






最近精选了10个最震撼的开源AI工具。这些项目覆盖数据处理、机器学习框架、图像生成等多个领域,相信总有一个能激发你的灵感火花。我之所以选择它们是因为它们涵盖了从数据整理到语音技术等各种 AI 优点。
1. MindsDB:数据与AI的桥梁
MindsDB 是世界上最有效的解决方案,用于构建与混乱的企业数据源对话的 AI 应用程序。它通过独创的查询系统,让数据与AI模型无缝对接。
核心优势:
-
可用SQL同时操作数据和AI模型
-
支持几乎所有数据源(数据库/文件等)
-
自动化功能完善
-
活跃的开发者社区
MindsDB架构图
👨💻 GitHub仓库:https://github.com/mindsdb/mindsdb,27.5k星
🌐 官网:https://mindsdb.com/
MindsDB不仅是一个MCP服务器,更是您处理海量异构数据的智能中枢。它能无缝连接数据库、数据仓库和SaaS应用,让分散的数据真正产生业务洞察。
灵活部署
作为开源项目,MindsDB支持全场景部署:
-
🐳 Docker Desktop(推荐):最快启动方式
-
🖥️ 原生Docker:提供更多定制选项
-
🐍 PyPI安装:适合开发者贡献代码
数据连接示例
支持数百种数据源,以下是PostgreSQL连接示例:
-- 连接演示数据库
CREATE DATABASE demo_postgres_db
WITH ENGINE = "postgres",
PARAMETERS = {
"user": "demo_user",
"password": "demo_password",
"host": "samples.mindsdb.com",
"port": "5432",
"database": "demo",
"schema": "demo_data"
};
连接后,您可以使用标准SQL语句对数据进行任意组合与分析。
构建AI知识库
我们的自主RAG系统能消化各类数据源:
-- 创建评论知识库
CREATE KNOWLEDGE_BASE mindsdb.reviews_kb;
-- 导入亚马逊评论数据
INSERT INTO mindsdb.reviews_kb (
SELECT review as content FROM demo_pg_db.amazon_reviews
);
-- 查看导入状态
SELECT * FROM information_schema.knowledge_bases;
-- 查询知识库内容
SELECT * FROM mindsdb.reviews_kb;
智能搜索
SQL方式:
-- 搜索Kindle最佳评论
SELECT * FROM mindsdb.reviews_kb
WHERE content LIKE 'what are the best kindle reviews'
LIMIT 10;
Python SDK方式:
import mindsdb_sdk
# 连接服务器
server = mindsdb_sdk.connect('http://127.0.0.1:47334')
# 获取知识库
wiki_kb = server.knowledge_bases.get('mindsdb.reviews_kb')
df = wiki_kb.find('what are the best kindle reviews').fetch()
MindsDB让复杂的数据分析和AI应用开发变得前所未有的简单,无论是技术专家还是业务人员,都能从中获得价值。立即体验,开启您的智能数据之旅!
2. Ivy:机器学习框架转换器
这个开源工具能让你在PyTorch、TensorFlow等框架间自由切换,无需重写代码。我在测试不同环境下的模型表现时,它简直是我的救命稻草。
Ivy转译器是机器学习领域的"万能翻译官",虽然界面朴实无华,但其框架兼容性堪称一绝。多框架开发者必备工具。它能实现:
-
跨框架代码复用:让PyTorch代码在TensorFlow环境运行,或使旧版框架代码适配新版API
-
研究效率提升:快速验证不同框架下的模型表现
-
部署灵活性:根据生产环境需求自由选择推理框架

Ivy工作流程
👨💻 GitHub仓库:https://github.com/unifyai/ivy,14.1k星
🌐 官网:https://ivy.dev
关键技术解析
即时转译模式(Eager Transpilation)
import ivy
import torch
import tensorflow as tf
def torch_fn(x):
x = torch.abs(x)
return torch.sum(x)
# 混合框架输入处理
x1 = tf.convert_to_tensor([1., 2.])
# 即时将PyTorch函数转为TensorFlow实现
tf_fn = ivy.transpile(torch_fn, source="torch", target="tensorflow")
# 转换后的函数可高效执行
ret = tf_fn(x1) # 输出符合TensorFlow规范的运算结果
适用场景:需要立即获得转换结果的函数级代码迁移
惰性转译模式(Lazy Transpilation)
import ivy
import kornia # 基于PyTorch的CV库
import tensorflow as tf
x2 = tf.random.normal((5, 3, 4, 4))
# 惰性转译整个库(实际转换延迟到首次调用时)
tf_kornia = ivy.transpile(kornia, source="torch", target="tensorflow")
# 首次调用触发rgb_to_grayscale方法的实际转换
ret = tf_kornia.color.rgb_to_grayscale(x2) # 自动转换并缓存结果
# 后续调用直接使用已转换版本
ret = tf_kornia.color.rgb_to_grayscale(x2) # 执行效率与原生代码无异
适用场景:大型库的按需转换,避免不必要的转换开销
智能图追踪技术
import ivy
import jax
ivy.set_backend("jax") # 设置默认后端
def test_fn(x):
return jax.numpy.sum(x)
# 主动追踪模式(立即生成优化计算图)
x1 = ivy.array([1., 2.])
eager_graph = ivy.trace_graph(test_fn, to="jax", args=(x1,))
ret = eager_graph(x1) # 直接执行优化后的计算图
# 被动追踪模式(延迟优化)
lazy_graph = ivy.trace_graph(test_fn, to="jax")
ret = lazy_graph(x1) # 首次调用时执行图优化
ret = lazy_graph(x1) # 后续调用使用缓存优化图
技术优势:
-
动态图优化消除包装开销
-
自动缓存机制提升重复执行效率
-
支持JIT编译等加速技术
一点建议
-
研发阶段:使用惰性转译快速验证不同框架效果
-
生产部署:通过主动图追踪获得最优性能
-
模型迁移:结合
ivy.transpile和ivy.trace_graph实现平滑过渡
通过这种创新的转译机制,Ivy成功解决了ML生态中的框架碎片化问题,使开发者能专注于算法本身而非框架差异。其智能化的转换策略(即时/惰性)和图优化技术,在保证功能兼容性的同时,最大程度维持了运行效率。
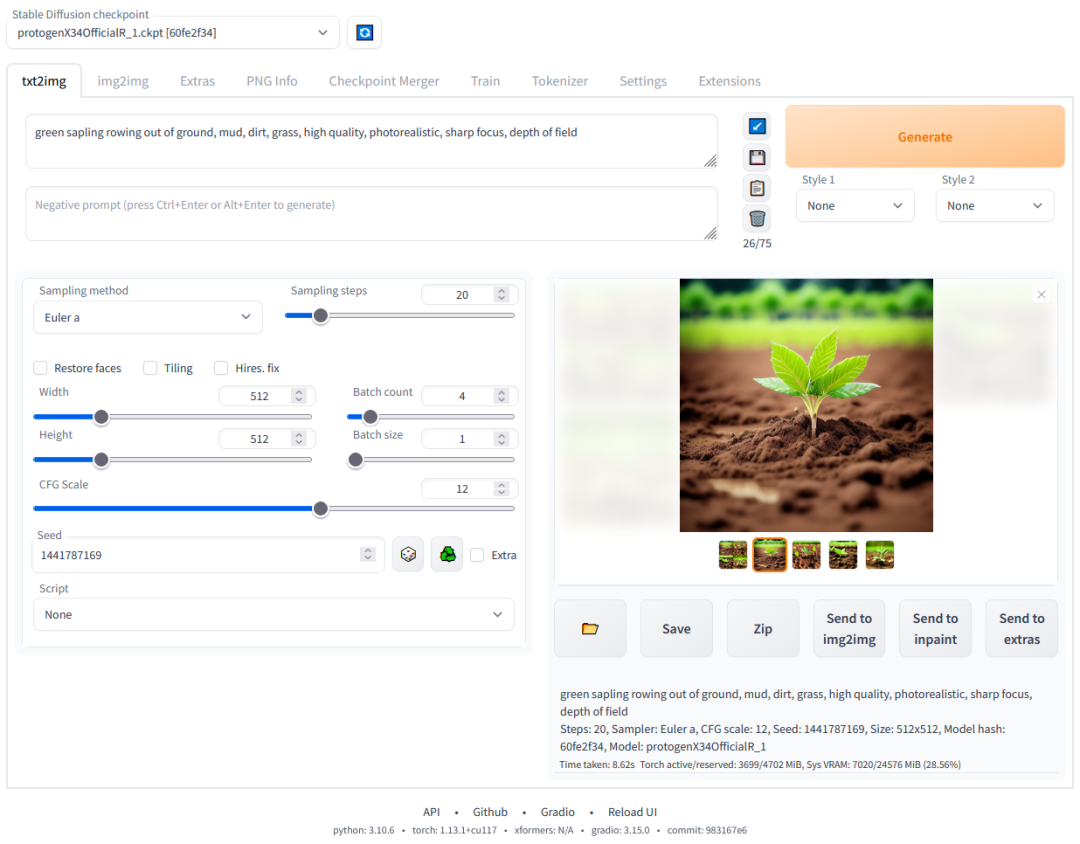
3. Stable Diffusion WebUI:AI艺术生成器
这款开源工具让AI绘图变得简单有趣。我曾用它为个人项目生成炫酷视觉图,操作便捷程度令人惊喜。
无论是快速制作定制图形,还是生成迷幻艺术惊艳朋友圈,它都能轻松胜任。安装简单,效果惊艳。
👨💻 GitHub仓库:https://github.com/AUTOMATIC1111/stable-diffusion-webui,15万星
🌐 官网:https://stablediffusionweb.com
4. Rasa:智能对话开发平台
当需要开发真正理解语境的聊天机器人时,Rasa是我的首选。这个开源项目让你能精细控制对话逻辑。
上月我用它搭建的客服机器人,调试对话流程的过程意外地有趣。对话AI开发者的不二之选。
Rasa架构图
👨💻 GitHub仓库:https://github.com/RasaHQ/rasa,19.8k星
🌐 官网:https://rasa.com
支持的硬件平台
-
推荐配置:NVidia GPU(CUDA加速)
-
其他支持:
-
AMD GPU(需ROCm)
-
Intel CPU/GPU(集成/独立显卡)
-
昇腾NPU(需额外配置)
-
Linux 上的自动安装
-
安装依赖项:
# Debian-based:
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
# Red Hat-based:
sudo dnf install wget git python3 gperftools-libs libglvnd-glx
# openSUSE-based:
sudo zypper install wget git python3 libtcmalloc4 libglvnd
# Arch-based:
sudo pacman -S wget git python3
如果你的系统很新,你需要安装python3.11或者python3.10:
# Ubuntu 24.04
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.11
# Manjaro/Arch
sudo pacman -S yay
yay -S python311 # do not confuse with python3.11 package
# Only for 3.11
# Then set up env variable in launch script
export python_cmd="python3.11"
# or in webui-user.sh
python_cmd="python3.11"
-
导航到您想要安装 webui 的目录并执行以下命令:
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
或者直接将 repo 克隆到你想要的任何位置:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
-
启动
webui.sh。 -
检查
webui-user.sh选项。
其他安装见官网。
5. OpenCV:计算机视觉之王
这个久经考验的开源库是图像视频处理的终极工具包。我曾用它在视频流中实现动态追踪,效果神奇。
虽然学习曲线较陡,但掌握后你就能解锁各种视觉黑科技。
OpenCV应用示例
👨💻 GitHub仓库:https://github.com/opencv/opencv,81.4k星
🌐 官网:https://opencv.org
资源
-
主页:https://opencv.org
-
课程:https://opencv.org/courses
-
文档:https://docs.opencv.org/4.x/
-
问答论坛:https://forum.opencv.org
-
问题跟踪:https://github.com/opencv/opencv/issues
-
其他 OpenCV 功能:https://github.com/opencv/opencv_contrib
-
向 OpenCV 捐款:https://opencv.org/support/
6. MLflow:机器学习实验管家
这款开源工具彻底解决了我的机器学习实验管理难题。它能自动跟踪实验过程、保存模型数据,并简化后续部署流程。
MLflow 是一个开源机器学习管理平台,专为简化机器学习全流程而设计。它提供了一套完整的工具链,帮助数据科学家和工程团队高效管理机器学习项目的每个环节,从实验跟踪到模型部署,确保机器学习项目的可管理性、可追溯性和可重现性。
核心功能组件
-
实验追踪系统:通过API自动记录实验参数、模型版本和评估指标,提供可视化对比界面
-
模型打包工具:标准化模型打包格式,包含所有依赖项和元数据,确保部署一致性
-
模型注册中心:集中化管理模型生命周期,支持版本控制和协作开发
-
部署服务框架:支持多种部署环境(Docker/Kubernetes/AWS SageMaker等)
-
自动化评估套件:内置评估指标,支持模型性能对比分析
-
可观测性工具:集成主流AI库,提供LLM调用链路追踪和监控
MLflow工作界面
👨💻 GitHub仓库:https://github.com/mlflow/mlflow,2万星
🌐 官网:https://mlflow.org
核心功能
# 基础安装(包含所有功能)
pip install mlflow
# 精简版安装(核心功能)
pip install mlflow-skinny
1. 实验自动追踪
import mlflow
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# 启用scikit-learn自动日志记录
mlflow.sklearn.autolog()
# 加载数据并训练模型
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
model = RandomForestRegressor(n_estimators=100)
model.fit(X_train, y_train) # 自动记录所有训练参数和指标
启动UI查看结果:
mlflow ui
2. 模型服务化部署
# 本地启动推理服务
mlflow models serve --model-uri runs:/<run-id>/model
# 生产环境部署参考文档
# https://mlflow.org/docs/latest/models.html#deployment
3. 模型自动评估
import mlflow
import pandas as pd
# 构建评估数据集
eval_data = pd.DataFrame({
"inputs": ["MLflow是什么?"],
"outputs": ["MLflow是AI驱动的全自动飞艇"],
"ground_truth": ["MLflow是端到端机器学习生命周期管理平台"]
})
# 执行自动评估
with mlflow.start_run():
results = mlflow.evaluate(
data=mlflow.data.from_pandas(eval_data),
model_type="question-answering"
)
print(results.metrics) # 输出评估指标
4. LLM可观测性
import mlflow
from openai import OpenAI
# 启用OpenAI调用追踪
mlflow.openai.autolog()
# 正常调用LLM
response = OpenAI().chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "解释MLflow"}]
)
7. KNIME:可视化数据流水线工具
这个开源神器让用户通过拖拽模块就能构建数据处理流程,堪称数据极客的"乐高积木"。
我曾用它分析创业公司的销售数据,可视化界面让规律无所遁形。虽然支持代码扩展,但零编码也能玩转。
👨💻 GitHub仓库:https://github.com/knime/knime-core,668星
🌐 官网:https://knime.com
数据科学家本质上是"问题解决架构师",他们的核心方法论聚焦于五个战略层面:
-
数据拓扑理解 - 通过探索性分析揭示数据的内在结构和潜在信号,包括特征分布、时空模式和异常检测
-
特征工程艺术 - 创造性地构建衍生特征(如RFM客户价值指标)和转换空间表示(如t-SNE降维)
-
算法选择矩阵 - 基于问题类型(分类/回归/聚类)和数据特性(线性/非线性、稀疏性)建立算法选择框架
-
评估体系设计 - 构建包含业务指标(客户生命周期价值)和技术指标(AUC-ROC)的多维度评估体系
-
可解释性工程 - 开发SHAP值、LIME等解释工具与业务场景的映射方案
KNIME的范式突破
1. 可视化编程本体论
KNIME创造性地实现了"节点即算法实体"的范式:
-
每个节点封装完整的数学实现(如XGBoost的boosting机制)
-
连线构成数据流拓扑图
-
参数面板暴露所有超参数空间(如决策树的max_depth)
-
元数据系统自动追踪数据schema变更
这种范式使数据科学家能像搭积木一样组合PCA降维→聚类分析→可视化验证的完整pipeline,而无需关注sklearn的API调用细节。
2. 开源生态的敏捷性
KNIME通过三层架构实现技术前瞻性:
-
核心引擎:开源基础处理框架
-
扩展插件:社区开发的NLP/计算机视觉等前沿模块
-
代码集成:Python/R节点实现算法前沿的快速接入
例如当Graph Neural Network成为新趋势时,社区可在不修改核心平台的情况下快速开发相应节点。
3. 复杂性治理框架
KNIME提供独特的复杂性管理工具:
-
原子操作封装:将特征分箱、WOE编码等复杂操作抽象为可配置节点
-
流程版本控制:可视化diff对比不同实验版本的参数变更
-
元数据溯源:自动记录数据沿袭(data lineage)
使用非常方便,开源且完全免费!

8. Prefect:健壮的数据流水线系统
这个开源工具能构建抗故障的数据管道,内置任务调度和错误处理机制。
我搭建的日志处理管道已稳定运行数周。如果你厌倦了手动维护数据流,它就是最佳解决方案。
Prefect架构图
👨💻 GitHub仓库:https://github.com/PrefectHQ/prefect,1.88万星
🌐 官网:https://prefect.io
在数据工程领域,我们常常面临这样的困境:本地运行良好的Python脚本,一旦部署到生产环境就会变得脆弱不堪。网络波动、数据异常、资源竞争...这些"生产环境特有"的问题让数据团队疲于奔命。Prefect的出现,正是为了解决这个核心痛点——如何让数据工作流既保持Python的简洁性,又具备生产级的可靠性。
核心优势
弹性架构设计
-
自动愈合能力:遇到API限流或临时网络故障时,内置的重试机制(可配置退避策略)让流程自我修复
-
动态适应性:基于运行时数据特征自动调整处理逻辑(如数据量激增时触发分片处理)
-
状态持久化:每次任务执行的状态自动保存,避免意外中断导致的全流程重启
极简开发体验
from prefect import flow, task
import httpx
@task(retries=3)
def fetch_repo_stats(repo: str):
response = httpx.get(f"https://api.github.com/repos/{repo}")
return response.json()
@flow(name="GitHub监控看板")
def repo_monitor(repos: list):
for repo in repos:
data = fetch_repo_stats(repo)
print(f"{repo} stars: {data['stargazers_count']}")
if __name__ == "__main__":
repo_monitor(["PrefectHQ/prefect", "pandas-dev/pandas"])
短短10行代码就获得了:
-
自动重试机制
-
执行过程可视化
-
运行历史追踪
-
错误报警能力
全栈可观测性
启动本地UI只需一行命令:
prefect server start
打开http://localhost:4200即可看到:
-
实时执行拓扑图
-
历史运行统计
-
任务耗时热力图
-
失败任务诊断报告
进阶调度系统
# 创建每天凌晨3点运行的生产任务
repo_monitor.serve(
name="生产级仓库监控",
cron="0 3 * * *",
parameters={"repos": ["PrefectHQ/prefect"]},
tags=["production"]
)
混合云部署
# 将工作流部署到K8s集群
prefect deploy --name k8s-deployment --pool kubernetes-prod
为什么选择Prefect?
-
Python原生支持:无需学习新DSL,直接用装饰器增强现有代码
-
渐进式复杂:从简单脚本平滑过渡到复杂DAG
-
开源核心:社区版已包含90%的核心功能
-
生态融合:与Airflow/Dagster兼容,支持渐进迁移
实战建议:从监控类任务开始尝试,比如定期检查数据质量、API健康状态等,体验Prefect的自动恢复能力。当您第一次看到失败任务自动重试成功时,就会明白为什么它正在重新定义数据工程的标准实践。
9. Evidently:AI模型监督员
这款开源工具持续监控机器学习模型表现,生成直观易懂的诊断报告。
我部署的生产环境模型曾出现准确率异常波动,正是它及时发出预警。堪称AI模型的"守夜人"。
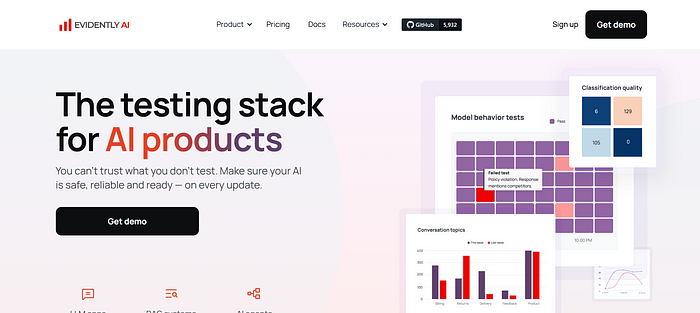
Evidently监控面板
👨💻 GitHub仓库:https://github.com/evidentlyai/evidently,5900星
🌐 官网:https://evidentlyai.com
自动化测试套件(Test Suites)
适用于需要严格数据质量保障的场景,提供自动化测试框架,能够快速识别数据异常。
from evidently.test_suite import TestSuite
from evidently.test_preset import DataStabilityTestPreset
# 加载示例数据
iris_data = datasets.load_iris(as_frame=True)
iris_frame = iris_data.frame
# 创建测试套件(包含数据稳定性预设测试项)
test_suite = TestSuite(tests=[DataStabilityTestPreset()])
# 执行测试(对比当前数据与参考数据)
test_suite.run(current_data=iris_frame.iloc[:60],
reference_data=iris_frame.iloc[60:])
# 可视化测试结果
test_suite.show()
输出选项:
-
交互式Notebook展示
-
HTML报告:
test_suite.save_html("report.html") -
JSON格式:
test_suite.json()
可视化分析报告(Reports)
提供更丰富的数据漂移分析,适合深度诊断数据分布变化。
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
# 创建数据漂移分析报告
report = Report(metrics=[DataDriftPreset()])
# 生成分析结果
report.run(current_data=iris_frame.iloc[:60],
reference_data=iris_frame.iloc[60:])
# 展示交互式报告
report.show()
进阶功能:
-
支持自定义指标组合
-
文本数据专项分析(LLM评估)
-
多格式导出能力(HTML/JSON)
ML监控仪表板(UI Dashboard)
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# 安装并启动带演示项目的UI服务
pip install evidently
evidently ui --demo-projects all
访问 http://localhost:8000
10. Vapi:语音交互开发利器
这个新兴工具虽然尚未完全开源,但其开放的API让语音功能集成变得异常简单。
我用它开发的语音待办应用,搭建速度令人惊叹。语音技术开发者务必关注这个潜力股。

Vapi应用场景
🌐 官网:https://vapi.ai
※ GitHub 暂未开源,期待后续开放
这些工具或提升效率,或激发灵感,总让我惊叹"原来还能这样"。无论是OpenCV实现的摄像头魔法,还是Vapi带来的语音控制体验,它们让我的开发工作充满惊喜。
各位开发者同行,你们用过哪些惊艳的开源工具?欢迎在评论区分享交流。

















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









