







增删改
insert 把数据插入到数据表中
insert into <list>(字段列表) values(值列表);
insert into student(name,sex) values('好好','女');update 对数据库表中的数据进行变更
update <tbname> set 字段名=值[字段名,值],... [where 条件表达式]
update student set sname='好好', where sname='哈哈'; #哈哈改成好好
update student set sname='好好', where sname='哈哈' and id=4; #哈哈id=4改成好好delete 删除表中数据记录
delete from <tbname> [where子句]
delete from student where sname=''; #删除姓名为空字符
delete from student where sname is null; #删除姓名为空DCL命令
访问权限
grant <权限列表> on 数据库.对象名 to '用户名'@'允许登录的地址' identified by '密码'- 权限列表:
- 分的细:selete,update,delete,insert
- 使用all privilege代替所有权限
- 对象名:表table,视图view,过程procedure: *.*代表所有的数据库中的所有对象
- 若用户名不存在,grant可以创建用户
给root用户分配远程访问的权限【重点】
grant all privileges on *.* to 'root'@'%' identified by 'root123';
flush privileges; #刷新权限缓存revoke 解除权限
revoke <权限列表> on 数据库名.对象名 from '用户名'@'允许登录的地址'
收回dbtester对woniusales数据库的插入数据权限
revoke insert on woniusales.* from 'dbtester'@'%';三大范式
范式:normal format设计数据库表的标准格式。
- 第一范式:表(二维表)中的字段不可拆分。
问题:数据的新增、删除、修改都会产生异常。
- 第二范式:表中的每一行必须唯一(避免出现重复数据),非主键必须完全依赖主键(可能会使用复合主键)。
建表时必须设立主键,能用一个主键不用两个。~~第二范式继承第一范式的问题。
- 第三范式:每列都和主键直接相关,而不是间接相关。
拆分表格 ~~外键约束表与表之间的完整性。
DQL
单表查询
1、select 筛选数据
select 字段名,字段名,...from 表名 [where子句][group by分组字段][having子句][order by子句][limit分页条件]
#查询2000-1-1之后的女学生姓名
select sname,sbirthday from student where sbirthday>'2000-1-1' and ssex='女';
select * from table where age between 18 and 30;排序
关键字:order by
排序类型:升序:ASC 降序:DESC
order by 字段名 ASC|DESC
#查询成绩,分数倒序
select * from score order by degree desc;
#查询成绩,学号倒序
select * from student order by sno;多字段排序
order by 字段名1 ASC|DESC,字段名2 ASC|DESC...
#查成绩,分数倒序,学号升序
select * from score order by degree desc,sno;模糊查询
where 字段名 like 表达式;表达式和通配符
%:代表任意个任意字符
_:代表任意的一个字符
注:表达式中通配符可以放多个,也可以放在字符串的任意位置。
#查询张姓同学
select * from student where sname like '张%';
#查询张姓或李姓同学
select * from student where sname like '张%' or like '李%';查重
select distinct 字段列表 from tablename [where 子句]
#对被统计字段进行先去重后统计
select count(distinct degree) from tablename;distinct的位置【难点】
- 放在select后面,对筛选出来的记录去重
- 放在函数里面,对被统计的字段去重
分页查询
控制查询返回的记录数量
关键字limit
limit x,y
x:表示查询起点的行数,从0开始计数,缺省就是0(可以不写,默认是0),即第一条记录。
y:表示需要返回y行
#查询最高分
select * from score order by degree desc limit 1;
select * from score order by degree desc limit 0,1;
#查询前三
select * from score order by degree desc limit 3;分组查询和聚合函数
聚合函数:对指定字段进行统计计算,计算的结果只有一个。
sum():求和
#查询表中degree的总和
select sum(degree) from demo;count(字段名|*|数字):计数
#查询demo中班级的数量,当字段名为参数时,会自动筛选非空记录
select count(class) from demo;
select count(1) from demo where class is not null;avg():求平均值
max():求最大值
min():求最小值
聚合函数中去掉null记录的简便写法
ifnull(字段名,0) : 如果字段的值为null,则使用0代替
#查询demo表中的degree平均值
select avg(ifnull(degree,0)) from demo;
#查询每科成绩的平均分
select cno,avg(degree) from score group by cno;
#查询每科成绩的最高分
select cno,max(degree) from score group by cno;
#查询每个学员的总成绩
select sno,sum(degree) from score group by sno;
分组查询
select 分类字段,聚合函数(字段名) from tablename group by 分类字段 [having 子句];
select ssex,count(*) from student group by ssex;
#查询班上男生人数
select count(*) from student where ssex='男';
#查询每科成绩的平均值
select cno,avg(degree) from score group by cno;having子句
对分组后的记录进行筛选
#查询每个学员的平均分及格的记录
select sno,avg(degree) from score group by sno having avg(degree)>=60;
select sno,avg(degree) from score group by sno having avg(degree)>=60 and sno>102;having和where的区别:
- 作用对象不一样:having作用于分组后的数据,where是作用于分组前的数据。
- 位置不一样:having只能放在group by后面,where只能放在group by前面。
查询中的别名系统
别名的作用:把复杂的表达式简单化,将子查询的返回的数据作为表使用
#查询每个学员的平均分及格的记录
select sno,avg(degree) from score group by sno having avg(degree)>=60;
select sno,avg(degree) as avgrlt from score group by sno having avgrlt>=60;别名的两种写法:
- 字段名 as 别名
- 字段名 别名
别名影响的对象
- 字段
- 表
select s.sname 姓名,s.sbirthday from student s
select s.sname,s.sbirthday from student s
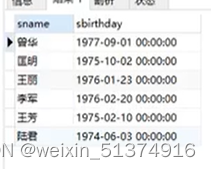
#查询score表中至少有5名学生选修的并以3开头的课程的平均分
查询score表中至少有5名学生选修的课程;
以3开头的课程
select cno,count(*) as count,avg(degree) from score group by cno having count>=5 and cno like "3%";
select cno,count(*) as count,avg(degree) from score where cno like "3%" group by cno having count>=5 ;连接查询引入
#连接查询引入
select * from student,score where student.sno = score.sno;
select sname,cno,degree from student inner join score on student.sno = score.sno;多表查询
1、连接查询
1、连接查询
连接种类:
1、内连接
简洁方式
select * from a,b where a.pk=b.fk[and 条件表达式]
完全方式
select * from a inner join b on a.pk=b.fk[where 子句]
懒汉方式
select * from a join b on a.pk=b.pk[where 子句]特点:
只有两边都匹配上的数据才显示,其他数据不显示。
#查询所有学生的sno,cname和degree列,筛选分数>=60
select * from student s,score s1,course c where s.sno=s1.sno and s1.cno=c.cno
·
·
select s.sno,c.cname,s1.degree from student s,score s1,course c where s.sno=s1.sno and s1.cno=c.cno and s1.degree>=60;
#查询平均分大于80分的学生是sno,cname和平均分
select s.sno,c.cname,avg(s1.degree) avgrlt from student s,score s1,course c where s.sno=s1.sno and s1.cno=c.cno group by s1.sno,cname having avgrlt>80;2、外连接:左外 右外
#左外
select * from a left join b on a.fk=b.pk;特点:
左表的数据全部显示,右表和左表匹配上的显示,匹配不上的数据显示为NULL。
#右外
select * from a right join b on a.fk=b.pk;特点:
右表的数据全部显示,左表和右表匹配上的显示,匹配不上的数据显示为NULL。
使用场景:
- 当产需返回的数据在多张表中时候,就需要使用连接查询
- 先确认表和表之间的关联关系,根据关联关系进行连接,注意选择连接的类型。
#查询张老师所教的学生的信息
select * from student s,score s1,course c,teacher t where s.sno=s1.sno and s1.cno=c.cno and c.tno=t.tno and t.tname like '张%';
#查询张老师所教学生的姓名和平均分
select s.sname,avg(s1.degree) from student s,score s1,course c,teacher t where s.sno=s1.sno and s1.cno=c.cno and c.tno=t.tno and t.tname like '张%' group by s.sname;2、子查询
子查询指嵌入到其他SQL语句中的查询语句
特性:子查询的返回是一个虚表,存放内存中一个二维表。
作用:
- 作为数据源,用来存放数据。
- 当返回结果为单列,可以用来查询条件中的数据。
#查询成绩总分大于150分的学员信息
当显示的字段在同一数据表中,而涉及到的又是多张表的时候,可以选择子查询
select * from student where sno in(select sno from score group by sno having sum(degree)>150)
#查询成绩总分大于150分的学员信息和总分、平均分
select s.*,a,total from student s,(select sno,sum(degree) total from score group by sno having total>150) a where s.sno=a.sno
#查询成绩总分大于150分的学员信息和总分、平均分
select s.*,a.total,a.avgdegree from student s,(select sno,sum(degree) total,avg(degree) avgdegree from score group by sno having total>150) a where s.sno=a.sno;3、组合查询
将多个查询的返回结果进行组合显示
(select 语句) union|union all (select 语句)特性:组合查询之后字段数量不会增加,只增加记录数。
适用场景:需要将不同的数据表当中的同类的数据进行组合显示的时候。
查询女性教师的姓名和生日以及女生姓名和生日
select tname,tbirthday from teacher where tsex='女'
union
select sname,sbirthday from student where ssex='女'union和union all区别:
union自动去重,union all不会去重
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
select语句执行顺序:
from
join on
where
group by
having
select
order by
distinct
limit
拿到查询需求怎么写出查询语句
- 看需要显示的字段:目的是定位第一个数据源。看筛选条件,目的是定位第二张表
- 分析这些表之间是否存在关联关系
。如果有,选择连接类型,连表
。如果没有,查找两张表的中间表,选择连接类型,连表
- 分析筛选条件,构造 where 子句
- 在确定分组,主要看需求之中有没有聚合函数方面的需求
。确定分组宇段
。确定聚合的类型
- 再确定分组之后的筛选条件排序
- 查重
- 分页
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









