







一、延时从库
1.介绍
普通的主从复制,处理物理故障比较擅长
如果主库出现了drop database 操作
延时从库:主库做了某项操作之后,从库延时多长时间回放(SQL),可以处理逻辑损坏
SQL线程延时:数据已经写入relay-log中了,SQL线程“慢点”运行
企业一般延时3-6小时
1.1为什么要有延时从库
数据库故障?
物理损坏
主从复制非常擅长解决物理损坏
逻辑损坏
普通主从复制没办法解决逻辑损坏
2.延从库配置
1)已经有主从的情况下
1.停止主从
mysql> stop slave;
2.设置延时为300秒
mysql> CHANGE MASTER TO MASTER_DELAY = 300;
3.开启主从
mysql> start slave;
4.查看状态
mysql> show slave status \G
SQL_Delay: 300
5.主库创建数据,会看到从库值变化,创建的库没有创建
SQL_Remaining_Delay: NULL
2)没有主从复制的情况下
1.修改主库,从库配置文件
server_id
开启binlog
2.保证从库和主库的数据一致
3.执行change语句
change master to
master_host='172.16.1.50',
master_user='rep',
master_password='123',
master_log_file='mysql-bin.000001',
master_log_pos=2752,
master_delay=180;
3)延时从库停止方法
1.停止主从
mysql> stop slave;
2.设置延时为0
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
3.开启主从
mysql> start slave;
#注:做延时从库只是为了备份,不提供服务
2.思考:延时到底是在哪里延时的
思考:IO线程还是SQL线程做的手脚?
#去主库创建一个库
create database ttt;
#查看从库的relaylog看看有没有内容
mysqlbinlog --base64-output=decode-rows -vvv db03-relay-bin.000002
总结:
延时从库是在SQL线程做的手脚,IO线程已经把数据放到relay-log里了.
SQL线程在执行的时候,会延迟你设定的时间长度.
3.故障模拟机恢复
1)模拟数据
create database hhh charset utf8mb4;
use hhh
create table t1(id int);
begin;
insert into t1 values(1),(2),(3),(4);
commit;
begin;
insert into t1 values(11),(22),(33),(44);
commit;
drop database hhh;
2)恢复思路
1.先停业务,挂维护页
2.停从库SQL线程
stop slave sql_thread;
看relay.info ---> 位置点
stop slqve;
3.追加后续缺失半部分的日志到从库
日志在哪存? ---> relay-log.
范围:
hhh: relay.info ---> drop
4.恢复业务方案
hhh 导出,恢复到主库
推荐方法:直接将从库直接承当hhh的业务
3)恢复过程
1.停SQL线程
从库: stop slave sql_thread;
2.截取relaylog
起点:
Relay_Log_File:db02-relay-bin.000002
Relay_Log_Pos:320
cat /data/3308/data/relay-log.info
./db02-relay-bin.000002
320
终点:
mysql> show relaylog events in 'db02-relay-bin.000002';
3.从库恢复
set sql_log_bin=0;
source /tmp/relay.sql;
set sql_log_bin=1;
select * from hhh.t1;
二、过滤复制(单台机器)
1.画图说明
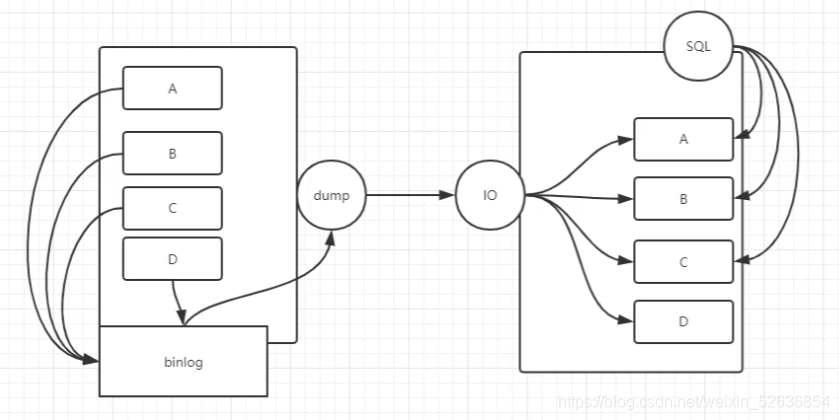
2.配置
1)主库
show master status;
binlog_do_db #白名单
binlog_ignore_db #黑名单
binlog_do_db=world
2)从库
show slave status\G
--库级别
replicate_do_db=world
replicate_ignore_do=xxx
--表级别
replicate_do_table=world.t1
replicate_ignore_table=
--表的模糊级别(模糊匹配)
replicate_wild_do_table=world.t1
replicate_wild_ignore_table=
修改配置文件
vim /data/3308/my.3308.conf
replicate_do_db=hhh
replicate_do_db=xxx
重启数据库
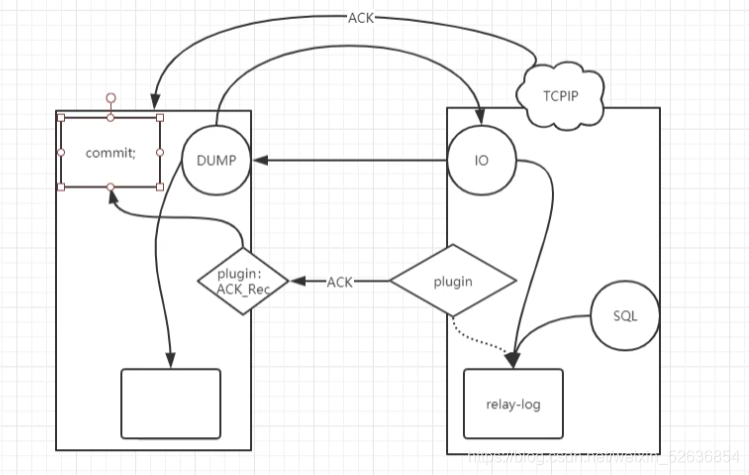
三、半同步复制
mysql主从本身就是传统异步复制,非GTID复制工作模型,会导致主从数据不一致情况
IO线程将数据写入TCP/IP以后就不管了,当TCP缓存返回ACK的时候,IO线程会继续去主库拿数据
5.5版本为了保证主从数据的一致性问题,加入了半同步复制的组件(插件),支持半自动复制。
半同步复制(Semi synchronous Replication)则一定程度上保证提交的事务已经传给了至少一个备库。
出发点是保证主从数据一致性问题,安全的考虑。
半同步复制是IO线程拿完数据,会等待SQL线程执行完以后再去拿数据,而且还会影响主库性能,他会阻塞主库数据的写入,如果SQL要执行十分钟,那么IO线程就一直等待,并且不让主库写入数据
半同步,是在IO线程上做的手脚,数据写入到TCP/IP缓存中,不返回ACK,直到SQL线程执行完之后,才返回ACK
ACK是一个确认字符
半同步其实是mysql自带的一个和插件(很少有人用)
1.效率低
2.影响主库的性能
3.设置一个超时时间:过了这个超时时间,会恢复到异步复制
5.5 出现概念,但是不建议使用,性能太差
5.6 出现group commit 组提交功能,来提升开启半同步复制的性能
5.7 更加完善了,在group commit基础上出现了MGR
5.7 的增强半同步复制的新特性:after commit; after sync;
在主从结构中,都加入了半同步复制的插件
控制从库IO是否将relaylog落盘,一旦落盘通过插件返回给ACK给主库ACK rec,接受到ACK之后,主库的事务才能提交成功。在默认情况下,如果超过10S没有返回ACK,此次复制行为会切换为异步复制,如果生产业务比较关注主从最终一致,推荐可以使用MGR的架构,或者PXC等一致性架构
1.画图说明
1.半同步复制开启方法
1)主库
#登录数据库
[root@db01 ~]# mysql -uroot -p123
#查看是否有动态支持
mysql> show global variables like 'have_dynamic_loading';
#安装自带插件(.so结尾的文件在 /usr/local/mysql/lib/plugin/ 下面)
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME'semisync_master.so';
#启动插件
mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;
#设置超时
mysql> SET GLOBAL rpl_semi_sync_master_timeout = 1000;
#修改配置文件
[root@db01 ~]# vim /etc/my.cnf
#在[mysqld]标签下添加如下内容(不用重启库)
[mysqld]
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
#查看半同步状态是否开启
mysql> show variables like'rpl%';
mysql> show global status like 'rpl_semi%';
2)从库
#登录数据库
mysql3308
#先检查从库状态
show slave status\G
#安装slave半同步插件
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME'semisync_slave.so';
#启动插件
mysql> SET GLOBAL rpl_semi_sync_slave_enabled = 1;
#重启io线程使其生效
mysql> stop slave io_thread;
mysql> start slave io_thread;
#编辑配置文件(不需要重启数据库)
[root@mysql-db02 ~]# vim /etc/my.cnf
#在[mysqld]标签下添加如下内容
[mysqld]
rpl_semi_sync_slave_enabled =1
3)测试半同步
三、 GTID复制
作用:主要保证让你更主从复制中的高级的特性
GTID:
5.6版本出现没有默认开启,5.7即使不开启也有匿名的GTID记录
DUMP传输可以并性,SQL线程并发回放提供了,5.7.17的版本以后几乎都是GTID模式
搭建GTID
1.环境准备
| hostname | 内网IP | 外网IP |
|---|---|---|
| db01 | 172.16.1.51 | 10.0.0.51 |
| db02 | 172.16.1.52 | 10.0.0.52 |
| db03 | 172.16.1.53 | 10.0.0.53 |
关闭防火墙
关闭selinux
能够实现远程xshell连接
2.环境清理(三台机器都要做)
pkill mysqld
rm -rf /data/3306/*
rm -rf /data/binlog/*
3.生成配置文件
[mysqld]
user=mysql
basedir=/service/mysql
datadir=/service/mysql/data
server_id=6
port=3306
socket=/service/mysql/mysql.sock
log-error=/service/mysql/data/mysql.err
log-bin=/service/mysql/data/mysql-bin
sync_binlog=1
secure-file-priv=/tmp
explicit_defaults_for_timestamp=true
#只在主库中配置,从库不配置
binlog_format=row
4.初始化数据(三个节点都要做)
mysqld --initialize-insecure --user=mysql --basedir=/service/daatabase/mysql --datadir=/data/3306
5.启动数据库
/etc/init.d/mysqld start
6.构建主从
创建用户
grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
7.从库开启主从
mysql> CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=444,
MASTER_CONNECT_RETRY=10;
mysql> start slave;
8.进入主库查看GTID是否开启
mysql> show variables like '%gtid%';
+---------------------------------+-----------+
| Variable_name | Value |
+---------------------------------+-----------+
| enforce_gtid_consistency | OFF |
| gtid_mode | OFF |
+---------------------------------+-----------+
9.修改配置文件,开启GTID
#配置三台机器配置文件
1.主库:
[root@db-01 data]# vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
gtid_mode=on #或者gtid_mode=1
enforce_gtid_consistency
2.从库01:
[root@db-02 data]# vim /etc/my.cnf
[mysqld]
gtid_mode=on
enforce_gtid_consistency
3.从库02:
[root@db-03 data]# vim /etc/my.cnf
[mysqld]
gtid_mode=on
enforce_gtid_consistency
4.启动不起来,查看错误日志:
[root@db-03 ~]# tail -100 /usr/local/mysql/data/db-03.err
[ERROR] --gtid-mode=ON requires --log-bin and --log-slave-updates
[ERROR] Aborting
#新配置三台机器配置文件
1.主库:
[root@db-01 data]# vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
2.从库01:
[root@db-02 data]# vim /etc/my.cnf
[mysqld]
gtid_mode=on
enforce_gtid_consistency
log-bin=mysql-bin
log-slave-updates
3.从库02:
[root@db-03 data]# vim /etc/my.cnf
[mysqld]
gtid_mode=on
enforce_gtid_consistency
log-bin=mysql-bin
#更新从库的binlog(从库的binlog不会写入,是把数据写到relay-log的,加这个参数会将数据写入binlog)
log-slave-updates
#有的时候双主也要加这个参数(不推荐使用,浪费资源)
#还有级联复制也要加(主库的从库也是其他主从的主库)
##使用log-slave-updates参数的情况
1.GTID
2.双主+KEEPALIVED
3.级联复制
9.说明
gtid的主从复制,第一次开启的时候,读取relaylog的最后gtid+读取gtid_purge参数,确认复制起点
10.GTID的优缺点
--优点
1.保证事务全局统一
2.截取日志更加方面,跨多文件,判断起点终点更加方便
3.判断主从工作状态更加方便
4.传输日志,可以并发传输,SQL回放可以更高并发
5.主从复制构建更加方便
--缺点
1.mysqldump 备份起来很麻烦,需要额外加参数 --set-gtid=on
2.如果主从复制遇到了错误,SQL停了,跳过错误,GTID无法跳过错误
stop slave;
set global sql_slave_skip_counter=1;
start slave;
#正常的主从,counter=1是跳过一条sql,而GTID是基于事务的主从复制,如果跳过就是跳过一个事务,我得错误语句只是一条SQL错了,是不允许跳过事务的
#网上跳过事务的方法:
1)停止slave进程
mysql> STOP SLAVE;
2)设置事务号,事务号从Retrieved_Gtid_Set获取
在session里设置gtid_next,即跳过这个GTID
mysql> SET GTID_NEXT= '6d257f5b-5e6b-11e8-b668-5254003de1b6:1'
3)设置空事物
mysql> BEGIN; COMMIT;
4)恢复事物号
mysql> SET SESSION GTID_NEXT = AUTOMATIC;
5)启动slave进程
mysql> START SLAVE;
双主+keepalived
grant replication slave on *.* to rep@'172.16.1.5%' identified by '123';
5)从库执行 chang master to语句
change master to
master_host='172.16.1.51',
master_user='rep',
master_password='123',
master_auto_position=1;
6)开启IO线程和SQL线程
start slave;
7)检查slave状态
show slave status\G
四、主从架构演变
1.原生态支持
1主1从
1主多从(3-4)
多级主从
双主结构
延时从库
过滤复制
MGR组复制(5.7。17+)
2.工作结构图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dAEAyg6W-1618274347566)(C:\Users\86150\Desktop\数据库\img\image-20210411202309028.png)]](https://img-blog.csdnimg.cn/20210413084325466.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl81MjYzNjg1NA==,size_16,color_FFFFFF,t_70)
3.非原生态
1. 安全:高可用
全年无故障率
99% 一般级别 1% *365 * 24 * 60 = 5256 Mins
99.9% 普通级别 0.1% *365 * 24 * 60 = 525.6 Mins
99.99% 准高级别 0.01% *365 * 24 * 60 = 52.56 Mins
代表产品: MySQL MHA
99.999% 金融级别 0.001% *365 * 24 * 60 = 5.256 Mins
代表产品:MySQL Cluster,InnoDB Cluster, PXC, MGC Oracle RAC sysbase cluster
99.9999% 超金融级别 0.0001% *365 * 24 * 60 = 0.5256 Mins
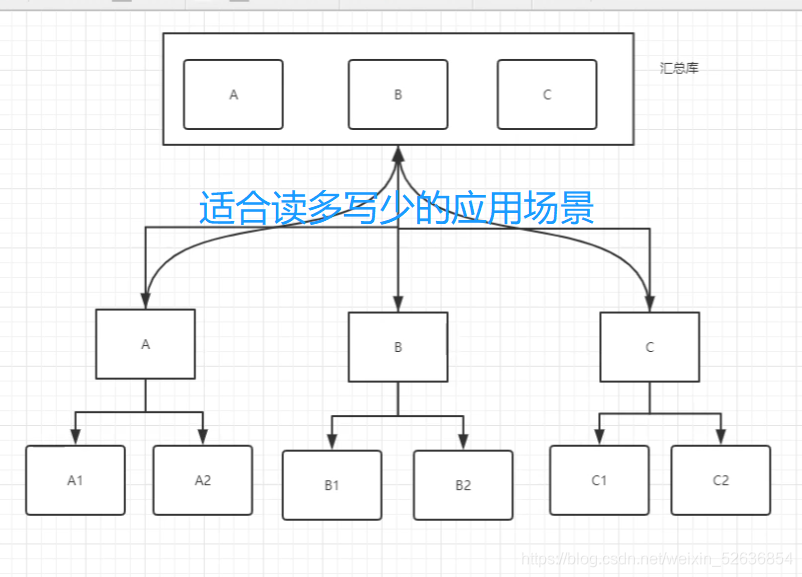
2. 性能
读多写少:读写分离方案
代表产品:Altas,ProxySQL,Maxscale,Mycat
读多写多:分布式方案
Mycat(DBLE),Atlas-sharing,sharing-jdbc
五、过滤复制(多台机器)
我们在授权主从用户的时候必须使用
mysql> grant replication slave on *.* to rep@'10.0.0.%' identified by 'oldboy123';
这里必须 *.* 不能指定库授权,因为 replication slave 是全局的,不用则报错
企业里或许有只想同步某一个库的需求,可能是因为环境多为了节省资源
企业里很多环境
1.开发环境:开发开发完自己测试
2.测试环境:
1)性能测试
2)功能测试
4.预发布环境(beta,内测不删档)、灰度环境、沙盒环境
5.生产环境
除了生产和预发布其他的环境都是虚拟机测试用的
测试环境有很多游戏,我就想一个从库同步一种游戏,还有合服,建新服,其实就是一个库或者一个表而已
创建角色总是提示改昵称已被创建,就是因为姓名也是唯一键
1.确认三台机器主从状态
show slave status\G
2.过滤复制两种方式
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 262 | 白名单 | 黑名单 | |
+------------------+----------+--------------+------------------+-------------------+
1)黑名单
不记录黑名单列出的库的二进制日志
#参数
--replicate-ignore-db
--replicate-ignore-table
--replicate-wild-ignore-table
2)白名单
只执行白名单中列出的库或者表的中继日志
#参数:
--replicate-do-db=test
--replicate-do-table=test.t1
--replicate-wild-do-table=test.t2
3.配置过滤复制
1)主库创建两个库
create database wzry;
create database yxlm;
2)从库1配置
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
replicate-do-db=wzry
[root@db02 ~]# systemctl restart mysql
#查看主从状态
show slave status;
3)从库2配置
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
replicate-do-db=yxlm
[root@db03 ~]# systemctl restart mysql
#查看主从状态
show slave status;
4)主库创建表测试
use wzry;
create table dianxin1;
use yxlm;
create table wangtong1;
5)从库查看表
#登陆两台数据库查看表是否存在
4.尝试把白名单配置到主库
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
replicate-do-db=yxlm
[root@db01 ~]# systemctl restart mysql
#测试同步
5.过滤复制总结:
#我们可以查看一下中继日志,其实数据都拿过来了,只不过他是读取配置文件过滤去执行sql的
在主库上设置白名单:只记录白名单设置的库或者表,相关的SQL语句到binlog中
在主库上设置黑名单:不记录黑名单设置的库或者表,相关的SQL语句到binlog中
在从库上设置白名单:IO线程会拿所有的binlog,但是SQL线程只执行白名单设置的库或者表相关的SQL语句
在从库上设置黑名单:IO线程会拿所有的binlog,但是SQL线程不执行黑名单设置的库或者表相关的SQL语句
#从库白名单,只同步某个库
replicate-do-db=test
#从库白名单,只同步某个库中的某个表
replicate-do-table=test.t1
replicate-do-table=test.c2
replicate-do-table=test.b3
replicate-do-table=test.a4
#从库白名单,只同步某个库中的以t开头的所有表
replicate-wild-do-table=test.t*














 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









