







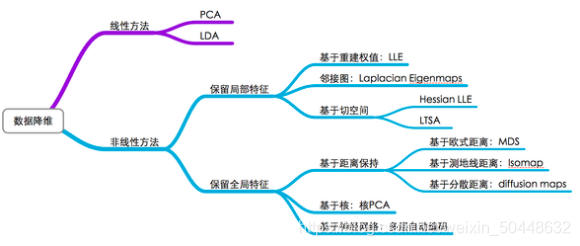
1.1.分类
关于降维的学习主要分为五类:PCA、LDA、LLE、tSNE、ISOMAP
.降维的作用:(为什么会有这些作用?)
(1)降低时间的复杂度和空间复杂度
(2)节省了提取不必要特征的开销
(3)去掉数据集中夹杂的噪音
(4)较简单的模型在小数据集上有更强的鲁棒性
(5)当数据能有较少的特征更好地解释数据,适合我们可以提取知识
(6)实现数据的可视化
1.3.降维的目的
用来进行特征选择和特征提取。
①特征选择:选择重要的特征子集,删除其余特征;
②特征提取:由原始特征形成的较少的新特征。
在特征提取中,我们要找到k个新的维度的集合,这些维度是原来k个维度的组合,这个方法可以是监督的,也可以是非监督的,如PCA是非监督的,LDA是监督的。
标题1.4.子集选择
对于n个属性,有2n个可能的子集。穷举搜索找出属性的最佳子集可能是不现实的,特别是当n和数据类的数目增加时。通常使用压缩搜索空间的启发式算法,通常这些方法是典型的贪心算法,在搜索属性空间时,总是做看上去是最佳的选择。他们的策略是局部最优选择,期望由此导致全局最优解。在实践中,这种贪心方法是有效的,并可以逼近最优解。
1.5.降维的本质:
学习一个映射函数f:x到y。(x是原始数据点的表达,目前最多的是用向量来表示,Y是数据点映射后的低维向量表达。)f可能是:显示的、隐式的、线性的、非线性的。
1.6.主成分分析PCA(principal Component Analysis)
1.6.1.PCA的作用
1、聚类:把复杂的多维数据点,简化成少量数据点,易于分簇
2、降维:降低高维数据,简化计算,达到数据降维,压缩,降噪目的
1.6.2.PCA的目的
1、将原有的d维数据集,转换成k维的数据,k<d;
2、 新生成的k维数据尽可能多的包含原来d维的信息
【例】二维降到一维的问题,要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录
【注】数据降维,要找投影之后的数据更加分散的方式来进行数据降维
这种分散程度,在数学上用方差来表述,方差越大表明该变量的变异越大。
【所以】PCA的目的是找到一个线性变化,让数据投影的方差最大化
1.6.3.过程

在PCA中,数据从原来的坐标系转换到新的坐标系,由数据本身决定。**转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。**第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向。重复该过程,重复次数为原始数据的特征维数。
1.6.4.性质
1、缓解维度灾难:PCA 算法通过舍去一部分信息之后能使得样本的采样密度增大(因为维数降低了),这是缓解维度灾难的重要手段;
2、降噪:当数据受到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到降噪的效果;
3、过拟合:PCA 保留了主要信息,但这个主要信息只是针对训练集的,而且这个主要信息未必是重要信息。有可能舍弃了一些看似无用的信息,但是这些看似无用的信息恰好是重要信息,只是在训练集上没有很大的表现,所以 PCA 也可能加剧了过拟合;
4、特征独立:PCA 不仅将数据压缩到低维,它也使得降维之后的数据各特征相互独立;
1.6.5.数学支撑
(1)内积
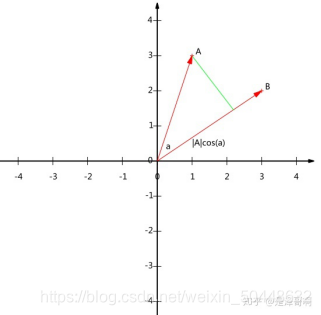
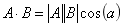
若
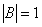
,则
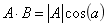
也就是说,A 与 B 的内积值等于 A 向 B 所在直线投影的标量大小。
注意投影是一个标量,所以可以为负。
(2)基
对于向量 (3, 2) 来说,如果我们想求它在 (1,0),(0,1) 这组基下的坐标的话,分别内积即可。当然,内积完了还是 (3, 2)。
所以,我们大致可以得到一个结论,我们要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。为了方便求坐标**,我们希望这组基向量模长为 1**。因为向量的内积运算,当模长为 1 时,内积可以直接表示投影。然后还需要这组基是线性无关的,我们一般用正交基,非正交的基也是可以的,不过正交基有较好的性质。
(3)基变换的矩阵表示


上述分析给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列向量
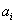
变换到左边矩阵中以每一行行向量为基所表示的空间中去。
也就是说一个矩阵可以表示一种线性变换。
(4)最大可分性
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,如果基的数量少于向量本身的维数,则可以达到降维的效果。
但是我们还没回答一个最关键的问题:如何选择基才是最优的。或者说,如果我们有一组 N 维向量,现在要将其降到 K 维(K 小于 N),那么我们应该如何选择 K 个基才能最大程度保留原有的信息?
一种直观的看法是:希望投影后的投影值尽可能分散,因为如果重叠就会有样本消失。当然这个也可以从熵的角度进行理解,熵越大所含信息越多。
(5)方差
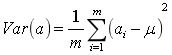
均值为0时候
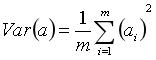
于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
(6)协方差
在一维空间中我们可以用方差来表示数据的分散程度。而对于高维数据,我们用协方差进行约束,协方差可以表示两个变量的相关性。
为了让两个变量尽可能表示更多的原始信息,我们希望它们之间不存在线性相关性,因为相关性意味着两个变量不是完全独立,必然存在重复表示的信息。
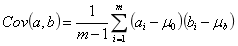
由于均值为0
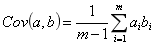
当样本数较大时,不必在意其是 m 还是 m-1,为了方便计算,我们分母取 m。
当协方差为 0 时,表示两个变量线性不相关。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上进行选择,因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标:将一组 N 维向量降为 K 维,其目标是选择 K 个单位正交基,使得原始数据变换到这组基上后,各变量两两间协方差为 0,而变量方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
PCA推导——最大方差理论
在信号处理中认为信号具有较大的方差,噪音具有较小的方差,信噪比越大越好。
(7)协方差矩阵

(8)矩阵对角化
根据我们的优化条件,我们需要将除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列(变量方差尽可能大),这样我们就达到了优化目的。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系

由上文知道,协方差矩阵 C 是一个是对称矩阵,在线性代数中实对称矩阵有一系列非常好的性质:
A.实对称矩阵不同特征值对应的特征向量必然正交。
B.设特征向量 重数为 r,则必然存在 r 个线性无关的特征向量对应于 ,因此可以将这 r 个特征向量单位正交化。

P 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 C 的一个特征向量。如果设 P 按照中特征值的从大到小,将特征向量从上到下排列,则用 P 的前 K 行组成的矩阵乘以原始数据矩阵 X,就得到了我们需要的降维后的数据矩阵 Y。
CA遵循投影后的样本点间方差最大原则。
如何选择n才能最大程度的保留原有的信息?
一种直观的看法是:希望投影后的投影值尽可能分散,因为如果重叠就会有样本消失。当然这个也可以从熵的角度进行理解,熵越大所含信息越多。
寻找一个基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
参考链接:https://www.bilibili.com/video/BV1ME411T7tV?p=3
https://blog.csdn.net/yangleo1987/article/details/52845912
https://wjrsbu.smartapps.cn/zhihu/article?id=77151308&isShared=1&hostname=baiduboxapp&_swebfr=1














 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









