






限流粒度分类
根据限流的粒度分类:
-
单机限流
-
分布式限流
现状的系统基本上都是分布式架构,单机的模式已经很少了,这里说的单机限流更加准确一点的说法是单服务节点限流。单机限流是指请求进入到某一个服务节点后超过了限流阈值,服务节点采取了一种限流保护措施。
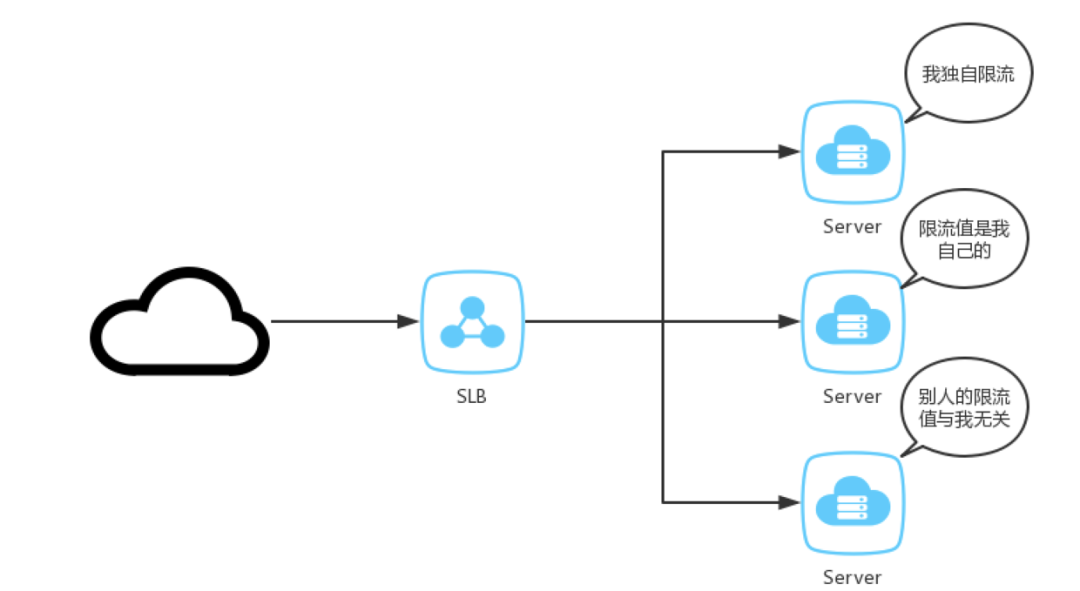
单机限流示意图
分布式限流狭义的说法是在接入层实现多节点合并限流,比如NGINX+redis,分布式网关等,广义的分布式限流是多个节点(可以为不同服务节点)有机整合,形成整体的限流服务。
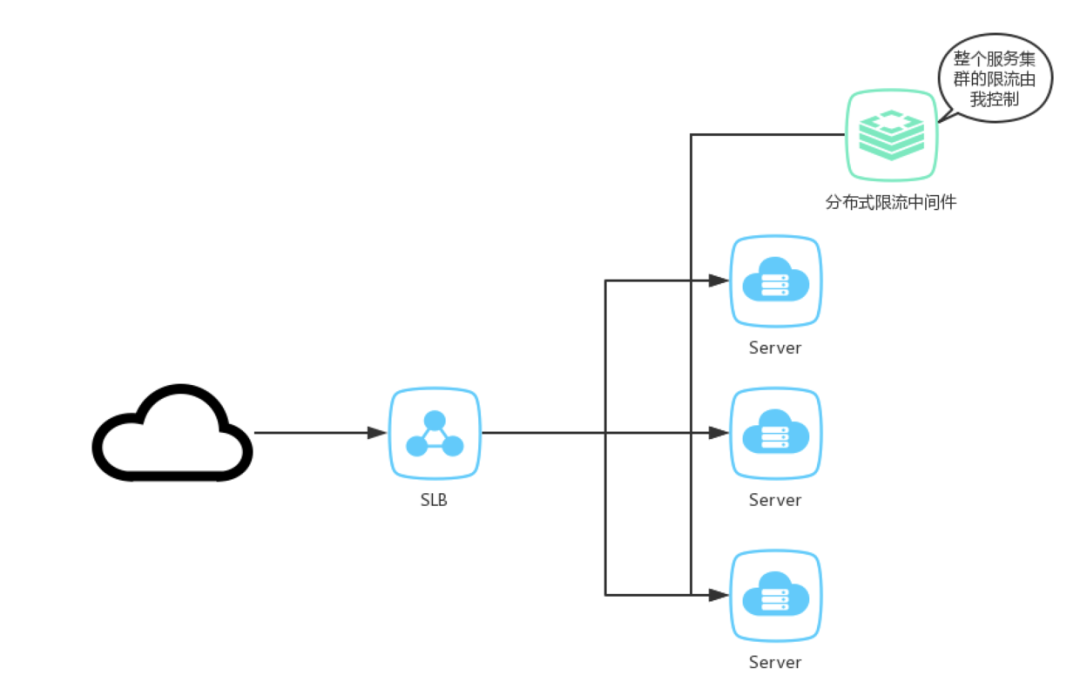
分布式限流示意图
单机限流防止流量压垮服务节点,缺乏对整体流量的感知。分布式限流适合做细粒度不同的限流控制,可以根据场景不同匹配不同的限流规则。与单机限流最大的区别,分布式限流需要中心化存储,常见的使用redis实现。引入了中心化存储,就需要解决以下问题:
-
数据一致性
在限流模式中理想的模式为时间点一致性。时间点一致性的定义中要求所有数据组件的数据在任意时刻都是完全一致的,但是一般来说信息传播的速度最大是光速,其实并不能达到任意时刻一致,总有一定的时间不一致,对于我们CAP中的一致性来说只要达到读取到最新数据即可,达到这种情况并不需要严格的任意时间一致。这只能是理论当中的一致性模型,可以在限流中达到线性一致性即可。
-
时间一致性
这里的时间一致性与上述的时间点一致性不一样,这里就是指各个服务节点的时间一致性。一个集群有3台机器,但是在某一个A/B机器的时间为
Tue Dec 3 16:29:28 CST 2019,C为Tue Dec 3 16:29:28 CST 2019,那么它们的时间就不一致。那么使用ntpdate进行同步也会存在一定的误差,对于时间窗口敏感的算法就是误差点。 -
超时
在分布式系统中就需要网络进行通信,会存在网络抖动问题,或者分布式限流中间件压力过大导致响应变慢,甚至是超时时间阈值设置不合理,导致应用服务节点超时了,此时是放行流量还是拒绝流量?
-
性能与可靠性
分布式限流中间件的资源总是有限的,甚至可能是单点的(写入单点),性能存在上限。如果分布式限流中间件不可用时候如何退化为单机限流模式也是一个很好的降级方案。
限流对象类型分类
按照对象类型分类:
-
基于请求限流
-
基于资源限流
基于请求限流,一般的实现方式有限制总量和限制QPS。限制总量就是限制某个指标的上限,比如抢购某一个商品,放量是10w,那么最多只能卖出10w件。微信的抢红包,群里发一个红包拆分为10个,那么最多只能有10人可以抢到,第十一个人打开就会显示『手慢了,红包派完了』。

红包抢完了
限制QPS,也是我们常说的限流方式,只要在接口层级进行,某一个接口只允许1秒只能访问100次,那么它的峰值QPS只能为100。限制QPS的方式最难的点就是如何预估阈值,如何定位阈值,下文中会说到。
基于资源限流是基于服务资源的使用情况进行限制,需要定位到服务的关键资源有哪些,并对其进行限制,如限制TCP连接数、线程数、内存使用量等。限制资源更能有效地反映出服务当前地清理,但与限制QPS类似,面临着如何确认资源的阈值为多少。这个阈值需要不断地调优,不停地实践才可以得到一个较为满意地值。
限流算法分类
不论是按照什么维度,基于什么方式的分类,其限流的底层均是需要算法来实现。下面介绍实现常见的限流算法:
-
计数器
-
令牌桶算法
-
漏桶算法
计数器
固定窗口计数器
计数限流是最为简单的限流算法,日常开发中,我们说的限流很多都是说固定窗口计数限流算法,比如某一个接口或服务1s最多只能接收1000个请求,那么我们就会设置其限流为1000QPS。该算法的实现思路非常简单,维护一个固定单位时间内的计数器,如果检测到单位时间已经过去就重置计数器为零。
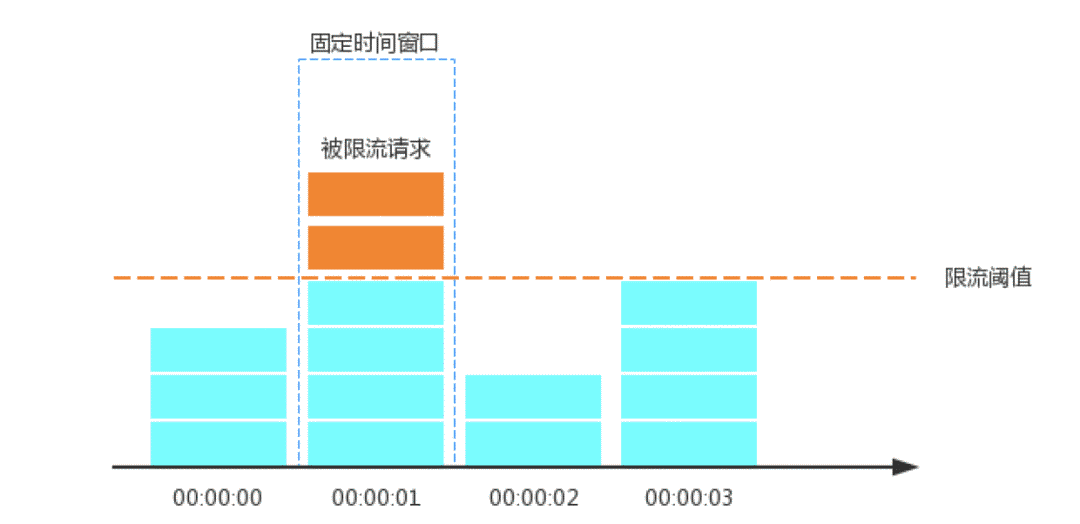
固定窗口计数器原理















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









