






该文档围绕 DeepSeek - R1 和 Kimi 1.5 等强推理模型展开,详细介绍了模型的开发技术、优势、技术对比以及未来发展方向,旨在探讨强推理模型在人工智能领域的重要进展和应用潜力。
模型概述与意义
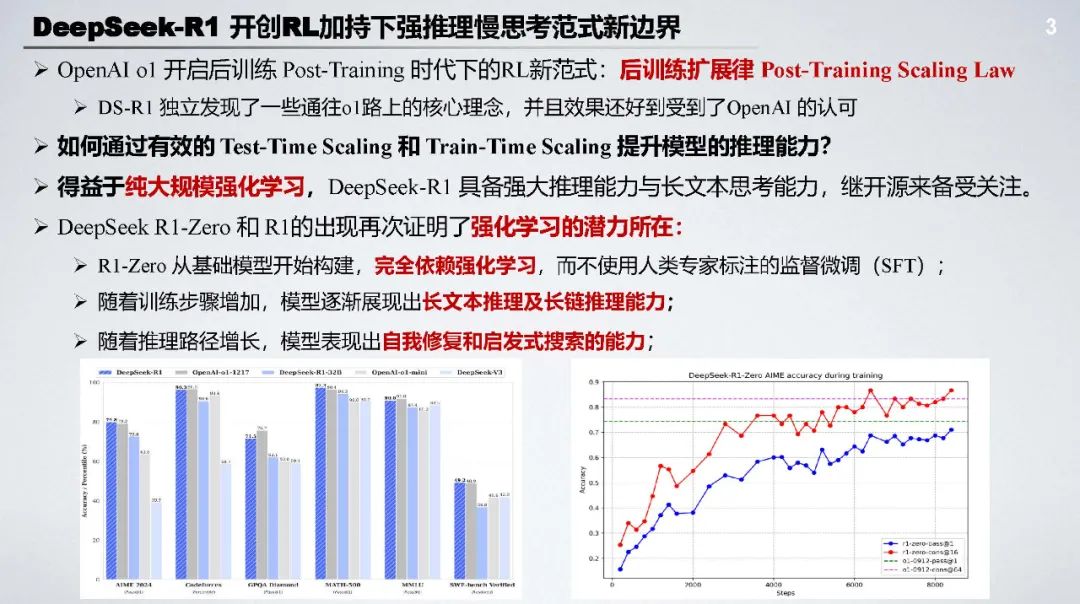
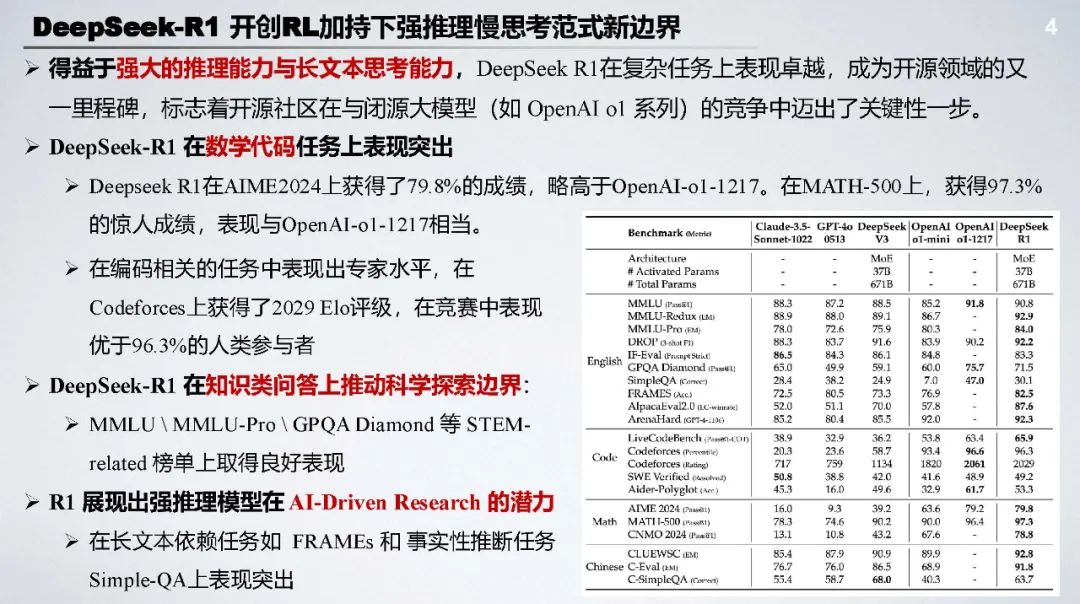
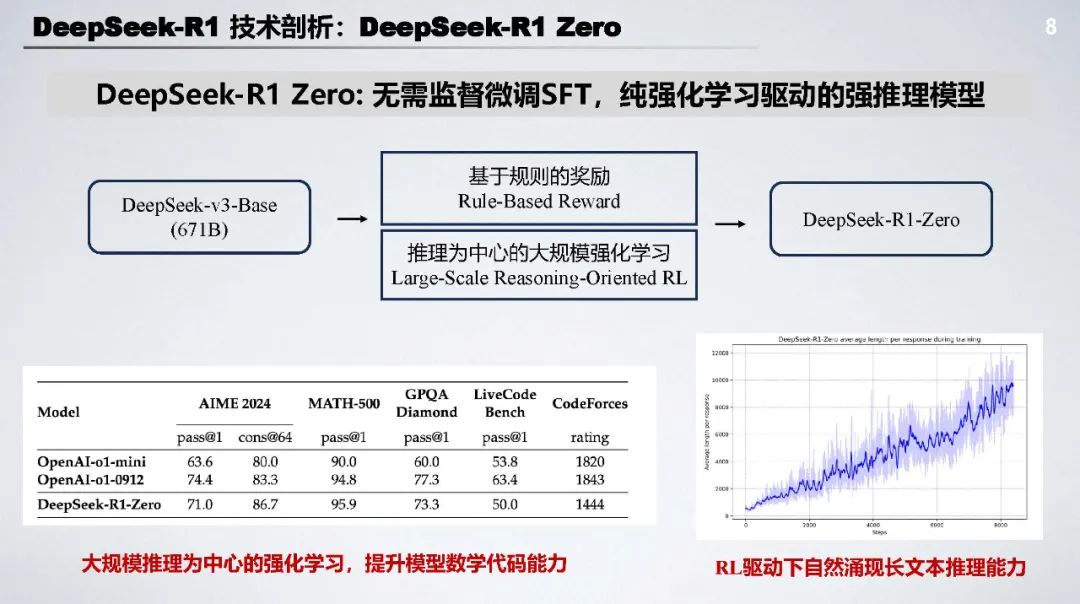
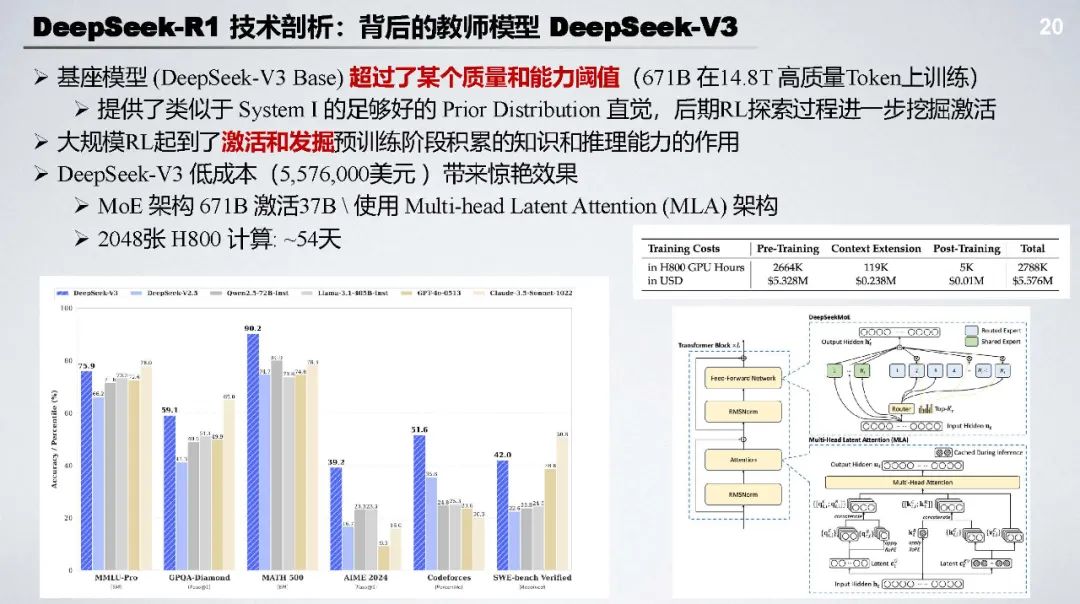
DeepSeek - R1 开创了 RL 加持下强推理慢思考范式新边界,在数学、代码、知识问答等任务上表现卓越,是开源领域的重要里程碑。其成功证明了强化学习在提升模型推理能力方面的巨大潜力。
技术剖析
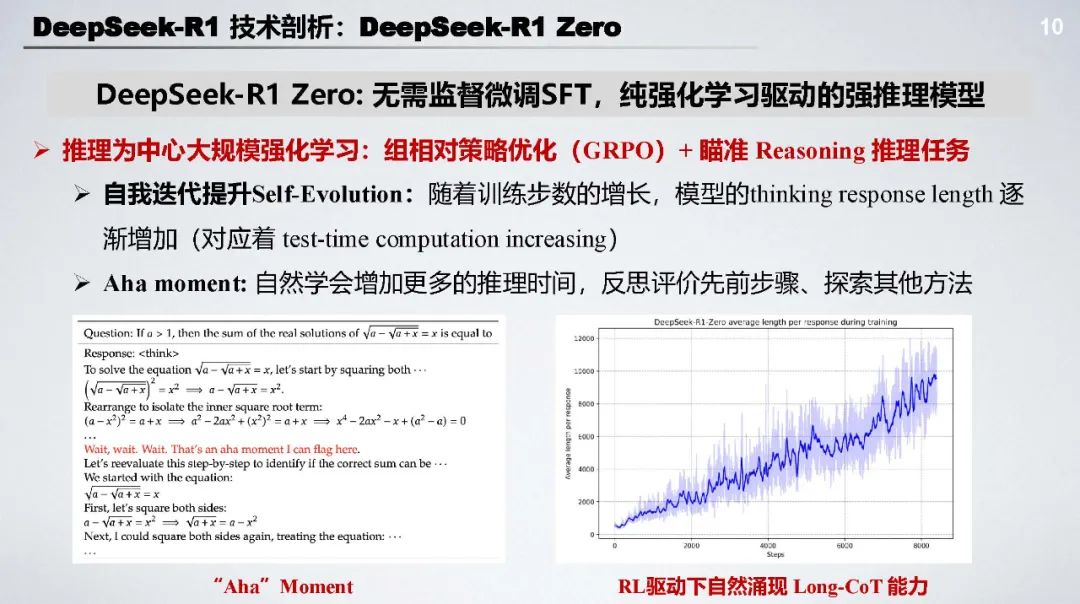
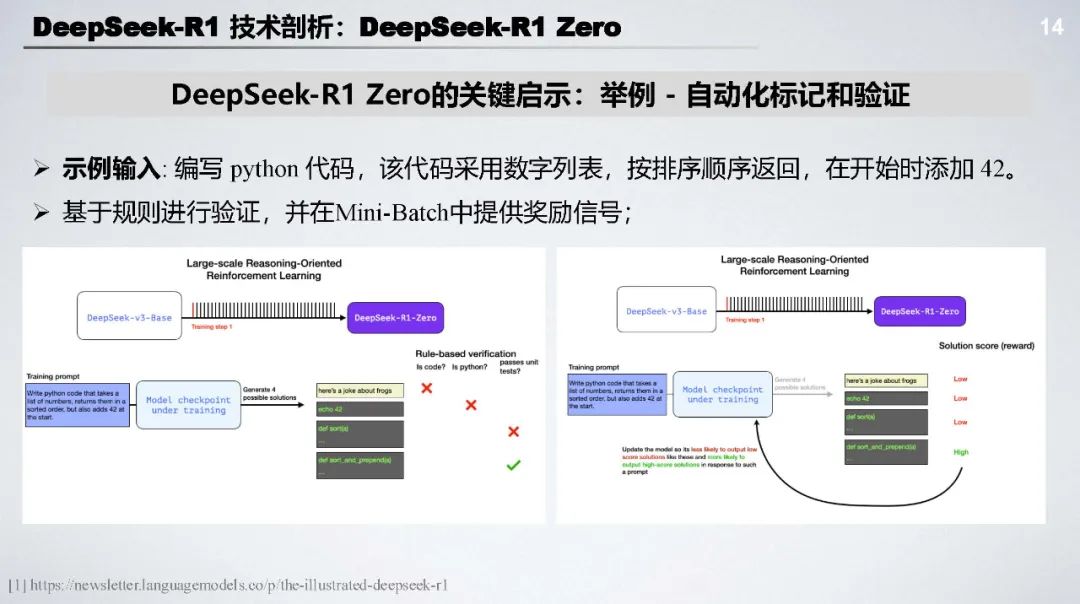
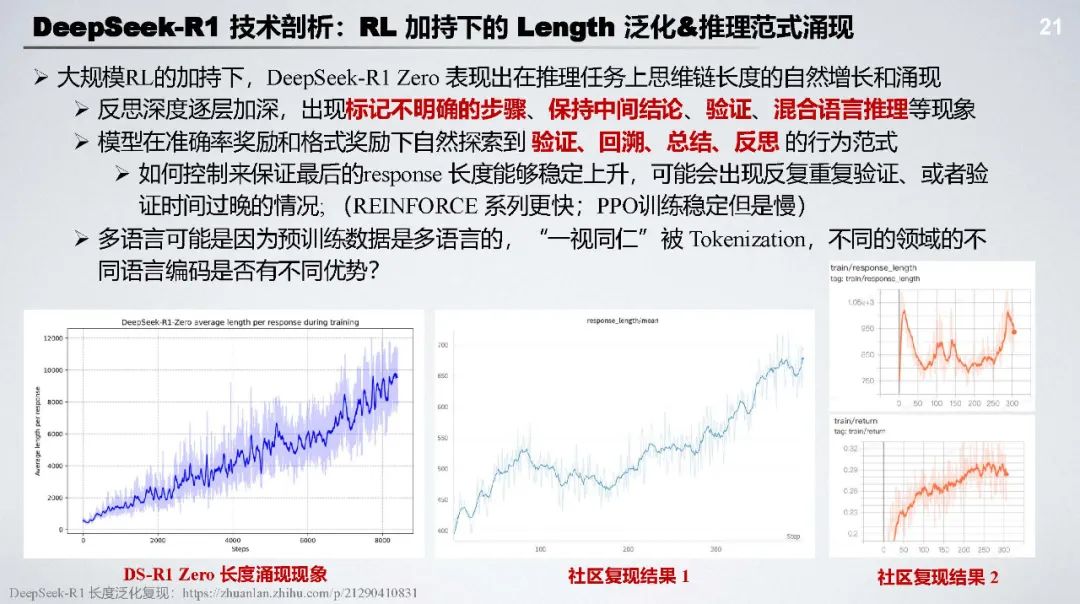
DeepSeek - R1 Zero:无需监督微调 SFT,采用基于规则的奖励(准确率奖励 + 格式奖励 )和以推理为中心的大规模强化学习(GRPO),能自主涌现长文本推理和自我修复等能力。
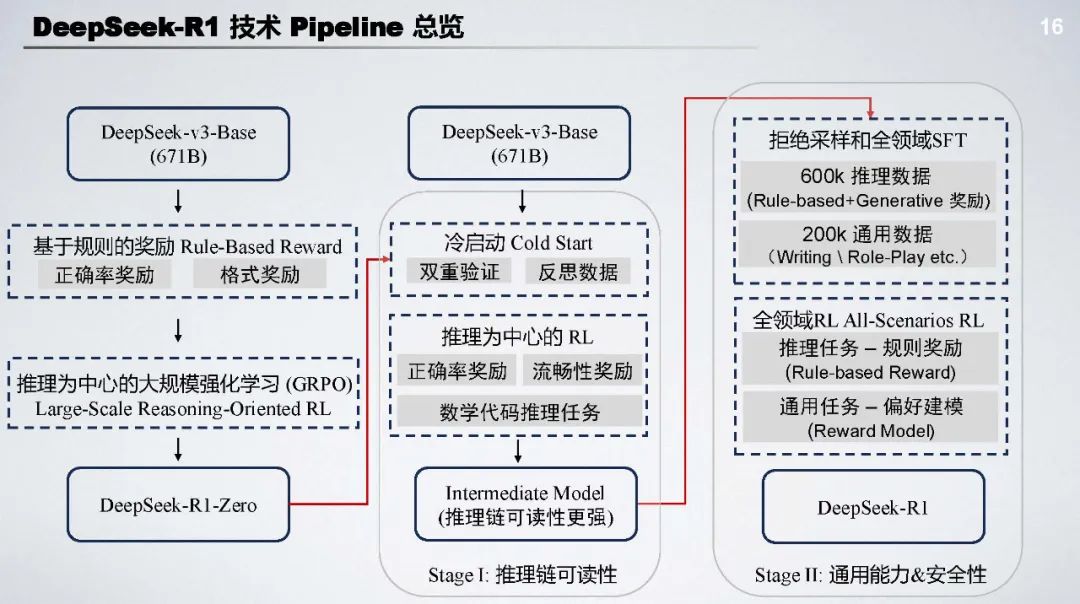
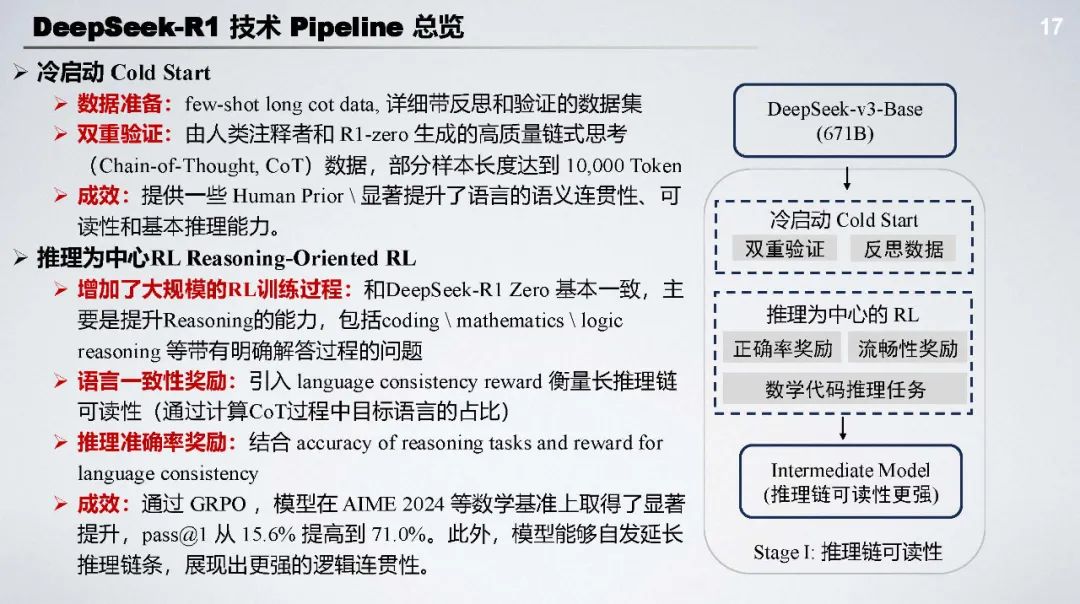
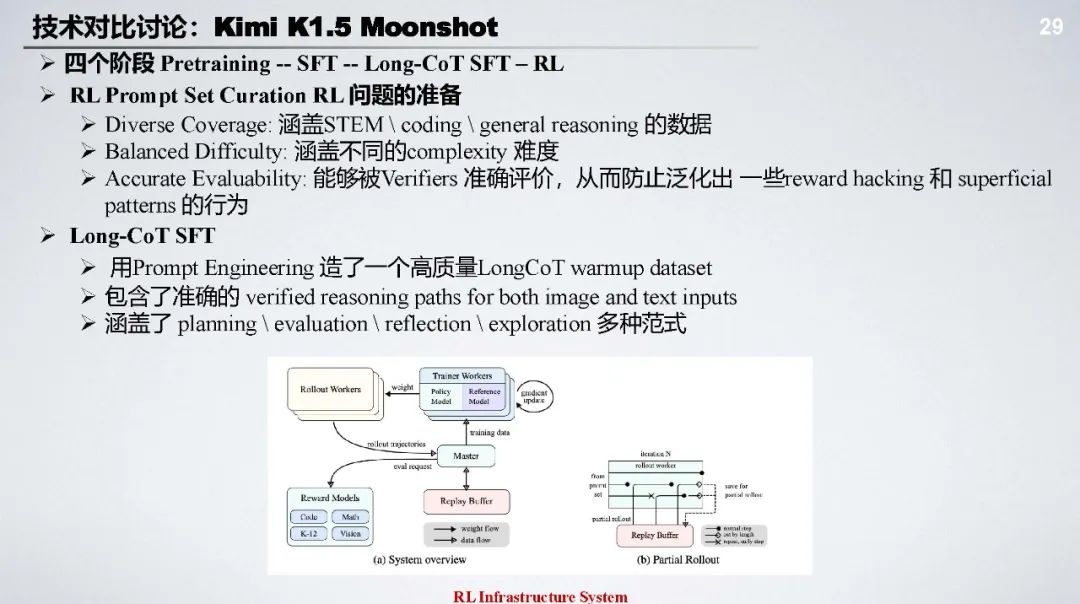
DeepSeek - R1 技术 Pipeline:包括冷启动、推理为中心 RL、拒绝采样和全领域 SFT、全领域 RL 等阶段,通过多阶段训练提升模型推理链可读性、通用能力和安全性。
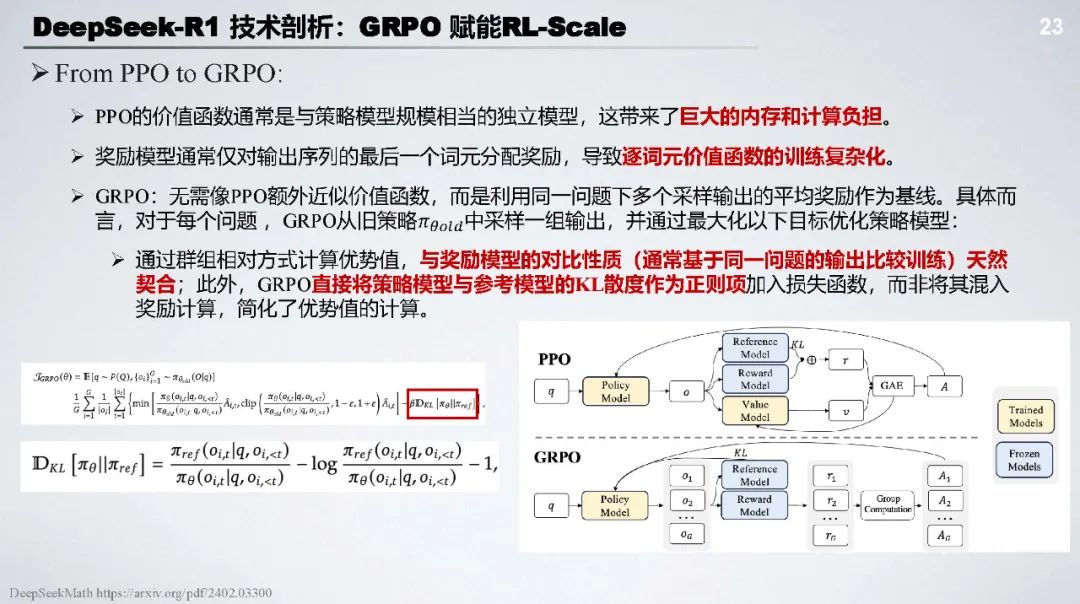
GRPO 算法:通过构建模型输出群组计算相对奖励估计基线,避免使用与策略模型相同大小的评论模型,降低计算成本,提升训练稳定性,有基于结果监督和过程监督两种方式。
技术亮点与收益
技术亮点:跳过 SFT 阶段,节省标注成本,让模型自由探索;多阶段训练的冷启动使 RL 训练更稳定;具备强大的自验证和长链推理能力 ;采用语言一致性奖励等多目标优化策略。
社会和经济效益:探索低成本高质量语言模型边界,促进资源优化、市场激活和高效创新,推动行业生态繁荣。
技术对比讨论
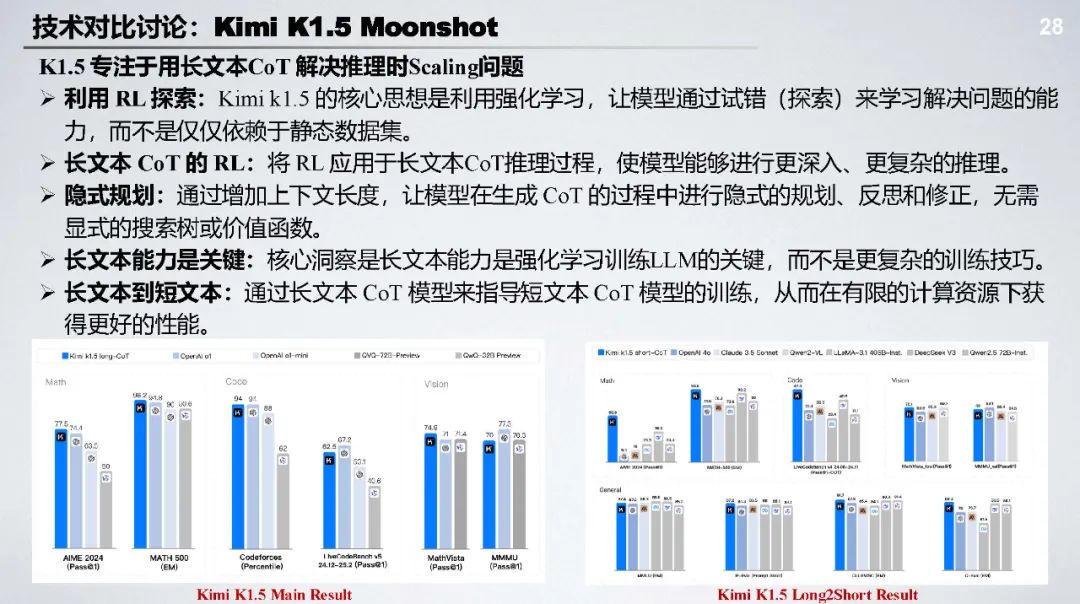
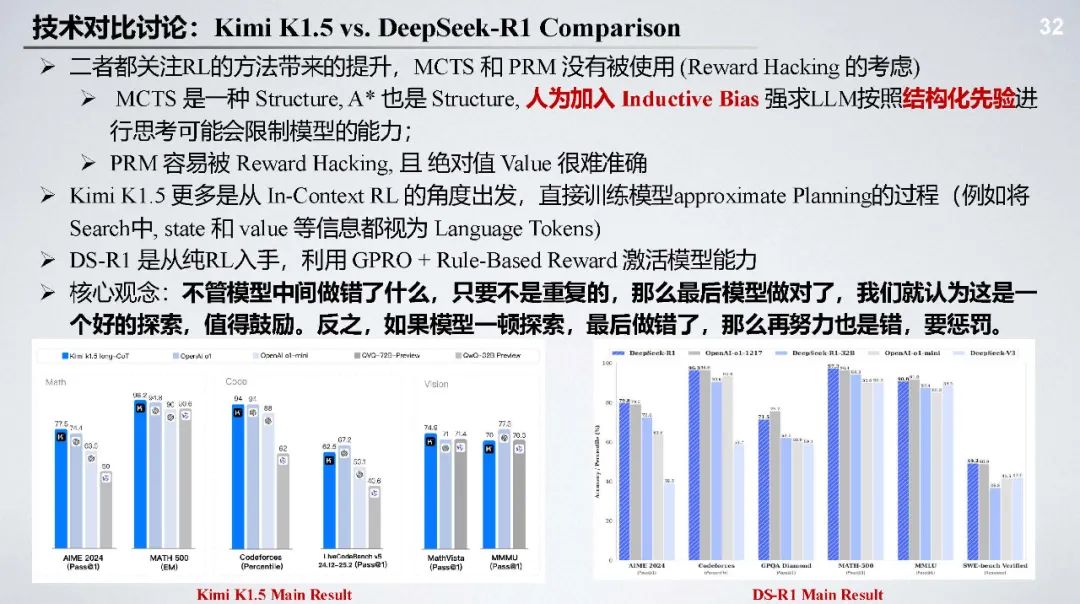
与 Kimi K1.5 对比:二者都关注 RL 提升,Kimi K1.5 从 In - Context RL 出发训练模型 approximate Planning 过程,DS - R1 从纯 RL 入手利用 GRPO 和规则奖励激活模型能力。
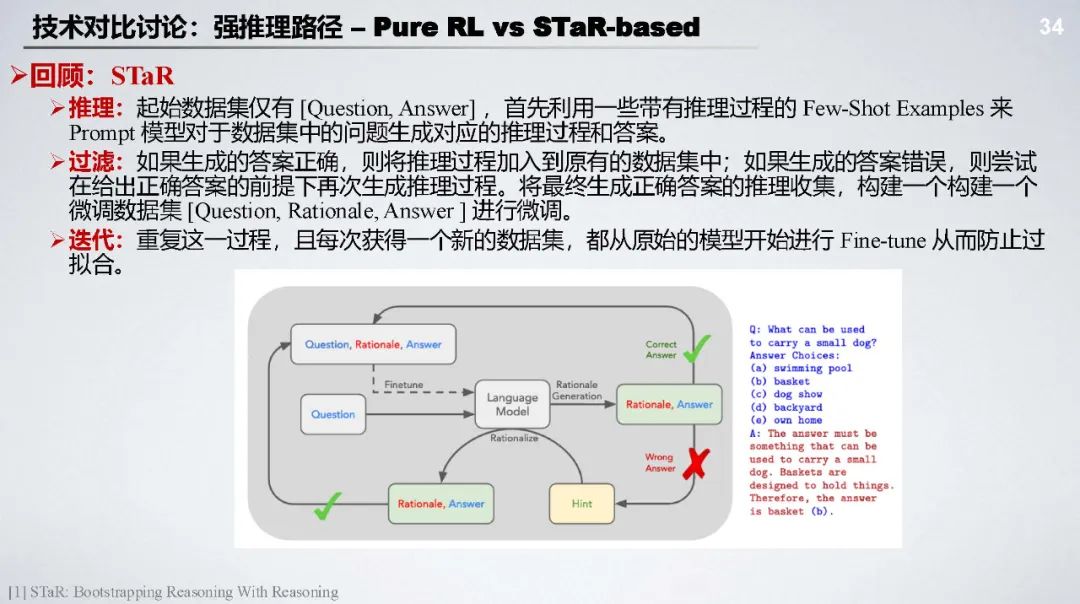
纯 RL 与 STaR - based 对比:STaR 将思考过程建模到 Next Token Prediction 中,通过迭代和微调学习 MetaCoT,但对问题结构要求高,难以融入 Rule - Based Reward;纯 RL 则直接激活基座模型推理潜力。
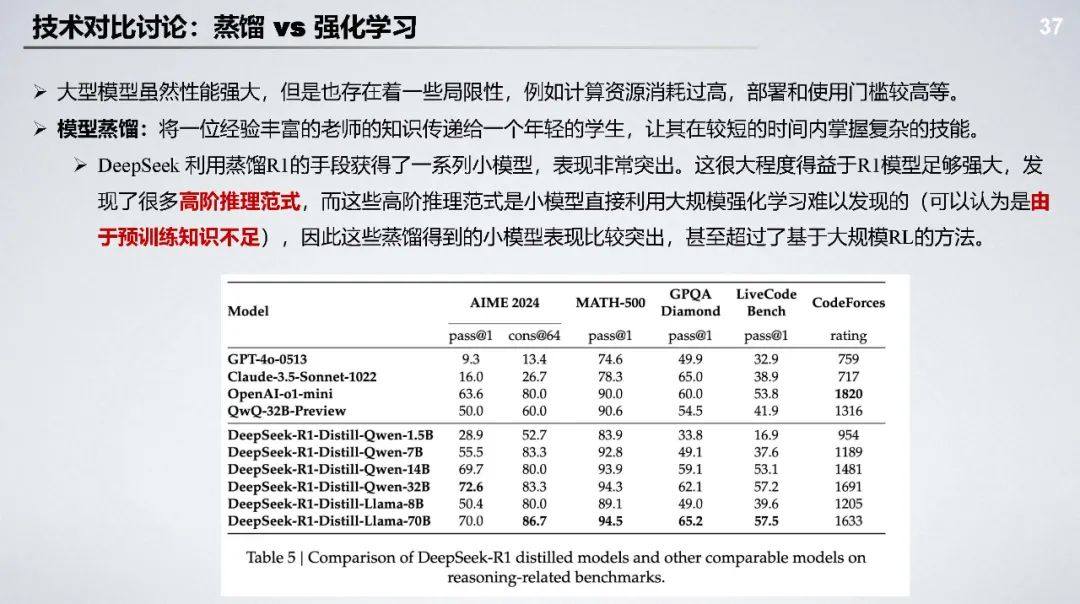
蒸馏与强化学习对比:蒸馏可学习数据中的推理范式,但难以学习数学规律和 MetaCoT;强化学习通过试错学习推理规律,泛化性更强。
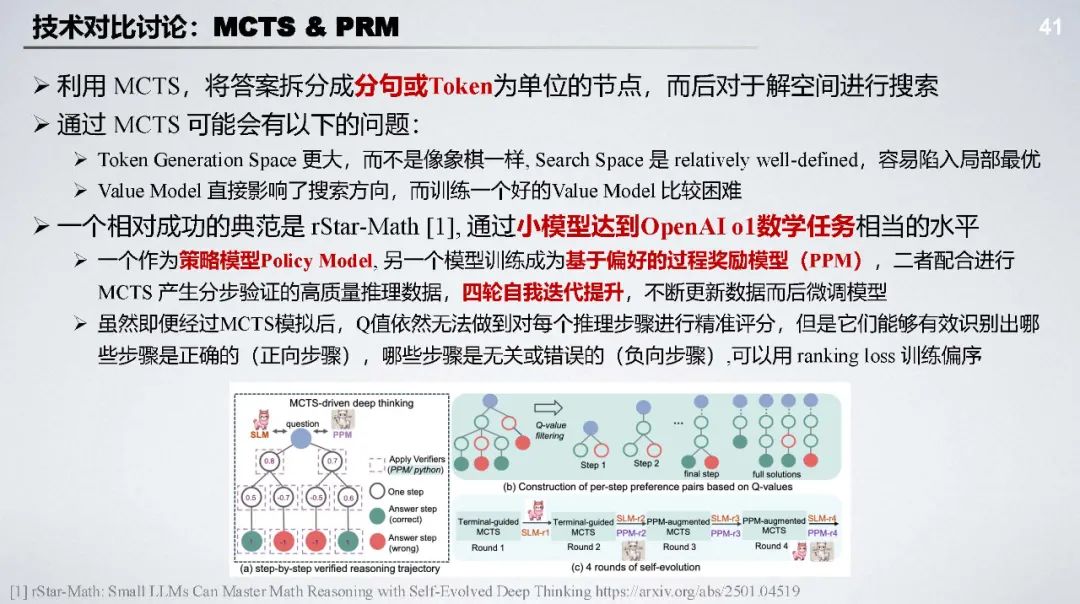
MCTS 和 PRM 分析:MCTS 应用于模型训练可能限制模型思考,PRM 存在自动化标注难、易被 reward hacking 等问题,但二者都有一定潜力。
未来技术展望
长思维链可解释性:CoT 可提高模型可解释性,但不能完全解决问题,需结合多种方法防止模型欺骗。
模态扩展与穿透:多模态场景下存在诸多挑战,提出从语言反馈中学习的模态统一范式 LLF,Align - Anything 框架支持全模态对齐。
强推理赋能 Agentic 发展:利用强推理能力赋能 Agent 和具身智能,需克服内存和记忆模块等挑战。
模型监管与安全保证:大模型存在弹性抗拒对齐,审计对齐 Deliberative Alignment 利用强推理能力学习安全规范,形式化验证可提升 AI 系统可靠性。
后台回复“250301A”,可获得下载资料的方法。




























本公号使用腾讯元器(使用DeepSeek R1大模型)创建了智能交通技术AI服务,欢迎扫码进入体验(或在后台使用私信对话)。

点击文后阅读原文,可获得下载资料的方法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









