








MarkDown编辑语法
bpftrace是一款基于BPF和BCC的开源跟踪器。和BCC一样,bpftrace自带了许多性能工具和支持文档。它同时还提供了一个高级编程语言环境,可以用来创建强大的单行程序和小工具。比如,下面的单行程序以直方图形式统计vfs_read() 的返回值(读取的字节数或错误码) :

Alastair Robertson阿拉斯泰尔·罗伯逊

Alastair Robertson于2016年12月创建了bpftrace, 当时它还只是一个业余项目。因为它看起来设计良好,并且和业已存在的BCC/LLVM/BPF工具链匹配程度好,笔者加入了该项目,并成为代码、性能工具和文档方面的主要贡献者。现在有不少人加入了我们的开发,第一版主要特性的开发都是在2018年完成的。
本章将介绍bpftrace和它的功能,提供一份工具和文档的概览,然后讲解bpftrace编程语言,最后以bpfrace的调试和内部实现介绍作为结束。
学习目标:
- 了解bpftrace的特性,并和其他工具进行对比。
- 了解在哪里可以找到工具和文档,以及如何使用这些工具。
- 学习如何阅读后续章节涉及的bpftrace工具源代码。
- 使用bpftrace编程语言,编写单行程序和工具。
- (可选)接触一下bpftrace的内部实现。
如果你想立即开始bpftrace编程,可以跳到5.7节,然后再返回这里继续完成bpftrace的学习。
bpftrace比较适合临时创造单行程序和短小脚本进行观测,而BCC则适合编写复杂的工具和守护进程。
5.1 bpftrace的组件
图5-1展示了bpfrace的高层目录结构。
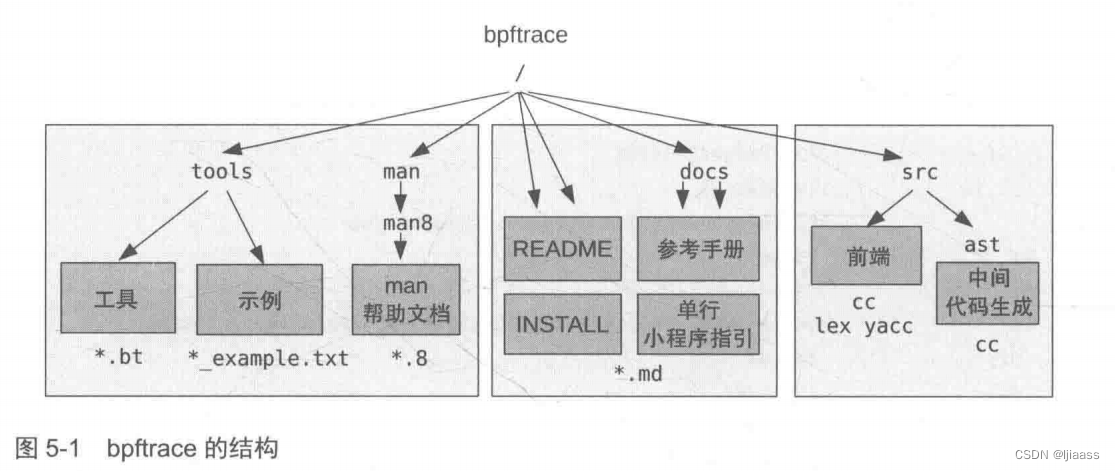
bpftrace中提供了工具的文档、man帮助文档、示例文件、一份bpftrace编程指引(单行程序指引),以及对应编程语言的参考手册。所有的bpftrace工具都以.bt作为文件名后缀。
前端使用lex和yacc来对bpftrace编程语言进行词法和语法分析,使用Clang来解析结构体。后端则将bpftrace程序编译成LLVM中间表示形式( intermidiate representation),然后再通过LLVM库将其编译为BPF代码。5.16 节中有相关细节的介绍。
5.2 bpftrace的特性
特性列表有助于你了解一项新技术所具备的能力。笔者制作了这样一个期望能够得到支持的特性列表,用于指导开发,现在这些特性都已经实现了,并在本节中列出。在第4章中,笔者将BCC的特性按照内核态和用户态特性进行了分类,因为它们属于不同的API。对于bpftrace来说,只存在一种API:bpftrace编程语言。这些bpftrace 特性会按照事件源、动作和一般特性进行分类绍。
5.2.1 bpftrace 的事件源
下面这些事件源使用了第2章介绍过的内核态技术。bpfrace 接口(探针类型)显示在括号中:
- 动态插桩,内核态(kprobe)
- 动态插桩,用户态(uprobe)
- 静态跟踪,内核态(tracepoint、 software)
- 静态跟踪,用户态(usdt, 借助libbcc)
- 定期事件采样(profile)
- 周期事件(interval)
- PMC 事件(hardware)
- 合成事件(BEGIN、END)
5.9节会对这些探针的类型进行详细解释。未来还计划加入更多的事件源,也许当你读到这里时,这些计划都已经实现了;这包括: sockets 和skb事件、裸跟踪点、内存断点和自定义的PMC事件。
5.2.2 bpftrace 的动作
下面列出的是当某个事件触发后可以执行的动作。这里只给出了其中关键的一部分;从用户参考手册(Reference Guide)中可以找到完整列表。
- 过滤(谓词条件)
- 每事件输出(printf())
- 基础变量(g1obal、 $local和per[tid])
- 内置变量(pid、tid、comm、nsecs …)
- 关联数组(key[value])
- 频率计数(count() 或者++)
- 统计值(min()、max()、sum()、avg()、 stats() )
- 直方图(hist()、lhist() )
- 时间戳和时间差(nsecs及哈希存储)
- 调用栈信息,内核态(kstack)
- 调用栈信息,用户态(ustack) .
- 内核态的符号解析(ksym()和kaddr() )
- 用户态的符号解析(usym()和uaddr() )
- 访问C结构体成员(->)
- 数组访问([])
- shell命令(system() )
- 打印文件(cat())
- 基于位置的参数($1、 $2、…)
5.7节会进一步阐述所有的bpfrace动作。如果有特别需求,未来会添加更多的动作。但是希望能够将语言规模保持得越小越好,以使之易于学习。
5.2.3 bpftrace 的一般特性
下面列出的是bpftrace的一般特性,以及源代码仓库中的相应部分:
- 额外开销较低的插桩技术(BPF JIT和映射表)
- 生产环境安全性(BPF验证器)
- 众多工具(在/tools 目录下)
- 新手指引(/docs/tutorial_one_liners.md )
- 参考手册(/docs/reference_guide.md)
5.2.4 bpftrace 与其他观测工具的比较
下面是bpftrace和其他也可以针对各种事件插桩的跟踪工具的对比。
- perf(1): bpfrace提供了简练的高级语言,而perf()脚本语言则相对冗长。perf(1)支持通过perfrecord方式比较高效地转储(dump)事件,也可使用perftop在内存中对事件进行统计。bpfrace 支持在内核中高效地进行统计,包括可以生成自定义直方图,而perf(1)内置的在内核中的统计功能只支持简单计数(perfstat)。虽然不能直接使用bpfrace这样的高级语言,但perf(1)仍然可以通过运行BPF程序进行能力扩展;附录D中有perf(1)运行BPF的示例。
- Ftrace : bpftrace 提供了一种和C以及awk语法十分相似的编程语言,而Ftrace则使用了一种自有语法来实现包括hist-triggers在内的探测功能。由于Ftrace所需的依赖更少,因而更适合嵌入式Linux环境。Ftrace 的某些方面,比如函数统计功能经过了专门的性能优化,比bpfrace使用的事件源更加高效。(笔者编写的Ftrace版本的funccount(8)目前比bpfrace启动停止更加迅速,运行时性能开销也更低。)
- SystemTap : bpfrace和SystemTap都提供了高级语言支持。bpftrace 基于Linux内置的技术,而SystemTap则使用自己开发的内核模块——这在REHL发行版之外的Linux上已经被证明是不太可靠的。目前有工作在推动SystemTap像bpfrace那样来支持BPF后端,这样可使它在其他发行版上也能稳定运行。从功能上来说,SystemTap目前的tapsets库拥有更多的辅助函数,可以用来对不同的目标进行插桩。
- LTTng: LTTng对于事件的导出转储进行了优化,并提供了分析事件转储结果的工具。这采取了和bpfrace完全不同的性能分析方法,bpfrace被设计为偏向临时性的实时分析。
- 应用程序定制工具:针对特定应用程序和语言运行时的工具只能在用户态范围内进行跟踪。bpftrace也可以对内核和硬件事件进行探测,这就使得其能够确认问题的范围比用户态工具要更广。此类工具的优势在于它们通常针对目标应用程序或运行时进行了专门定制。比如MySQL数据库性能剖析器可以理解如何对数据库查询进行跟踪,JVM 剖析器则可以专门对垃圾回收进行跟踪。在bpfrace中,这些工作都需要自行编码实现。
这里的结论是,无须拘泥于bpftrace。我们的目标是解决问题,而不是过分专注于bpfrace工具。有时组合使用这些工具能更快地达到目标。
5.3 bpftrace的安装
bpftrace可以使用Linux发行版提供的安装包进行安装,但是在本书写作之时,这些包才刚刚开始出现:第一个bpfrace包是以Canonical公司提供的snap包形式以及一个Debian包提供的,这些包在Ubuntu19.04中可用。你可以自行通过源代码编译bpfrace。查看最新源代码仓库中的INSTALL.md文件可获得安装指令。
5.3.1内核版本要求
这里推荐你使用Linux 4.9 (2016年12月发布)或更新的内核版本。bpftrace 所使用的主要的BPF组件是在Linux 4.1到4.9之间添加的。后续的版本中有各种改进,所以使用越新的内核越好。在BCC文档中包含了一个不同Linux版本支持的BPF特性列表,其中也解释了为什么越新的内核越好(请参看参考资料[64])。
使用时需要启用内核的一些配置选项。在很多发行版中,这些选项是默认开启的,所以通常不需要再手动开启。包括: CONFIG_ BPF=y、CONFIG_BPF_SYSCALL=y、CONFIG BPF JIT=y、CONFIG_HAVE_EBPF JIT=y 及 CONFIG_BPF_EVENTS=y。
5.3.2Ubuntu
当Ubuntu发行版中的bpftrace安装包可用时,可以执行如下动作安装:

个人尝试用Ubuntu发行版中的bpftrace安装包下载:
将下载源改成中科大,再下载安装:
安装完尝试使用:

bpftrace也可以通过源代码进行安装:

5.3.3Fedora
一旦bpftrace经过打包之后,可以通过如下动作安装:

bpftrace也可以通过源代码进行构建:

5.3.4构建后的安装 步骤
为了确认编译构建过程是成功的,可以运行测试用例以及使用一个单行程序进行测试:

运行sudo make install 可将bpftrace二进制文件安装到/usr/local/bin/bpftrace,将工具安装到/usr/local/share/bpfrac/toolso可以使用cmake(1)选项来变更安装位置,默认值是-DCMAKE INSTALL PREFIX=/usr/local.
5.3.5其他发行版
请先检查一下是否有可用的bpfrace安装包,同时请参看bpfrace的INSTALL.md文件中的安装指引。
5.4 bpftrace工具
图5-2展示了主要的系统组件,以及来自bpftrace源代码仓库的bpftrace和本书中新增的bpftrace,这些工具可以用来对系统组件进行观测。
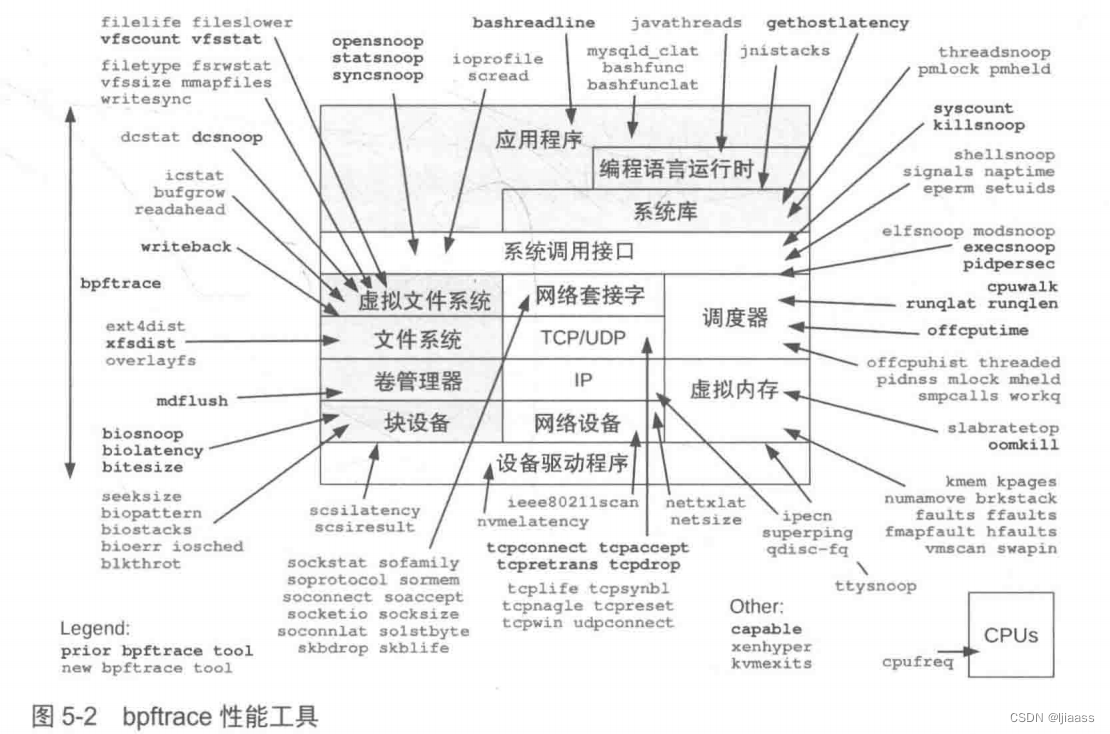
bpftrace源代码仓库中当前的工具使用黑色字体,来自本书的新的工具则使用了灰色。有一些变体工具没有被包含进来(比如第10章介绍的qdisc变体工具)。
5.4.1 重点工具
表5-1根据主题分类列出了一些工具,这些工具会在后续章节加以详细介绍。

注意,本书讲述的BCC工具并未在表5-1中列出。
在阅读完本章之后,你可以根据需要跳转到任意一章继续学习,到时可以将本书当作一本参考手册来使用。
5.4.2工具特征
bpftrace工具有以下共同特征:
■解决真实世界的观测性问题。
■设计为在生产环境中由root 用户来使用。
■每个工具都有一个对应的man帮助文档(在man/man8目录下)。
■每个工具都配备一个示例文件,其中有示例输出以及对输出的解释(在tools/*_example.txt文件中)。
■工具源代码以一段注释作为开始。
■工具尽量简单和短小。(更复杂的工具可借助BCC实现。)
5.4.3工具的运行
如果你是root用户,可以立即运行自带的工具:
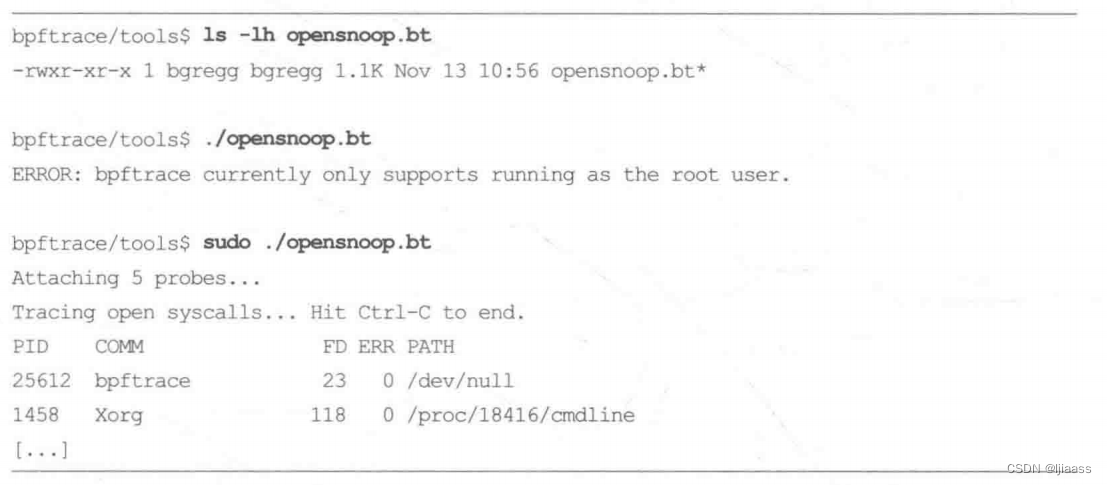
这些工具可以和其他系统工具一起放在某个sbin目录下,比如/usr/local/sbin。
5.5 bpftrace单行程序
本节提供了一些单行程序,一方面它们本身就很有用,另一方面也可用它们来展示bpftrace的各种能力。
下一节会解释bpftrace编程语言,再往后的章节会介绍更多的针对特定目标的单行程序。注意,许多单行程序在内核内存中进行数据统计,直到用户按下Ctrl+C组合键后才会打印出一个摘要消息。
#展示系统中谁在执行什么命令:
bpftrace -e ’ tracepoint:syscalls:sys enter_ execve{ printf(“%s -> s\n”, comm,str (args->filename)); }
#展示新进程的创建,以及参数信息:
bpftrace -e ’ tracepoint:syscalls:sys_enter_execve { join (args->argv); } ’
#通过openat()查看打开文件动作,按进程统计:
bpftrace -e ‘tracepoint:syscalls:sys enter_ openat { printf(“is 8s\n”,comm,str (args->filename)); }’
#按照不同程序统计系统调用:
bpftrace -e 'tracepoint:raw syscalls:sys_enter { @[comm] = count(); }
#按系统调用探针的名字对系统调用进行计数:
bpftrace -e 'tracepoint:syscalls:sys_enter_* { e[probe] = count(); } ’
#按进程统计系统调用数量:
bpftrace -e ‘tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }’
#按进程展示总的读取字节数:
bpftrace -e ‘tracepoint:syscalls:sys_exit_ read /args->ret/ ( @[comm] sum (args->ret); }’
#按进程展示read返回结果大小的分布:
bpftrace -e ‘tracepoint:syscalls:sys_exit_ read { @[comm] = hist(args->ret); }’
#展示进程的磁盘1/0尺寸:
bpftrace -e 'tracepoint:block:block_ rq_issue { printf(“gd 8s %d\n”, pid, comm,args->bytes);} ’
#按进程展示页换入的数量:
bpftrace -e ’ software:major-faults:1 { @[comm] = count(); } ’
#按进程展示缺页中断的数量:
bpftrace -e ‘software:faults:1{ @[comm] = count(); }’
#对PID为189的进程,以49Hz的频率抓取其用户态的调用栈信息:
bpftrace -e ‘profile:hz:49 /pid = 189/ ( @[ustack] = count(); }’
5.6 bpftrace的文档
和BCC项目下的工具一样,每个bpftrace工具都有一个相应的man帮助文档和示例文件。
第4章对这些文件的格式和用途进行了讨论。
为了帮助人们学习开发新的单行程序或者工具,笔者编写了“bpfrace One-Liner Tutorial(教程)” 和“bpfrace Reference Guide(手册)" 。这些文档可以在源代码仓库的/docs 目录下找到。
5.7 bpftrace编程
本节提供了一个如何使用bpfrace以及如何进行bpfrace编程的短小指南。本节的格式受到了最初awk文章[Ab078的启发,那篇文章使用了6页的篇幅描述了awk语言。bpfrace语言本身的设计灵感来自awk和C,还包括其他跟踪器的特色,如DTrace和SystemTap.
下面是一个bpfrace编程的例子:它对内核函数vfs__read(的执行时间进行测量,并以微秒为单位将结果以直方图形式进行打印。这里摘要解释了此工具包含的组件:

接下来的5节会深入bpftrace编程的细节,内容包括:探针、测试、运算符、变量、
函数和映射表类型。
5.7.1用法
命令:
bpftrace -e program
会执行program(n.程序),并开始跟踪其中定义的所有事件。程序会持续运行,直到Ctrl+C组合键被按下,或者程序显式地调用exit()为止。带-e参数运行的bpftrace程序被称作单行程序。
除此以外,程序可以被保存到一个文件中,然后通过下面的方式来执行:
bpftrace file.bt
这里.bt扩展名并不是必需的,不过有助于后续确认文件类型。
在文件开始的位置放置一行代码可指定解释器:
#!/usr/local/bin/bpftrace
apt-get安装的文件,安装后软件默认位置:/usr/share;可执行文件位置:/usr/bin
如果将文件属性设定为可执行(chmod a+x file.bt),就可以像其他任何程序一样运行:
./file.bt
bpftrace必须由root用户(超级用户)运行。在某些环境下,root shell可以用来直接运行程序,而在另外- - 些环境下则更倾向使用sudo(1)来执行特权程序:
sudo ./file.bt
5.7.2程序结构
bpftrace程序的结构是一系列探针加对应的动作:
probes { actions }
probes { actions }
...
当探针被激活后,相应的动作就会被执行。可以在动作前面放置一个可选的过滤表达式:
probes /filter/ { actions }
只有当过滤表达式为真时,相应的动作才会执行。这和awk(1)程序结构相似:
/pattern/ { actions }
awk(1)编程和bpftrace编程也有几分相似。在程序中可以定义多个动作块,这些块可以按照任意顺序执行:只有在它们匹配模式,或者说探针+过滤条件得到匹配时才会被触发。
5.7.3注释
对于bpfrace程序文件,单行的注释可以通过“//"添加:
// this is a corment
注释行是不会被执行的。多行注释使用和C语言一样的语法:
/*
*Thisisa
*multi-line comment。
*/
该语法也可以对一行之内的内容进行注释(例如,/* comments */)。
5.7.4探针格式
探针(probe) 以类型名字开始,然后是一系列以冒号分隔的标识符:
type:identifier1[:identifier2[...]]
标识符的组织形式由探针类型决定。看下面这两个例子:
kprobe:vfs_read
uprobe:/bin/bash:readline
kprobe探针类型对内核态函数进行插桩,只需要一个标识符 :内核函数名。uprobe探针类型对用户态函数进行插桩,需要两个标识符:二进制文件的路径和函数名。可以使用逗号将多个探针并列,指向同一个执行动作。比如:
probe1,probe2,... { actions }
有两个特殊的探针类型不需要额外的标识符:BEGIN和END,它们会在bpfrace程序启动和结束时触发(和awk(1)一样)。欲了解更多关于探针类型和它们的使用方法的信息,可参看5.9 节。
5.7.5探针通配符
有些探针类型接受通配符。下面这个探针
kprobe:vfs_ *
会对所有的以“vfs_ ”开头的kprobe (内核函数)进行插桩。对过多的探针同时进行插桩会造成不必要的性能开销。为了避免不小心引发上述问题,bpftrace可以设定允许同时开启探针数量的上限,具体方法是设定BPFTRACE_MAX_ PROBES 环境变量(目前它的默认值是512)。
在使用通配符之前,可以先通过运行bpftrace -l进行测试:

这会匹配56个探针。探针的名字放在单引号中,以防止shell对其进行解释和展开。
5.7.6过滤器
过滤器是一个布尔表达式,它决定一个动作是否被执行。下面这个过滤条件
/pid = 123/
只在内置变量PID (进程ID)等于123时才会触发执行后续动作。如果没有指定具体的测试条件:
/pid/
过滤器会检查内容是否为非零值(/pid/ 等价于/pid !=0/)。过滤器还可以使用布尔运算符进行组合,比如使用逻辑与(&&)。例如:
/pid > 100 && pid < 1000/
此过滤器要求两个子表达式的值都为真。
5.7.7动作
一个动作既可以是单条语句,也可以是使用分号分隔的多条语句:
目前如果同时开启512个探针进行插桩的话,会让bpftrace启动和结束变慢,因为它的插桩动作是一个接一个进行的。在后续的内核版本中已经计划添加批处理插桩支持。这个功能实现后,这个数量限制可以上调,甚至可以完全移除。
{ action one; action two; action three}
全部语句最后也可以加分号。语句使用bpfrace语言写成,和C语言类似,可以操作变量和执行bpfrace函数调用。例如,动作
{ $x = 42; printf("$x is %d", $x); }
为变量$x赋值为42,然后使用printf()打印。5.7.9 节和5.7.11节会介绍其他可用的函数调用。
5.7.8 Hello, World!
你现在应该可以理解下面这个基本程序了,它在bpftrace程序启动时打印“Hello,World!" :
# bpftrace -e 'BEGIN { printf ("Hello, World!\n"); }'
Attaching 1 probe...
Hello, World!
^C
如果以文件形式书写,可以格式化如下:
#!/usr/1oca1/bin/bpftrace
BEGIN
printf ("He11o, World!\n");
}
程序中的换行和缩进不是必需的,但是可以增强代码的可读性。
5.7.9函数
除了使用printf()进行格式化输出外,其他内置函数还包括如下几个。
■exit() :退出bpfrace.
■str(char *) :输入一个指针,返回字符串。
■system(format[, arguments …1) :在shell中运行命令。
下面这个动作:
printf ("got: %11x %s\n",$x,str($x)); exit();
会以十六进制形式打印变量$x,然后将它视作一个以NULL结尾的字符串数组的指针(char*),然后再以字符串形式打印,最后退出。
5.7.10变量
有3种类型的变量:内置变量、临时变量和映射表变量。
内置变量:由bpftrace预先定义好并提供,通常是一个只读的信息源。内置变量包括表示进程id的pid,表示进程名字的comm,表示以纳秒为时间戳单位的nsecs,表示当前线程的task_ struct 结构体的地址的curtask。
临时变量:可以被用于临时的计算,字首加“$”作为前缀。它们的名字和类型在首次赋值时被确定。以下语句:
$x=1;
$y = "hello";
$z = (struct task struct *)curtask;
声明 x 为整数, x为整数, x为整数,y 为字符串,$z为一个指向task_ struct 结构体的指针。这些变量只能在它们赋值的动作块中使用。如果引用一个未声明的变量,bpfrace 会出错(这有助于定位代码拼写错误)。
映射表变量:使用BPF映射表来存储对象,名字带有“@”前缀。它们可以用作全局存储,在不同动作之间传递数据。程序
probel{@a=1;}
probe2{$x=@a;}
在probel触发时将1赋值给@a,然后在probe2触发时将@a赋值给 x 。如果 p r o b e l 先于 p r o b e 2 被触发, x。如果probel先于probe2被触发, x。如果probel先于probe2被触发,x 会被设置为1,否则为0 (未初始化)。此处可以提供由单个或多个元素组成的key,将映射表作为哈希表来使用(关联数组)。以下语句:
@start[tid] = nsecs;
会经常被用到:内置变量nsecs会赋值给一个名为start、以tid ( 当前线程ID)为key的映射表。这允许每个线程存储自己的时间戳,不用担心被其他线程所覆盖。
@path[pid, $fd] = str (arg0);
这是一个使用复合键的映射表,同时使用了内置变量pid和$fd的组合作为key。
5.7.11映射表函数
映射表可以通过特定的统计函数赋值。这些函数以特殊方式来存储和打印数据。以下赋值:
@x = count();
对事件进行累计统计,打印时会打印出累计结果。这里使用了每CPU独立的映射表,@x成为一个特殊的count类型的对象。下面这个语句也会对事件进行计数:
@x++;
不过,这里使用的是–个全局映射表,而非每CPU独立的映射表,这里@x的类型是整数。
有的时候,由于程序需要整数而非count类型,所以这里提供了两种支持,但是要记住,这里可能因为并发更新(参看2.3.7 节)而产生小误差。下面的赋值:
@y = sum($x);
(sum n.总和)会对变量$x求和,打印时打印出总数。赋值:
@z = hist ($x);
将$x保存在一个以2的幂为区间的直方图中,当输出时,会打印桶的数值和ASCII字符形式的直方图。
有些函数直接操作映射表。比如:
print (@x);
会从@start中删除键为tid的键值对。
5.7.12对 vfs_read() 计时
现在你已经掌握了相关语法,我们来看一个更复杂和更实际的例子。
程序vfsread.bt对内核函数vfs_read() 进行计时,并将时长以直方图形式打印(单位为微秒):

hist($duration_us)将$duration_us保存在一个以2的幂为区间的直方图中,当输出时(即按下ctrl+C时),会打印桶的数值和ASCII字符形式的直方图。
这段程序通过kprobe对函数的开始位置进行插桩,将时间戳以线程id作为键存放到@start哈希表中,然后以kretprobe对函数的结束位置进行插桩,计算时间差: now - start,最终实现对内核函数vfs_read() 运行时长的记录。
这里使用了过滤条件,是为了确保只关注那些已经记录了开始时间的调用;否则会出现无效值:now-0。下面是输出的例子:


程序会持续运行,直到Ctrl+ C组合键被按下,才会打印结果并退出。这个直方图的名字“us”代表了输出的单位。以这种有含义的方式命名,比如“bytes”或者“latency_ns”会使得直方图便于理解。
这个脚本也可以根据需要进行定制。可以考虑改变hist()赋值这行代码:
@us [pid, comm] = hist ($duration _us) ;
这会把每个进程ID和进程名组成的对都保存为一个直方图。此时输出变成:

上面展示了bpfrace最有用的功能之一。如果使用传统的系统工具,如iostat(1)和.vmstat(1),输出格式是固定的,很难定制。但是使用bpftrace时,可以将指标进一步打散,并与其他探测的指标进行组合关联,直到能够解决问题为止。
5.8 bpftrace的帮助信息
如果不带参数(或者通过-h)会打印bpftrace的帮助信息,提供对重要的选项和环境变量的介绍,并且列出一些单行程序的示例:

上述输出来自bpftrace 版本v0.9-232-g60e6,日期为2019年6月15日。随着支持的特性越来越多,帮助信息可能会变得过于冗长,因此可能会改为长短两个版本。你可以查看一下当前版本的输出,看看是否已经进行了更改。
查看我的bpftrace版本:
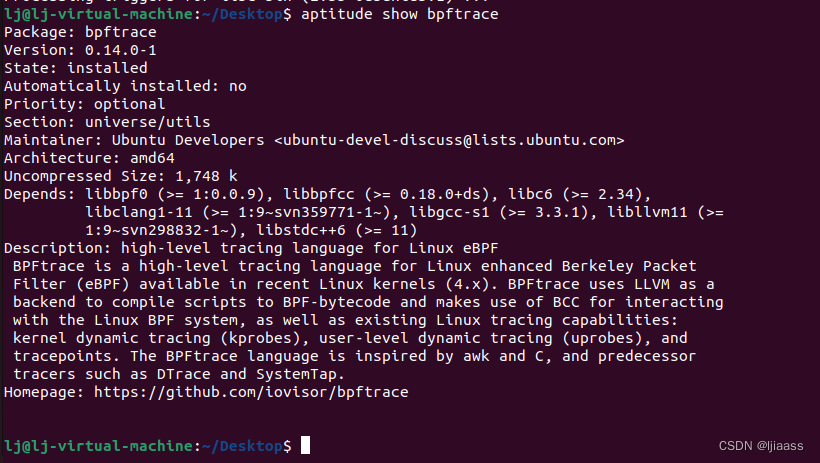
lj@lj-virtual-machine:~/Desktop$ sudo aptitude show bpftrace
程序包:bpftrace
版本:0.14.0-1
状态:已安装
自动安装:否
优先级:可选
部分:universe/utils
维护者:Ubuntu开发者<ubuntu-devel-discuss@lists.ubuntu.com>
架构:amd64
未压缩尺寸:1748 k
取决于:libbpf0(>=1:0.0.9)、libbpfcc(>=0.18.0+ds)、libc6(>=2.34)、,
libclang1-11(>=1:9~svn359771-1~)、libgcc-s1(>=3.3.1)、
libllvm11(>=1: 9~svn298832-1~),libstdc++6(>=11)
描述:Linux eBPF的高级跟踪语言
BPFtrace是针对Linux增强的Berkeley Packet的高级跟踪语言
最新Linux内核(4.x)中提供的过滤器(eBPF)。BPFtrace使用LLVM作为后端将脚本编译为BPF字节码,并利用BCC进行交互
使用Linux BPF系统,以及现有的Linux跟踪功能:内核动态跟踪(kprobes)、用户级动态跟踪(rootes)和跟踪点。BPFtrace语言的灵感来自awk和C以及前身跟踪程序,如DTrace和SystemTap。
主页:https://github.com/iovisor/bpftrace
5.9 bpftrace的探针类型
表5-2列出了可用的探针类型。其中许多也支持缩写,方便写出更短的单行程序。

这些探针类型是对现有内核技术的接口。第2章解释了这些内核技术是如何工作的:kprobes、uprobes、 tracepoints、 USDT和PMC ( 硬件探针类型)。
有些探针触发的频率较高,比如调度器事件、内存分配事件,以及网络收发包事件等。为了减少额外开销,请尽量尝试使用低频事件。第18章会讨论如何让BCC和bpftrace减少额外开销。
下面的部分会介绍bpftrace探针的使用。
5.9.1 tracepoint
racepoint探针类型会对内核跟踪点进行插桩。t格式是:
tracepoint: tracepoint_name
tracepoint_ name是跟踪点的全名,包括用来将跟踪点所在的类别和事件名字分隔开的冒号。比如,bpftrace 可以通过tracepoint:net:netif_ rx方式对net:netif_ rx这个跟踪点进行插桩。
跟踪点通常带有参数:bpftrace可以通过内置变量args来访问这些参数的信息。比如,net:netif_rx有一个代表数据包长度的参数,名字为len,可以通过args->len进行访问。如果你刚开始接触bpfrace与跟踪技术,与系统调用相关的跟踪点是很好的练习对象。这些跟踪点基本覆盖了内核资源的使用情况,并且API文档全面——都在系统调用man帮助文档之中。比如:
linux的man指令是系统参考手册的接口。
语法格式:man [参数] 对象
手册的分类和格式
Linux 帮助手册是一个庞大的参考书,为了更好的组织信息,Linux 将整个手册页分成了8章(编号1~8)。各个发行版之间实际名称可能会有所不同,但是,所有的 Linux 手册都倾向于遵循相同的组织原则。
章节 说明
1 标准用户命令(包含大量的命令手册)
2 系统调用(在程序中使用,用来请求内核执行指令)
3 库调用
4 特殊文件(包含物理设备和设备的驱动信息)
5 文件格式(包含配置文件)
6 游戏
7 杂项(各种混杂信息)
8 管理命令(系统管理员使用的特殊命令)
一般系统没有man命令,如果只安装man,就只能查看第一部分(命令)
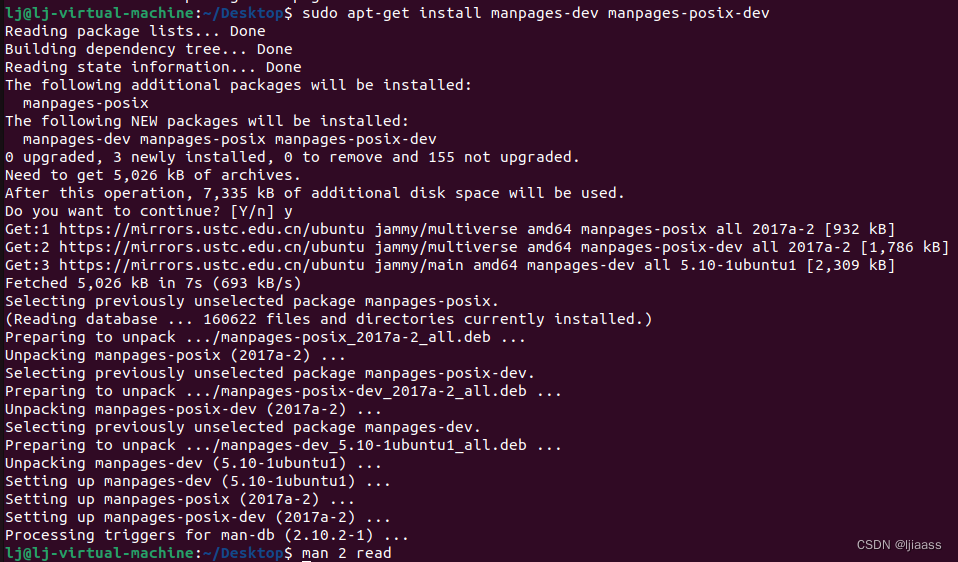
如果要查看函数,也就是后面的部分,还需要安装man-pages。在Ubuntu系统下可以使用以下的命令安装开发使用的man pages:
sudo apt-get install manpages-dev manpages-posix-dev
syscalls:sys_enter_read
syscalls:sys_exit_read
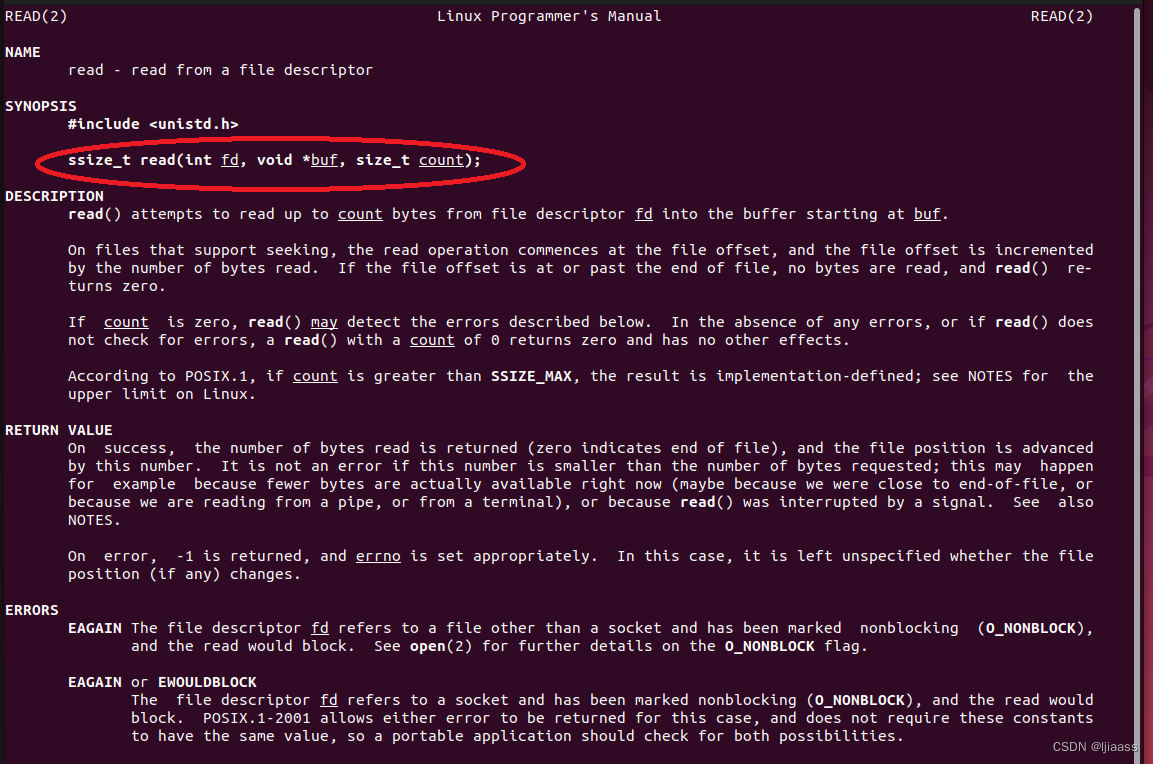
会对系统调用read(2) 的开始和结束进行插桩。man帮助文档中有它的调用规范:
ssize_ t read(int fd, void *buf, size_ t count) ;
对于sys_enter_read 跟踪点来说,它的参数可以通过args->fd、 args->buf 和args->count进行调用。这可以通过bpfrace的-l (列表)和-v (详细)模式选项进行查看:

man帮助文档中还描述了这些参数的意义,以及read(2)系统调用的返回值,后者可以使用sys_ exit_ read 这个跟踪点进行插桩。这个跟踪点中还有man帮助文档中没有列出的参数,_ syscall_nr, 即系统调用号。
再举一个有趣的跟踪点的例子,我们来对clone(2)系统调用的开始和结束进行插桩。该系统调用创建了新的进程( 与fork(2)类似)。对于这些事件,我们会使用bpftrace的内置变量打印出当前进程的名字和PID。对于系统调用的退出,我们也会使用tracepoint的参数打印出其返回值:

上面这个系统调用的特殊之处在于,它进入1次,但是返回2次。在跟踪时,笔者在bash(1)终端运行了ls(1)。能够看到父进程(PID 2582)进入了clone(2), 然后产生了2次返回: 一次在父进程中,返回了子进程的PID (27804), 另一次是子进程返回0 (代表成功)。当子进程开始后,它仍然是“(进程)bash",因为此时还没有执行exec(2)系统调用来让它成为“(进程)ls”。这个过程也可以被跟踪:

输出显示PID (28181)进入系统调用execve(2)时还是“bash",在退出时已经是“Is”了。execve()执行指定的程序
5.9.2usdt
usdt探针类型对用户态静态探针点进行插桩。格式如下:

usdt可以对提供了完整路径的可执行二进制文件或者共享库进行插桩。probe_name是二进制文件中USDT的探针名字。
例如,MySQL中一个名为query_start 的探针可以通过usdt:/usr/local/sbin/mysqld:query__start 进行访问。
当没有指定探针的命名空间时,它默认与二进制文件名或者库文件名相同。当有许多不同的探针时,需要指定命名空间。一个例子是: libjvm (JVM库)的“hotspot”命名空间的探针。例如(没有包含完整路径):
usdt:/.../libjvm. so:hotspot:method__entry
USDT探针的任意参数,都可以使用内置变量args的成员进行访问。二进制文件中所有可用的探针都可以使用-l列出来,例如:


可以使用-p PID列出一个正在运行进程的USDT探针,而不用手动列出探针的描述。
5.9.3 kprobe 和kretprobe
这些探针类型用于内核的动态插桩。格式如下:
kprobe : function_ name
kretprobe : function name
kprobe对函数的开始(入口)进行插桩, kretprobe对函数的结束(返回)进行插桩。function_ name是内核函数的名字。举例来说,vfs_ read()内核函数可以使用kprobe:vfs_read和kretprobe:vfs_ _read 进行插桩。
kprobe的参数“arg0,argl…arg/V"是进入函数时的参数,类型均为64位无符号整型。如果它们是指向C结构体的指针,可以强制类型转化为对应的结构体。未来的BPF类型格式(BTF)技术会让这个过程自动化(参见第2章)。
kretprobe的参数:内置的retval是函数的返回值。retval 的类型也永远是64位无符号整型;如果这和函数的返回值不一-致,那么需要通过类型强制转换回相应的类型。
5.9.4 uprobe 和uretprobe
这些探针类型用于用户态的动态插桩。格式如下:

>uprobe对函数的开始(入口)进行插桩,uretprobe 对函数的结束(返回)进行插桩。function_name是函数的名字</font。举例说,/bin/bash中的readline(函数可以使用uprobe:readline和uretprobe:readline进行插桩。
uprobe的参数: arg0, argl, … argN是进入函数时的参数,类型均为64位无符号整型。如果它们是指向C结构体的指针,可以强制类型转换为对应的结构体。
uretprobe的参数:内置的retval是函数的返回值。retval的类型恒为64位无符号整型;如果这和函数的返回值不一致,那么需要通过类型强制转换回相应的类型。
5.9.5 software 和hardware
这些探针的类型是预先定义好的软件事件和硬件事件。类型如下:

软件事件和跟踪点类似,不过更适合于基于计数器的指标和基于采样的探测。硬件事件是用于处理器级分析的PMC中的一个子集。
这两类事件的发生频次可能很高,如果对每个事件进行插桩可能带来显著的额外开销,影响系统性能。这可以使用采样和count字段来避免这种情况,具体来说这样会在每发生[count]次事件时才会触发一次探针。 如果没有指定这个count值,那么会使用默认值。举个例子,探针software:page-faults:100会在发生100次缺页中断时才被激活一次。 表5-3列出了可用的软件事件,不同版本的内核支持会有差异。
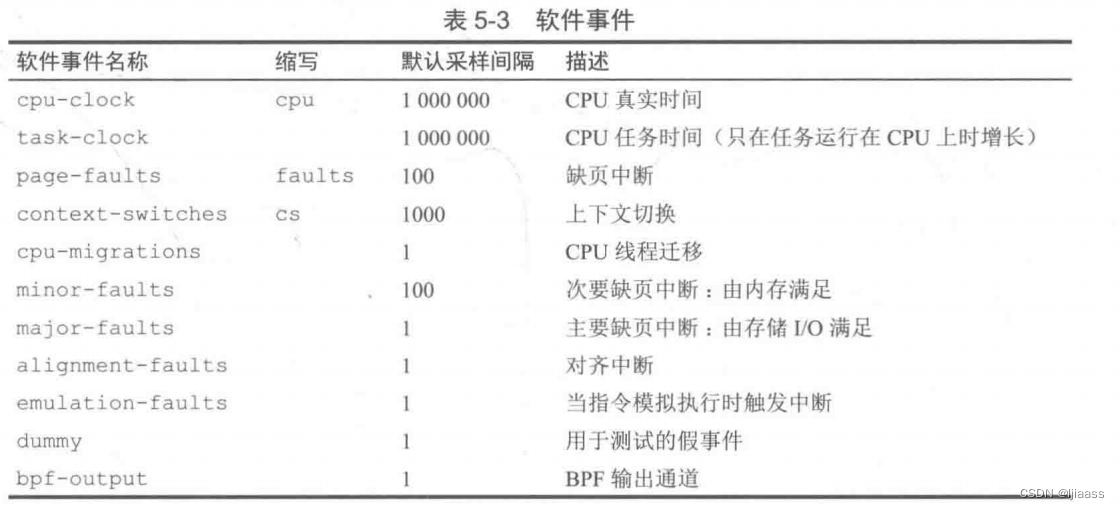
表5-4列出了可用的硬件事件,不同版本的内核支持会有差异。
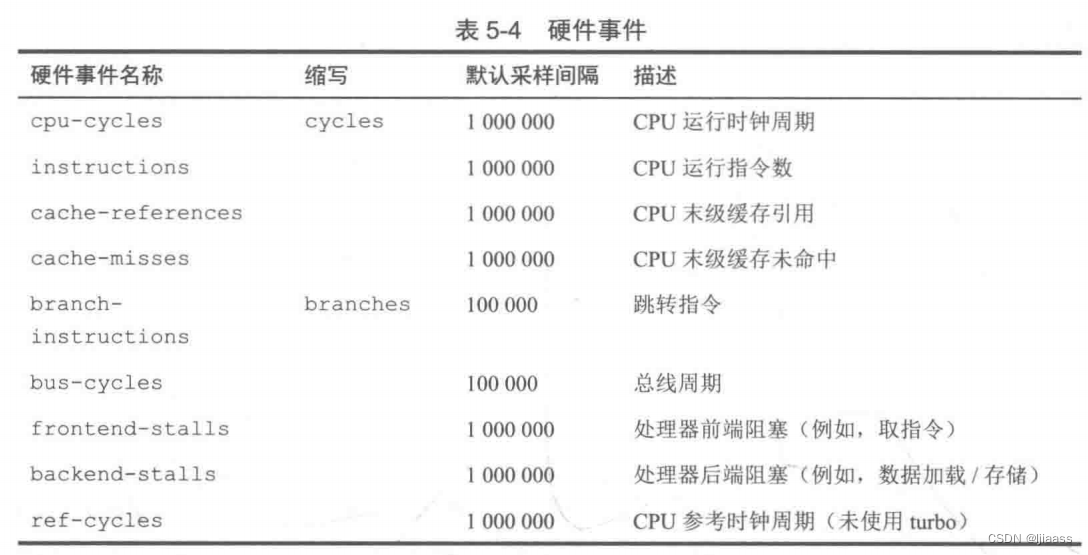
硬件事件出现的频次很高,所以默认的采样间隔也设定得更大。
5.9.6 profile 和interval
这些探针类型是基于定时器的事件。格式如下:

profile类型会在全部CPU上激活,可以用作对CPU的使用进行采样。interval 类型只在单个CPU上激活,可以用于周期性地打印输出。
第2个字段是最后一个字段rate的单位。这个字段的值可以是如下几种。
■hz:赫兹(事件每秒发生的次数)
■s:秒
■ms :毫秒
■us:微秒
举例来说,探针profile:hz:99 每秒在全部CPU上激活99次。通常频率采用99Hz而不是100Hz是为了避免出现锁定步进(lockstep) 采样的问题。探针interval:s:1 每秒激活1次,可以用于每秒打印事件。
5.10 bpftrace的控制流
bpftrace中支持3种类型的测试:过滤器filter、ternary 运算符和if语句。这些测试会基于布尔表达式有条件地改变程序执行的流向。
■=:等于
■!=:不等于
■>:大于
■<:小于
■>=:大于或等于
■<=:小于或等于
■&&:与
■||:或
表达式可以使用括号进行分组。
这里对循环的支持有限制,这是因为BPF验证器出于安全性考虑会拒绝加载可能导致无限循环的代码。bpftrace 支持将循环展开,今后应该会支持有界的循环。
5.10.1过滤器
先前介绍过,过滤器用于判断是否让一个事件执行。格式如下:
probe /filter/ { action }
可以使用布尔表达式。过滤器/pid==123/只会在pid等于123 时让下面的动作实际执行。
5.10.2三元操作符
一个三元运算符是-一个有3个元素的运算符,包含1个测试和2个输出。格式如下:
test ? true_ statement : false_ statement
举一个例子,你可以使用一个三元运算符来得到$x的绝对值:
$abs=$x>=0?$x:-$x;
5.10.3 if 语句
if语句的语法如下:
if (test) { true_ statements }
if (test) { true_ statements } else { false_ statements }
有一个用例是在程序运行时对IPv4和IPv6分别执行不同的动作。举例来说:
if ($inet_ family = $AF_ INET) {
// IPv4
} else {
// IPv6
目前还不支持“elseif" 语句。
5.10.4循环展开
BPF运行在受限环境中,其必须能够验证一个程序可以结束而不会陷入无限循环。对于需要循环功能的程序来说,bpftrace 支持使用unroll)进行循环的展开。
语法如下:
unroll (count) { statements}
count是一个整数数字(常量),最大值为20。目前还不支持把count作为一个变量来提供,因为循环的次数必须在BPF编译阶段晓。
Linux 5.3版本包含了对BPF有界循环的支持。bpftrace 今后的版本应该会支持这个能力,这样就会在unroll()之外再提供for和while循环的支持。
5.11 bpftrace的运算符
前面的小节中介绍了用于测试条件的布尔运算符。bpfrace 还支持以下运算符。
- =:赋值
= +、-、*、/:加减乘除 - ++.–:自动加1、自动减1
= &、|、^:按位与、按位或和按位与或 - !:逻辑非
- <<、>>:向左位移,向右位移
- +=、-=、*=、/=、%=、&=、^=、<<=、>>=:复合运算符
这些运算符的定义与C语言中的类似。
5.12 bpftrace的变量
如5.7.10节中指出的,有3类变量:内置变量、临时变量和映射表变量。
5.12.1内置变量
bpftrace提供的内置变量一般用作对信息的只读访问。表5-5列出了重要的内置变量。
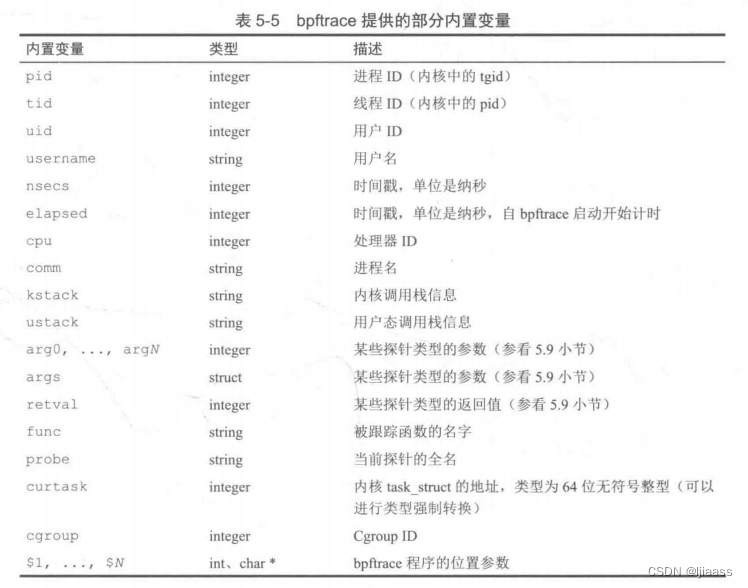
所有的整数类型目前都是64位无符号整型。这些值指向当探针激活时当前运行的线程、探针、函数和CPU。
在线文档“bpftrace Reference Guide" 中有完整的、持续更新的内置变量说明。
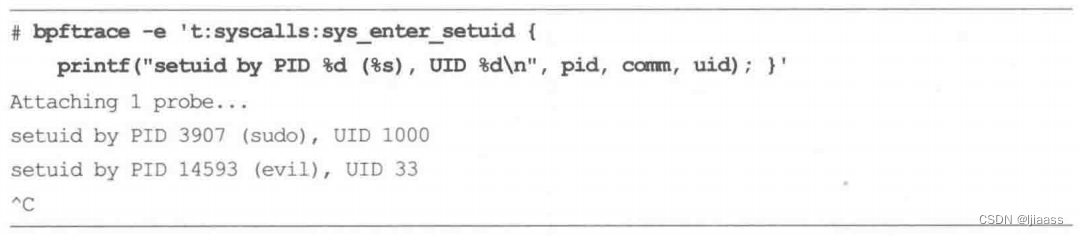
5.12.2内置变量: pid进程ID、comm进程名 和 uid用户ID
有许多内置变量可以很直观地使用。下面这个例子用到了pid、 comm 和uid来显示谁在调用setuid()这个系统调用:
仅仅看到系统调用发生不能代表它一定调用成功了。你可以使用另外一个跟踪点来跟踪它的返回值:

上面使用了另外一个内置变量args。对于跟踪点来说,args 是一个结构体类型,它提供了自定义的字段。
int setuid(uid_t uid);//设置调用进程的有效用户ID。
5.12.3内置变量 : kstack和ustack
kstack和ustack以多行字符串文本形式返回内核态和用户态的调用栈信息。返回的栈深度最大为127。后面会讲到的kstack()和ustack()函数允许选择调用栈的深度。
举个例子说明使用kstack打印块I/O插入的内核调用栈信息:
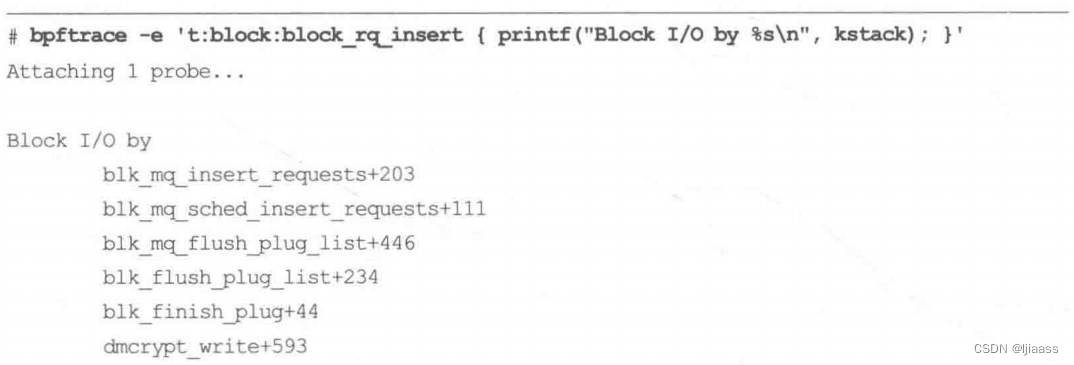
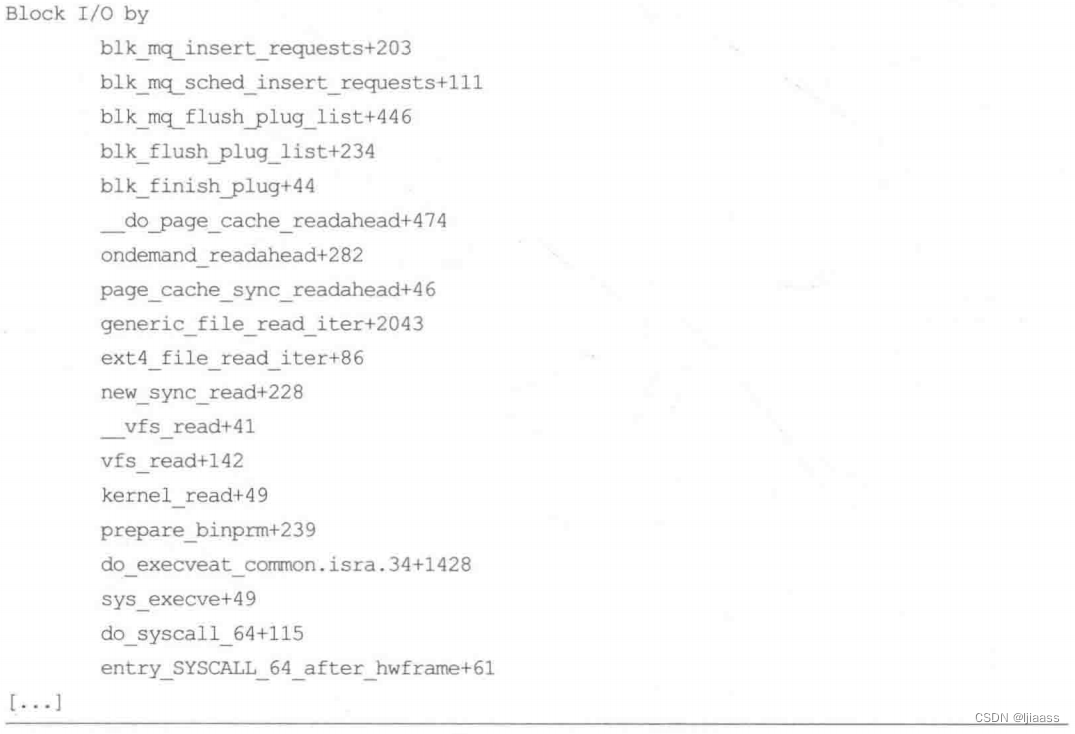
每个调用栈都以先子函数、后父函数的顺序打印帧,每个帧包含函数名字和函数偏移地址。
stack内置变量也可以用作映射表的键,这样就可以对它们的出现次数进行统计。
@x = count();对事件进行累计统计,打印时会打印出累计结果。
比如,下面对内核中引发块I/O的栈进行计数:
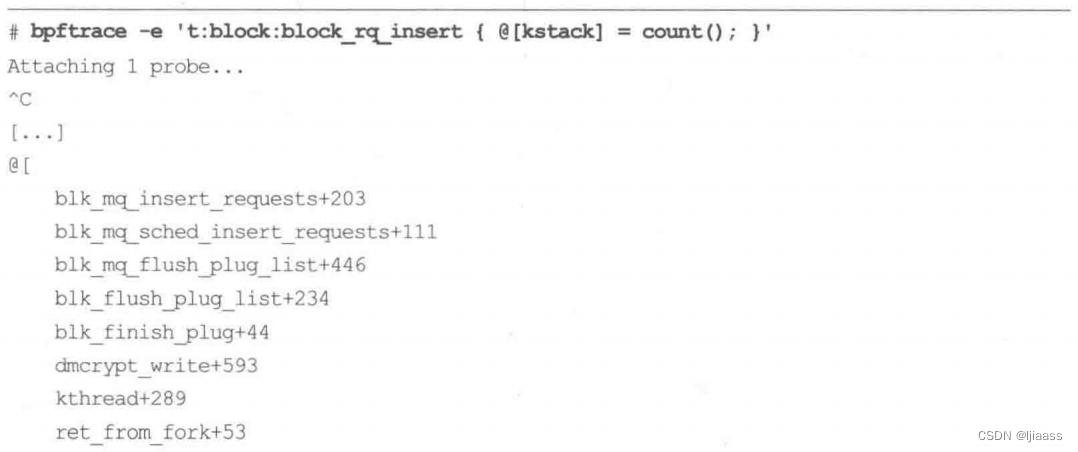
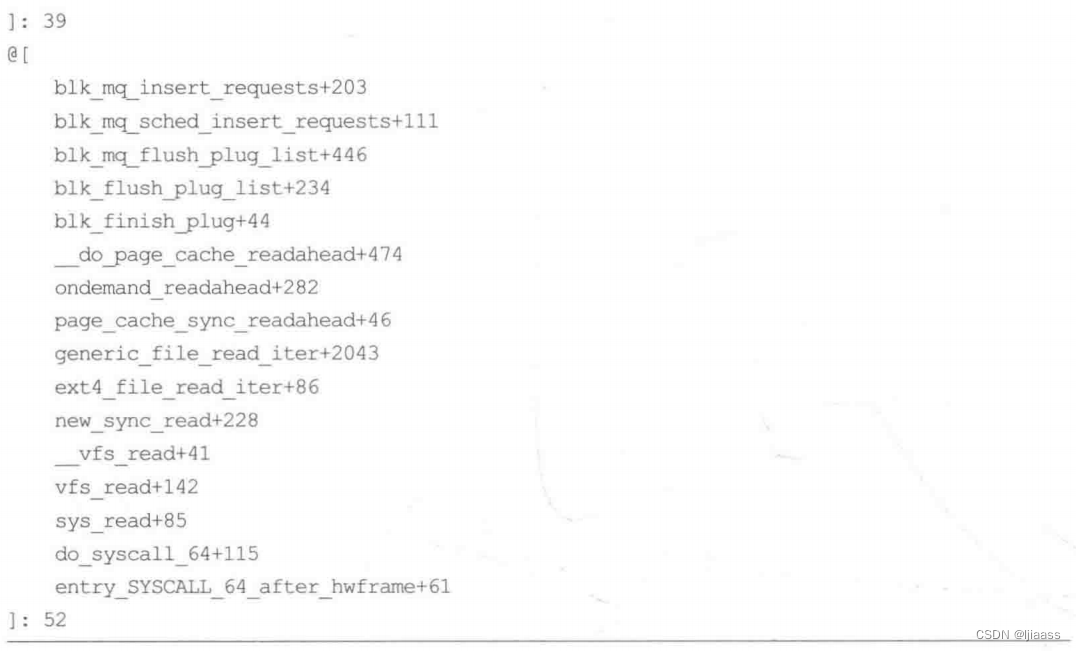
这里只显示了最后两个调用栈,它们的累计数量分别是39和52。按栈计数比把每个栈都打印出来要高效,因为调用栈会在内核上下文中进行计数,这种方式的效率较高。
5.12.4内置变量:位置参数
位置参数是通过命令行传递给程序的参数,且基于shell编程中使用的位置参数。$1代表第1个参数,$2代表第2个,以此类推。
以watchconn.bt举例:

注意下面通过命令行参数传递的PID :

也可以通过如下形式使用位置参数: .

这些参数默认是整数类型。如果将一个字符串用作参数,它必须使用str()来进行访问。例如:

如果访问到了一个没用通过命令行传递的参数,那么它有一个默认值,如果它是整数类型则为0,如果它是字符串类型则为""。
5.12.5临时变量
格式如下:
$Sname .
这些变量可以在一个动作语句中进行临时计算。它们的类型取决于第1次赋值,其类型可以是整数、字符串、结构体的指针,或者结构体。
5.12.6映射表变量
格式如下:
@name
@name[key]
@name[key1, key2[, ..]]
这些变量使用BPF映射表对象作为存储,BPF 映射表是一种哈希表(关联数组),可用于不同的存储类型。值可以使用一个或多个键来存储。映射表使用的键值类型必须保持前后一致。
和临时变量一样,映射表的类型取决于第一次赋值,包括赋值为特殊类型的函数。对于映射表来说,类型中同时包含了键和值的类型。比如,下面的首次赋值:
@start = nsecs;
@last[tid] = nsecs;
@bytes = hist (retval);
@who[pid, comm] = count();
@start和@last这两个映射表的类型是整数类型,因为向它们赋值了一个整数:内置的纳秒级时间戳变量(nsecs)。 @last 也要求其键的类型为整数类型,因为这里用到了一个整数键:线程ID (tid)。@bytes 则成为一个特殊类型:以2的幂为区间的直方图.会管理存储并打印直方图。最后, @who映射表中有两个键,整数( pid)和字符串( comm),它的值是一个统计函数count()。
5.14节会介绍这些函数。
5.13 bpftrace的函数
bpftrace提供了针对各种任务的内置函数。其中最重要的一些列在 了表5-6中。


这里的一些函数是异步处理的:内核将事件加入队列,一小段时间后由用户态程序进行处理。异步处理的函数有printf()、time()、cat()、 join() 和system()。kstack()、ustack()、ksym() 和usym()会同步记录地址,但是符号转义是异步进行的。
详细的函数列表可以参看线上的“bpftrace Reference Guide" 。下 面的章节会详细介绍其中的一部分函数。
5.13.1 print()
调用printf()函数可以进行格式化打印,其行为和C语言以及其他语言类似。语法如下:
printf(format [, arguments ...])
格式化字符串可以包含任意文本消息,并且可以包含以“\”开头的特殊转义字符和
以“%”开头的占位符。如果没有给定参数,那么占位符也是不需要的。
常用的转义字符包括如下三个。
- \n:换行
- ":双引号
- \:反斜杠
可以看一下printf(I)的man帮助文档来了解其他转义字符。
占位符以“%”开头,格式如下:
%[-] width type
“-”设定输出是左对齐、默认还是右对齐。
width是该占位符占据的字符数。
type是以下类型之一。
- %u、 %d:无符号整型、整型
- %lu、 %ld:无符号长整型(long unsigned)、长整型( long)
- %llu、 %lld: 无符号超长整型(unsigned long long)、超长整型(long long)
- %hu、 %hd :无符号短整型(unsigned short)、短整型( short)
- %x、%lx、%llx:以十六进制数输出的无符号整型、无符号长整型和无符号超长整型
- %c:字符
- %s:字符串
下面这个printf()调用:
printf("%16s %-6d\n", corm, pid)
会使用16个字符长度的字符串打印内置变量comm,将pid作为一个6个字符长度的整
数类型右对齐。打印输出,后面还会跟-一个换行符。
5.13.2 join()
join()是一个特殊的函数,用于将多个字符串使用空格进行连接并打印出来。语法如下:
join(char *arr[])
比如,下面这个单行程序显示了尝试执行的命令,以及命令行参数:

它会打印execve()系统调用的argv数组参数。
注意,这里展示的是所有的执行尝试:syscalls:sys_exit_execve这个跟踪点和它的args->ret值会指明该系统调用是否执行成功。
join()在某些场合中可能是一个方便使用的函数,但是它对能够连接的参数数量和大小都有限制。如果输出看起来被截断了,那么有可能碰到了这个上限,这时就需要换一种方式进行输出。
目前已经有一些计划改进join()的行为,让它返回一个字符串而非直接打印结果。此时前面的bpftrace单行程序就会变为:

这个改变也会让join()不再是一个异步函数。
5.13.3 str()
str()输入一个指针(char*), 返回字符串。语法如下:
str(char *s [, int length])
举例来说,bash(1) shell readline()的返回值是一个字符串,可以用如下的命令进行打印:

retval .n 返回值
这个单行程序可以显示系统范围内全部的bash交互命令。
默认情况下,返回的字符串的长度上限是64字节,这个长度限制可以通过bpftrace的环境变量BPFTRACE_STRLEN进行调整。目前还不支持超过200字节的长度;这是一个已知的限制,未来这个上限可以被极大地提高。
5.13.4 kstack() 和ustack()
kstack()和ustack()和内置变量kstack和ustack类似,不过它们可以接受一个limit参数和一个mode选项。语法如下:

举例来说,通过跟踪block:block__rq_insert这个跟踪点可以显示引发创建块I/O的内核调用栈,深度为3:
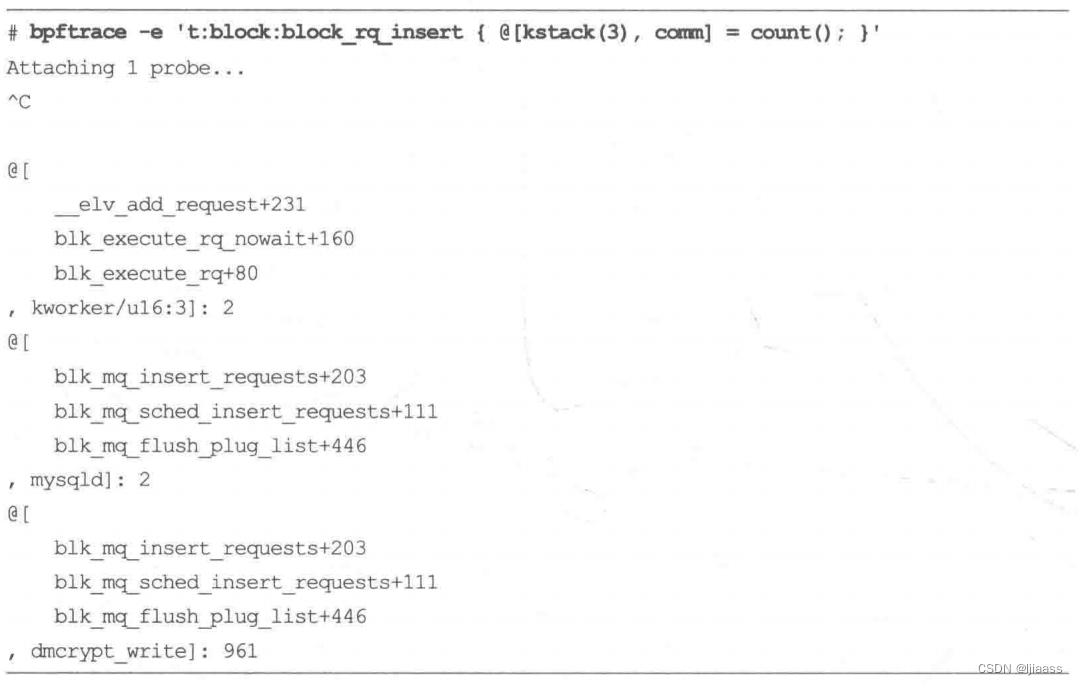
当前允许的最大调用栈的深度是1024。
mode参数可以用不同格式输出调用栈。目前只支持两种模式:默认是“bpftrace",
另一种是“perf",这会使输出的调用栈形式上和perf(1)工具保持一致。 举例来说:

5.13.5 ksym() 和usym()
ksym()和usym()函数可以将地址解析为对应的函数名称(字符串)。ksym()用于内核地址,usym() 用于用户空间地址。语法如下:

举个例子,timer:hrtimer_ start 跟踪点有-一个函数指针参数,可以用来对其调用频率计数:
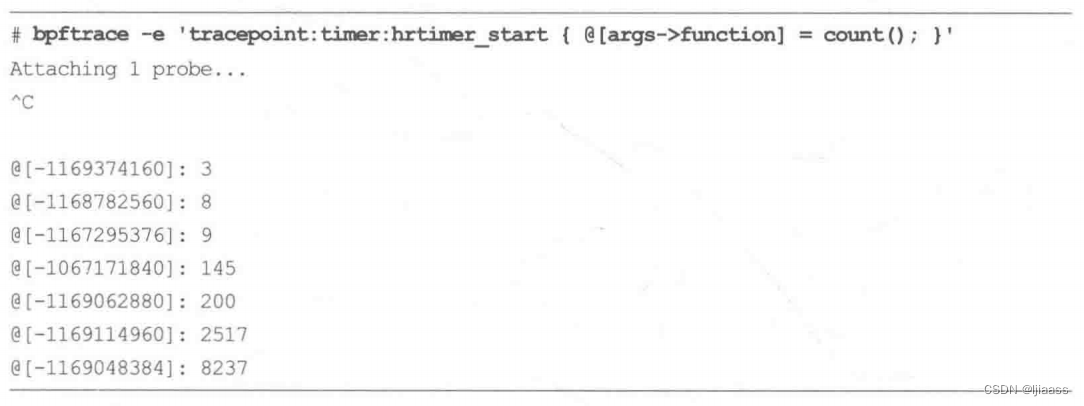
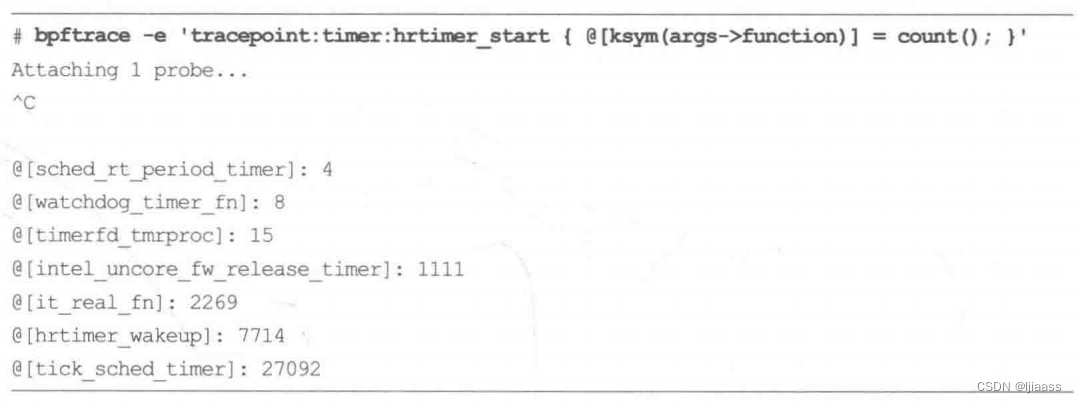
上面显示的是原始地址形式。使用ksym()可以将其转换为内核函数名:
5.13.6 kaddr() 和uaddr()
kaddr()和uaddr()的参数是一个符号名,返回其所在地址。kaddr()用于内核地址,uaddr()用于用户空间地址。语法如下:

举个例子,当bash(1) shell函数被调用时,开始查找用户空间符号“ps1_prompt",然后解析该地址并以字符串形式打印出来:

这会打印出符号的内容——在本例中就是bash(1)的PS1提示。
5.13.7 system()
system()从shell中执行命令。语法如下:
system(char *fmt [, arguments ...])
由于shell可以执行任意命令,因此system()被认为是不安全的函数,bpftrace 需要加上- -unsafe参数才可以使用。
举个例子,运行ps(1)来打印PID的调用nanosleep( ):

ps (英文全拼:process status)命令用于显示当前进程的状态,-p按进程ID选择
如果被跟踪的函数调用相当频繁,使用system()会在创建新的进程时消耗大量的CPU资源,应该只在必要时才使用system()。
5.13.8 exit()
exit()用来结束bpftrace程序。语法如下:
exit()
该函数可用于给周期性的探针固定的探测时长。举例如下:

这显示了在5秒内,–共有735次read()系统调用。所有的映射表都会在bpftrace结束时打印出来,就像本例中所示的那样。
5.14 bpftrace映射表的操作函数
映射表是BPF的一种特殊类型的哈希表存储对象,可用于不同的用途,比如,可用来存储键/值对和统计数值。bpftrace提供了内置的函数用于映射表赋值和操作,大多用于支持统计需求的映射表。一些重要的映射表函数在表5-7中被罗列了出来。

其中一些函数是异步的:内核会将事件加入队列,一小段时间后会在用户空间进行处理。异步的动作包括print()、clear() 和zero()。在写程序时一定要记住这里有个延迟。可以看在线的“bpftraceReferenceGuide”以得到完整和保持更新的函数列表。后面的小节中会对其中一些函数进行进一步讨论。
5.14.1 count()
count()对出现次数进行计数。语法如下:
@m = count() ;
该函数可以使用探针的通配符,并且可以使用内置的probe变量进行计数:
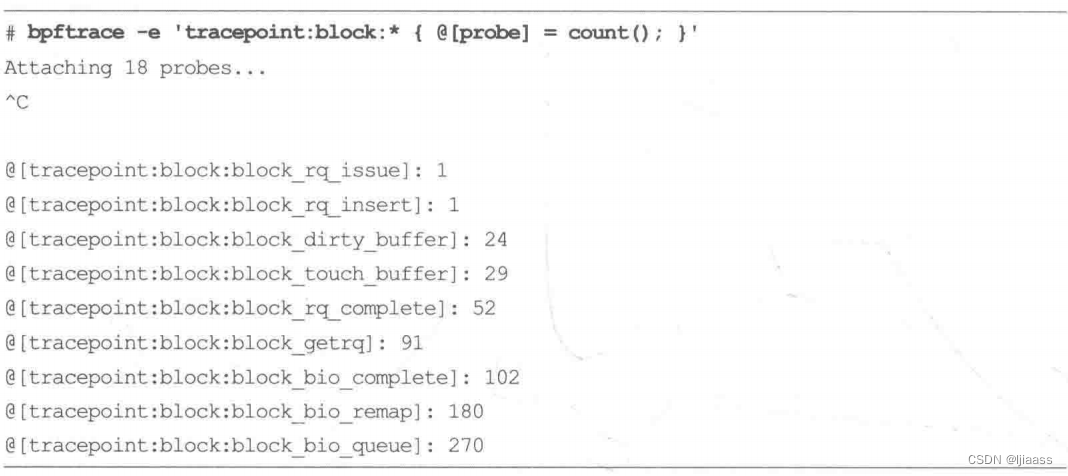
对于周期性探针( interval),可以周期性地进行打印,比如:

这个基本功能也可以使用perf(1)命令和Ftrace通过perfstat来实现。bpftrace支持更多的定制能力:使用BEGIN探针可以包含一个printf()调用来解释输出,而周期性的输出可以包含–个time()调用,使用时间戳标记每次调用。
5.14.2sum()、avg()、 min() 和max()
这些函数会把基础的统计值——和、平均值、最小值、最大值——以映射表形式进行存储。语法如下:

举例来说,使用sum()来统计通过read(2) 系统调用读取的总字节数:

这个映射表的名字叫作“bytes", 用来指明输出的含义。注意,这个例子中使用了一个过滤器来保证args->ret是正数:从read(2)中读取的正的返回值表明了读取的字节数量,而负值则表明出现了错误。这在read(2)的man帮助文档中有说明。
5.14.3 hist()
hist()将值存放到以2的幂为区间的直方图中。语法如下:
hist (int n)
下面是一个成功执行read(2)的返回值的直方图:
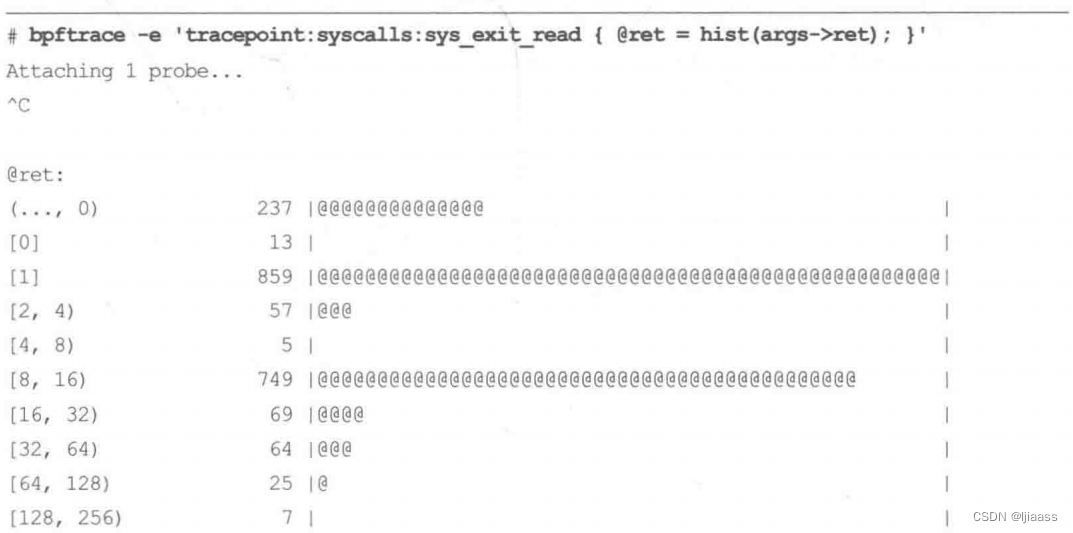

直方图对于定位分布的某些特征,比如多峰分布和离群点十分有用。这些示例直方图中有多个峰,一个峰读取的是size为0或小于0(小于0的返回值标志了错误)的返回值,另一峰读取的是size为1的返回值,还有一峰读取的是size的大小介于8~ 16之间的返回值。
区间中的字符的表示形式来自如下区间表示法。
■ [:表示大于或者等于
■ ]:表示小于或者等于
■ (:表示大于
■ ):表示小于
■…:表示无限
区间“[4,8)”代表了从4 (包含)到8 (不包含)的区间(也就是从4到7999…)。
5.14.4 Ihist()
step .n 步子
lhist( 数据,第一个区间尾点,最后一个区间起点,每个区间的宽度 ) 将值保存为线性直方图。语法如下:
lhist(int n, int min, int max, int step)
举个例子,一个read(2)调用返回值的直方图如下:
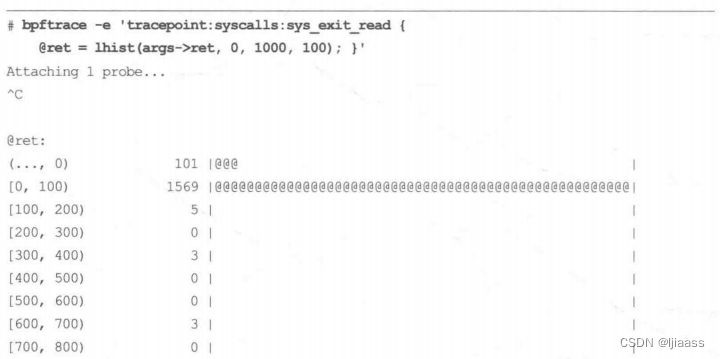

以上输出显示,多数的读操作返回值在0到(小于) 100之间。区间使用了和hist()相同的表示方法进行输出。“(… ,0)”. 这行显示了错误计数:在跟踪期间共有101次read(2)错误。注意,错误计数最好以另-种视角来看待,比如像下面这样专门对错误码进行统计:

错误码11代表了EAGAIN (再次尝试),read(2) 返回-11。
5.14.5 delete()
delete()从映射表中刪除一个键值对。语法如下:
delete(@map[key])
中括号里的key指定删除哪个键值。
根据映射表的类型不同,键的参数数量可能会多于1。
5.14.6 clear() 和zero()
clear()从映射表中删除全部键值对,zero() 则将全部值置为0。语法如下:
clear(@map)
zero(@map)
当bpfrace结束时,默认会将全部映射表打印出来。有些映射表,比如用于时间戳差值计算的,本不应该出现在工具的输出中,可以在END探针中将它们清空,以防止自动打印:

print()用来打印映射表。语法如下:
print(@m [, top [, div]])
可以使用两个参数: top指明只打印最高的top个项目,div 是-一个整数分母,用来将数值整除后输出。
为了说明top参数的用途,下面的例子打印了次数最多的5个以“vfs_ ”开头的内核函数调用:
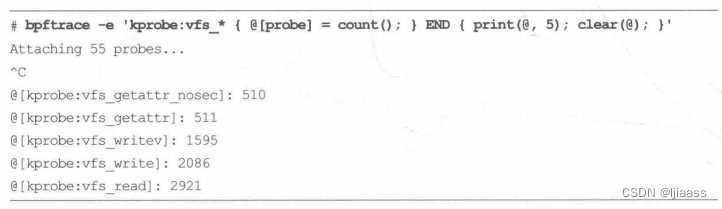
在上述跟踪过程中,vfs_ read() 被调用次数最多(2921 次)。为了说明div参数的用途,以下记录了vfs_ _read() 所花费的时间,并且以毫秒为单位打印出来:
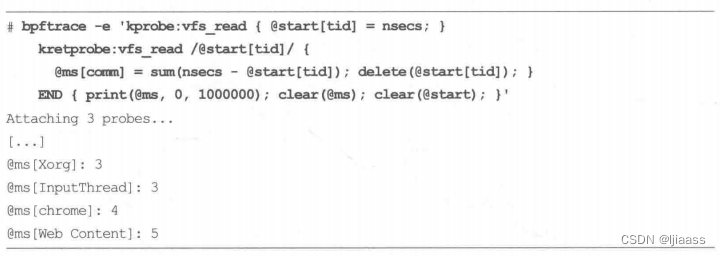
为什么需要有一个除数呢?这里我们本来可以这样来写这个程序:
@ms [comm] = sum( (nsecs - @start[tid]) / 1000000);
不过,sum() 对整数进行操作会向下取整,所以任何比1毫秒小的时间都会合计为0。这会导致输出出现取整导致的误差。解决方法是对纳秒求和sum(),这样就会保留1毫秒
以下的时间,这样在调用print()时会对其总数做除法得到结果。
未来对bpftrace的改动可能会允许print()无格式打印除映射表之外的任意类型。
5.15 bpftrace的下一步工作
有一些计划中的对bpftrace的工作,可能在你拿到这本书时已经完成了。你可以看一下 bpftrace的发布文档来检查新增加的特性,网址参见链接5。
本书中所包含的bpftrace源代码,目前并没有改动计划。如果确实碰到必须改变的时候,可以查看本书网址以了解更新,网址参见链接1。
5.15.1显 式区分地址模式
对bpftrace最大的改动会是要求显式区分内核态地址和用户态地址,这样可以用来支持将bpf_probe_read() 拆分为bpf probe_read_kemel()和bpf_probe_read_user()。这个拆分对于支持一些处理器架构来说是必需的。它不会对本书中提到的工具有任何影响。同时,还会增加相应的kstr()和ustr()两个bpftrace函数以明确地址模式。这些函数很少需要直接使用:bpftrace会尽可能根据探针类型和函数来自动判定地址空间的上下文。下面会展示如何使用探针的上下文。
kprobe/kretprobe (内核上下文):
- arg0…argN、 retval :作为内核态地址解引用。
- *addr::作为内核态地址解引用。
- str(addr) :得到一个以NULL结尾的内核字符串。
- *uptr(addr) :作为用户态地址解引用。
- str(ptr(addr))::获取一个以NULL结束的用户字符串。
uprobe/uretprobe (用户上下文):
- arg0…argN、retval :作为用户态地址解引用。
- *addr:作为用户态地址解引用。
- str(addr):得到一个以NULL结尾的用户态字符串。
- *kptr(addr):作为内核态地址解引用。
- str(kptr(add)):获取一个以NULL结束的内核态字符串。
这样*addr和str()可以继续工作,但是只会指向探针上下文所在的地址空间:对kprobes来说是内核态的地址,对uretprobes来说是用户态的地址。为了扩展地址空间,必须使用kptr()和uptr()函数。一些函数,比如curtask),会返回一个内核指针,而不管是否是内核上下文(符合用户预期)。
其他探针类型则默认指向内核上下文,但是也会有一些特例,在“bpfraceReference Guide" 中有说明。一个特例是syscall(系统调用)跟踪点,这个跟踪点中包含的是指向用户地址空间的指针,所以它们的探针动作会带有用户地址空间上下文。
5.15.2其他扩展
其他计划中的扩展包括:
- 用于内存观察点(memory watchpoint) 的额外探针类型, socket和skb程序以及裸跟踪点。
- 带偏移量的 uprobe和kprobe函数。
- 支持Linux 5.3的BPF受限循环的for和while循环。
- 裸PMC探针类型(提供一个掩码和事件选择支持)。
- uprobes也支持不带绝对路径的相对函数名(比如,uprobe:/ib/x86_ 64-linux-gnu/lib…和upbob:…都可以工作)。
- 使用signal()向进程发送信号(包括SIGKILL)。,
- 使用return()或override() 对事件的返回值进行重写(使用bpf_override_returm()。
- ehist()用来做指数区间直方图。当前使用以2的幂为区间的直方图,hist()可以切换到ehist()以得到更高的精度。
- pcomm用来返回进程名字。comm返回的是线程的名字,通常情况下,线程名和进程名相同。但是有一些应用,比如Java可能为每个线程设置不同的comm。在这种情况下,pcomm 仍会是“java”.
- 一个用来将file结构体指针还原为完整路径的辅助函数。
一旦完成这些扩展,你就可以将本书中的一些工具从hst()转换到chist()以更高精度统计,并且在使用uprobes时,使用更简单的相对路径,而不是像现在一样 需要提供完整路径。
5.15.3ply
Tobias Waldekranz创建了BPF 的前端ply,提供了一种类似bpftrace的高级语言,同时尽量避免需要依赖(不需要LLVM和Clang)。这就使得ply适用于资源受限的环境,不好的一点是,无法包含头文件和访问结构体变量( 本书中的很多工具都需要这些支持)。
下面是ply对open(2)跟踪点进行插桩的例子:

这个单行程序和bpfrace的对应版本几乎是一样的。ply的后续版本可能会直接支持bpftrace语言,这样就提供了轻量级的工具运行bpftrace单行程序。此类单行程序通常无法使用结构体的内部成员,最多只能使用跟踪点的参数(像本例中提到的一样),这个功能是ply支持的。将来,具备了BTF功能后,ply可以使用BTF得到结构体信息,这样就可以支持运行更多的bpfrace程序了。
5.16 bpftrace的内部运作
图5-3展示了bpftrace的内部运作。
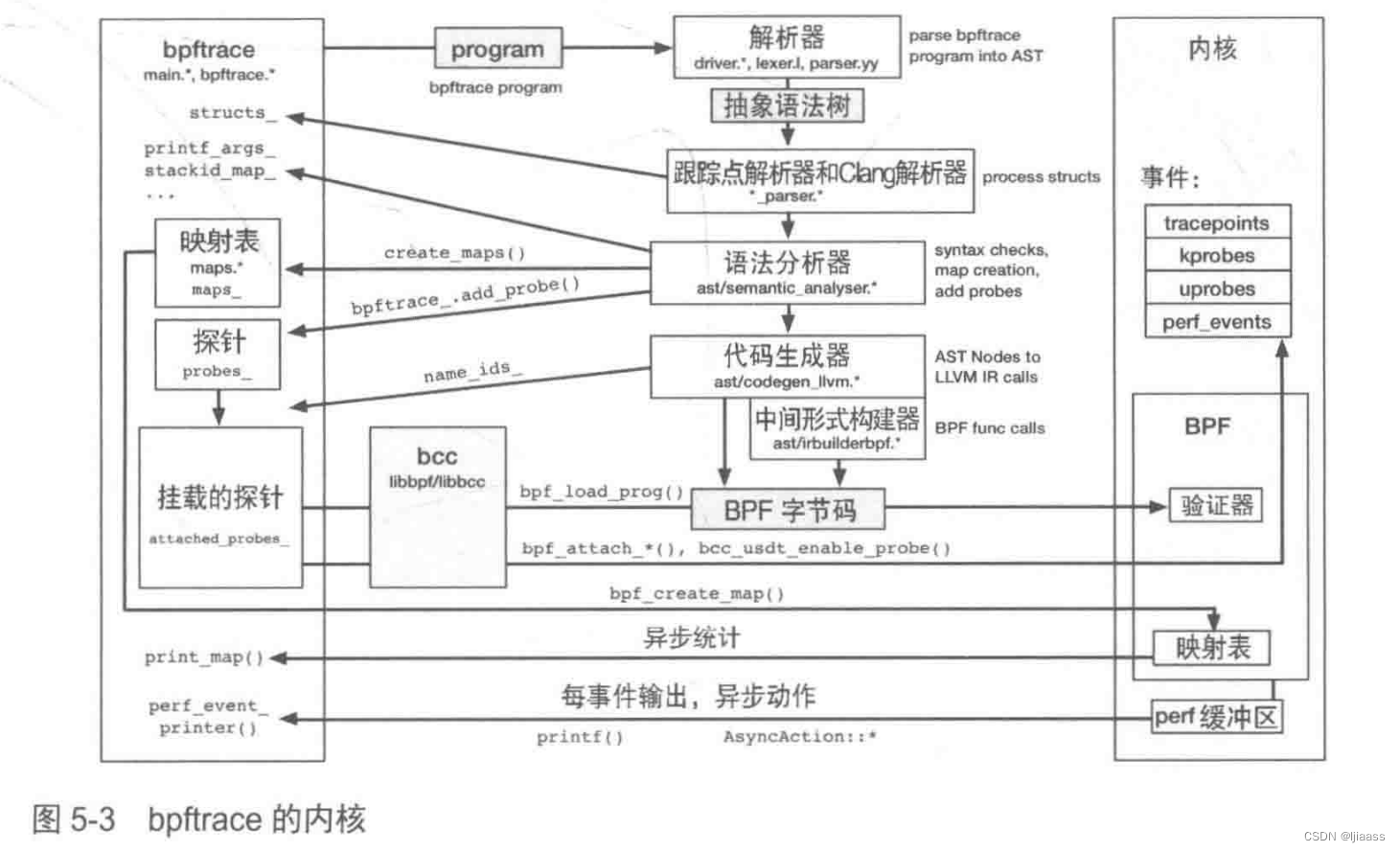
bpftrace使用libbec和libbpf完成对探针的插桩、程序的加载,以及使用USDT。它也使用LLVM将程序编译为BPF字节码。
bpftrace语言是使用lex和yacc文件定义的,会分别经过flex和bison程序处理。输出是一个作为抽象语法树存在的程序。跟踪点解析器和Clang解析器会对这个结构进行语法分析。一个语法分析器会检查语言元素的使用,在出错时会抛出错误。下一步是代
码生成一将 AST节点转为LLVMIR,最后再由LLVM编译为BPF字节码。
下一节会介绍bpftrace 的调试模式,在该模式下会动态展示这些步骤: -d打印AST和LLVMIR,-V打印BPF字节码。
5.17 bpftrace的调试
有很多种方式可对bpftrace程序进行调试和定位问题,本节会简要介绍printf()语句和bpftrace调试模式。如果你看到这里是因为在定位问题,那么可能还需要看一下第18章,那里会介绍常见的问题,包括丢失的事件、残缺的调用栈和不完整的符号问题。bpfrace是一种强大的语言,它是由一组稳定的、从设计上来说可以安全并存,并且会拒绝以错误方式使用的功能集组成的。作为对比,BCC允许C和Python程序执行,可以使用的能力范围更广,但是这些能力并不确保一定可以协同工作。这样一来,bpftrace倾向于失败时弹出用户友好的错误消息,一般不需要再进一步进行调试。而BCC程序可能需要使用调试模式来解决未知问题。
5.17.1 printf() 调试
可以插入printf()语句以显示某个探针是否被实际激活,也可以用来查看某个变量的值是否符合预期。考虑以下程序:打印一个vfs _read() 函数执行时长的直方图。然而,当运行时,你可能会发现它的输出中包含了超高时长的离群点。你能定位问题所在吗?

如果bpftrace在执行的时候存在只执行了一半的vfs. read),那么会导致后面的kretprobe触发执行,因为在这种情况下,@start[tid] 尚未被初始化,这样延迟计算的结果就变成了“nsecs- 0”。解决方案是在kretprobe.上增加一个过滤器,在进行计算之前先检查@start[id]是否为0。这时可以通过printf()语句检查输入的方式以进行调试:printf (“Sduration. ms = (%d - 8d) / 1000000\n”, nsecs, @start[tid]);
还有bpftrace调试模式(后面会讲),不过此类bug可以通过选好位置加入printf()轻松解决。
5.17.2调试模式
使用-d选项可以开始bpftrace的调试模式,这时它不会运行程序,而是会展示它是如何进行语法分析然后转换为LLVMIR的。注意,这个模式通常仅对bpfrace的开发者有用。这里介绍这个功能是为了让你了解它的存在。该命令会以打印代表整个程序的抽象语法树(AST)作为开始:

接下来会打印转换为的LLVM IR汇编语言:


还有一个-dd选项,其为调试详情模式,会打印出更多的信息:优化前/后的LLVM IR汇编语言。
5.17.3详情模式
使用-v可以开启详情模式,bpftrace 会在运行时打印出额外的信息。比如:

程序ID可以如第2章中所介绍的,配合bpftool使用,用来打印BPF的内核状态。
BPF字节码也会被打印出来,后面跟的是它所挂载的探针。和-d一样,这个级别的信息主要对bpftrace核心开发者有用。普通用户在使用bpftrace时,并不需要操心实际执行的BPF字节码。















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









