






比方说,我现在想爬实时更新:新型冠状病毒肺炎疫情地图 (baidu.com)里面美国日增病例数据,但这里面美国日增数据是以线图的形式展现的,如图
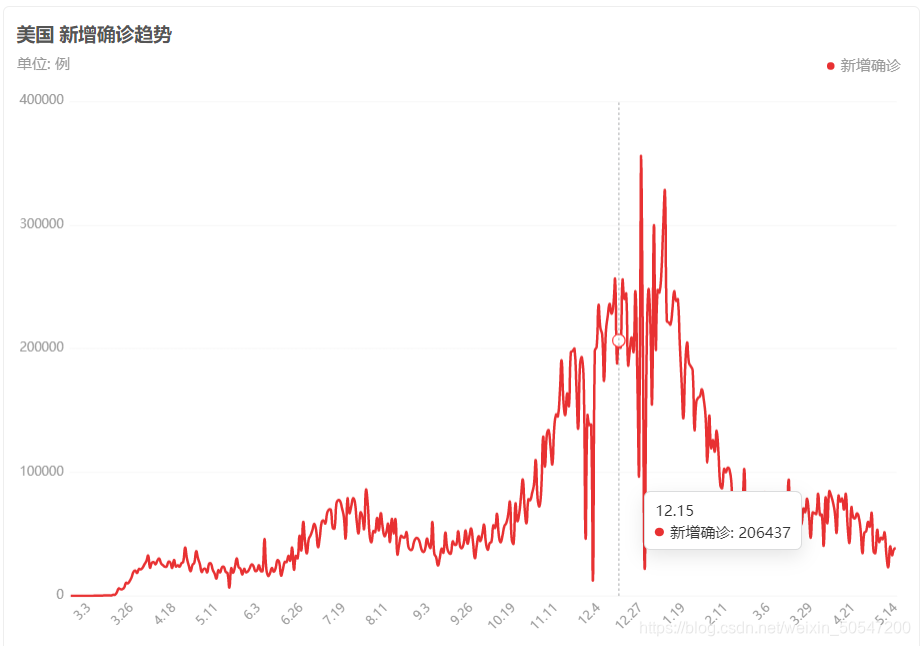
所以我们要先分析一下它的html文本内容,看看网页有没有完整的线图中的数据,首先用如下代码获得网页的html
import requests as rq #获得网页的html
from bs4 import BeautifulSoup #利用soup进行指定搜索
url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner&city=美国-美国'
html = rq.get(url,timeout=30)
html.raise_for_status
html.encoding = html.apparent_encoding #防止出现中文乱码
print(html.text)翻到下图这个位置,可以看到日期数据:
这里面还可以看到很多unicode代码,用Unicode翻译器就可以发现上面的代码表示一些关键字,如地名等。再往下拖,可以看到病例数据:

这里最大病例数是103986,很明显就是国内数据了。说明虽然我们网页url输入的是美国的页面,但其实包含了这个网站所有的数据。我们只需要找到美国对应的部分就行了。这个html很明显除了数据部分,还有很多其他的内容,我们只需要数据部分,怎么做呢?用beautifulSoup的查找功能即可,查找数据所对应的tag。先将页面网上拖,拖到数据开始的tag,如下图所示:
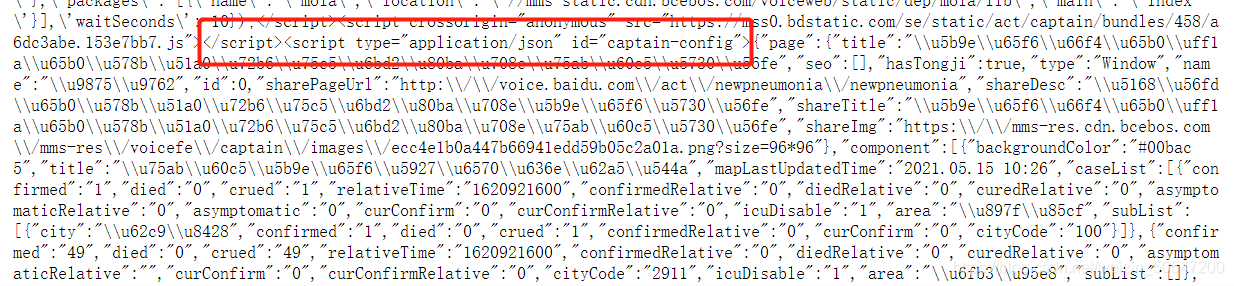
可以看到数据部分是从红圈中这个tag开始的,红圈之后就是字典了,而且是字典里面还有很多字典。。用soup搜索到这部分内容,注意script这个关键字在非数据部分也出现,所以要用id搜索:
soup = BeautifulSoup(html.text,'html.parser')
script = soup.find_all('script',id="captain-config")
print(script)
得到如下结果,这里面包含了该网页所用到的所有数据。

但是这个script的类型是bs4.element.ResultSet. 先取出其中的字符串部分(也就是去除前面那<>括号里的那部分),再用json载码数据, 得到输出的y结果如下:
import json as js
for item in script[0]:
y = js.loads(item)
现在我们只要找到美国的数据就行了。这个字典里嵌套的字典太多,先搞清楚第一层字典有几个关键字。下图可以看到,数据全都在component里面。同时也可以看到,经过json解码数据,所有的Unicode代码都显示为汉字了。图里显示的这块为国内数据。
for key in y:
print(key)
print(y[key])
print('\n')
接下来我们逐个检查component中关于美国日增数据并作图,具体代码和结果如下:
component = y['component']
component = component[0]
for key in component:
print(key)
print(component[key],'\n')
trend = component['topCountryAddTrend']
for key in trend:
print(key)
print(trend[key],'\n')
topcountry = trend['list']
date = trend['updateDate']
for i in range(len(topcountry)):
if topcountry[i]['name'] == '美国':
america = topcountry[i]
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure(dpi=300,figsize=(12,6)) #设置像素大小
plt.plot(america['data'])
a = list(range(len(date)))
plt.xticks(a,date)
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(20))#设置X轴间隔20个数值显示一次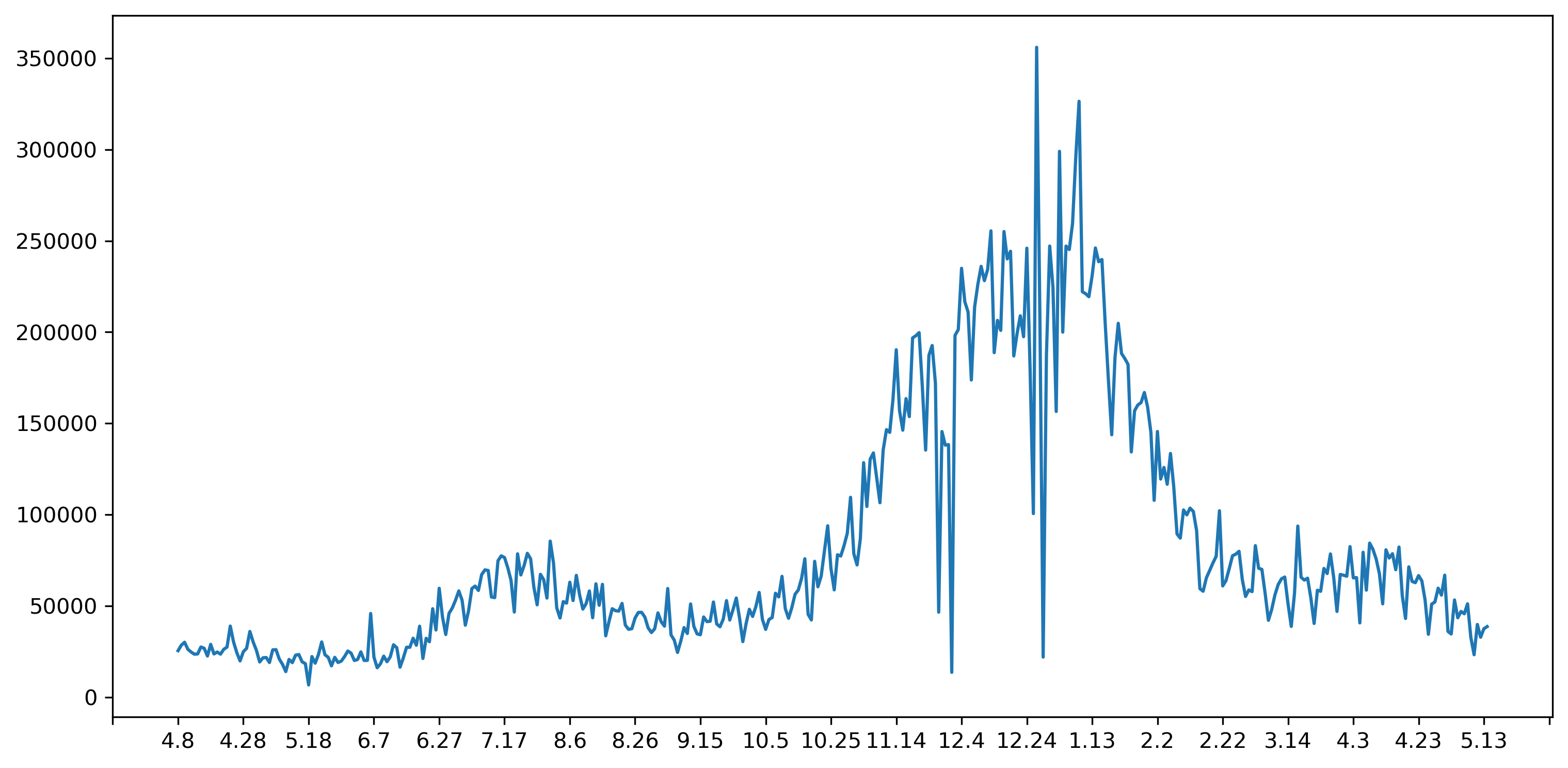
如有疑问,可在评论区讨论,笔者自己也是python初学者。














 3588
3588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









