







Introduction of ELMO, BERT, GPT
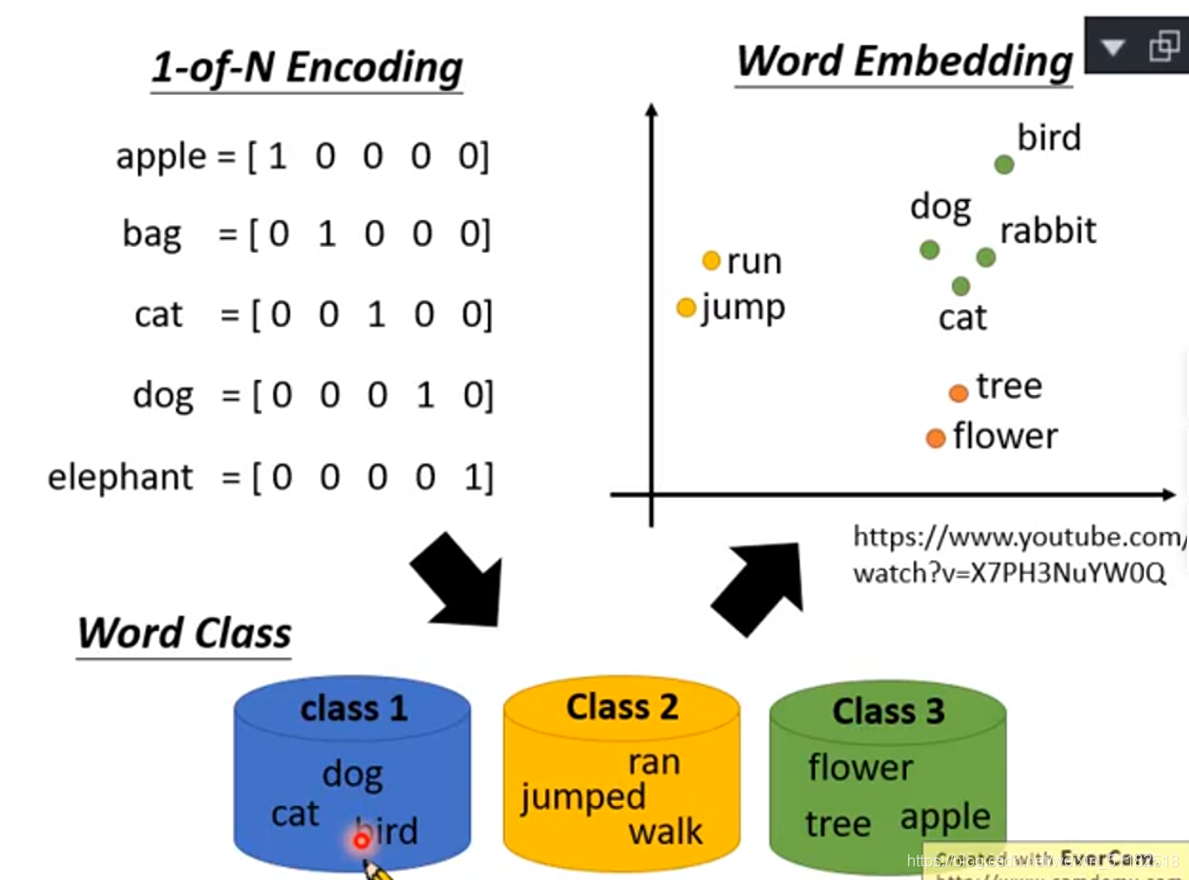
词嵌入:将每一个词用一个向量表示,语意相近的词他们的向量在控件的位置会比较接近。
解决一词多义的问题
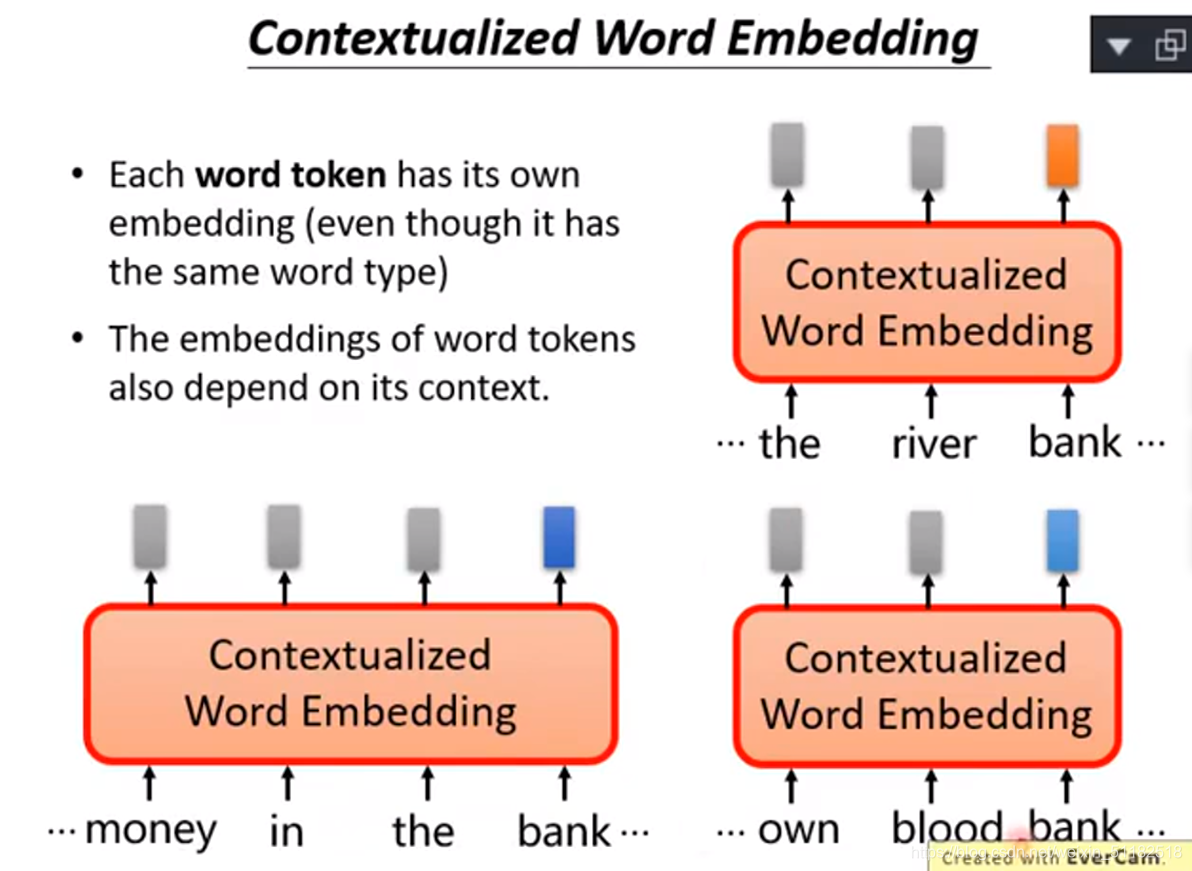
根据词所在文本的上下文
1、EMLO Embeddings from Language Model
Contextualized word embedding
根据上一个词预测下一个词是什么,RNN之间的hidden layer就是当前输入词汇的contextualized word embedding
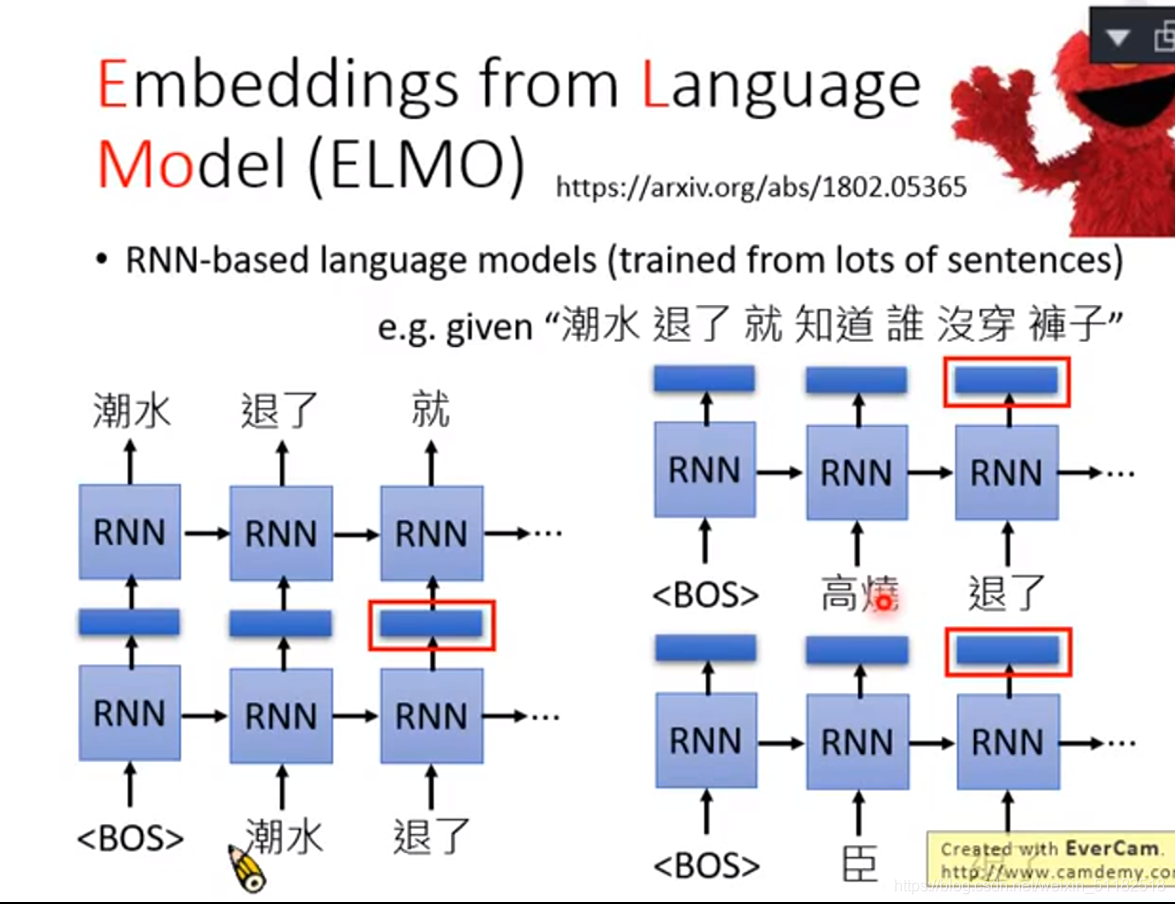
退了这个词前面可能有其他不同的输入,由于它之前读过的embedding不同,所以输出的也不一样。
反向rnn
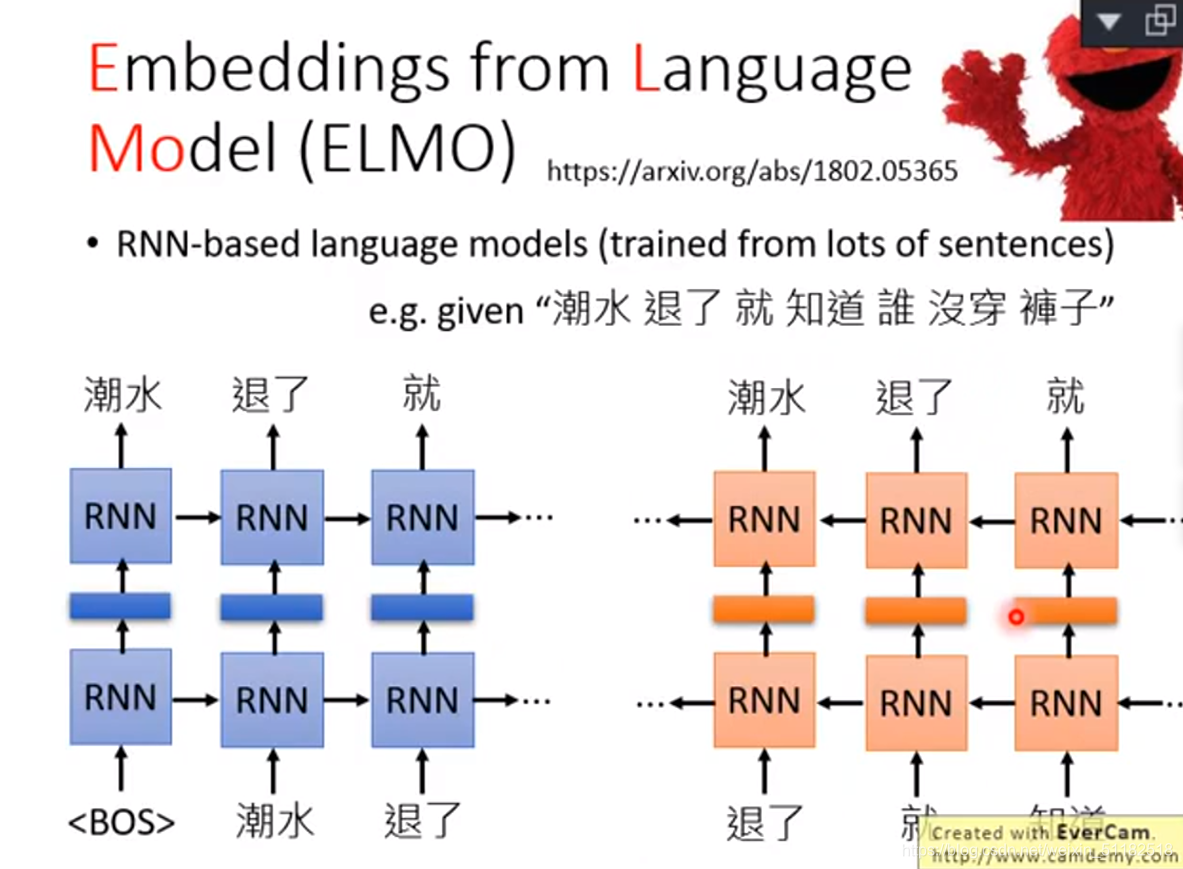
deep rnn
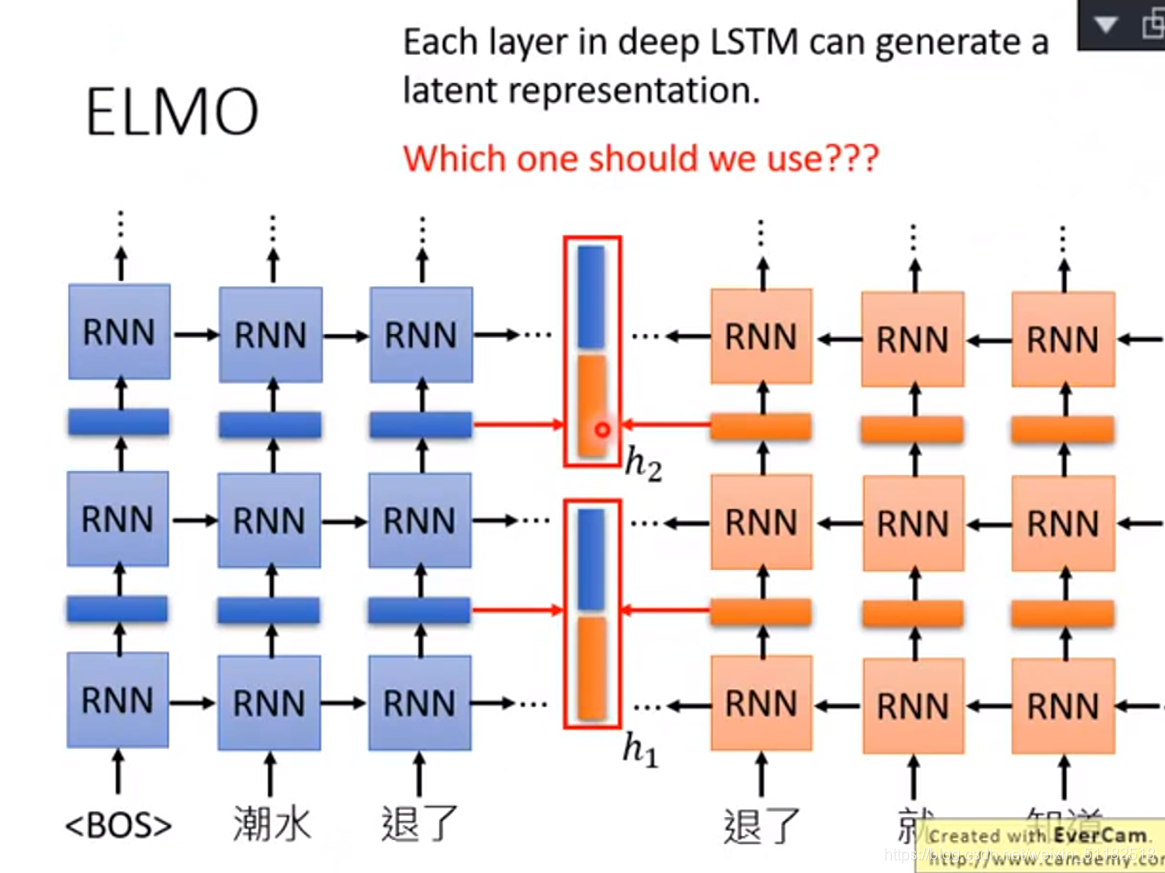
- token:原始词
- lstm-1:第一层
- lstm-2:第二层
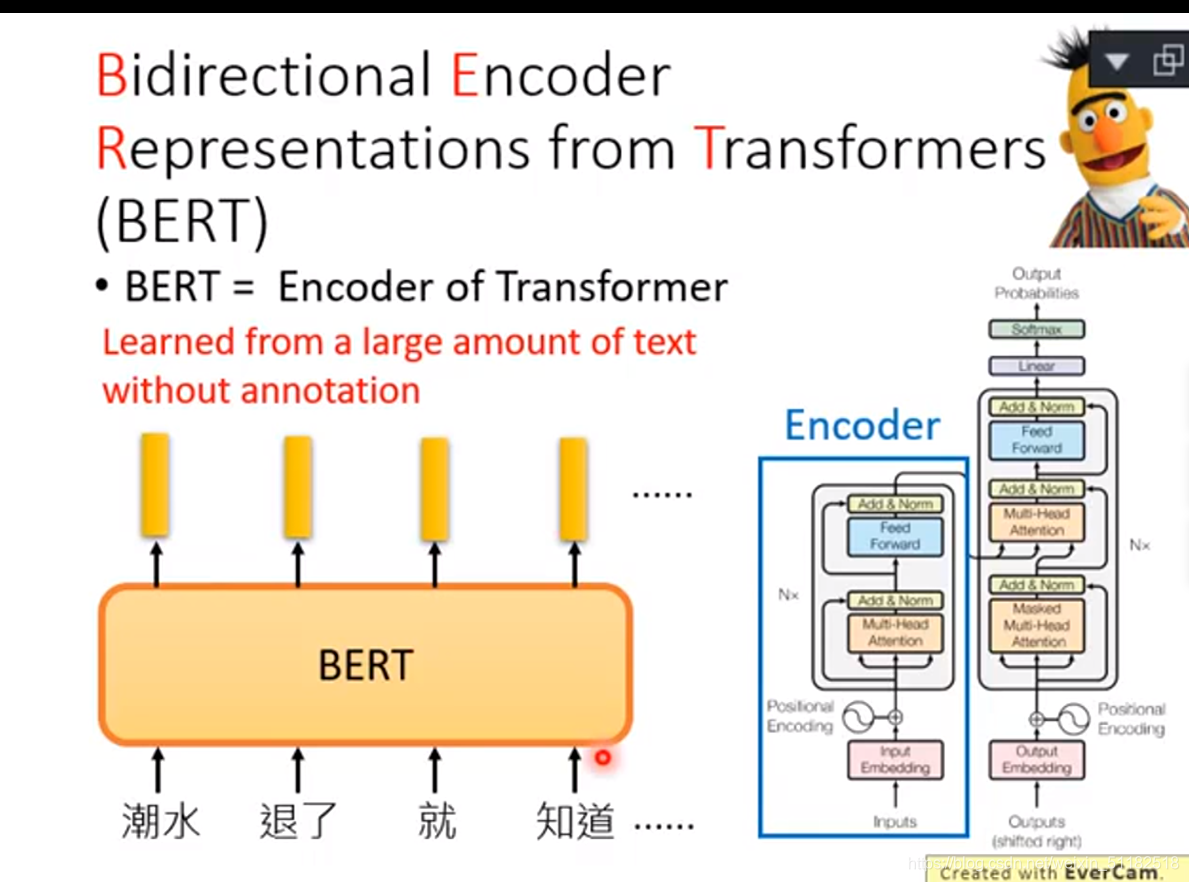
BERT: Bidirectional Encoder Representations from Transformers
使用字代替词作为bert的输入的话,使用one-hot encoding 会更方便很多
== bert=Encoder of Transformer==
Train of BERT
Approach 1:Masked LM
把输入的句子随机有15%的几率会被mask遮挡住,特殊的token,bert要做的就是去猜测这些盖住的mask是什么
每一个input通过bert都会输出一个embedding,把被masked的embedding 丢入一个linear multi-class classifier,要求这个classifier预测出被masked的词汇是哪个,由于该线性classifier很简单的模型,如果可以预测对,则代表这个bert模型足够复杂。

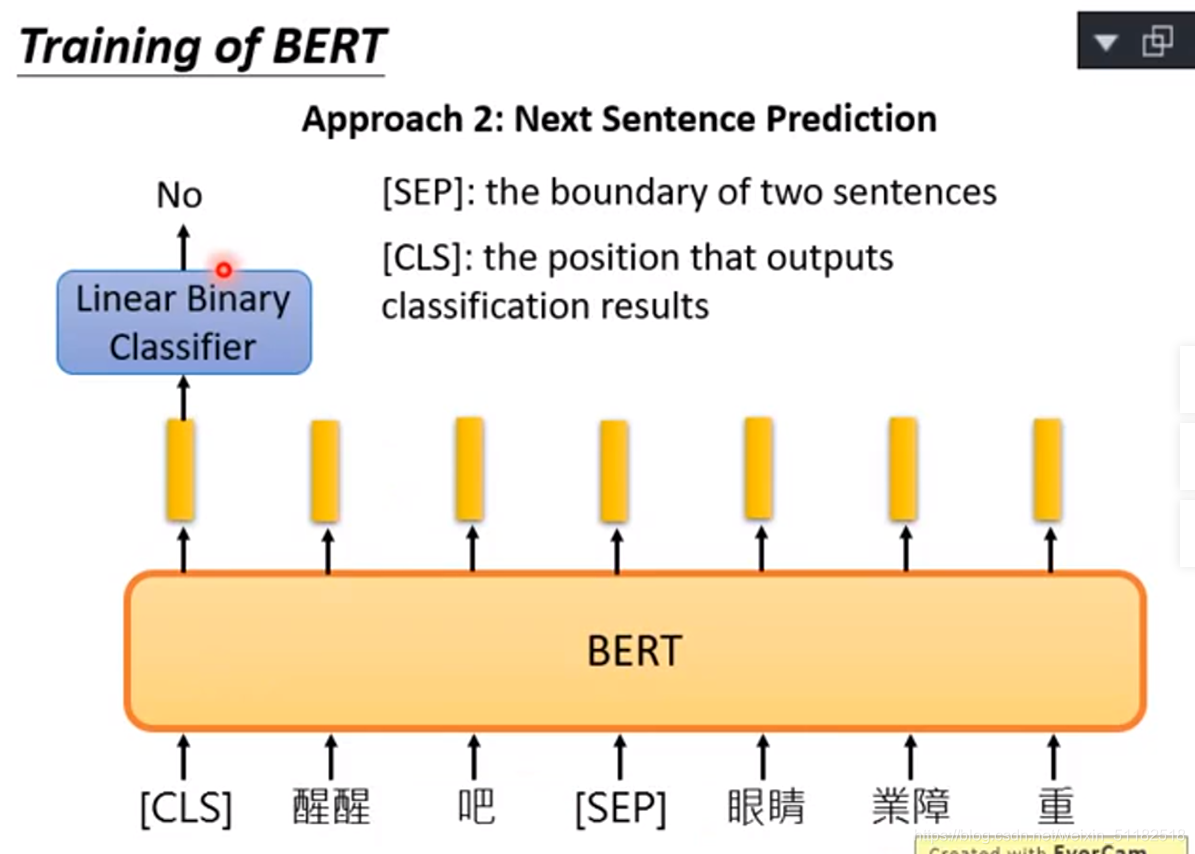
Approach2:Next Sentence Prediction
The boundary of two sentences
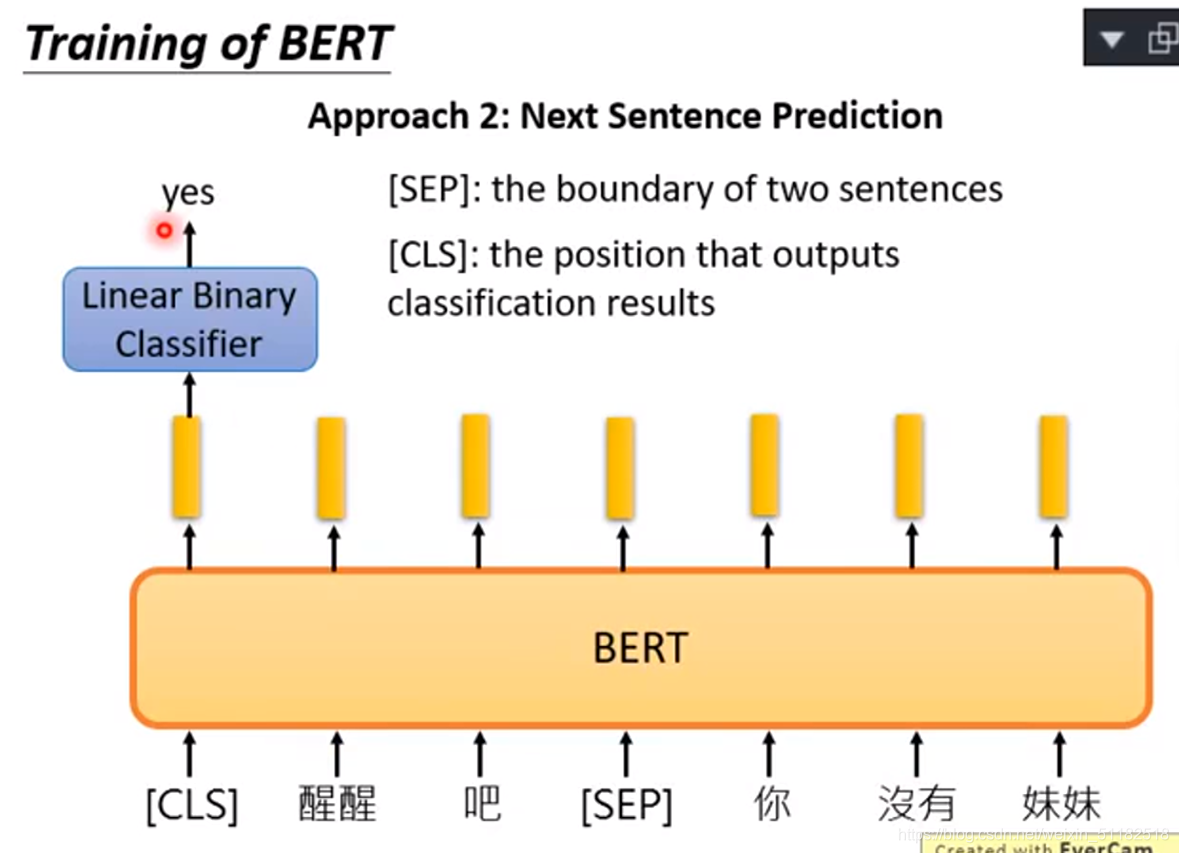
将两个句子以[sep]链接输入到BERT中,最后[CLS]位置的输出再输入进一个线性二项分类器中,判断两个句子是否该连在一起。如果bert中的nn为RNN,[CLS]最好放在最后面。因为RNN是由左读到右的。但BERT的内部不是RNN,而是一个transformed encoder。将每两个句子连接,训练它linear binary classifier是yes还是no,代表他们是否该相连。
两个方法同时使用
将bert当成一个抽feature的工具形成新的embedding
How to use BERT ——Case 1
判断句子属于哪个主题
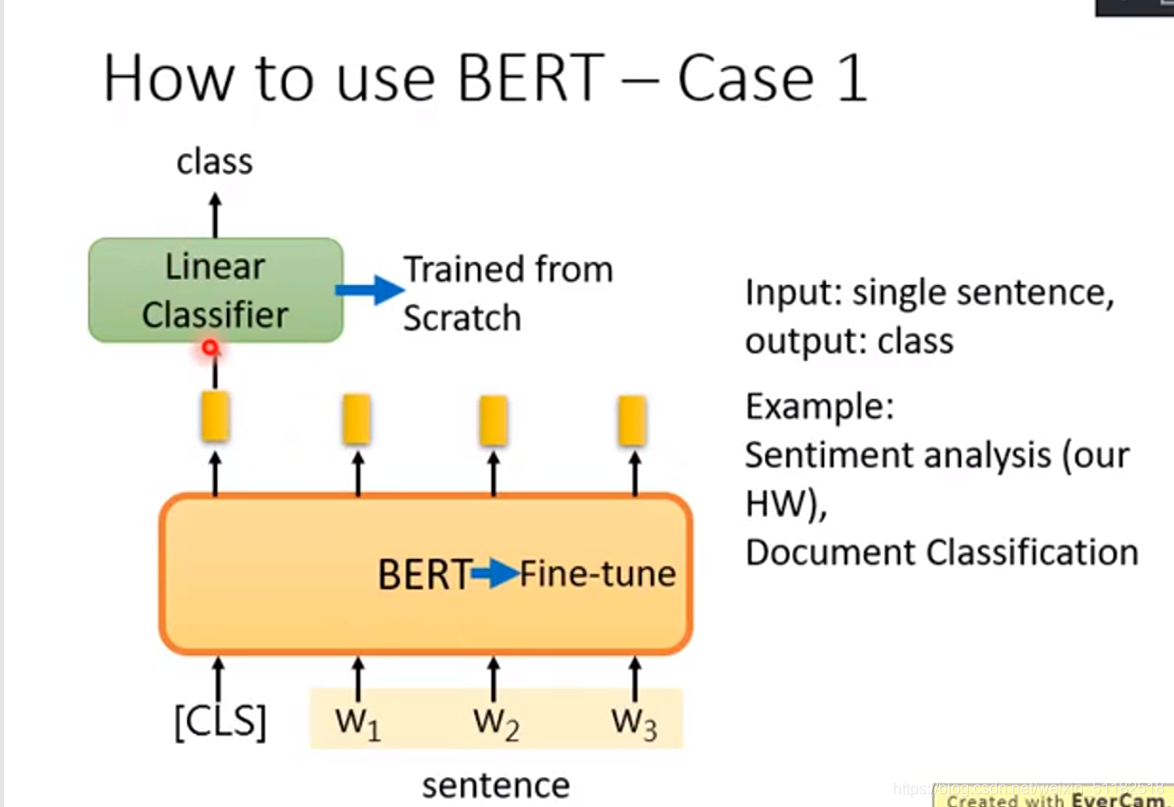
bert和linear classifier一起学习,后者要trained from scratch,从头学
How to use BERT ——Case 2
判断句子中的每个词汇属于哪个主题
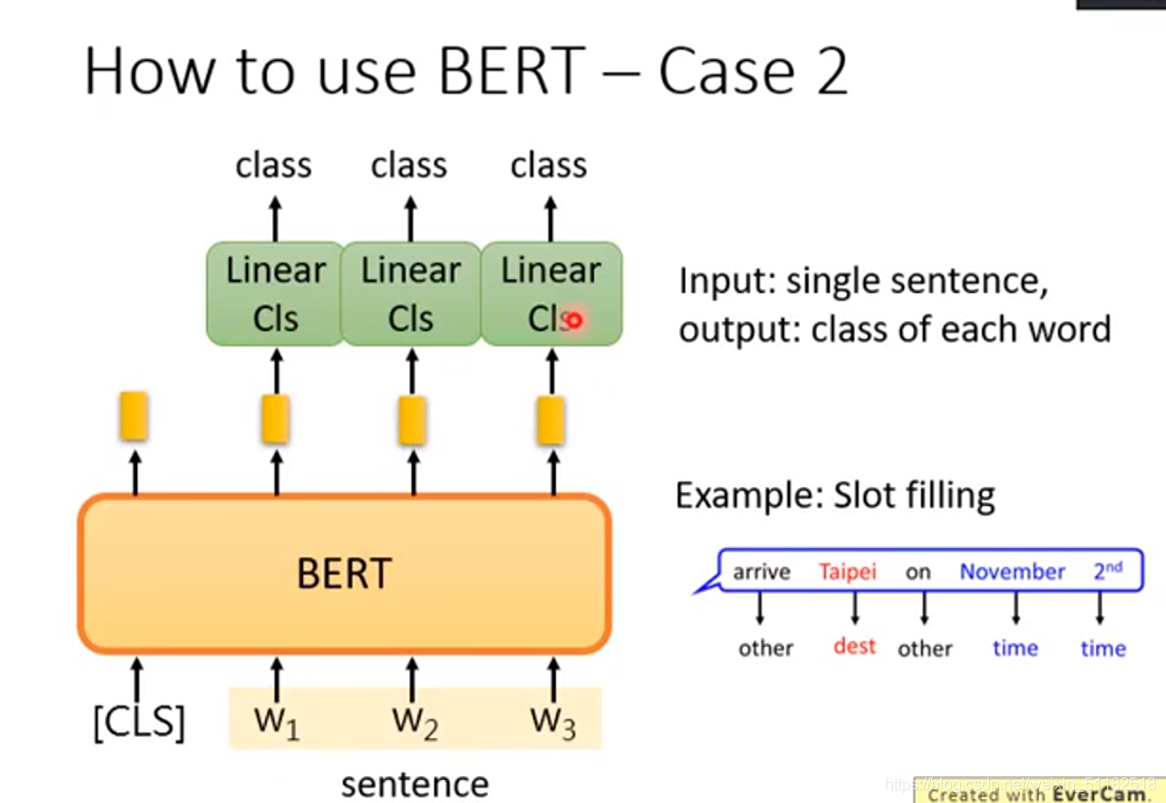
input一个句子,每一个词汇都会产生一个embedding,再把这些embedding输入到linear cls中。
How to use BERT ——Case 3
input两个句子,output一个class
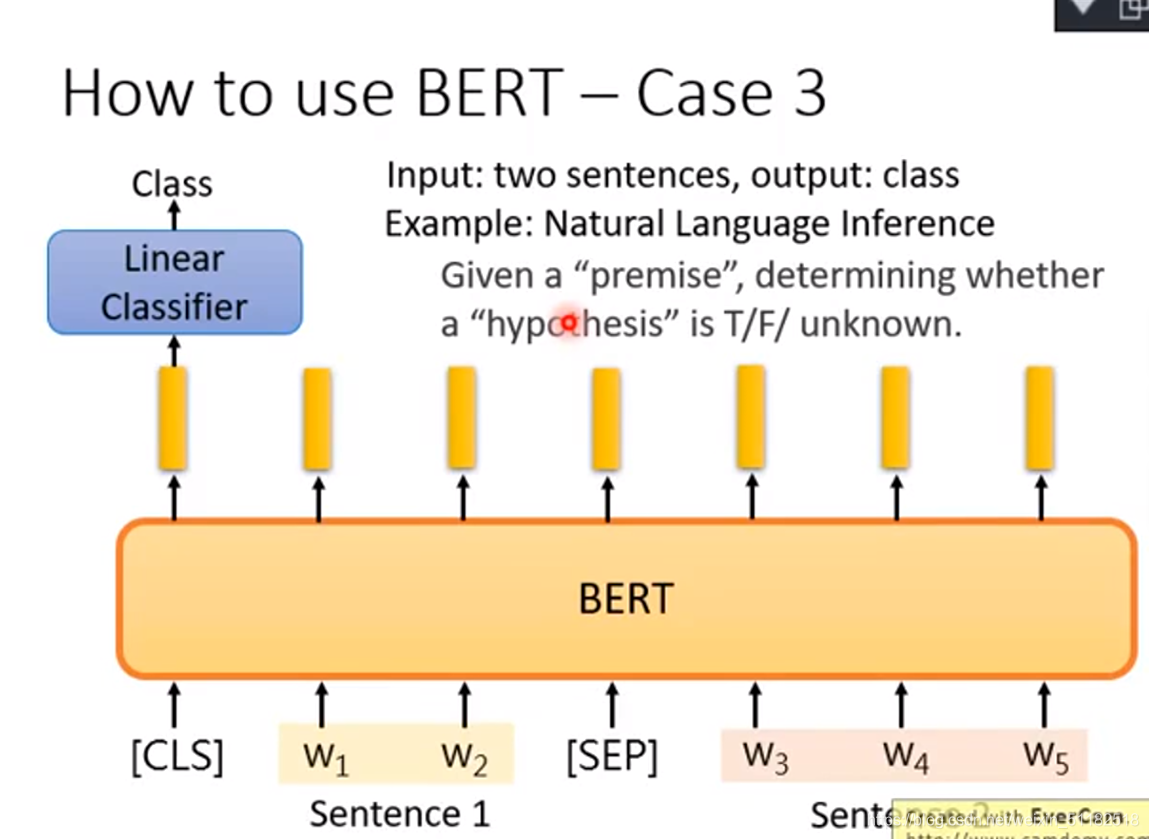
只有三个类别的分类问题,T,F,Unknown
通过[sep]分割符号把两个sentence丢给BERT,在开头加入[cls],代表分类,将开头的地方输出的embedding,拿它输入linear classifier做分类。
How to use BERT ——Case 4
Extraction-based Question answering
给你的model都一篇文章,给它一个问题,希望可以得到问题,条件为:答案一定出现在文章里
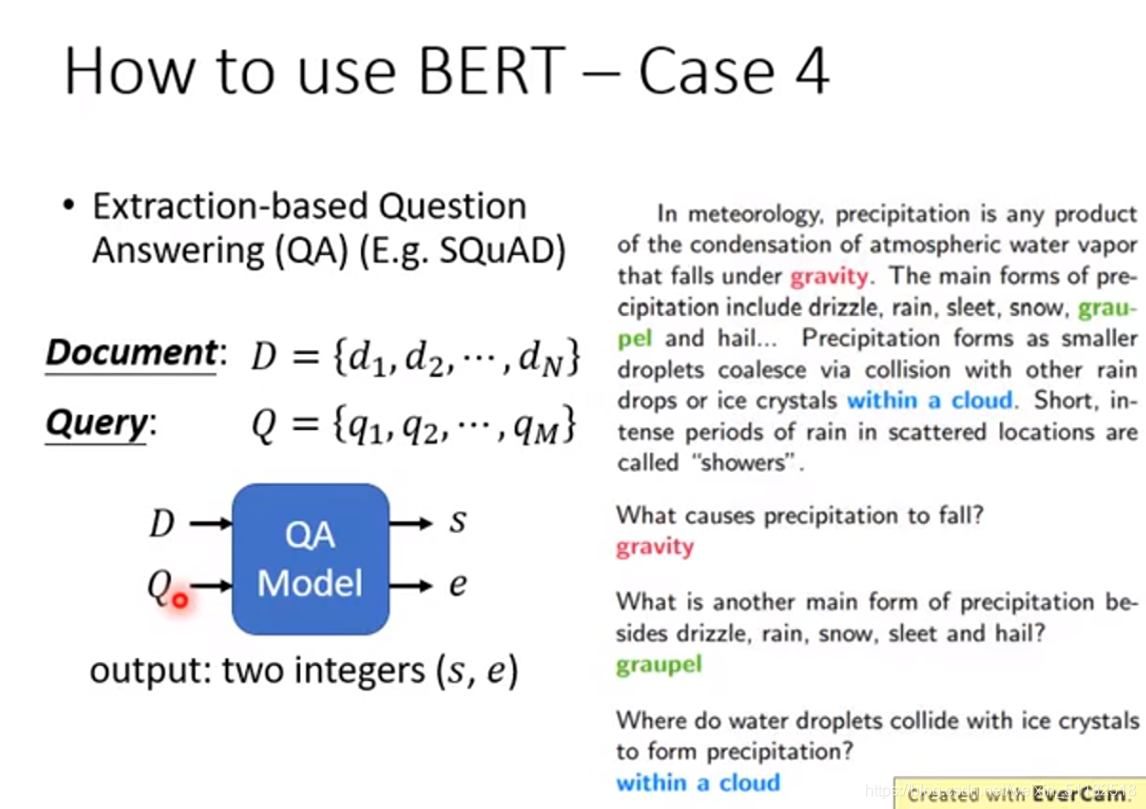
给QAmodel一个文章一个问题,output两个整数(s,e),这两个整数的意思是现在该问题的答案落在该文章 d s 到 d e d_s到d_e ds到de个token。
对于答案为gravity的问题,s和e的输出为17和17
对于答案为within a cloud,s和e的输出分别为77,79

如何用bert解决case 4
把问题和文章间隔为[sep]输进去,让machine去learn另外两个vector(红色的和蓝色的),这两个的dimension和bert输出的embedding的dimension是一样的,拿红色的vector与document里的每一个word embedding做dot product,类似attention。算出一个scaler,通过softmax得到文档中拿个词汇得到的分数最高。红色的vector决定了s等于多少。再用蓝色的vector作上述操作,定义e的大小。
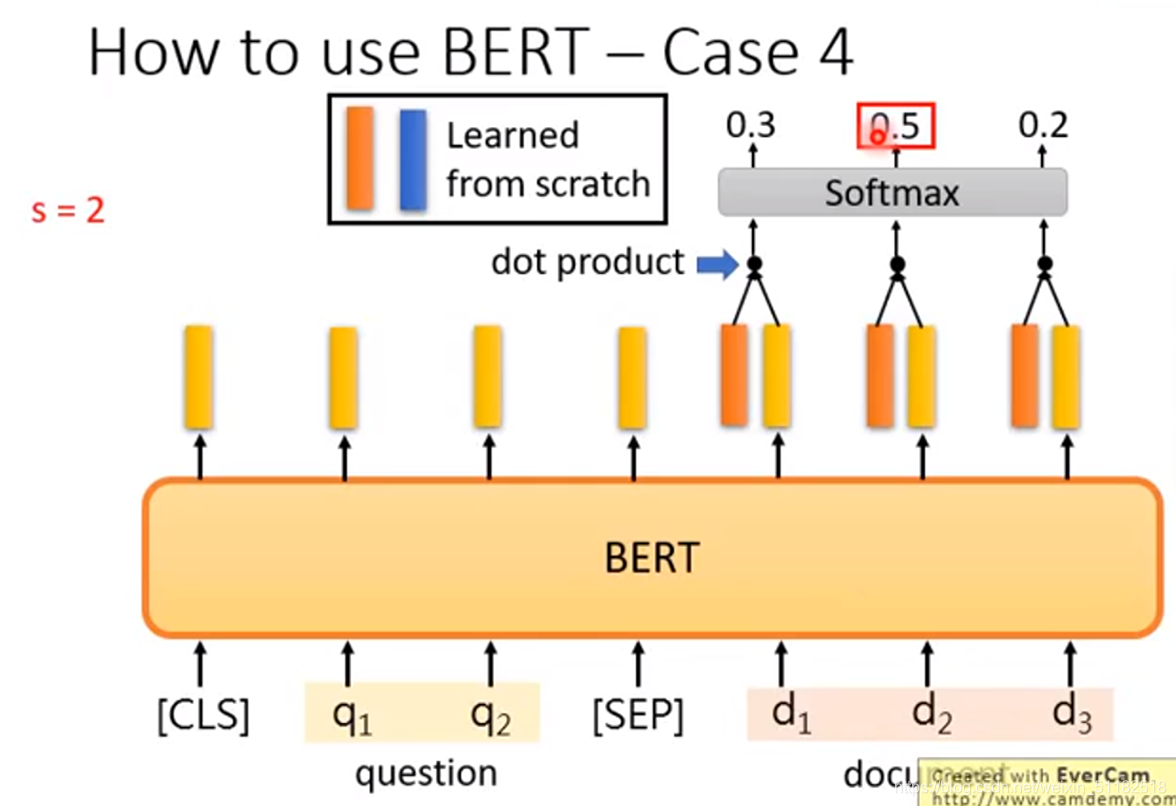
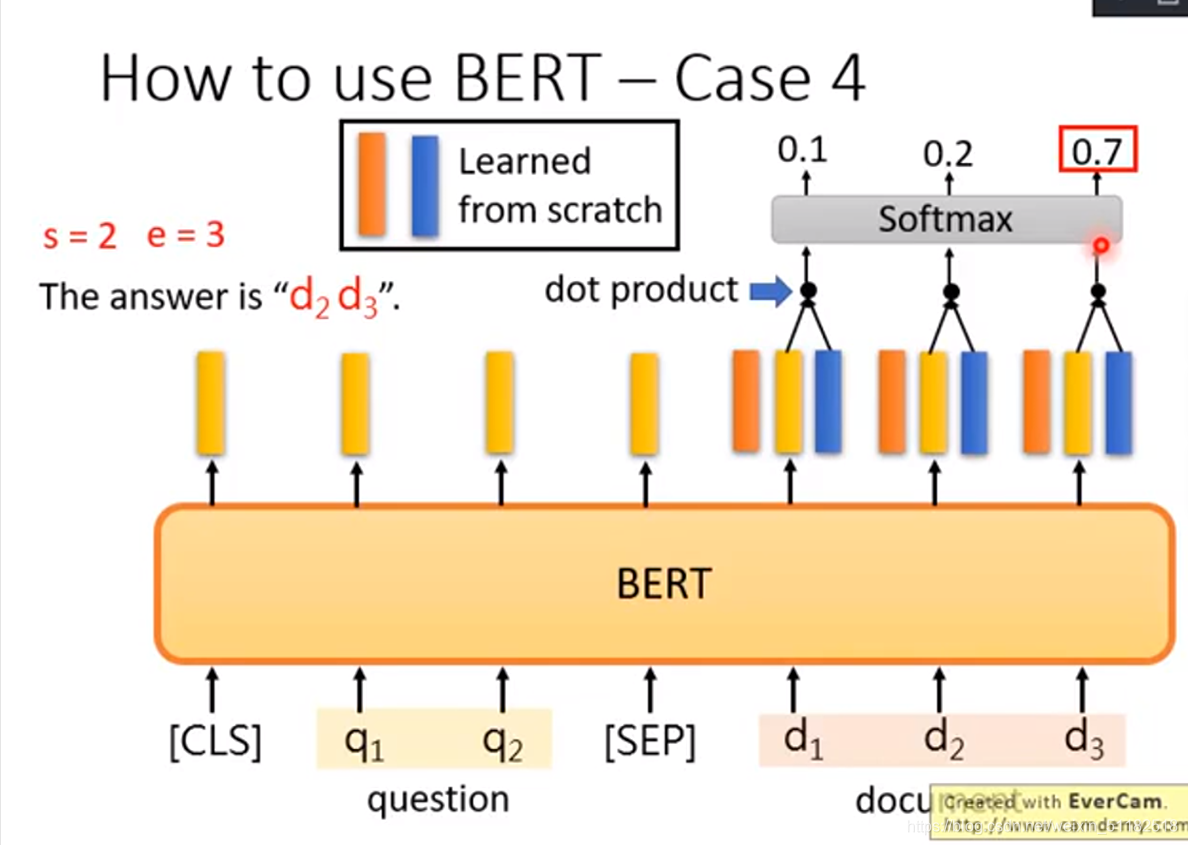
红色的vector和蓝色的vector是学习出来的,给与模型学很多问题和文本。random的从头开始学出来的
Enhanced Representation through Knowledge Integration ——ERNIE
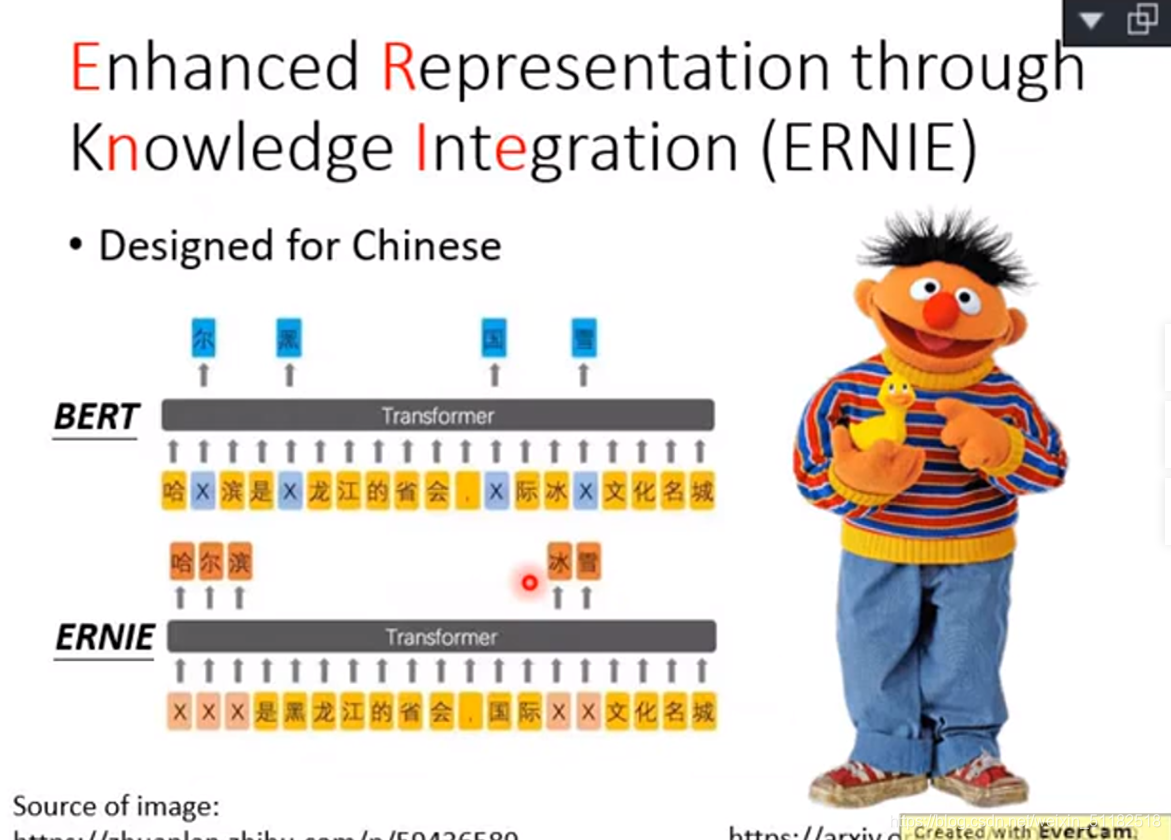
以中文的字为单位,一次用mask盖住一个词汇
BERT 在各种测试中的表现
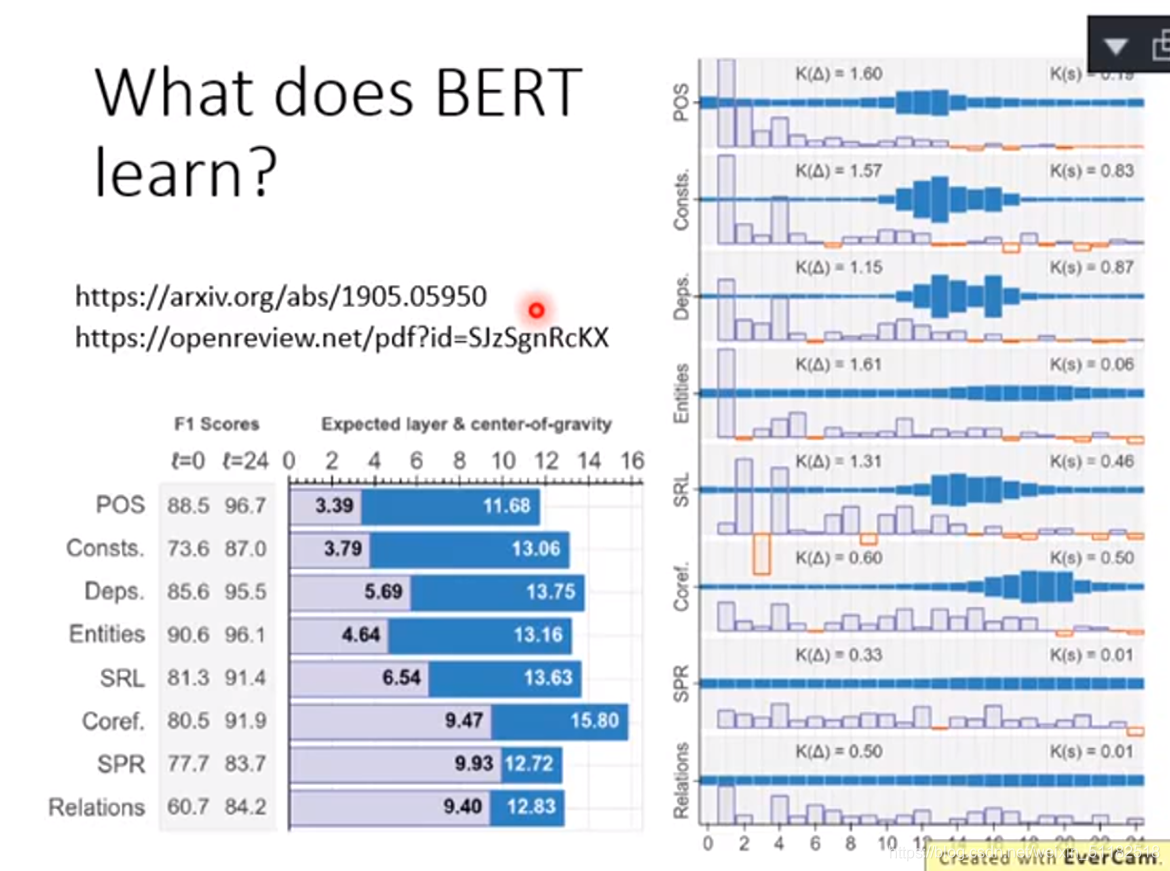
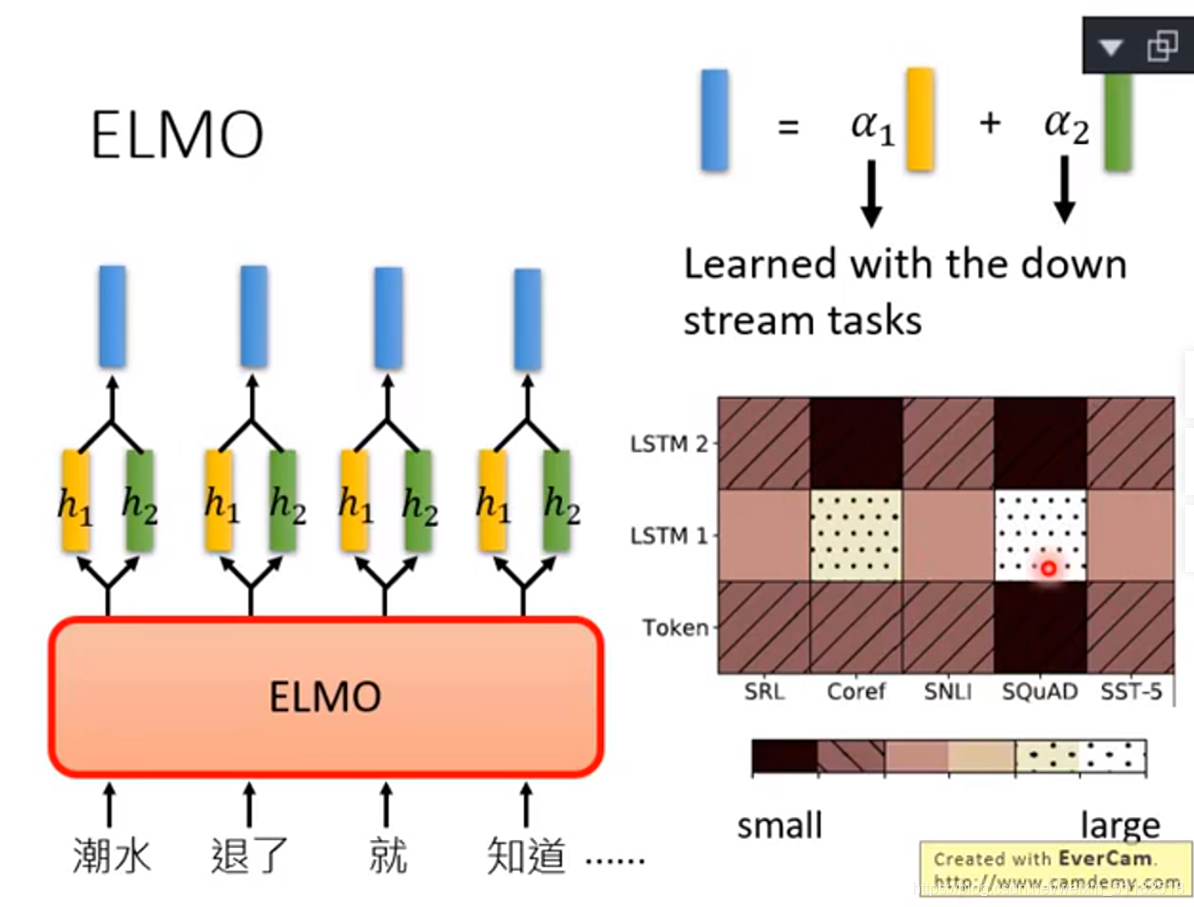
上方图片右侧图表中的蓝色区域越大的代表那一部分所在的word embedding的权值越大。每一个row代表了一个nlp的任务,每一个column代表bert的层。例如做pos(词性标记),最需要bert的11-13层,如果解的是coref任务,最需要17-19层的bert。
3、GPT Generative pre-Training

GPT-2有1542M的参数
- Transformer decoder
如何运作,预测下一个词汇
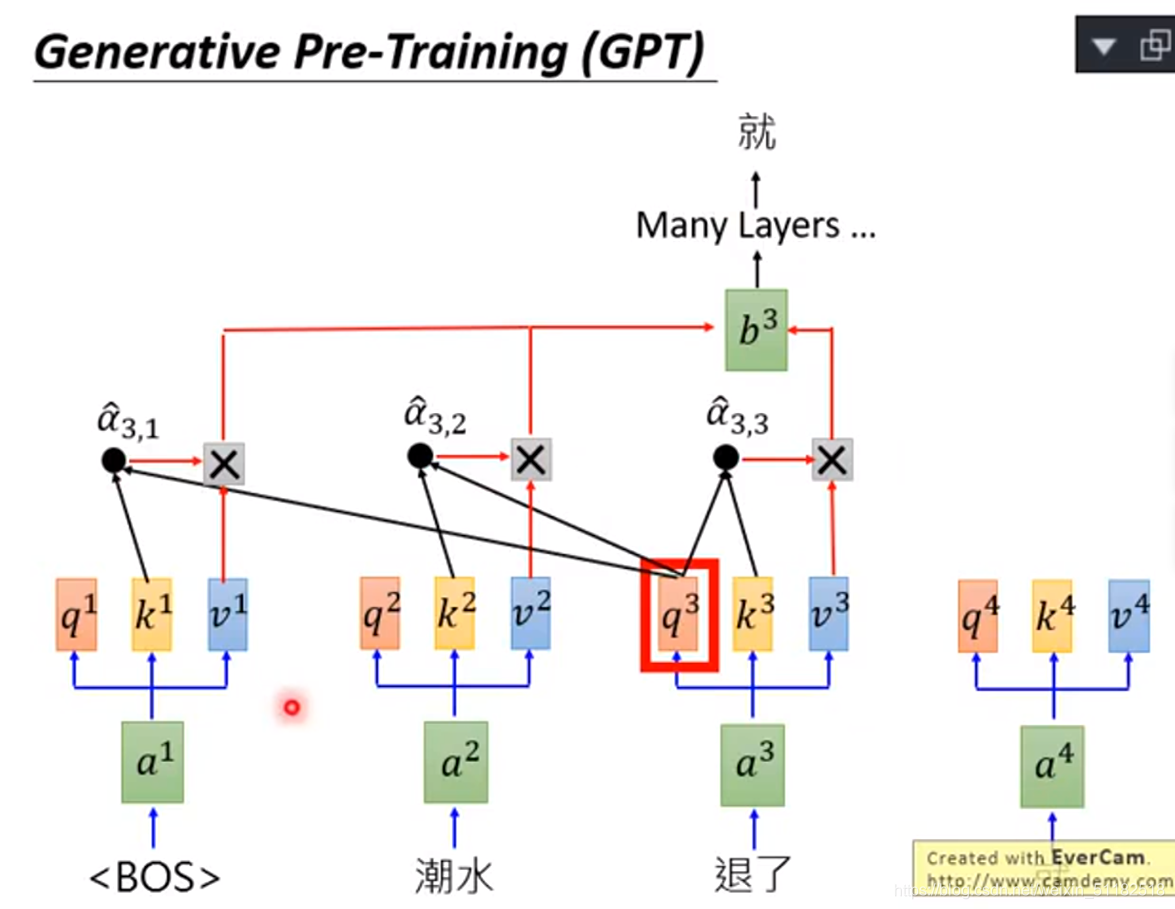
将q3和已经产生的词汇k1和k2做attention产生 a 3 , 1 , a 3 , 2 和 a 3 , 3 a_{3,1},a_{3,2}和a_{3,3} a3,1,a3,2和a3,3,再跟每一个词汇产生的 v 1 , v 2 , v 3 v^1,v^2,v^3 v1,v2,v3做?,得到 b 3 b^3 b3的embedding,再通过很多层产生就这个词,继续这个过程,产生一个完整的句子
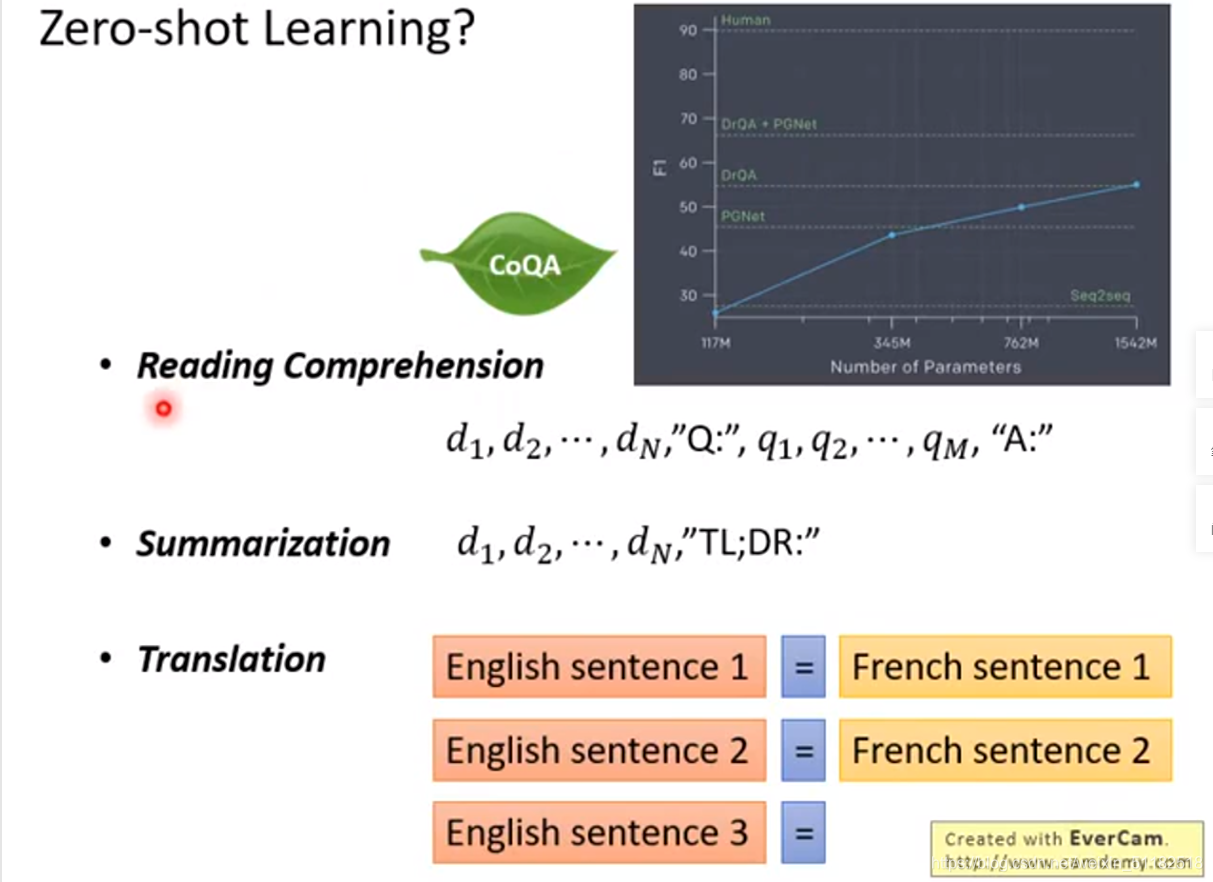
可以在完全没有训练资料的情况下做
- reading comprehension
- summarization
- Translation
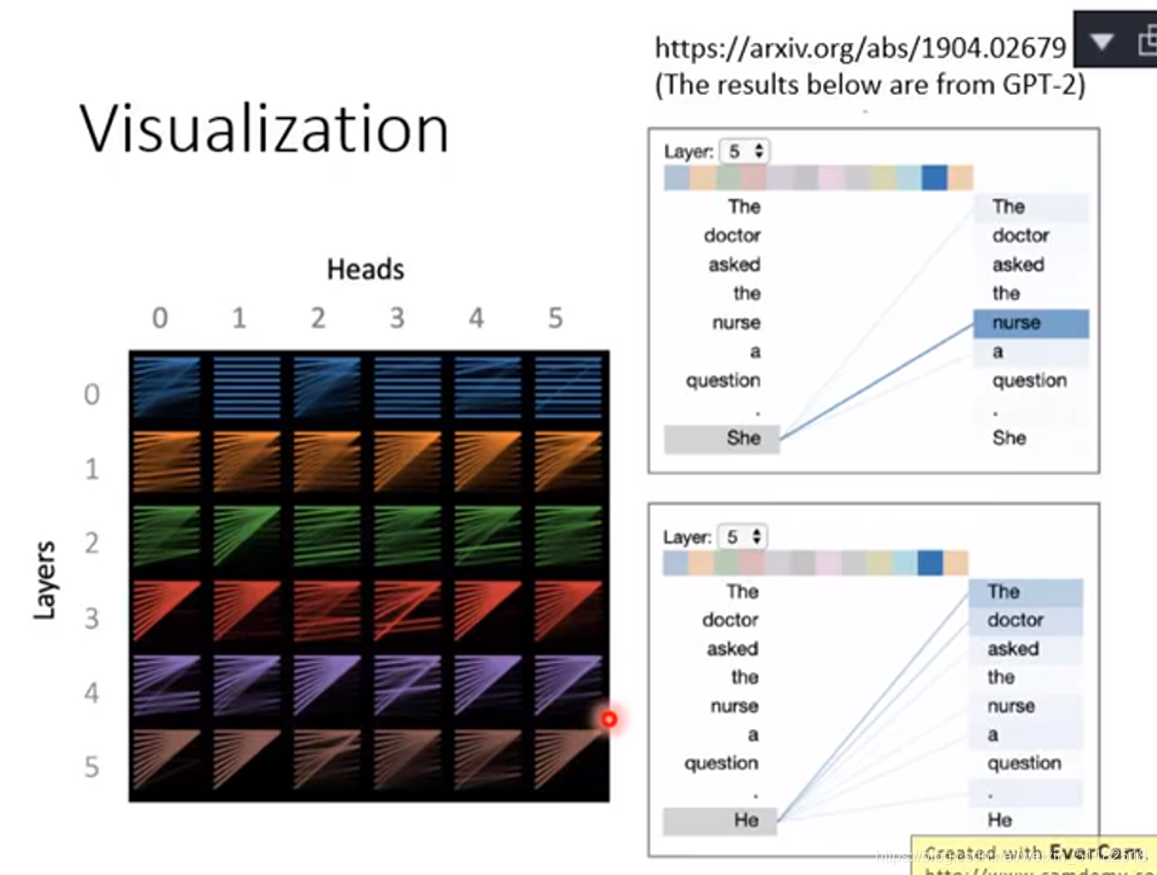
很多不同的词汇都会探测到第一个词汇,layer和head越深约会这样
2、Transformer
Seq2seq model with “Self-attention”
最常用的架构:RNN
- 输入一串vector sequence,输出另一串vector sequence。输出 a 3 , 时 a 1 , a 2 a^3,时a^1,a^2 a3,时a1,a2已经被看过
- 问题:不易被平行化,例如,为了计算 b 4 , 需 要 考 虑 , a 1 − 4 b^4,需要考虑,a^{1-4} b4,需要考虑,a1−4
- 所以用CNN取代RNN
- 每一个三角形代表一个filter,以三个vector作为输入,与filter里的参数做内积,用filter扫过 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1081
1081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









