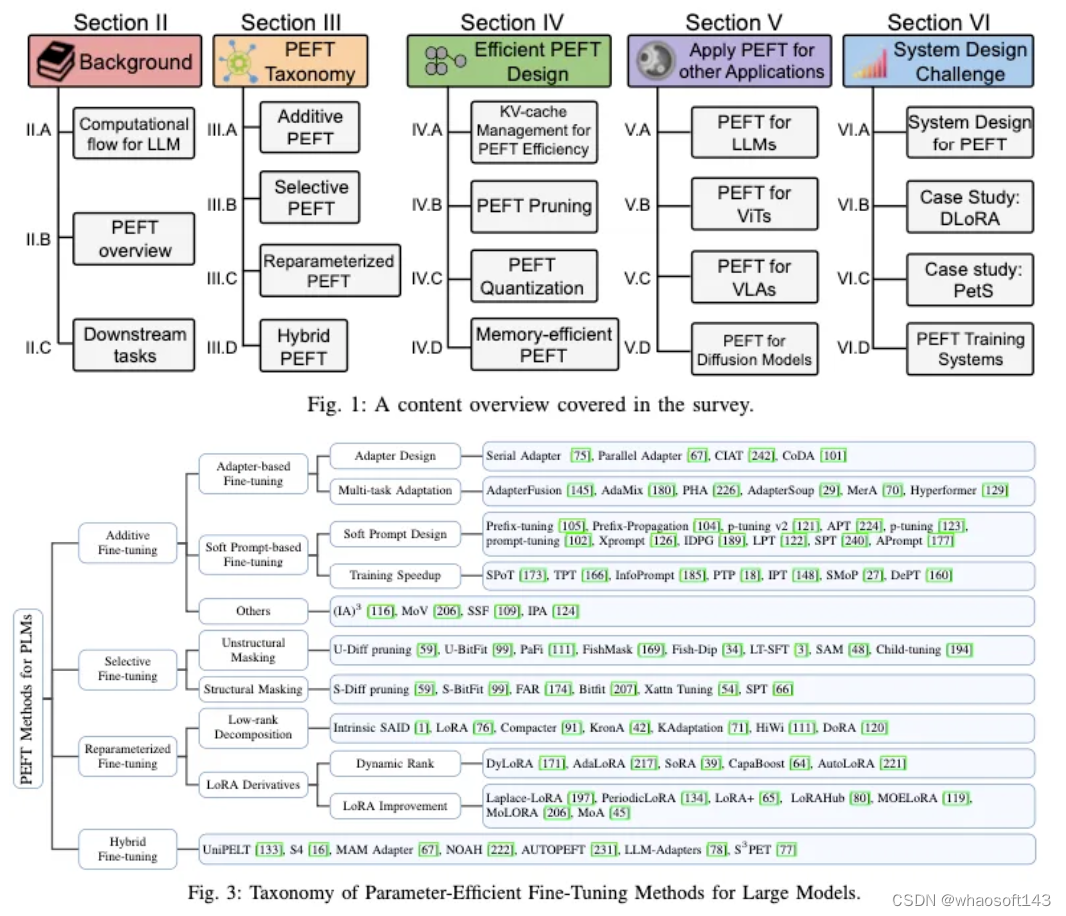
PEFT分类
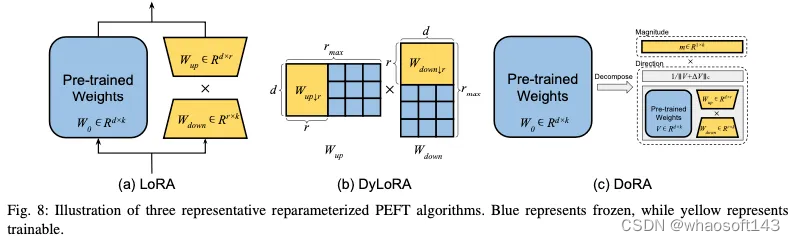
PEFT策略可大致分为四类:附加PEFT(第III-A节),通过注入新的可训练模块或参数来修改模型架构;选择性PEFT(第III-B节),使参数子集在微调期间可训练;重新参数化PEFT(第III-C节),它构建了用于训练的原始模型参数的(低维)重新参数化,然后等效地将其转换回用于推理;以及混合PEFT(第III-D节),它结合了不同PEFT方法的优势,建立了统一的PEFT模型。不同类型的PEFT算法概述如图4所示。
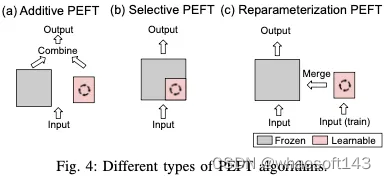
A. Additive PEFT
标准的完全微调需要大量的计算费用,也可能损害模型的泛化能力。为了缓解这个问题,一种广泛采用的方法是保持预先训练的主干不变,并且只引入在模型架构中战略性定位的最小数量的可训练参数。在针对特定下游任务进行微调时,仅更新这些附加模块或参数的权重,这导致存储、内存和计算资源需求的显著减少。如图4(a)所示,由于这些技术具有添加参数的特性,因此可以将其称为加性调整。接下来,我们将讨论几种流行的加法PEFT算法。
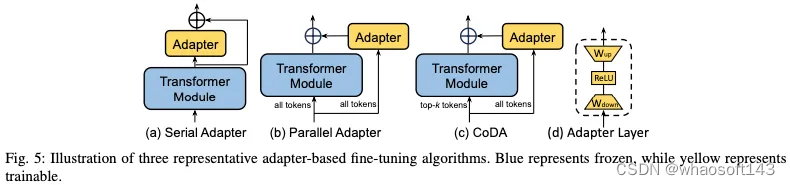
1)适配器:适配器方法包括在Transformer块中插入小型适配器层。
2)软提示:提示调整提供了一种额外的方法来细化模型,以通过微调提高性能。
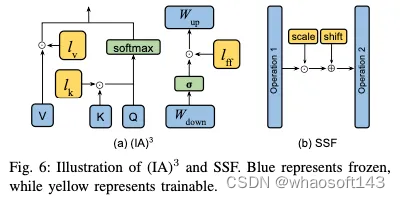
3)其他加法方法:除了上述方法外,还出现了其他方法,在微调过程中战略性地加入了额外的参数。
B. Selective PEFT
如图4(b)所示,选择性PEFT不是通过添加更多参数来增加模型复杂性的附加PEFT,而是对现有参数的子集进行微调,以提高模型在下游任务中的性能。
差分修剪是在微调期间将可学习的二进制掩码应用于模型权重的代表性工作。为了实现参数效率,通过L0范数惩罚的可微近似来正则化掩模。PaFi只需选择具有最小绝对幅度的模型参数作为可训练参数。
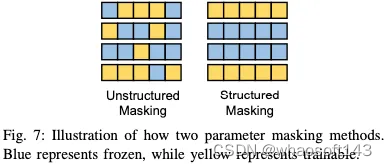
然而,当实现PEFT时,上述非结构化参数掩蔽导致非零掩蔽的不均匀分布和硬件效率的降低。如图7所示,与随机应用的非结构化掩码不同,结构化掩码以规则模式组织参数掩码,因此可以提高训练过程中的计算和硬件效率。因此,对各种结构选择性PEFT技术进行了广泛的研究。Diff修剪提出了一种结构化的修剪策略,将权重参数划分为局部组,并战略性地将它们一起消除。类似地,FAR通过将Transformer块中的FFN的权重分组为节点来微调BERT模型,然后使用L1范数对学习器节点进行排序和选择。为了进一步降低存储器访问频率,他们还通过将学习器节点分组在一起来重新配置FFN。
C. Reparameterized PEFT
重新参数化表示通过转换模型的参数将模型的体系结构从一个等效地转换到另一个。在PEFT的背景下,这通常意味着在训练过程中构建一个低阶参数化来实现参数效率的目标。对于推理,可以将模型转换为其原始的权重参数化,确保推理速度不变。该程序如图4(c)所示。
早期的研究表明,常见的预训练模型表现出异常低的内在维度。换言之,可以找到对整个参数空间的微调有效的低维重新参数化。内在SAID是研究LLM微调过程中内在维度特征的主要工作。然而,最广泛认可的重新参数化技术是LoRA(低秩自适应),如图8(a)所示。
D. Hybrid PEFT
各种PEFT方法的疗效在不同的任务中可能存在显著差异。因此,许多研究旨在结合不同PEFT方法的优势,或通过分析这些方法之间的相似性来寻求建立统一的视角。例如,UniPELT将LoRA、前缀调整和适配器集成到每个Transformer块中。为了控制应激活哪些PEFT子模块,他们还引入了门控机制。该机制由三个小的FFN组成,每个FFN产生一个标量值,然后将其分别应用于LoRA、前缀和适配器矩阵。
EFFICIENT PEFT DESIGN

从计算的角度来看,处理延迟和峰值内存开销是需要考虑的关键因素。本节介绍LLM的一个关键特性,旨在平衡延迟和内存使用(第IV-a节)。在此之后,我们探索了开发高效PEFT方法以应对计算挑战的策略,包括PEFT修剪(第IV-B节)、PEFT量化(第IV-C节)和记忆高效PEFT技术(第IV-D节),每种技术都旨在提高模型性能,同时最大限度地减少资源消耗。值得注意的是,量化本质上解决了存储器开销问题。然而,鉴于其独特的特性,我们单独讨论了这些量化方法,而不是将它们纳入记忆有效PEFT部分。
A. KV-cache Management for PEFT Efficiency
LLM模型的核心是一个自回归Transformer模型,如图2所示。当我们观察自回归特性时,它成为设计推理系统的一个主要挑战,因为每次生成新的令牌时,整个LLM模型都必须将所有权重从不同的内存转移到图形处理器的内存中,这对单用户任务调度或多用户工作负载平衡非常不友好。服务于自回归范式的挑战性部分是,所有先前的序列都必须被缓存并保存以供下一次迭代,从先前序列生成的缓存激活被存储为键值缓存(KV缓存)。
KV缓存的存储将同时消耗内存空间和IO性能,导致工作负载内存受限且系统计算能力利用不足。以前的工作提出了一系列解决方案,如KV缓存控制管理或KV缓存压缩,以提高吞吐量或减少延迟。在设计PEFT方法时,考虑KV缓存的特性以补充其特性是至关重要的。例如,当在推理阶段应用软提示时,通过确保与提示相关的数据易于访问,有效地利用KV缓存进行这些额外的输入可以帮助加快响应时间。
B.Pruning Strategies for PEFT
修剪的加入可以大大提高PEFT方法的效率。特别是,AdapterDrop探索了在AdapterFusion中从较低的转换层和多任务适配器中删除适配器,这表明修剪可以在性能下降最小的情况下提高训练和推理效率。SparseAdapter研究了不同的修剪方法,发现高稀疏率(80%)可以优于标准适配器。此外,大稀疏配置增加了瓶颈尺寸,同时保持了恒定的参数预算(例如,以50%的稀疏度将尺寸翻倍),大大增强了模型的容量,从而提高了性能。
C. Quantization Strategies for PEFT
量化是提高计算效率和减少内存使用的另一种流行技术。例如,通过研究适配器的损失情况,BI Adapter发现适配器能够抵抗参数空间中的噪声。在此基础上,作者引入了一种基于聚类的量化方法。值得注意的是,它们证明了适配器的1位量化不仅最大限度地减少了存储需求,而且在所有精度设置中都实现了卓越的性能。PEQA(参数高效和量化感知自适应)使用两级流水线来实现参数高效和量化器感知微调。QA LoRA解决了QLoRA的另一个局限性,QLoRA在微调后难以保持其量化特性。在QLoRA中,量化的预训练权重(NF4)必须恢复到FP16,以在权重合并期间匹配LoRA权重精度(FP16)。相反,QA LoRA使用INT4量化,并引入分组运算符以在推理阶段实现量化,因此与QLoRA相比提高了效率和准确性。
D. Memory-efficient PEFT Methods
QA LoRA解决了QLoRA的另一个局限性,即在微调后难以保持其量化特性。在QLoRA中,量化的预训练权重(NF4)必须恢复到FP16,以在权重合并期间匹配LoRA权重精度(FP16)。相反,QA LoRA使用INT4量化,并引入分组运算符以在推理阶段实现量化,因此与QLoRA相比提高了效率和准确性。
为了提高内存效率,已经开发了各种技术来最小化在微调期间对整个LLM的缓存梯度的需要,从而减少内存使用。例如,Side-Tuning和LST(Ladder-Side Tuning)都引入了与主干模型并行的可学习网络分支。通过专门通过这个并行分支引导反向传播,它避免了存储主模型权重的梯度信息的需要,从而显著降低了训练期间的内存需求。类似地,Res Tuning将PEFT调谐器(例如,即时调谐、适配器)与主干模型分离。在分解的基础上,提出了一个名为Res-Mtuning Bypass的高效内存微调框架,该框架通过去除从解耦的调谐器到主干的数据流,生成与主干模型并行的旁路网络。
PEFT FOR DNNS OF OTHER APPLICATIONS
在第三节中,我们概述了四类PEFT方法及其改进。尽管如此,我们的讨论并没有完全扩展到传统架构(如LLM)或标准基准(如GLUE数据集)之外的PEFT技术的利用或适应,其中大多数讨论的PEFT方法都是应用的。因此,在本节中,我们将重点介绍和讨论利用PEFT策略执行各种下游任务的几项最具代表性的工作。我们并不打算在本节中涵盖所有PEFT应用场景。我们的目标是展示产品环境足迹在各个研究领域的重大影响,并展示如何优化和定制通用产品环境足迹方法,以提高特定模型或任务的性能。
通常,在将预先训练的主干模型适应专门的下游任务时会进行微调。为此,本节围绕各种模型架构组织讨论,这些架构包括:LLM、视觉Transformer(ViT)、视觉语言对齐模型(VLA)和扩散模型。在每个体系结构类别中,讨论是基于不同的下游任务进行进一步分类的。
A. PEFT for LLMs – Beyond the Basics
与NLP中的常见任务(如NLU和NLG)不同,PEFT技术在不同的场景中具有广泛的应用。PEFT已成功应用于常识性问答、多层次隐含话语关系识别、分布外检测、隐私保护、联合学习和社会偏见缓解等领域。在本节中,我们将更多地关注三个具有代表性的下游任务:视觉教学跟随、持续学习和上下文窗口扩展。
1)视觉指导:包括VL-BART、MiniGPT-4和LLaVA在内的几项研究成功地扩展了LLM的能力,LLM最初是为纯文本设计的,可以理解和生成对视觉输入的响应。这些增强的模型,即视觉指令跟随LLM,可以处理图像和文本以产生文本响应,这些文本响应可以在图像字幕和视觉问答(VQA)等任务上进行基准测试。然而,这些方法对整个LLM进行微调以学习视觉表示,这在时间和内存方面都是低效的。因此,将PEFT技术应用于LLM后视觉教学的微调是很自然的。
2)持续学习(CL):CL旨在在一个模型中学习一系列新任务,在对话系统、信息提取系统和问答系统等场景中有广泛应用。CL的主要挑战是灾难性遗忘。一种流行的做法,称为基于体系结构的方法,通过在模型中为每个新任务维护特定于任务的参数来处理CL。因此,将PEFT方法用于CL任务是很自然的。
3)上下文窗口扩展:LLM通常使用预定义的上下文大小进行训练。例如,LLaMA和LLaMA2分别具有2048和4096个令牌的预定义上下文大小。位置编码RoPE具有弱的外推特性,这意味着在输入长度超过预定义上下文长度的情况下,性能明显下降。为了解决这个问题,一个简单的解决方案是将预先训练的LLM微调到更长的上下文。然而,这会随着上下文大小的二次方增加计算成本,从而使内存和处理资源紧张。
B. PEFT for ViTs
在最近的计算机视觉社区中,ViT已经成为一种强大的骨干模型。在ViT模型中,图像被视为固定大小的补丁序列,类似于LLM如何使用离散标记。这些补丁经过线性嵌入,然后接收位置编码。随后,它们通过标准的Transformer编码器进行处理。ViT的训练可以是监督的或自监督的,并且当使用更多数据和更大的模型大小进行训练时,ViT可以实现卓越的性能。然而,这种规模的扩大不可避免地会增加培训和存储成本。因此,与LLM类似,PEFT广泛应用于各种下游任务,如密集预测、连续学习、深度度量学习。在这里,我们重点关注两个典型的任务来展示PEFT的参与:图像分类和视频复原。
1)图像分类:在目标视觉数据集上进行图像分类是一种非常普遍的需求,具有广泛的应用,而预训练-微调范式是一种广泛的策略。多种方法利用PEFT技术实现有效的模型调整。
2)视频识别:一些工作考虑了更具挑战性的适应问题,即将ViT转移到具有更大领域差距的下游任务。例如,ST适配器(时空适配器)和AIM都将适配器层插入到预训练的ViT块中。他们的主要目标是对时空信息进行建模,从而使ViT能够有效地从图像模型适应视频任务。值得注意的是,这两种方法的性能都超过了传统的全模型微调方法。
C. PEFT for VLAs
视觉语言对齐模型(VLA),如CLIP、ALIGN、DeCLIP和FLAVA,旨在学习可以在统一表示空间内对齐的良好图像和文本特征。每个VLA通常由提取各自特征的独立图像和文本编码器组成。在这些模型中,对比学习被用来有效地对齐图像和文本特征。微调被用来提高VLA在特定数据集或任务中的性能,但对整个模型的微调是计算密集型的。
1) 开放式词汇图像分类:在开放式词汇的图像分类中,早期的作品为每个类别设计特定类别的提示,例如class的照片,并根据图像与这些文本描述的相似性对图像进行排名。CoOp(上下文优化)用可学习向量替换手工制作的文本提示,同时在训练期间保留整个VLA修复。CoCoOp(条件上下文优化)通过解决CoOp在推广到看不见的类方面的局限性,建立在这一基础上。
在另一个方向上,一些研究探讨了适配器在VLA中的使用。例如,CLIP适配器在CLIP的文本和视觉编码器之后集成了残余样式适配器。因此,与CoOp和CoCoOp不同,CLIP Adapter避免了通过CLIP编码器的梯度反向传播,从而降低了训练内存和时间方面的计算要求。尖端适配器采用与CLIP适配器相同的设计。与CLIP适配器不同的是,适配器的权重是以无训练的方式从查询密钥缓存模型中获得的,该模型是以非参数方式从最少监督构建的。因此,与CLIP-Adapter的SGD训练过程相比,Tip-Adapter表现出了极大的效率。
D. PEFT for Diffusion Models
扩散模型是一类生成模型,通过渐进去噪过程将随机噪声转换为结构化输出,学习生成数据。在训练过程中,扩散模型学习使用去噪网络来反转添加到训练数据中的噪声,而在推理中,它们从噪声开始,使用去噪网迭代创建与训练示例相同分布的数据。扩散模型有各种应用,而最值得注意的是稳定扩散,它以其直接从文本描述生成连贯和上下文相关图像的强大能力弥合了文本和图像之间的差距。许多研究利用PEFT技术将预先训练的扩散模型用于下游任务,包括加速采样速度、文本到视频的自适应、文本到3D的自适应等。本节主要关注两种场景:在仅基于文本的条件之外集成额外的输入模式,以及基于预先训练的传播模型定制内容生成。
1)附加输入控制:为了在保留预先训练的模型中的广泛知识的同时纳入附加输入模式(如布局、关键点),GLIGEN引入了一种新的方法,该方法保持原始模型的权重不变,并集成新的、可训练的门控Transformer,以接受新的接地输入。所得到的模型不仅可以准确地表示接地条件,而且可以生成高质量的图像。值得注意的是,该模型在推理过程中也能很好地推广到看不见的物体。
2)自定义生成:文本到图像扩散模型的有效性受到用户通过文本描述阐明所需目标的能力的限制。例如,很难描述一辆创新玩具车的精确特征,而这在大型模型训练中是不会遇到的。因此,定制生成的目标是使模型能够从用户提供的图像的最小集合中掌握新概念。
SYSTEM DESIGN CHALLENGE FOR PEFT
A. System design for PEFT
在本节中,我们首先简要介绍基于云的PEFT系统。接下来,我们介绍了用于评估系统性能的相应指标。此外,我们还提出了三种潜在的利用场景,以说明系统设计中的挑战。
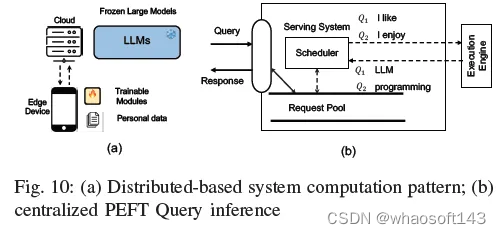
1) 集中式PEFT查询服务:云提供商最近推出了一系列LLM服务,旨在通过应用程序编程接口(API)提供用户应用程序。这些API有助于将许多ML功能无缝集成到应用程序中。在通过API接收到针对一个特定下游任务的一个查询之后,基于云的服务器使用一个特色LLM模型来处理该查询。在这种情况下,所提出的用于处理多个PEFT查询的云解决方案涉及仅存储LLM的单个副本和多个PETT模块。此单个副本维护多个PEFT模块分支,每个分支与不同的PEFT查询相关联。最先进系统的案例研究可在第VI-C节中找到。图10(b)说明了多查询PEFT推理的计算模式,其中打包PEFT查询根据其截止日期和当前系统条件进行调度和执行。
2) 服务指标:为了评估集中式PEFT查询服务的系统性能,我们提出了一组评估指标。
- 系统吞吐量:将PEFT查询视为内部任务和内部任务,我们使用每秒令牌来测量系统吞吐量。
- 内存占用:查询服务期间的运行时内存消耗,内存利用率来自模型参数和KV缓存,如第IV-A节所述。
- 准确性性能:真实世界的查询通常具有不同的上下文长度,具有变化长度的性能作为性能基准。
- 服务质量:查询与延迟要求相关,截止日期缺失率被视为另一个基准。
3) PEFT的分布式系统:然而,在当代LLM模型中,预先训练的模型并不完全支持个性化任务,因此,需要使用前面章节中提到的方法进行额外的微调。然而,当我们考虑将数据集提供给云提供商时,会引起一个很大的担忧,因为这些数据集是个性化的。
对于这个问题,我们假设我们的计算遵循模型集中式和PEFT分布式范式。骨干LLM存储在云设备中,而个人PEFT权重以及数据集存储在用户自己的设备中。如图10(a)所示。
4) 分布式度量:为了评估所提出方法的有效性,我们建立了一组评估度量。为了进行此分析,在不失一般性的情况下,我们采用语言模型作为度量定义的基础。
- 精度性能:微调模型在下游任务中的性能。
- 计算成本:在边缘设备上进行正向和反向传播操作期间的计算成本。
- 通信成本:指边缘设备和云之间传输中间数据时所涉及的数据量。
5) 多产品环境足迹培训:与多个产品环境足迹服务不同,使用多个定制产品环境足迹进行调整总是涉及不同的骨干LLM。当考虑在各种下游任务中使用LLM时,预先训练的模型通常表现出较差的性能。使LLM适应不同任务的一种流行方法涉及精心调整的PEFT。然而,同时调整多个PEFT可能会带来相当大的挑战。如何管理内存梯度和模型权重存储,以及如何设计用于批处理PEFT训练的高效内核等挑战仍未解决。产品环境足迹将根据其产品环境足迹算法和骨干LLM模型进行分类。设计挑战涉及如何同时将多个具有相同LLM主干和多个不同LLM主干的PEFT合并。
B. Parallel PEFT Training Frameworks
a) 设计挑战:与旨在适应灵活的多PEFT算法的PetS系统不同,SLoRA和Punica仅专注于促进各种任务的多个LoRA块。设计多个产品环境足迹培训系统主要面临两个方面的关键挑战 方面:
- 具有相同LLM主干的多个PEFT模型的高效并发执行。
- 设计一个高效的系统,用于不同LLM骨干网的多租户服务。
b)高效的内核设计:Punica解决了第一个挑战,将现有的矩阵乘法用于主干计算,并引入了一种新的CUDA内核——分段聚集矩阵矢量乘法(SGMV),用于以批处理的方式将PEFT附加项添加到主干计算中。该内核对批处理中不同请求的特征权重相乘进行并行化,并将对应于同一PEFT模型的请求分组,以增加操作强度并使用GPU张量核心进行加速。
第二个挑战超出了计算成本,设计一种高效的系统架构是另一个重大挑战,该架构可以在尽可能小的GPU集上有效地服务于多租户PEFT模型工作负载,同时占用最少的GPU资源。Punica通过将用户请求调度到已经服务或训练PEFT模型的活动GPU来解决这一问题,从而提高GPU利用率。对于较旧的请求,Punica会定期迁移它们以整合工作负载,从而为新请求释放GPU资源。
c)多租户PEFT设计:为Punica框架中的多租户PEVT模型设计一个高效的系统,重点是解决几个关键挑战,以最大限度地提高硬件利用率并最大限度地减少资源消耗。该系统旨在将多租户LoRA服务工作负载整合到尽可能小的GPU集上。这种整合是通过对已经在服务或训练LoRA模型的活动GPU的用户请求进行战略调度来实现的,从而提高GPU利用率。对于较旧的请求,Punica会定期迁移它们以进一步整合工作负载,从而为新请求释放GPU资源。它结合了LoRA模型权重的按需加载,只引入了毫秒级的延迟。该功能为Punica提供了将用户请求动态合并到一小组GPU的灵活性,而不受已经在这些GPU上运行的特定LoRA模型的约束。除此之外,Punica认为解码阶段是模型服务成本的主要因素,其设计主要侧重于优化解码阶段的性能。模型服务的其他方面利用直接的技术,例如按需加载LoRA模型权重,来有效地管理资源利用率。
结论和未来方向
在当前由大型模型和大型数据集主导的时代,PEFT是一种非常有吸引力的方法,可以有效地使模型适应下游任务。这项技术通过解决传统的全模型微调带来的重大挑战而获得吸引力,这种微调通常会给普通用户带来难以维持的计算和数据需求。本调查对PEFT的最新进展进行了系统回顾,涵盖算法开发、计算和效率方面、应用和系统部署。它提供了一个全面的分类和解释,作为一个很好的指导和知识库,使不同级别和学科的读者能够迅速掌握PEFT的核心概念。
为了进一步研究PEFT,我们从算法和系统的角度提出了一系列可能的方向,希望能激励更多的研究人员在这些领域进行进一步的研究。
A. Simplify hyperparameter tuning
PEFT的有效性通常对其超参数敏感,如适配器的瓶颈尺寸r、LoRA的等级和不同附加PEFT层的位置。手动调整这些超参数将花费大量精力。因此,未来的工作可以集中在开发不太依赖手动调整这些参数的方法,或者自动找到最佳超参数设置。一些研究已经开始解决这个问题,但需要更简单有效的解决方案来优化这些超参数。
B. Establish a unified benchmark
尽管存在像HuggingFace的PEFT和AdapterHub这样的库,但仍然缺乏一个全面的PEFT基准。这种差距阻碍了公平比较不同PEFT方法的性能和效率的能力。一个被广泛接受的、类似于物体检测的MMDetection的最新基准将使研究人员能够根据一组标准的任务和指标来验证他们的方法,从而促进社区内的创新和合作。
C. Enhance training efficiency
PEFT的假定参数效率并不总是与训练期间的计算和内存节省一致。考虑到可训练参数在预训练模型的体系结构中相互交织,在微调过程中通常需要计算和存储整个模型的梯度。这种监督要求重新思考什么是效率。如第四节所述,潜在的解决方案在于模型压缩技术的集成,如修剪和量化,以及专门为优化PEFT调整期间的内存而设计的创新。进一步研究提高PEFT方法的计算效率势在必行。
D. Explore scaling laws
最初为较小的Transformer模型开发的PEFT方法的设计和有效性不一定与较大的模型相适应。随着基础模型规模的增加,识别和调整保持有效的产品环境足迹战略至关重要。这一探索将有助于根据大型模型架构的发展趋势定制PEFT方法。
E. Serve more models and tasks
大型基础模型在各个领域的兴起为PEFT提供了新的机会。设计适合模型独特特征的PEFT方法,如Sora、Mamba和LVM,可以释放新的应用场景和机会。
F. Enhancing data privacy
信任集中式系统来服务或微调个性化PEFT模块是系统开发人员的另一个问题。侧通道攻击者已成功部署,通过劫持中间结果来重建用户的数据。未来值得信赖的LLM系统设计的一个视角涉及为个人数据以及中间训练和推理结果开发加密协议。
G. PEFT with model compression
模型压缩是使LLM在资源有限的设备上可执行的最有效方法之一。然而,模型压缩技术对在硬件上运行的PEFT算法性能的影响仍然是另一个系统性挑战。量化和修剪等常见的压缩技术需要专用的硬件平台来加快过程,而为压缩模型构建这样的硬件平台是研究人员的另一个方向。















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









