






WeakHashMap源码解析
简介
WeakHashMap 是一种 弱引用 map,内部的 key 会存储为弱引用,当 jvm gc 的时候,如果这些 key 没有强引用存在的话,会被 gc 回收掉,下一次当我们操作 map 的时候会把对应的 Entry 整个删除掉,基于这种特性,WeakHashMap 特别适用于 缓存 处理。
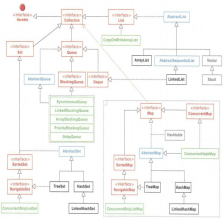
继承体系

可见,WeakHashMap 没有实现 Clone 和 Serializable 接口,所以不具有克隆和序列化的特性。
存储结构
WeakHashMap 因为 gc 的时候会把没有强引用的 key 回收掉,所以注定了它里面的元素不会太多,因此也就不需要像 HashMap 那样元素多的时候转化为红黑树来处理了。
因此,WeakHashMap 的存储结构只有 (数组 + 链表) 。
源码解析
属性
/*
* 默认初始容量为16
*/
private static final int DEFAULT_INITIAL_CAPACITY = 16;
/*
* 最大容量为2的30次方
*/
private static final int MAXIMUM_CAPACITY = 1 << 30;
/*
* 默认装载因子
*/
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
/*
* 桶
*/
Entry<K,V>[] table;
/*
* 元素个数
*/
private int size;
/*
* 扩容门槛,等于capacity * loadFactor
*/
private int threshold;
/*
* 装载因子
*/
private final float loadFactor;
/*
* 引用队列,当弱键失效的时候会把Entry添加到这个队列中
*/
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
(1)容量
- 容量为数组的长度,亦即桶的个数,默认为 16,最大为 2 的 30 次方,当容量达到 64 时才可以树化。
(2)装载因子
- 装载因子用来计算容量达到多少时才进行扩容,默认装载因子为 0.75。
(3)引用队列
- 当弱键失效的时候会把 Entry 添加到这个队列中,当下次访问 map 的时候会把失效的 Entry 清除掉。
内部类Entry
WeakHashMap 内部的存储节点,没有 key 属性。
// 继承与弱引用类WeakReference
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
// 可以发现没有key,因为key是作为弱引用存到Reference类中
V value;
final int hash;
Entry<K,V> next;
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
// 调用WeakReference的构造方法初始化key和引用队列
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
}
public class WeakReference<T> extends Reference<T> {
public WeakReference(T referent, ReferenceQueue<? super T> q) {
// 调用Reference的构造方法初始化key和引用队列
super(referent, q);
}
}
public abstract class Reference<T> {
// 实际存储key的地方
private T referent; /* Treated specially by GC */
// 引用队列
volatile ReferenceQueue<? super T> queue;
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}
}
从 Entry 的构造方法我们知道,key 和 queue 最终会传到到 Reference 的构造方法中,这里的 key 就是 Reference 的 referent 属性,它会被 gc 特殊对待,即当没有强引用存在时,当下一次 gc 的时候会被清除。
构造方法
/*
* 下面三个构造方法都是调用的这个构造方法
* @param initialCapacity:初始容量
* @param loadFactor:初始负载因子
*/
public WeakHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Initial Capacity: "+
initialCapacity);
// 如果初始容量超过了最大容量,则赋值为最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load factor: "+
loadFactor);
// capacity赋值为1
int capacity = 1;
// 如果capacity小于传进来的initialCapacity
// while一直循环,直到出现一个 2的n次方的值 大于传入容量,则就是初始容量
while (capacity < initialCapacity)
// 将capacity左移一位,也就是capacity = capacity * 2
capacity <<= 1;
// 创建一个容量为 大于等于传入容量最近的2的n次方的Entry数组
table = newTable(capacity);
this.loadFactor = loadFactor;
// 扩容阈值
threshold = (int)(capacity * loadFactor);
}
public WeakHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public WeakHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public WeakHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR);
putAll(m);
}
构造方法与 HashMap 基本类似,初始容量为大于等于传入容量最近的 2 的 n 次方,扩容门槛 threshold 等于 capacity * loadFactor。
put(K key, V value)
- 添加元素的方法。
public V put(K key, V value) {
// 如果key为空,用空对象代替
Object k = maskNull(key);
// 计算key的hash值
int h = hash(k);
// 获取桶
Entry<K,V>[] tab = getTable();
// 计算元素在哪个桶中,h & (length-1)
int i = indexFor(h, tab.length);
// 遍历桶对应的链表
for (Entry<K,V> e = tab[i]; e != null; e = e.next) {
if (h == e.hash && eq(k, e.get())) {
// 如果找到了元素就使用新值替换旧值,并返回旧值
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
modCount++;
// 如果没找到就把新值插入到链表的头部
Entry<K,V> e = tab[i];
tab[i] = new Entry<>(k, value, queue, h, e);
// 如果插入元素后数量达到了扩容门槛就把桶的数量扩容为2倍大小
if (++size >= threshold)
resize(tab.length * 2);
return null;
}
(1)计算 hash;
-
这里与 HashMap 有所不同,HashMap 中如果 key 为空直接返回 0,这里是用空对象来计算的。
-
另外打散方式也不同,HashMap 只用了一次异或,这里用了四次,HashMap 给出的解释是一次够了,而且就算冲突了也会转换成红黑树,对效率没什么影响。
(2)计算在哪个桶中;
(3)遍历桶对应的链表;
(4)如果找到元素就用新值替换旧值,并返回旧值;
(5)如果没找到就在链表头部插入新元素;
- HashMap 就插入到链表尾部。
(6)如果元素数量达到了扩容门槛,就把容量扩大到 2 倍大小;
- HashMap中是大于 threshold 才扩容,这里等于 threshold 就开始扩容了。
resize(int newCapacity)
- 扩容方法。
void resize(int newCapacity) {
// 获取旧桶,getTable()的时候会剔除失效的Entry(key为null,被gc回收),因为调用了expungeStaleEntries()方法,下文会讲
Entry<K,V>[] oldTable = getTable();
// 旧容量
int oldCapacity = oldTable.length;
// 如果就容量已经等于table最大容量,则直接赋值为int最大值 并返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新桶
Entry<K,V>[] newTable = newTable(newCapacity);
// 把元素从旧桶转移到新桶
transfer(oldTable, newTable);
// 把新桶赋值桶变量
table = newTable;
// 如果元素个数大于扩容门槛的一半,则使用新桶和新容量,并计算新的扩容门槛
if (size >= threshold / 2) {
threshold = (int)(newCapacity * loadFactor);
} else {
/*
* 否则把元素再转移回旧桶,还是使用旧桶
* 因为在transfer()的时候会清除失效的Entry,所以元素个数可能没有那么大了,就不需要扩容了
*/
// 再次清理过期的Entry
expungeStaleEntries();
transfer(newTable, oldTable);
table = oldTable;
}
}
private void transfer(Entry<K,V>[] src, Entry<K,V>[] dest) {
// 遍历旧桶
for (int j = 0; j < src.length; ++j) {
// 拿到当前桶位的元素
Entry<K,V> e = src[j];
// 将当前桶位置为null
src[j] = null;
// 遍历该桶位的链表
while (e != null) {
Entry<K,V> next = e.next;
// 获取当前元素的key
Object key = e.get();
// 如果key等于了null就清除,说明key被gc清理掉了,则把整个Entry清除
if (key == null) {
e.next = null; // Help GC
e.value = null; // " "
size--;
} else {
// 否则就计算在新桶中的位置并把这个元素放在新桶对应链表的头部
int i = indexFor(e.hash, dest.length);
e.next = dest[i];
dest[i] = e;
}
e = next;
}
}
}
(1)判断旧容量是否达到最大容量;
(2)新建新桶并把元素全部转移到新桶中;
(3)如果转移后元素个数不到扩容门槛的一半,则把元素再转移回旧桶,继续使用旧桶,说明不需要扩容;
(4)否则使用新桶,并计算新的扩容门槛;
(5)转移元素的过程中会把 key 为 null 的元素清除掉,所以 size 会变小;
get(Object key)
- 获取元素。
public V get(Object key) {
// 如果key为空,用空对象代替
Object k = maskNull(key);
// 计算hash
int h = hash(k);
// 返回table,并做一次expungeStaleEntries()
Entry<K,V>[] tab = getTable();
// 计算下标
int index = indexFor(h, tab.length);
// 找到所在的桶
Entry<K,V> e = tab[index];
// 遍历链表,找到了就返回
while (e != null) {
if (e.hash == h && eq(k, e.get()))
return e.value;
e = e.next;
}
// 没找到则返回null
return null;
}
(1)计算 hash 值;
(2)遍历所在桶对应的链表;
(3)如果找到了就返回元素的 value 值;
(4)如果没找到就返回空;
remove(Object key)
- 移除元素。
public V remove(Object key) {
// 如果key为空,用空对象代替
Object k = maskNull(key);
// 计算hash
int h = hash(k);
// 返回table,并做一次expungeStaleEntries()
Entry<K,V>[] tab = getTable();
// 计算下标
int i = indexFor(h, tab.length);
// 元素所在的桶的第一个元素
Entry<K,V> prev = tab[i];
Entry<K,V> e = prev;
// 遍历链表
while (e != null) {
Entry<K,V> next = e.next;
if (h == e.hash && eq(k, e.get())) {
// 如果找到了就删除元素
modCount++;
size--;
if (prev == e)
// 如果是头节点,就把头节点指向下一个节点
tab[i] = next;
else
// 如果不是头节点,删除该节点
prev.next = next;
// 返回该节点的value值
return e.value;
}
// 向后迭代
prev = e;
e = next;
}
// 没找到则返回null
return null;
}
(1)计算 hash;
(2)找到所在的桶;
(3)遍历桶对应的链表;
(4)如果找到了就删除该节点,并返回该节点的 value 值;
(5)如果没找到就返回 null;
expungeStaleEntries()
- 剔除失效的 Entry(key 为 null,被 gc 回收)。
/*
* 当key失效的时候gc会自动把对应的Entry添加到引用队列中
* 此方法就是将引用队列中所有的Entry从map中剔除掉
*/
private void expungeStaleEntries() {
// 遍历引用队列
for (Object x; (x = queue.poll()) != null; ) {
// 加锁
synchronized (queue) {
@SuppressWarnings("unchecked")
// 拿到当前出队元素
Entry<K,V> e = (Entry<K,V>) x;
// 计算下标
int i = indexFor(e.hash, table.length);
// 找到所在的桶
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
// 遍历链表
while (p != null) {
Entry<K,V> next = p.next;
// 找到该元素
if (p == e) {
// 删除该元素
if (prev == e)
// 如果是头节点,就把头节点指向下一个节点
table[i] = next;
else
// 如果不是头节点,删除该节点
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
// 将value置为null
e.value = null; // Help GC
size--;
break;
}
// 向后迭代
prev = p;
p = next;
}
}
}
}
(1)当 key 失效的时候 gc 会自动把对应的 Entry 添加到这个引用队列中;
(2)所有对 map 的操作都会直接或间接地调用到这个方法先移除失效的 Entry,比如 getTable()、size()、resize();
(3)这个方法的目的就是遍历引用队列,并把其中保存的 Entry 从 map 中移除掉,具体的过程请看类注释;
(4)从这里可以看到移除 Entry 的同时把 value 也一并置为 null 帮助 gc 清理元素,防御性编程。
使用案例
import java.util.Map;
import java.util.WeakHashMap;
public class WeakHashMapTest {
public static void main(String[] args) {
Map<String, Integer> map = new WeakHashMap<>(3);
// 放入3个new String()声明的字符串
map.put(new String("1"), 1);
map.put(new String("2"), 2);
map.put(new String("3"), 3);
// 放入不用new String()声明的字符串
map.put("6", 6);
// 使用key强引用"3"这个字符串
String key = null;
for (String s : map.keySet()) {
// 这个"3"和new String("3")不是一个引用
if (s.equals("3")) {
key = s;
}
}
// 输出{6=6, 1=1, 2=2, 3=3},未gc所有key都可以打印出来
System.out.println(map);
// gc一下
System.gc();
// 放一个new String()声明的字符串
map.put(new String("4"), 4);
// 输出{4=4, 6=6, 3=3},gc后放入的值和强引用的key可以打印出来
System.out.println(map);
// key与"3"的引用断裂
key = null;
// gc一下
System.gc();
// 输出{6=6},gc后强引用的key可以打印出来
System.out.println(map);
}
}
在这里通过 new String() 声明的变量才是弱引用,使用 “6” 这种声明方式会一直存在于常量池中,不会被清理,所以 “6” 这个元素会一直在 map 里面,其它的元素随着 gc 都会被清理掉。
总结
(1)WeakHashMap 使用 (数组 + 链表) 存储结构;
- 单纯作为 Map 没有 HashMap 好:HashMap 在 jdk8 做了很多优化,比如单链表在过长时会转化为红黑树,降低极端
情况下的操作复杂度。但 WeakHashMap 没有相应的优化,有点像 jdk8 之前的 HashMap 版本。
(2)WeakHashMap 中的 key 是 弱引用,gc 的时候会被清除;
(3)每次对 map 的操作都会剔除失效 key 对应的 Entry;
(4)使用 String 作为 key 时,一定要使用 new String() 这样的方式声明 key,才会失效,其它的基本类型的包装类型是一样的;
(5)WeakHashMap 常用来作为 缓存 使用;
参考文章















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











