






title: pthread 实现线程同步功能的 Queue
urlname: queue-with-thread-synchronization
date: 2021-05-25 15:40:57
tags: [‘C/C++’, ‘linux’, ‘pthread’, ‘queue’, ‘synchronization’]
原文链接:https://www.foxzzz.com/queue-with-thread-synchronization/
这几天需要使用 pthread 实现了一个线程同步功能的 Queue,过程中踩了两个坑:
-
pthread_cond_wait() 需要放在 pthread_mutex_lock() 和 pthread_mutex_unlock() 之中,而不是之外,否则将发生死锁,这里的概念有点绕,需要理解 pthread_cond_wait() 是会释放当前的 lock,以便其他线程进入临界区,当其他线程 pthread_cond_signal() 的时候,wait 线程被唤醒,又重新获得锁;
-
pthread_cond_wait() 唤醒后需要再次条件判断,并且条件判断形式必须是 while 而不能是 if,之所以必须这样做的原因是pthread_cond_signal() 可能唤醒多个正处于 wait 状态的线程(多cpu情况),所以被唤醒的线程需要再次检测是否真有数据需要处理,如不需要处理应当继续进入 wait 以等待下次唤醒。
我将 Queue 实现成可支持一对一、一对多、多对一、多对多的线程同步机制,并写了一个简单的生产者消费者模型用以测试。完整程序如下,测试环境是 ubuntu 20.04:
/********************************************
* Queue with thread synchronization
* Copyright (C) i@foxzzz.com
*
* Using pthread implementation.
* Can be used in the producer-consumer model
* of one-to-one, one-to-many, many-to-one,
* many-to-many patterns.
*********************************************/
#include <iostream>
#include <sstream>
#include <vector>
#include <cstdio>
#include <sys/time.h>
#include <pthread.h>
#include <unistd.h>
/*!
* @brief queue with thread synchronization
*/
template<typename T>
class Queue {
public:
Queue(int capacity) :
front_(0),
back_(0),
size_(0),
capacity_(capacity),
cond_send_(PTHREAD_COND_INITIALIZER),
cond_receive_(PTHREAD_COND_INITIALIZER),
mutex_(PTHREAD_MUTEX_INITIALIZER) {
arr_ = new T[capacity_];
}
~Queue() {
delete[] arr_;
}
public:
/*!
* @brief data entry queue
* @param[in] data needs to be put into the queue
*/
void send(const T& data) {
pthread_mutex_lock(&mutex_);
while (full()) {
pthread_cond_wait(&cond_receive_, &mutex_);
}
enqueue(data);
pthread_mutex_unlock(&mutex_);
pthread_cond_signal(&cond_send_);
}
/*!
* @brief retrieve data from the queue
* @param[out] data retrieved from the queue
*/
void receive(T& data) {
pthread_mutex_lock(&mutex_);
while (empty()) {
pthread_cond_wait(&cond_send_, &mutex_);
}
dequeue(data);
pthread_mutex_unlock(&mutex_);
pthread_cond_signal(&cond_receive_);
}
private:
void enqueue(const T& data) {
arr_[back_] = data;
back_ = (back_ + 1) % capacity_;
++size_;
}
void dequeue(T& data) {
data = arr_[front_];
front_ = (front_ + 1) % capacity_;
--size_;
}
bool full()const {
return (size_ == capacity_);
}
bool empty()const {
return (size_ == 0);
}
private:
T* arr_;
int front_;
int back_;
int size_;
int capacity_;
pthread_cond_t cond_send_;
pthread_cond_t cond_receive_;
pthread_mutex_t mutex_;
};
/*!
* @brief a demonstration of queue operations
*/
template<typename T, typename Make>
class Demo {
public:
Demo(int capacity) :
queue_(capacity) {
start();
}
public:
/*!
* @brief generate the data and queue it(for producer thread)
* @param[in] origin The starting value of the data
* @param[in] count The amount of data to be generated
* @param[in] interval the time interval(ms) to enter the queue
*/
void send(int origin, int count, int interval) {
Make make;
while (count--) {
T data = make(origin);
queue_.send(data);
print("send", data);
usleep(interval * 1000);
}
}
/*!
* @brief retrieve data from the queue(for consumer thread)
* @param[in] interval the time interval(ms) to enter the queue
*/
void receive(int interval) {
while (true) {
T data;
queue_.receive(data);
print("receive", data);
usleep(interval * 1000);
}
}
private:
void print(const char* name, const T& data) {
char buffer[256] = { 0 };
sprintf(buffer, "[%-4lu ms][pid %lu][%-10s] ", elapsedMS(), pthread_self(), name);
std::stringstream ss;
ss << buffer;
ss << data;
ss << "\n";
std::cout << ss.str();
}
private:
void start() {
gettimeofday(&start_time_, nullptr);
}
long elapsedMS() const {
struct timeval current;
gettimeofday(¤t, nullptr);
return diffMS(start_time_, current);
}
static long diffMS(const timeval& start, const timeval& end) {
long seconds = end.tv_sec - start.tv_sec;
long useconds = end.tv_usec - start.tv_usec;
return (long)(((double)(seconds) * 1000 + (double)(useconds) / 1000.0) + 0.5);
}
private:
timeval start_time_;
Queue<T> queue_;
};
/*!
* @brief generates integer data
*/
class IntMake {
public:
IntMake() : count_(0) {
}
public:
int operator() (int origin) {
return (origin + count_++);
}
private:
int count_;
};
/*!
* @brief thread type
*/
enum {
TYPE_THREAD_SEND,
TYPE_THREAD_RECEIVE
};
/*!
* @brief thread arguments
*/
struct Args {
Args(Demo<int, IntMake>& demo, int type, int interval) :
demo(demo),
type(type),
interval(interval),
origin(0),
count(0) {
}
Args(Demo<int, IntMake>& demo, int type, int interval, int origin, int count) :
demo(demo),
type(type),
interval(interval),
origin(origin),
count(count) {
}
Demo<int, IntMake>& demo;
int type;
int interval;
int origin;
int count;
};
/*!
* @brief thread info
*/
struct ThreadInfo {
ThreadInfo(const Args& args) :
tid(0),
args(args) {
}
pthread_t tid;
Args args;
};
/*!
* @brief producer thread function
*/
void* thread_func_send(void* arg) {
Args* args = (Args*)arg;
args->demo.send(args->origin, args->count, args->interval);
return nullptr;
}
/*!
* @brief consumer thread function
*/
void* thread_func_receive(void* arg) {
Args* args = (Args*)arg;
args->demo.receive(args->interval);
return nullptr;
}
/*!
* @brief start to work
*/
void work(std::vector<ThreadInfo>& list) {
for (auto& it : list) {
switch (it.args.type) {
case TYPE_THREAD_SEND:
pthread_create(&it.tid, nullptr, thread_func_send, &it.args);
break;
case TYPE_THREAD_RECEIVE:
pthread_create(&it.tid, nullptr, thread_func_receive, &it.args);
break;
}
}
for (auto& it : list) {
pthread_join(it.tid, nullptr);
}
}
int main() {
Demo<int, IntMake> demo(10);
//configuration of the threads
std::vector<ThreadInfo> list = {
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 2, 1, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 2)),
};
work(list);
return 0;
}
程序配置了一个生产端线程,一个消费端线程,生产端和消费端效率都设置成2ms:
Demo<int, IntMake> demo(10);
//configuration of the threads
std::vector<ThreadInfo> list = {
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 2, 1, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 2)),
};
从程序打印输出结果看,生产端和消费端类似于回合制:

修改配置,降低消费端效率,由原来的2ms修改为20ms:
Demo<int, IntMake> demo(10);
//configuration of the threads
std::vector<ThreadInfo> list = {
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 2, 1, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 20)),
};
从程序打印输出结果看,当队列满后(队列容量设置为10),生产端需要等待消费端从队列中拿走数据后方可再生产:
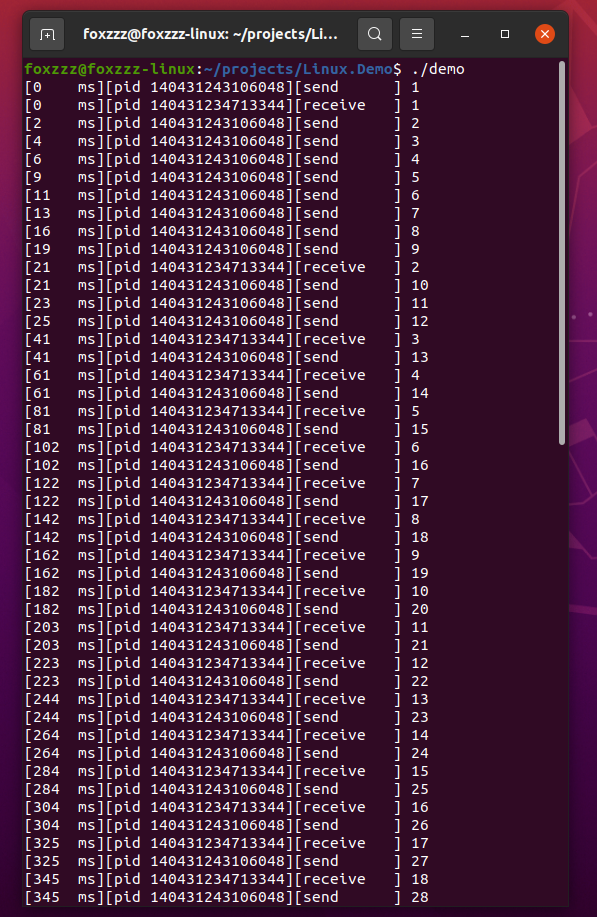
修改配置,降低生产端效率,由原来的2ms修改为20ms:
Demo<int, IntMake> demo(10);
//configuration of the threads
std::vector<ThreadInfo> list = {
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 20, 1, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 2)),
};
从程序打印输出结果看,生产端和消费端又类似于回合制,这是因为消费端效率高,它得等到生产端生产:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DfWNyZ6e-1658649371666)(https://www.foxzzz.com/queue-with-thread-synchronization/3.png)]
修改配置,生产端数量增加到3,消费端数量不变,生产端效率是20ms,消费端效率是2ms:
Demo<int, IntMake> demo(10);
//configuration of the threads
std::vector<ThreadInfo> list = {
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 20, 1, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 20, 51, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 20, 101, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 2)),
};
从程序打印输出结果看,消费端效率还是远高于生产端,即便生产端有3个,但无法填满队列:

修改配置,生产端数量依然是3,消费端数量变为2,生产端效率是10ms,消费端效率是2ms:
Demo<int, IntMake> demo(10);
//configuration of the threads
std::vector<ThreadInfo> list = {
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 10, 1, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 10, 51, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_SEND, 10, 101, 50)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 2)),
ThreadInfo(Args(demo, TYPE_THREAD_RECEIVE, 2)),
};
程序打印输出呈现多对多模式:

以上是几个示例的演示,配置比较简单,可按自己意思设计(创建生产端另外的两个参数一个是起始数值,一个是生产数量)。















 5397
5397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









