







在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题。可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。

为了克服上述的问题,项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。redis技术就是NoSQL技术中的一种,但是引入redis又有可能出现缓存穿透,缓存击穿,缓存雪崩,数据库与缓存一致性等问题。本文就这些问题进行较深入剖析。感兴趣的小伙伴可以点击下方链接跟着3y学习redis。
1、缓存穿透
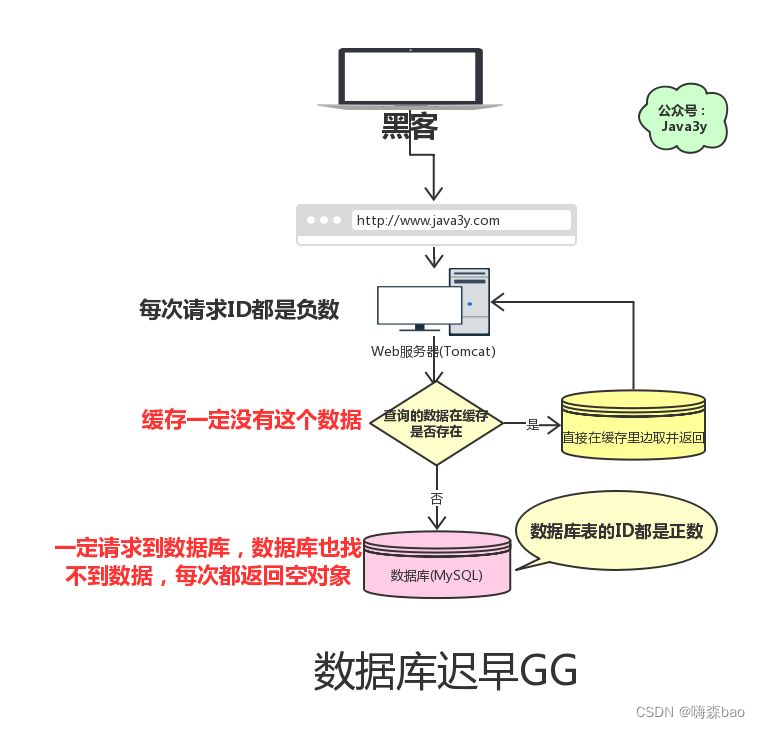
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。例如持续请求null值、id为负数的订单信息等。
解决方案:
- 最常见的则是采用
布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。 - 将不存在的key对象缓存起来,实现简单。但会存在如下问题:
- 一是空值做缓存,意味着缓存中存了更多的key-value,也就是需要更多空间(有人说空值没多少,但是架不住多啊),解决方法是我们可以设置一个较短的过期时间。
- 二是数据会有一段时间窗口的不一致,假如,Cache设置了5分钟过期,此时Storage确实有了这个数据的值,那此段时间就会出现数据不一致,解决方法是我们可以利用消息或者其他方式,清除掉Cache中的数据。但这样会造成系统的复杂性增加。
| 解决缓存穿透 | 适用场景 | 维护成本 |
|---|---|---|
| 缓存空对象 | 1. 数据命中不高; 2. 数据频繁变化实时性高 | 1. 代码维护简单; 2. 需要过多的缓存空间; 3. 数据不一致 |
| BloomFilter或者压缩filter提前拦截 | 1. 数据命中不高; 2. 数据相对固定实时性低 | 1. 代码维护复杂; 2. 缓存空间占用少 |
TODO:布隆过滤器解决缓存击穿案例实战
布隆过滤器是一个bit数组,一个很长的bit数组和一系列的hash函数构成,更准确的说是一种概率型的数据结构,它能判断某个元素一定不存在或者是可能存在。
深入了解布隆过滤器推荐博文:
2、缓存击穿
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存击穿这里强调的是并发,造成缓存击穿的原因有以下两个:
- 添加到了缓存,reids有设置数据失效的时间 ,这条数据刚好失效,大并发访问(热点数据)
- 该数据没有人查询过 ,第一次就大并发的访问。(冷门数据)
解决方案:使用互斥锁(mutex key),简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
3、缓存雪崩
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
造成缓存雪崩的原因,有以下两种:
- reids宕机
- 大部分数据失效
解决方案:
- 设置不同的过期时间,防止同一时间内大量的key失效
//伪代码
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//缓存标记
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//获取缓存值
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //未过期,直接返回
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//这里一般是 sql查询数据
cacheValue = GetProductListFromDB();
//日期设缓存时间的2倍,用于脏读
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
}
解释说明:
缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
- 加锁,对大并发请求做限流,将其中一个作失效处理后重新写入缓存后,就能使其余请求命中缓存,从而避免雪崩

流程是这样子的,在多个请求同时到达业务系统时候,只能有一个线程能获取到锁,然后才能继续去缓存或者是数据库中查询数据,然后后面的流程和之前的是一样的,执行完成后释放锁,然后其他线程再争抢锁,然后重复前面的流程。
这个就是在缓存中如果获取不到,再去串行的访问数据看,这里不一定非要串行,可以配合线程池,控制一定的并发数。
其它优化手段:
- 缓存预热:所谓缓存预热就是将一些可能经常使用数据在系统启动的时候预先设置到缓存中,这样可以避免在使用到的时候先去数据库中查询
- 缓存降级:系统可以根据一些关键数据进行自动降级,降级的最终目的是保证核心服务可用,即使是有损的。但是有的一些业务的核心服务是不能降级的
4、缓存一致性保证
缓存与数据库双写会造成什么问题呢?
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
这里不一致指的是:数据库的数据跟缓存的数据不一致
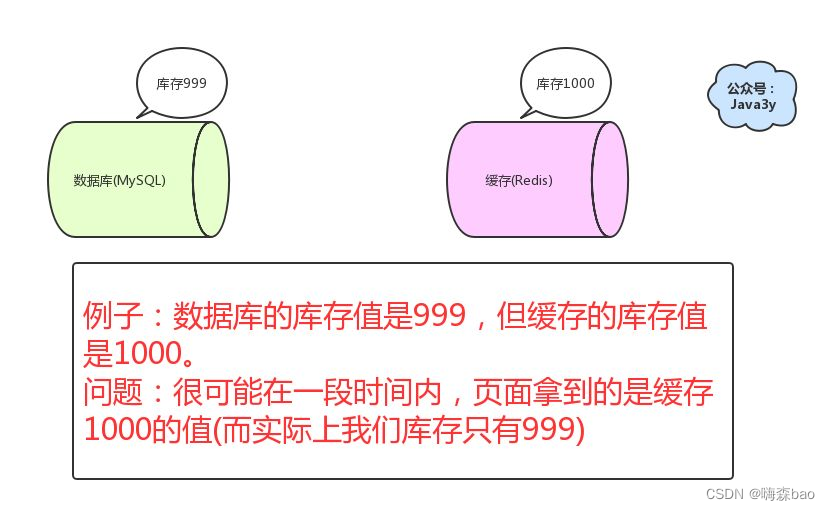
从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来尽量避免数据库与缓存处于不一致的情况发生。
对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
-
先操作数据库,再操作缓存
-
先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个分布式事务的问题。
所以,如果原子性被破坏了,可能会有以下的情况:
-
操作数据库成功了,操作缓存失败了。
-
操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下吧。
1)操作缓存
操作缓存也有两种方案:
-
更新缓存
-
删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
-
高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接简单很多)
-
如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
基于这两点,对于缓存在更新时而言,都是建议执行删除操作!
2)先更新数据库,再删除缓存
正常的情况是这样的:
-
先操作数据库,成功;
-
再删除缓存,也成功;
如果原子性被破坏了:
-
第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
-
如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
-
缓存刚好失效
-
线程A查询数据库,得一个旧值
-
线程B将新值写入数据库
-
线程B删除缓存
-
线程A将查到的旧值写入缓存
要达成上述情况,还是说一句概率特别低!
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
对于这种策略,其实是一种设计模式:Cache Aside Pattern

删除缓存失败的解决思路:
-
将需要删除的key发送到消息队列中
-
自己消费消息,获得需要删除的key
-
不断重试删除操作,直到成功
3)先删除缓存,再更新数据库
正常情况是这样的:
-
先删除缓存,成功;
-
再更新数据库,也成功;
如果原子性被破坏了:
-
第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
-
如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
-
线程A删除了缓存
-
线程B查询,发现缓存已不存在
-
线程B去数据库查询得到旧值
-
线程B将旧值写入缓存
-
线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
并发下解决数据库与缓存不一致的思路:
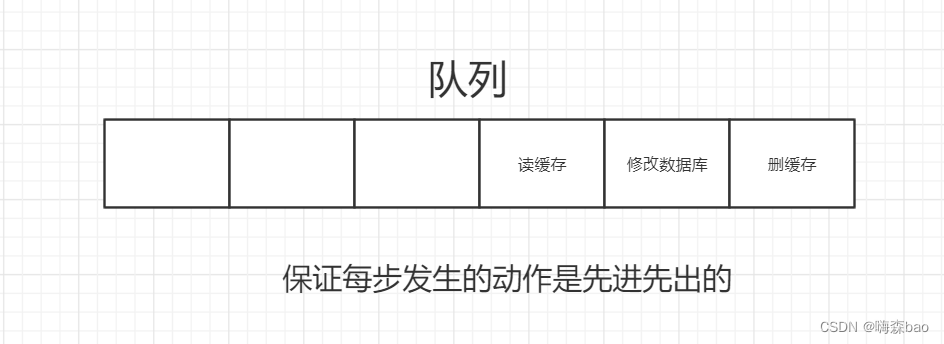
- 将删除缓存、修改数据库、读取缓存等的操作积压到队列里边,实现串行化。
对比两种策略(从原子性及高并发场景下的表现来说)
我们可以发现,两种策略各自有优缺点:
- 先更新数据库,再删除缓存(Cache Aside Pattern设计模式)
- 在高并发下表现优异,在原子性被破坏时表现不如意
- 先删除缓存,再更新数据库
- 在高并发下表现不如意,在原子性被破坏时表现优异
其它保障数据一致性的方案及资料
最后,文章参考3y 关于面试前必须要知道的Redis面试题 博文。
希望大家看完有所帮助,顺利拿到offer!















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









