






 本文详细介绍了Python中的库概念,重点讲解了标准库和第三方库的区别,特别是urllib模块,包括其发送HTTP请求、解析URL、处理响应状态码以及下载文件的功能。通过实例展示了如何使用urllib进行HTTP请求和参数编码。
本文详细介绍了Python中的库概念,重点讲解了标准库和第三方库的区别,特别是urllib模块,包括其发送HTTP请求、解析URL、处理响应状态码以及下载文件的功能。通过实例展示了如何使用urllib进行HTTP请求和参数编码。
一、Python库的概念
python库(library)是指一组相关的模块和函数,用于提供特定领域或功能的支持。Python标准库和第三方库都属于Python库,以后会遇到很多python库。这些库是经过开发人员编写和测试的可重用代码集合。这些库提供了各种常用的函数、类、工具和算法,能够快速解决实际问题和加速开发过程。我们也可以自行编写并发布自己的库。
python库分为:
●标准库:Python官方提供的库,已经包含在Python解释器中,无需安装。Python标准库是指Python官方提供的、包含在Python解释器里的多个模块和包。这些模块和包提供了许多常用的功能,例如文件操作、网络通信、GUI开发、数据处理等等,可以直接在代码中使用。
Python标准库中的模块和函数都经过严格测试和验证,确保其稳定性和可靠性。因此,在实际开发中,我们通常会优先使用Python标准库提供的功能,而不是自己编写代码实现同样的功能。这不仅可以节省时间和精力,还可以提高代码的可维护性和可重用性。
●第三方库:由其他开发者提供的库,需要通过pip等包管理工具单独安装。
二、urllib简介
urllib是Python标准库中的一个模块,它包含了很多用于处理URL的功能。常见的用法包括发送HTTP请求、读取和解析网页内容等。具体来说,urllib模块中包含以下子模块:
urllib子模块:
●urllib.request: 用于发送HTTP请求和获取响应,支持HTTP、HTTPS和FTP协议。
●urllib.error: 包含与HTTP错误相关的异常类。
●urllib.parse: 用于解析和操作URL,例如解析URL参数。
●urllib.robotparser: 用于解析robots.txt文件,该文件告诉网络爬虫哪些页面可以访问。
三、发送HTTP请求
urllib.request模块提供了以下函数用于发送HTTP请求:
urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, *, cafile=None, capath=None, cadefault=False, context=None)
#打开一个URL并返回响应对象。可选参数包括POST数据、超时时间、证书文件等
参数解释:
●url:必需,表示请求的URL地址,可以是一个字符串类型或者一个请求对象。
●data:可选,表示要发送的POST数据,需要以字节流(bytes)形式传递。如果不指定该参数,则默认为GET请求。
●timeout:可选,表示请求超时时间,单位为秒,默认值为None,即永远等待服务器响应。
●cafile:可选,表示SSL证书认证文件路径,通常为.pem文件,用于验证HTTPS请求的合法性。如果不指定该参数,则使用系统默认设置。
●capath:可选,表示SSL证书认证文件夹路径,通常为.pem文件夹,用于验证HTTPS请求的合法性。如果不指定该参数,则使用系统默认设置。
●cadefault:可选,如果设置为True,则使用系统默认的证书位置进行认证,否则需要指定cafile或capath参数。
●context:可选,表示SSL上下文,在处理HTTPS请求时需要使用,用于指定证书和协议等信息。
四、解析HTTP响应
urllib.request.urlopen()函数返回的响应对象包含了以下方法和属性:
●response.read([size]): 读取响应内容,可选参数指定最多读取的字节数。
●response.readline(): 读取一行响应内容。
●response.readlines([sizehint]): 读取所有响应内容并以列表形式返回,每个元素是一行响应内容。
●response.getcode(): 获取HTTP状态码。
200 OK:请求成功
201 Created:成功创建新资源
204 No Content:请求已成功处理,但没有内容返回
301 Moved Permanently:请求的URL已移动到新地址
302 Found:请求的URL临时转移到其他地址
304 Not Modified:请求的资源未被修改,可以直接使用缓存数据
400 Bad Request:请求参数有误,服务器无法解析请求
401 Unauthorized:请求需要用户认证或者认证失败
403 Forbidden:请求被拒绝访问,通常是因为权限不足
404 Not Found:请求的资源不存在
500 Internal Server Error:服务器出现内部错误
除了以上状态码之外,HTTP协议还定义了很多其他的状态码,例如502 Bad Gateway、503 Service Unavailable等等。在处理HTTP请求和响应时,我们需要通过判断响应状态码来确定HTTP请求是否成功,并根据响应状态码进行下一步操作。
●response.headers: 响应头信息,是一个类字典对象,提供了各种方法来访问头信息。
●response.info(): 获取响应头信息,等价于response.headers。
●response.geturl(): 获取实际请求的URL,可能与原始请求的URL不同。
五、下载文本、图片和视频等文件
**urllib.request.retrieve()**是Python标准库中的一个函数,用于下载文件并保存到本地。该函数有两个参数:
●url:必需,表示要下载的文件的URL地址。
●filename:可选,表示文件保存路径和名称。如果不指定该参数,则使用默认的文件名。
除了以上参数之外,urllib.request.retrieve()函数还支持以下两个参数:
●reporthook: 可选,回调函数,每次读取块时都会调用此函数。该函数通常用于显示下载进度等信息。
●data:可选,POST数据,需要以字节流(bytes)形式传递。
import urllib.request
url="https://www.baidu.com/img/flexible/logo/pc/index@2.png"
name="D:/图片/1.png"
urllib.request.urlretrieve(url,name)
此时在本地路径D:/图片/1.png下会有百度的logo图片被命名为1.png

六、urllib的parse函数
urllib.parse是Python标准库中的一个模块,用于URL解析、编码和构造相关的操作。该模块包含了各种与URL相关的函数和类,可以方便地进行URL参数解析、拼接、编码和反编码等操作。
1、urlencode函数
urllib.parse.urlencode()是Python标准库中的一个函数,用于将字典类型或包含键值对元组的可迭代对象编码为URL参数。在HTTP请求和URL参数传递过程中,我们需要将数据转换为URL安全格式,并拼接到URL地址后面进行传递,此时就可以使用urlencode()函数进行编码
该函数有一个必需参数params,表示要编码的字典类型或可迭代对象(如列表、元组等)。除此之外,还有三个可选参数:
●doseq:表示是否需要将相同参数名的多个值都编码并拼接到URL参数中,默认值为False。
●safe:表示不需要编码的字符,可以是字符串类型或者字节流(bytes)类型。默认值为/,表示/字符不需要编码。
●encoding:表示原始字符串的编码方式,默认值为utf-8。
urllib.parse.urlencode()函数将字典类型或可迭代对象中所有的键值对按照key=value的格式进行拼接,并将其编码为URL安全格式。例如:
import urllib.parse
2
a={
3
'name':'Tom',
4
'age':20
5
}
6
b=urllib.parse.urlencode(a)
7
url="https://example.com/search?" + b
8
print(url)
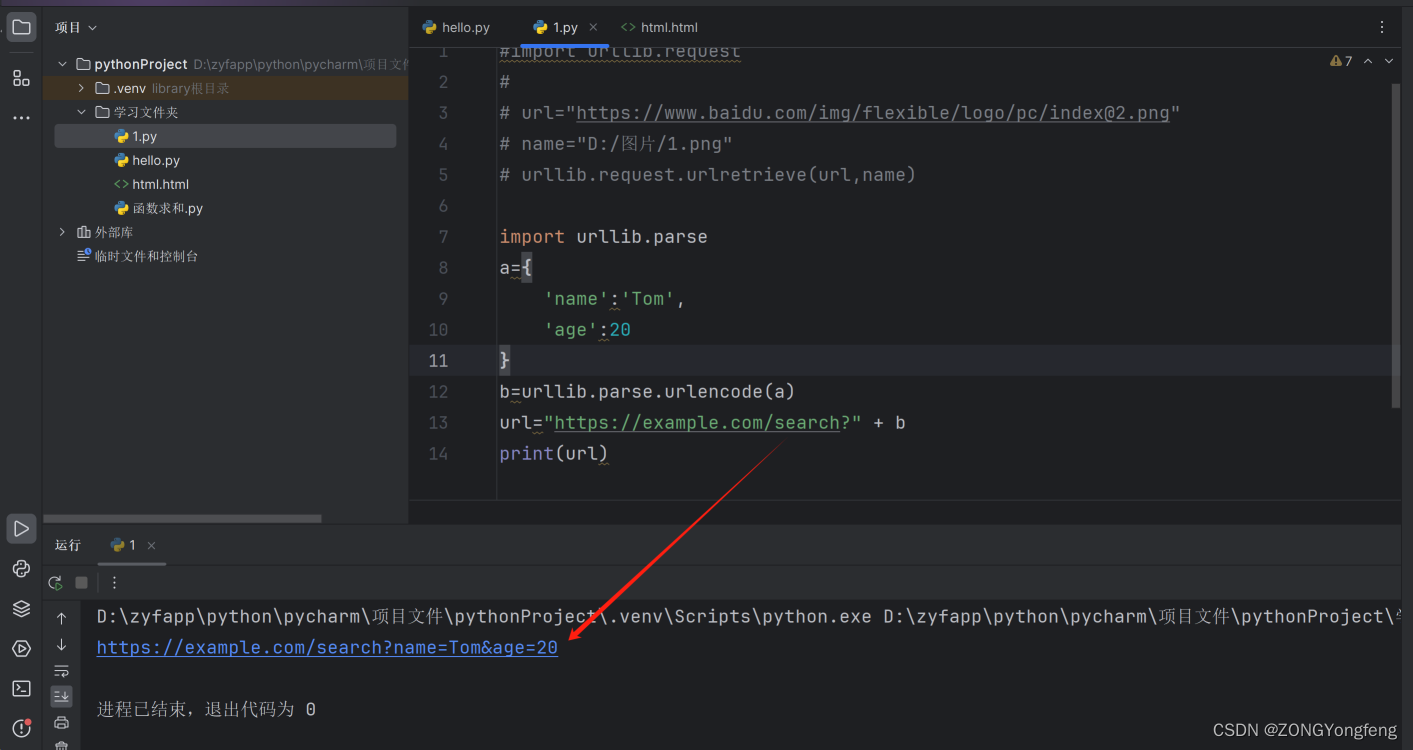
以上代码将params字典类型的数据编码为URL参数,并拼接到URL地址后面,生成了一个完整的URL地址。在构造URL时,我们通常需要使用urllib.parse.urlencode()函数将URL参数进行编码,以确保URL的正确性和安全性。
2、urlencode.encode函数
urllib.parse.urlencode(params).encode()方法将字符串类型的数据编码为bytes类型,例如:
data = 'name=Alice&age=20'
encoded_data = data.encode()
print(encoded_data)
#输出结果:
b'name=Alice&age=20'
当我们需要使用POST方法向服务器传递数据时,通常需要将数据编码为bytes类型。因此,可以将urlencode()函数和encode()方法结合使用,将字典类型的数据编码为bytes类型的数据,例如:
import urllib.parse
params = {'name': 'Alice', 'age': 20}
encoded_params = urllib.parse.urlencode(params).encode()
以上代码将字典类型的params数据编码为URL参数形式的字符串,并将其转换为bytes类型的数据encoded_params。在实际开发中,我们可以根据具体需求选择合适的参数和方式,完成HTTP请求和URL参数的编码和解码工作。
综合示例:
import urllib.request
import http.client
import urllib.parse
#请求地址,打印请求状态码
ststus=urllib.request.urlopen('http://www.weather.com.cn/') # type: http.client.HTTPResponse
#获得状态码并打印
a=ststus.getcode()
print(type(a))
if a == 200:
print(f'请求成功,状态为:{a}')
# 开始查找城市天气
city = {
'name': '郑州',
'time': '2024-03-06'
}
# 将字典类型的数据data转换为URL参数形式的字符串,同时转换为bytes
data = urllib.parse.urlencode(city).encode()
print("进入网址开始查找----->")
weather = urllib.request.Request(url='https://api.asilu.com/weather/', data=data)
b=weather.add_header('User-Agent', 'Mozilla/5.0')
#print(b)
response = urllib.request.urlopen(weather)# type: http.client.HTTPResponse
#获取相应内容,并转换编码
c=response.read().decode()
#获取城市名字
d=city['name']
print(f'{d}的天气如下:{c}')
else:
print(f'请求出错,请重新尝试!{a}')


















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









