






第一阶段
基础命令
【一些小知识点】:
SQL
SQL(Structured Query Language 即结构化查询语言) SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。 DDL语句 数据库定义语言:数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER DML语句 数据库操纵语言(对记录的操作): 插入数据INSERT、删除数据DELETE、更新数据UPDATE DCL语句 数据库控制语言(和权限有关): 例如控制用户的访问权限GRANT、REVOKE DQL语句 数据库查询语言:查询数据SELECT
yum makecache fast 快速加载 ps -ef |grep nginx 简略列出 ps aux| grep nginx 详细列出 nginx -s stop 停止nginx服务 ss -tunlp |grep 80 过滤80端口 systemctl enable --now nginx 启动服务并加入到开机自启ing systemctl disable --now firewalld 关闭防火墙,开机自动关闭。 添加ip 地址: • 添加:ifcongfig ens33:1 192.168.107.50/24 • 删除:ifcongfig ens33:1 192.168.107.50/24 down\ hostname -I 查看主机的ip地址 server_tokens off; 添加 /etc/nginx/nginx.conf http协议族 ,隐藏nginx版本 watch -n 1 ifconfig 查看实时流量 # 查看所有网卡实时网速 nload -m 需要下载 yum -y install nload
sql终端执行shell命令:\! ls
数据库中使用正则:regexp:正则表达
案例:select * from emp where name regexp '^j.*(n|y)$';
🎈** 的各种用法:反引号和()一样**
🎈运算方式三种:(()) [ ] exper
🎈 ntpdate ntp.aliyun.com 时间同步
🎈关机: init 0、 poweroff 重启:reboot 、init6
🎈关闭防火墙 : systemctl stop firewalld
🎈永久关闭防火墙: systemctl disable firewalld
🎈临时关闭 setenforce 0
🎈永久关闭,需要重启机器 : vim /etc/sysconfig/selinux 修改为disable
🎈启动网卡: ifup ens33
🎈重启网络 systemctl restart network
一、Linux命令
①IP a--------查看IP地址。
②useradd 用户名--------添加用户。
③userdel -r 用户名-----删除用户名。
④Id 用户名--------查看用户
⑤Su - 用户名--------切换到用户名的家目录。
⑥Su 用户名--------切换到当前用户的家目录。、
⑦命令 --help-------------查看命令的相关帮助
二、ls 命令
①ls 命令:显示(查看)文件的属性信息。
②目录文件(文件夹):存储其他文件(目录文件、普通文件、链接文件、管道文件。。。。)。
③普通文件(文本文件):存储文字。
④ls -l --------详细显示文件的属性信息。
⑤ls -a --------查看目录内所有文件的信息,包含隐藏文件。
⑥ls -h --------人性化显示文件大小的单位。
⑦ls -d --------查看目录本身的属性信息(只针对目录生效)。
⑧ls -t --------按时间顺序查看文件。
date 查看时间
Date +%F显示年月份
Date +%X显示小时分钟秒
netdate ntp.aliyun.com 时间同步 yum -y install ntpd date -s 修改时间 例如 date -s 2012-12-10
①touch 普通文件,创建一个普通文件。
例如:touch /home/yxy.txt。在home中创建一个yxy.txt普通文件。
②mkdir 目录文件夹,创建一个目录文件,里面用来放普通文件。
例如:mkdir /home/yxl 在home中创建一个yxl目录文件。
③rm -rf 文件地址---删除文件。
例如:rm -rf /home/yxy 删除home中的yxy目录文件。
*三、命令别名*
①Type 别名(命令)-----查看别名的是由那些命令缩写
②alias 别名=’命令’设置临时别名
例如:alias qf=’df -Th’
取消别名:unalias qf
*四、绝对相对路径*
①df -Th 查看磁盘使用率的大小
绝对路径:以“/”开始的路径。例如:/root/home
相对路径:不以“/”开始的路径。例如:./xixi/a.Txt
. 表示当前用户的工作目录
..表示用户工作目录的上一级目录。图片如下:
创建文件
一、cd切换命令
①cd 直接回到家目录
②cd ..-----返回上一级目录
③cd - -------返回上一级待过的目录,再次使用,两个目录间来回切换
*二、快捷键:*
①ctrl + a -----移动到命令行首
②ctrl + e-----移动到命令行尾
③ctrl + u-----从光标处往左删除到行首
④ctrl + k -----从光标处往右删除到行尾
⑤Which 命令------查看该命令在bin或sbin那个位置
例如:which ls。查看ls命令在哪个位置
⑥mkdir -p 跳级创建目录
例如:mkdir -p /root/111/222。在root中没有111目录文件,-p可以先创建111文件然后再在111目录文件中创建222目录文件。
mkdir -v 查看创建目录文件的详细信息
⑦Echo “ 内容” > 文件路径
讲内容写到该文件路径的文档中
例如:echo “wocao” > /root/123。在root中123显示输入的wocao。
Echo “ 内容” > > 文件路径
将内容加到文件目录中,和之前的内容一起展现出来。
例如:echo “杨欣龙” > /root/123。
通过cat 文件路径 查看/root/123文件的内容为“wocao杨欣龙”。
按住ESC + . 复制上一个命令的最后一部分,以分隔符隔开。
⑧cat:查看文件的内容(存储的文字)信息【一般针对普通文件使用】。16
vi和vim
一、cp 复制命令
cp /目录文件地址/地址 /复制到文件地址/地址
cp -r /目录文件地址/地址 /目录文件地址/地址 /目录文件地址/地址 目的文件地址 前面都是源文件地址,前面的文件都复制到目的文件地址。
mv 剪贴命令(移动) 将源文件地址移到目的文件地址
例如 : mv /源文件地址 /目的文件地址
Mv /源文件地址/名字 /源文件地址/新名字,
二、Vim vim有三个模式。命令模式。编辑模式 。行尾模式。
命令模式:通过i键转到“编辑模式”,
编辑模式:通过ESC返回“命令模式”
尾行模式:通过“命令模式”中的“:”进入。按住enter键返回命令模式。
可视化模式:按住v进入可视化模式
①命令模式的操作命令
yy复制光标所在的一行
3yy复制包含光标下的3行
gg光标移动到这页面第一行行首位置
G光标移动到这页面最后一行的行首位置
p光标所在行的下一行粘贴
P光标所在行的上一行粘贴
6p在光标的下一行粘贴六次
dgg删除光标上方所有内容,包含光标所在行
dG删除光标下方的所有内容,包含光标所在行
dd删除光标所在的行
50gg或者50G把光标移东到50行的行首位置
D^删除光标左面的所有字符
d$删除光标右面的所有字符 包含光标所在字符
②编辑模式的操作命令
小写a进入编辑模式,光标向后移动一个字符
大写A进入编辑模式,光标直接移动到行的尾部进行编辑
小写o进入编辑模式,光标移动到所在行的下一行空白进行编辑
大写O进入编辑模式,光标移动到所在行的上一行空白进行编辑
③尾行模式操作命令
set nu给内容设置行序;set nonu 取消内容的行序
%S/匹配(查找的)/(替换)/ig
i不区分大小写, g表示所在整行都进行替换,没有g表示只替换这一行的第一个要替换的内容 %全部行都替换
1,3S/匹配(查找的)/(替换)/ig表示1到3行的相关内容替换。
:10 #进入第10行
:w #保存
:q #退出
:wq #保存并退出
:q! #不保存并退出
④可视化模式的编辑命令:
①从命令模式按一下v进入可视化模式。选中光标所在字符,往下移动光标,选中上一行,以及到光标的所有字符
②从命令模式按一下大写v进入可视行模式。选中光标所在的整行,往下移动,一行一行的选中
③按住Ctrl+v进入可视快模式,选中光标所在字符,向左移动光标,向下,选中上面光标所选中的字符。
查找
Cat -n 显示行号
A 包括控制字符(换行符/制表符)
Head 默认查看文件的前十行
Tail 模式查看文件的后十行
Less
More
组和用户的增删改查
一、组管理的增删改查
groupadd 组名--------添加一个组
groupadd -g 组id号 组名---------添加一个组,并为此组设置组id号
groupmod -g 新的组id 旧组名-------将之前的组id更改为新的组id
groupmod -n 新组名 旧组名-------将之前的组名更改为新的组名
groupdel 组名字--------删除组
查看组的文件 cat /etc/group
二、用户管理的增删改查
echo 密码 | passwd --stdin 用户名 修改用户密码
useradd 用户名------添加用户
useradd -r 用户名------添加系统用户
useradd -M 用户名------ 添加用户,但 不创建用户的主目录
useradd -g 组名 用户名------给新添加的用户强制设定一个主组
useradd -G组名 用户名------给新添加的用户强制设定一个附属组
useradd -u 用户id 用户名------给新添加的用户设定一个特定的用户id
usermod -u 新uid号 用户名-------对用户的id号进行修改
usermod -l 新用户名 旧用户名-------对用户的名字进行修改
usermod -g 组名或者组id 旧用户名-------对用户的主组进行强制修改
usermod -G 组名或者组id 旧用户名-------对用户的附属组进行强制修改 覆盖之前的附属组
usermod 用户名 -s 后面跟shell命令:如下
①/bin/bash 或者 /bin/sh 表示该用户可以进行登录
②/sbin/nologin 表示该用户不可以进行登录
userdel -r 用户名------ 删除用户
三、gpasswd添加附属组
gpasswd -a 用户名 组名(附属组) 将用户添加到这个组里面,并且这个组是该用户的附属组。
gpasswd -M 用户名,用户名........用户名 组名(附属组) 将多个用户添加到这个附属组里,并且这个添加,会覆盖之前已经添加过的用户
gpasswd -d 用户名 组名(附属组) 将用户从这个组当中删掉
组和用户的权限
一、ugo权限
r------>4 w------->2 x------->1
只读 写 执行
chmod:对文件的权限(UGO)进行更改。 也可以用数字来代替如:777 :rwxrwxrwx
chmod u+x 文件 对文件的u权限进行修改 755 :rwxr-xr-x
chmod g+x,o+x 对文件go权限进行修改。
chmod a=rwx 将文件的ugo权限都设置成rwx
-R 对文件修改UGO权限也有递归效果。
chown:拥有者.所属组 文件路径**。修改文件的拥有者和所属组。
例如:chown yxl.root file1 将文件的拥有者和所属组改为yxl和root。
-R 递归修改,如果把文件夹的拥有者和所属组改掉,则文件里面包含的文件拥有者和所属组也会改掉。
二、rwx对于目录的影响**
1、r相当于用户是否有ls查看目录内容的权限。r ---ls
【注意】当用户只有r没有x权限时,我们可以查看到文件名,但是无法详细查看文件属性。
2、w相当于用户是否可以使用touch、mkdir、*rm等命令创建文件、删除文件、修改文件。w -----touch、rm
3、x相当于用户是否可以使用cd命令进入目录内部 。x ---- cd
【注意】当需要对一个A目录内的文件进行增、删、改,则需要对该用户对A目录是否有w权限,其中w权限需要配合x权限才有效果。
三、rwx对普通文件的影响
1、r相当于用户是否有cat、grep查看文件内容的权限。r----cat
2、w相当于用户是否有 echo “内容” >> 文件路径 向文件内增加内容。w ---vi、vim
3、x用户是否有权限将该文件内的每行内容当做命令来执行
【注意】如果只有x权限,没有r权限,则无法执行文件。x ---- bash /dir/file
四、高级权限
1、对命令的提权(suid)
chmod 4777
chmod u+s 命令的绝对路径 。对该命令进行提权,其他用户使用该命令时,和root一样。但是这样所有用户可以使用。
2、组继承(sgid)
chmod 2770
chmod g+s 文件的绝对路径。如果一个目录的所属组是root,则在里面创建的所有文件都继承目录文件的所属组root。
3、T权限命令(sticky)
chmod 1770
chmod o+t 文件的绝对的路径 。一个目录文件内,有两个用户,tom、jack 都可以在该文件内进行增删改查,如果加T权限,不能对不是自己的文件进行删除,两个人不可以互相删除。
4、sudo:有针对性,例如针对某个用户以能够以root的身份执行某些命令。
visudo 按住‘’:’‘号进入尾行模式,然后找到100行,进行命令的编写。
例如:root ALL =(ALL) ALL
yxl ALL =(ALL) NOPASSWD:ALL 或者 YXL ALL =(ALL) NOPASSWD:: 。
如果yxl用户想以root身份来执行某些命令。前面必须加sudo 后面跟命令
例如:sudo rm -rf /root/1.txt
五、文件属性的扩展属性
chattr +i 不允许做任何操作, 但是可以cp
chattr +a不允许修改 ,只允许追加
chattr +A 锁定访问时间,可以进行所有操作,访问时间不变
lsattr 查看文件的隐藏属性
源码安装 rpm和yum源
一、软件管理
1、rpm
①wget 文件下载地址
#wget 下载地址 -O 指定存放路径
#curl 下载地址 -o 另存为的文件路径
例如: wget http://mirror.centos.org/centos/7/os/x86_64/Packages/unzip-6.0-21.el7.x86_64.rpm
②rpm - ivh 安装文件
③rpm -e 删除下载过的软件。
例如: rpm -ivh unzip-6.0-21.el7.x86_64.rpm #本地安装rpm包
④rpm -qa 查询此电脑安装的所有软件安装包
-ql 找这个安装包下面的所有安装文件(找儿子)
-qf 通过文件找这个文件的安装来源 (找爹)
⑤rpm -qa | wc -l 查询中软件总安装数,并显示总量。
2、yum

二、yum操作命令
yum clean all ------------------> 清理yum缓存
yum makecache -------------> 缓存软件包信息
yum repolist ------------------>查询yum源信息
yum provides 命令 ----------> 查询命令属于哪个软件下载的
yum -y install 软件名称 ----> 安装软件
yum -y remove 软件名称---> 卸载软件
yum -y reinstall 软件名称 --->重装软件
配置阿里云yum源
1、
阿里yum源地址页面 https://developer.aliyun.com/mirror/centos?spm=a2c6h.13651102.0.0.3e221b11WaK1yM
安装主yum源 [root@linux-server ~]# cd /etc/yum.repo.d [root@linux-server yum.repos.d]# mkdir back [root@linux-server yum.repos.d]# mv *.repo back [root@linux-server yum.repos.d]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo #下载aliyun的yum源 参数解释 curl -o 指定存放路径 或者 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
安装扩展源--epel.repo
[root@linux-server ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo [root@linux-server ~]# cd /etc/yum.repos.d/ [root@linux-server yum.repos.d]# ls CentOS-Base.repo epel.repo
三、通过镜像制作本地yum源
1、在根下面一个目录文件里创建一个目录(家目录除外)。操作:mkdir /mnt/1
2、将镜像centos7的镜像文件拖到root目录下
3、将镜像挂载到刚刚创建的目录下。mount 挂载设备 挂载点 。 操作:mount /root/centos /mnt/1
4、切换到 /etc/yum.repos.d/ 目录下 。操作: cd /etc/yum.repos.d/
5、将该文件下的与所有.repo文件放到一个新的文件夹里。操作:mkdir back 操作: mv *.repo back
6、在该目录下创建一个本地的以repo结尾的文件 操作:vim b endi.repo
7、在bendi.repo进入编辑模式写入:
[QF2401]---------------------------------->源标签
name= 本地仓库------------------------ >名称,英文中文都可以
baseurl=file:///root/1------------------> file:// 后面跟镜像仓库的绝对路径(第一步创建的目录)
gpgcheck=0------------------------------->检查软件的哈希值 正规不正规
8、通过yum clean all && yum makecache 进行清理缓存和建立缓存
9、通过yum repolist 查询yum源信息。
四、制作本地缓存yum源
1、看看是否有createrepo命令 ,如果没有则需要进行安装。yum -y install createrepo
2、用vim打开 /etc/yum.conf,将里面的keepcache=0修改下面参数的值为1,软件会被保存到cachedir指定的目录下。例如vim /etc/yum.conf
3、创建目录mkdir /root/2
4、安装httpd命令,软件包会自动保存到 /var/cache/yum下面 。操作:yum -y install httpd
5、找到安装httpd的文件将文件移动到创建的目录中 例如:find /var/cache/yum -name "*.rpm" | xargs -i mv {} /root/2
6、查看该文件是否有rpm结尾的文件,并在此文件中创造一个repodata 文件 ,声明当前目录是yum仓库 操作:createrepo /root/2
7、切换到 cd /etc/yum.repos.d/ 目录下
8、将该文件下的与所有.repo文件放到一个新的文件夹里操作:mkdir back 操作:mv *.repo back
9、在该目录下创建一个本地的以repo结尾的文件 vim huancun.repo
10、在huancun.repo进入编辑模式写入:
[QF2401]---------------------------------->源标签
name= 本地仓库------------------------ >名称,英文中文都可以
baseurl=file:///root/2------------------> file:// 后面跟镜像仓库的绝对路径(第一步创建的目录)
gpgcheck=0------------------------------->检查软件 正规不正规
11、通过yum clean all 进行清理缓存
12、通过yum repolist 查询yum源信息。
三、源码安装Nginx 无法被linux系统直接识别。需要编译为二进制文件。
1、下载编辑环境gcc make。 yum -y install gcc make zlib-devel pcre pcre-devel openssl-devel
2、下载安装包 wget http://nginx.org/download/nginx-1.16.1.tar.gz
3、解压安装包 tar xzf nginx-1.16.1.tar.gz xvf显示解压文件
3、配置
很重要:cd nginx-1.16.1下面三步都要在该目录下
①配置 ./configure --user=www --group=www --prefix=/usr/local/nginx
②编译 make
③编译安装 make install
4、创建用户 useradd -r -M -s /sbin /nologin www
-r 该用户为系统用户
-M 不创建用户的主目录
-s shell命令,不能登录
5、启动nginx /usr/local/nginx/sbin/nginx
6、#关闭防火墙 systemctl stop firewalld #关闭防火墙
7、关闭nginx /usr/local/nginx/sbin/nginx -s stop
8、在浏览器输入自己电脑的ip确定自己是否打开或者关闭nginx
四、二进制包
界于rpm与源码包之间的一种安装方式。 安装速度快,安装位置比yum和rpm明确。
管道重定向
一、输出重定向
① 1> 标准正确
例如 :ls /home/ /aaaaaaaaa >list.txt
② 2 > 标准错误
例如:ls /home/ /aaaaaaaaa >list.txt 2>error.txt #重定向到不同的位置
③ > 覆盖
例如: date 1> date.txt
④ >> 追加
例如:date >> date.txt
⑤ &>正确和错误的都输入到一个地方
例如: ls /home/ /aaaaaaaaa &>list.txt #混合输出到相同文件
⑥、/dev/null 将正确与错误的输出丢掉
例如: ls /home/ /aaaaaaaaa &>/dev/null #空设备,将正确与错误的输出丢掉
二、输入重定向
语法:cat > file5 <<EOF #可以写到脚本或者文件里面 EOF:开始和结束的标记。 成对使用 结尾的另一个必须定格写。
例如:
一道题 请用输入重定向将123456写入a.txt文件中。
1、cat > a.txt <<eof
123456
eof
2、vim a cat > a.txt << EOF 123456 EOF chmod a+x a ./a
三、管道 | 参数传递:xargs
🎈管道左边的命令执行的结果作为参数,反正管道右边的后面,执行右边的命令
例如: ls /etc |grep 'sys' #查询目录内符合要求的文件
①ls cp rm 不能执行管道 ,所以通过xargs
{}:前面传过来的内容 -i :为了让大括号生效
cat 文件 | xargs -i rm -rf {}
cat 文件 | xargs -i ls {}
cat a.txt | xargs -i cp -r {} /目录
四、sort按照uid排序
sort -t":" -k3 -n /etc/passwd #以: 分隔,将第三列按字数升序
sort 排序,默认升序 -t 指定分隔符 -k 指定列 -n 按数值 -r 降序 head 默认输出前十行 tail 默认输出后十行
进程管理
一、查看进程
ps aux -------> ps -ef
lsof -i :端口号
top 查看动态进程
ps aux | grep 进程名称 查看某个进程的相关信息
netstat -tanlp | grep 进程名称---------------->查看进程的相关信息,还可以查看有没有当前进程。
yum -y install net-tools
二、进程控制 杀死进程kill
kill 信号 PID
pkill 信号 进程名称
-1 重新加载的进程的配置, 但进程的PID不变 。 类似于不停机更新
-9 强制杀死进程
-15 正常杀死进程, 有一定的缓存时间。(可以默认不写)
-18 重启进程
-19 挂载(暂停)进程
三、作业控制
jobs ------------------------------->查看后台的工作号
fg %1 ------------------------------->将后台的程序调到前台
bg %2 ----------------------------------->让暂停的程序在后台运
sleep 7000 & ------------------------------>&:让命令或者程序在后台运行
ctrl+z ---------------------------------------> 把程序放到后台(这方法会让程序在后台暂停)
kill -9 %2 ------------------------------------------>通过kill杀死进程
四、常用命令
查看当前CPU负载 ---------------------------------> uptime
查看内存使用-----------------------------------------> free -m
临时清理内存----------------------------------------> echo 3 > /proc/sys/vm/drop_caches
.查看系统的版本------------------------------------->cat /etc/redhat-release
看查正在运行的内核版本------------------------- >uname -a
查看内核版本------------------------------------------>uname -r
主机名,修改完之后断开与终端连接,然后在重新连接即可。
vim /etc/hostname 编辑中文的主机名字
hostnamectl set-hostname xxxx 数字或者英文的主机名字
隐藏文件扩展查看3月12号末尾知识。
日志
一、一次性调度执行at
查看是否有没有at命令
如果没有则 yum provides at 查看该命令的安装包
yum -y install at安装该文件
systemctl start atd 启动该服务
①at now + 时间 例如: at now + 2min 现在的时间往后推两分钟
②at>输入命令 例如: useradd tom
③at > ctrl +d结束
①vim 一个普通文件-------------------------------------->vim at.jobs
useradd u99 ②写各种命令 并保存退出 -----------------------------> useradd u00 touch /a.txt
③at 时间 < 文件的地址 ----------------------------------> at 20:33 < at.jobs 。表示在20:33分执行at.jobs内的命令
不加x执行权限:是因为at读取到了文件里的内容去替root吧他执行啦
例如:root手里一封信,root让at去解决,at读取完之后,把事情办啦
atq查看该用户的一次性计划
atrm 序号 删除该用户的一次性计划
@@@@【使用rpm包安装的服务都可以使用如下命令进行操作】
systemctl start 服务名-------------> 启动服务
systemctl stop 服务名-------------> 停止服务
systemctl status 服务名-------------> 查看服务状态
systemctl enable 服务名-------------> 开机自动启动服务
systemctl disable 服务名-------------> 取消开机自动启动服务
二、循环调度执行cron
分钟 小时 日 月 周
1* * * * *
0-59 0-23 1-31 1-12 0-7
*:----------> 每
*/5 :--------------->每隔5分钟
,: -----------> 不同的时间段 1,10 表示每小时的1分钟 ,10分钟执行该命令
-: -------------> 表示范围性
crontab -e 编辑当前用户的计划任务
crontab -l 列出当前用户的计划任务
crontab -r 删除当前用户所有的计划任务
crontab -r -l -e -u用户名 , 去管理其他用户的计划任务
三、crontab结合脚本创建日志问文件
① 创建一个普通文件,在普通文件中进行命令的编辑--------------->vim /root/1.sh
【注意】:命令必须要写绝对路径
②编辑创建文件的UGO权限 ---------------------------------> chmod a+x /root/1.sh
③crontab -e 进行日志的编辑
④* * * * * 脚本的绝对路径① ------------------------> * * * * * /root/1.sh
日志轮转
一、【什么时候一个日志才会被切割】
1、logrotate命令被执行 logrotate /etc/logrotate.conf
-f 强制轮换
2、该日志符合切割标准 min 两个都得满足才可以切割 时间 大小
max 两者满足一个就可以切割 时间 大小
二,对日志轮转进行编辑
vim /etc/logrotate.conf
weekly #轮转的周期,一周轮转,单位有年,月,日 rotate 4 #保留4份 create #轮转后创建新文件 dateext #使用日期作为后缀
include /etc/logrotate.d #包含该目录下的配置文件,会引用该目录下面配置的文件
crontab -e 设置循环调度日志
logrotate /etc/logrotate.conf 一般情况设置为 03*** /usr/sbin/logrotate /etc/logrotate.conf
logrotate /etc/logrotate.d/yum 对某一个日志进行切割
三、ssh链接:
yum -y install openssh*
systemctl start sshd
关闭防火墙
vim /etc/ssh/sshd_config 修改端口密码
①ssh root@对方机器IP地址 -p 端口号,
需要输入对方机器的密码
②ssh-keygen 一直回车 下载自己电脑的秘钥(公钥和私钥)
③ssh-copy-id 对方IP地址 将自己的公钥传给对方机器
④ssh 对方IP地址,不需要密码,直接连接对方电脑成功
四、上传下载
scp -r 本机文件的详细地址 对方机器的ip地址 :文件要存储目录的位置
scp -r 对方机器的ip地址 :文件路径 本机存储文件的地址。
五、常用命令
ping -c 3 www.baidu.com 查看该主机是否联网 -c:指定次数
六、Telnet和ssh的区别
telnet:①不安全,没有对传输数据进行加密,容易被监听,还有遭受中间人攻击,
②telnet不能压缩传输数据,所以传输慢
③不能以root身份直接登录,中间需要过度。 ssh:对数据进行了加密,安全度高,ssh传输数据经过压缩,所以传输速度比较快
文件查找和压缩 链接文件
一、查找
find 范围 (目录) 选项 参数
-perm 权限
-name ”文件名“
-size ±文件大小
-type 文件类型(f 、d、b、l)
-atime 单位:天(+代表几天之前)
-ctime 单位:天(-代表几天之内)
-mtime 单位:天
-amin 单位:分钟
-cmin 单位:分钟
-mmin 单位:分钟
grep 查找文件中的文字 find -atime 按照文件访问时间查找文件(以天为单位) find -mtime按照文件更改时间查找文件(以天为单位) find -ctime 按照文件改动时间查找文件(以天为单位) find -amin 按照文件访问时间查找文件(以分钟为单位) find -mmin按照文件更改时间查找文件(以分钟为单位) find -cmin 按照文件改动时间查找文件(以分钟为单位)
-a and和的意思
-o 或者的意思
二、打包和压缩
①打包 :
tar cf 打包后的文件路径 被打包的文件路径
②解包:
tar xf 打包的文件 -C 指定解包路径
③打包压缩一起
tar cvzf file.tar.gz 源文件 tar cvjf file.tar.bz2 源文件 z:表示gz压缩 j:表示bz2压缩
④解压包语法: tar xvzf 压缩文件 [-C 解压路径] tar xvjf 压缩文件 [-C 解压路径]
三、链接
数据一直在bolck块中存放,硬软连接丢失,数据不会丢失
ls -i 查看文件的inode号码
语法: 已知存在一个文件,A.txt
ln A.txt B.txt B是A的硬链接
ln -s /A.txt C.txt C是A的软连接 。 这里A文件必须是绝对路径
硬链接: ①硬链接的 indoe号一模一样
②给A文件写入东西在B文件也可以查看
③删除任意一个A、B文件数据不会丢失
软连接:①软链接的indoe号不一样 A和C不一样
②删除软连接C A 文件可以正常查看数据,数据不会丢失
③ 如果删除A文件,则C文件,软连接失效。
磁盘
一、磁盘分为三步 例如新磁盘是/dev/sdb
1、给磁盘分区
①fidsk /dev/sdb 进行分区
②输入n创建磁盘分区 ,回车
③选择p或者e ( p:为主分区 e:为扩展分区 l:逻辑分区)【只有创建了扩展分区才可以进行逻辑分区】,回车
④选择(1-4)设置分区号随机挑选
⑤起始 扇区:开始处直接回车
⑥给分区设置大小 例如:+1G
⑦ w保存 ,q退出 d 删除分区
2、格式化(安装文件系统): mkfs.ext4 /dev/sdb1 或者 mkfs.xfs /dev/sdb1
3、挂载 mount 挂载设备 挂载点。
① 要先创建一个目录为挂载点:mkdir /root/A
②mount /dev/sdb1 /root/A
4、完成
【扩展】:
lsblk 查看的是有没有被挂载的磁盘
blkid 查看设备的UUID号以及文件系统类型
df -Th :查看系统中挂载设备的情况 查看磁盘使用率的情况
free - m 查看内存使用
二、开机自动挂载:
① 打开 vim /etc/fstab
挂载设备 挂载点 文件系统 文件系统参数配置 备份:0关闭 1开启 检测:0关闭 1开启
/dev/sdb1 /root/A ext4 defaultsa 0 0
②打开 vim /etc/rc.d/rc.local
写入mount /dev/sdb1 /root/A
然后chmod a+x /etc/rc.d/rc.local 对文件进行UGO权限设置
LVM逻辑卷和raid磁盘阵列
一、创建lVM逻辑卷并挂载使用
①对一个磁盘进行分区------------------------> fdisk /dev/sdb sdb1
②声明/dev/sdb1物理卷。-------------------->pvcreate /dev/sdb1
③创建vg卷组并给卷组命名。 ---------------->vgcreate vg1 /dev/sdb1
【注意】:-s 指的是在分区的时候指定PE的大小。
④创建lv逻辑卷。---------------------------------->lvcreate -L +5G -n lv1 vg1
【注意】 -l 后面跟的是PE值
-L 跟内存大小(M、G)
-n 给lv逻辑卷命名
⑤格式化(声明文件系统)-------------------------> mkfs.xfs /dev/vg1/lv1
⑥挂载 ---------------------------------------------------> mkdir /root/lv1 mount /dev/vg1/lv1 /root/lv1
二、lvm逻辑卷扩容
存在一个/dev/sdc磁盘 ,磁盘大小为10G
①声明/dev/sdc为物理卷。 -----------------------> pvcreate /dev/sdc
②vg卷组扩容------------------------------------------->vgextend vg1 /dev/sdbc
③lv逻辑卷扩容------------------------------------------>lvgextend -L +5G /dev/vg1/lv1
【注意】:(小)l或者L后面跟PE值或者大小(M、G) 没有+号是扩容到5G 有+号是在原有的基础上在增加5G
④xfs扩容:----------------------------------------------->xfs_gorwfs /dev/vg1/lv1
ext4扩容:-----------------------
----------------------->resize2fs /dev/vg1/lv1
补充:
| pvs | vgs | lvs | vgdisplay+卷组名 |
|---|---|---|---|
| 查看物理卷信息 | 查看卷组信息 | 查看逻辑卷信息 | 查看这个卷组还有多少内存或者(PE值) |
三、lvm移除扩展
移除lv逻辑卷 lvremore lv绝对路径---------------------->lvremore /dev/vg1/lv1
移除vg卷组 vgremore vg的绝对路径---------------------->vgremore /dev/vg1
移除pv物理卷 pvmore pv的绝对路径---------------------->pvremore /dev/sdb
四、swap交换区 分为两种:LVM和file
LVM从磁盘中扩容
1、分区
①从一个磁盘分一个主分区 fdisk /dev/sdb 得到sdb1
②partprobe /dev/sdb 刷新磁盘
2、初始化:mkswap /dev/sdb1 通过blkid 查看它的类型
3、制作开机自动挂载
① 打开 vim /etc/fstab
② 进行编辑 /dev/sdb1 swap swap defaults 0 0
4、swapon -a 激活swap分区(读取/etc/fstab)
swapon -s 查看交换分区信息
swapoff /dev/sdd1 关闭swap分区
file在根下面通过创建文件对swap进行扩容
1、dd if=/dev/zero of=/swap1 bs=1M count=1024 bs显示快的大小 count显示块的数量
2、初始化 mkswap /swap1
3、制作开机自动挂载
①打开 vim /etc/fstab
②进行编辑 /swap1 swap swap defaults 0 0
4、swapon -a 激活swap分区 。这个时候 已经成功可以使用啦, 但是会提醒你让你修改权限,0644改为0600
5、一般会在第三步结束的时候添加 chmod 0600 /swap1
6、完成
五、mount挂载类型
-o 指定文件系统属性 rw 读写 ro 只读 noexec 不允许执行二进制文件 exec 允许执行二进制文件 auto mount -a 开机自动挂载 remount 在线重新挂载
六、raid磁盘阵列 🤡1、raid0-----数据条带卷
磁盘数量:最少两块磁盘。
作用:最少需要两块磁盘,分别往每一块磁盘上写一部分数据。
优点:①读写速度快。②磁盘利用率:100%
缺点:不提供数据冗余,无数据检验,不能保证数据的正确性,存在单点故障。
应用场景:① 对数据完整性要求不高的场景,如:日志储存,个人娱乐
② 要求读写效率高,安全性能要求不高,如:图像工作站
🤡2、raid1又叫镜像raid
磁盘数量:一般需要两个磁盘
作用:每块磁盘上都会储存一份完整的数据。这俩磁盘成为互为备份的数据磁盘,但是磁盘空间利用率是比较低的
优点:提供数据冗余,数据双倍存储安全性高支持容错。读取速度快
缺点:写速度慢,无数据校验。磁盘利用率不高
磁盘利用率:50%
应用场景:存放重要数据,如数据存储领域
🤡3、raid5:RAID是最常见的等级。
磁盘:最少需要3块磁盘。
作用:它的校验分布在阵列中所有的磁盘上。同时存储数据和 校验数据。当一个磁盘损坏时,系统可以根据 数据块和对应的校验数 据来重建损坏的数据。
优点:①可以找回丢失的数据---数据可以通过校验计算得出。
②冗余磁盘------->(需要4块磁盘将其中一块做热备)当某一块磁盘坏掉后,冗余磁盘会自动替换上去。
③有校验机制
④读写效率高
⑤磁盘利用率高
缺点:磁盘越多安全性越差
应用场景:安全性高,如金融,数据库,存储等。
🤡4、raid6:在raid5的基础上为了进一步增强数据保护而设计的一种raid磁盘
磁盘数量:最少需要四块磁盘。
作用:它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。
优点:①容错:允许两块磁盘同时坏掉。读写快
②良好的随机读性能。
③有校验机制
缺点:①写入速度差
②成本高
应用场景:对数据安全级别要求比较高的企业
🤡5、raid10:先做镜像再做条带----也叫混合raid
优点:①有较高的IO 性能
②有数据冗余
③无单点故障
④安全性能高
缺点:成本高
应用场景:特别适用于既有大量数据需要存取,同时又对数据安全性要求严格的领域,如银行,金融,商业超市,仓储库房,各种档案管理等。
构建NFS远程共享存储和FTP
一、构建NFS远程共享存储
服务端和客户端都关闭防火墙
😒systemctl stop firewalld
😒systemctl disable firewalld
😒setenforce 0
❤️服务端:
1、安装nfs和rpc服务-----------------------> yum -y install nfs-utils rpcbind
2、启动服务---------------------------> systemctl start nfs rpcbind
3、创建存储目录
①直接在根下面创建一个存储目录,mkdir /nfs
②通过给磁盘分区、格式化、挂载 制作存储目录
4、编辑共享文件打开 -------------------->vim /etc/exports
共享目录 对方ip(rw,no_root_squash,sync)
/nfs 192.168.107.140(rw,no_root_squash,sync)
5、重启服务 ----------------------------------->systemctl restart nfs-server
6、确认nfs开启成功 -------------------------> exportfs -v
7、服务端部署完成
❤️客户端
1、安装nfs和rpc服务-----------------------> yum -y install nfs-utils rpcbind
2、启动服务---------------------------> systemctl start nfs rpcbind
3、创建挂载点-----------------------> mkdir /my_nfs
4、挂载-------------------------------->mount -t nfs 192.168.107.136:/nfs /my_nfs
5、df -Th 查看挂载情况
7、完成
二、FTP文件共享配置
主动:
客户端随机开放一个≥1024的端口,链接服务的21号端口, 并向服务传递我已经打开了n+1号端口,请链接我传输数据。 服务通过20号端口给客户端传输数据
被动:
客户端开放两个一个端口(1024)通过连接服务端的21号端口建立通信,并请求服务端打开一个端口,客户端主动去连接服务端进行数据的传输。
❤️服务端
1、安装vsftpd服务------------------------->yum -y install vsftpd
2、启动服务----------------------------------> systemctl start vsftpd
3、进行文件的配置:
①chown ftp.ftp /var/ftp/pub
②打开vim /etc
/vsftpd/vsftpd.conf
③编辑:anon_umask=000 匿名用户所上传文件的权限掩码 anon_upload_enable=YES 允许匿名用户上传文件 anon_mkdir_write_enable=YES 允许匿名用户创建目录 anon_other_write_enable=YES 是否允许匿名用户有其他写入权(改名,删除,覆盖)
4、重启服务----------------------------------->systemctl restart vsftpd
5、服务端配置完成
❤️客户端
1、安装lftp服务 ------------------------------->yum -y install lftp
2、启动-------------------------------------------->lftp systemctl start lftp
3、lftp 192.168.107.136 链接服务端进行上传下载功能
4、cd pub切换到该目录进行上传下载的操作
或者
1、创建用户,通过lftp 192.168.107.136 -u 用户名进行登录
2、下载的东西会到该用户的家目录。
三、系统优化检测常用命令
1、查看平均负载 uptime
2、释放buffer和cache echo 3 > /proc/sys/vm/drop_caches
3、 带宽使用情况 yum install -y iftop.x86_64 命令iftop
4、网络接口统计报告 yum install -y nethogs.x86_64 命令nethogs
web服务器
一、Apache服务安装
🎈服务一定要关闭防火墙🎈
1、安装httpd服务yum -y install httpd
2、启动systemctl start httpd
3、查看启动状态systemctl restart httpd
二、Apache工作目录详细:
vim /etc/httpd/cond/httpd.conf
listen 80-------------------->端口号
ServerRoot "/etc/httpd"------------------------------->工作目录
Listen 80---------------------------------------------------->监听端口
ServerAdmin root@localhost ---------------------->设置管理员邮件地址
DocumentRoot "/var/www/html" ----------------->网站的主目录文件在这个目录下
Options Indexes FollowSymLinks------------------->找不到index.html主页时,以目录的方式呈现,并允许链网站根目录以外
AllowOverride None-------------------------------------->不添加任何属性
DirectoryIndex index.html-------------------------------->自定义修改index.html的名字
允许所有人访问:granted表示运行所有访问,denied表示拒绝所有访问
只拒绝一部分客户端访问:
不允许任何人访问,除了制定的ip可以访问外:
三、虚拟主机 :1、基于域名 2、基于ip 3、基于端口
1、基于域名:其他ip和端口保持一致
2、基于ip:域名和端口保持一致
增加ip: ip a a 新的ip/24 dev ens33
取消新添加的ip地址:ip a d IP地址/24 dev ens33
3、基于端口:域名和ip保持一致
大致如下:
①创建一个配置文件vim /etc/httpd/conf.d/1.conf进行编辑
<VirtualHost 192.168.107.136:80> DocumentRoot /yxl ServerName www.yxl.com <Directory "/yxl/"> AllowOverride None Require all granted </Directory> </VirtualHost>
② 在根目录下面创建yxl ----------------------->mkdir /yxl
③ echo “杨新龙” >> /yxl/index.html
④进行域名和ip的配置 vim /etc/hosts
192.168.107.136 www.yxl.com
⑤重启服务 systemctl restart httpd
⑥ curl www.yxl.com完成
四、nginx
nginx的配置文件
nginx主配置文件 /etc/nginx/nginx.conf nginx虚拟主机配置文件 vim /etc/nginx/conf.d/default.conf server { listen 80; #监听的端口 server_name localhost; #设置域名或主机名
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main; #日志存放路径
location / { #请求级别:匹配请求路径
root /usr/share/nginx/html; #默认网站发布目录类似httpd服务客户端请求时 调用的页面
index index.html index.htm; #默认打开的网站主页
}
计算机网络
osi :物理层 、数据链路层、网络层、传输层、表示层、会话层、应用层
tcp/ip: 物理层、数据链路层、网络层、传输层、应用层
一、端口号:
1-65535 http---80 https--443 telnet--23 ftp--21、20 ssh--22 mysql--3306 php--9000 tomcat---8080
二、TCP三次握手和四次挥手
1.TCP的传输过程:
Seq 序列号 保障传输过程可靠。 ACK (确认消息) SYN (在建立TCP连接的时候使用) FIN (在关闭TCP连接的时候使用)
3.TCP建立连接的过程:
三次握手
1.)发送端首先发送一个带有SYN(synchronize)标志地数据包给接收方。 2)接收方接收后,回传一个带有SYN/ACK标志的数据包传递确认信息,表示我收到了。 3)最后,发送方再回传一个带有ACK标志的数据包,代表我知道了,表示’握手‘结束。 =================================== 通俗的说法 1)Client:嘿,李四,是我,听到了吗? 2)Server:我听到了,你能听到我的吗? 3)Client:好的,我们互相都能听到对方的话,我们的通信可以开始了。
四次挥手
原理: 1)第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送。 2)第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1 3)第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送. 4)第四次挥手:Client收到FIN后,接着发送一个ACK给Server,确认序号为收到序号+1. ====================== 通俗的说法 1)Client:我所有东西都说完了 2)Server:我已经全部听到了,但是等等我,我还没说完 3)Server:好了,我已经说完了 4)Client:好的,那我们的通信结束
三、私有地址
在A类地址中,10.0.0.0到10.255.255.255是私有地址
在B类地址中,172.16.0.0到172.31.255.255是私有地址。
在C类地址中,192.168.0.0到192.168.255.255是私有地址。
四、ip分类
公网ip地址--->合法的IP地址,可以在互联网上访问
A类:0.0.0.0 - 127.255.255.255/8 0是保留的并且表示所有IP地址,而127也是保留的地址,并且是用于测试回环用的。127.0.0.1,通常被称为本地回环地址。 B类:128.0.0.0 - 191.255.255.255/16 C类:192.0.0.0 - 223.255.255.255/24 目前我们用的ip地址 D类:范围从224-239,D类IP地址目前这一类地址用来一次寻址一组计算机。224.0.0.0-239.255.255.255 组播地址 E类:范围从240-254,为将来使用保留。
全零(“0.0.0.0”)地址对应于当前主机。IP地址(“255.255.255.255”)是当前子网的广播地址。
五、子网掩码
【作业】 当前公司有一个IP所在的网络:49.234.237.88/24,需要进行子网划分: 1、运维部需要28个IP 2、开发部需要120个IP 3、人事部需要20个ip 4、销售部需要60个IP
请根据实际情况进行子网划分(需要考虑已经使用的子网空间不能再次使用)。
1、网络地址借了一位【1】
子网掩码:11111111.11111111.11111111.10000000
网络地址: 00110001.10011100.10011111.10000000 49.234.237.128/25
广播地址: 00110001.10011100.10011111.11111111 49.234.237.255/25
ip地址范围 49.234.237.129---49.234.237.254可以分为开发部需
2、 网络地址借了两位【01】
网络地址: 00110001.10011100.10011111.01000000 49.234.237.64/26
广播地址: 00110001.10011100.10011111.01111111 49.234.237.127/26
ip地址范围是49.234.237.65----49.234.237.126 适用于销售部
3、基础上继续进行子网划分网络地址借了三位【001】
网络地址: 00110001.10011100.10011111.00100000 49.234.237.32/27
广播地址: 00110001.10011100.10011111.00111111 49.234.237.63/27
ip地址范围是49.234.237.33----49.234.237.62人事部
4、继续进行子网划分网络地址借了三位【000】
网络地址: 00110001.10011100.10011111.00000000 49.234.237.0/27
广播地址: 00110001.10011100.10011111.00011111 49.234.237.31/27
ip地址范围是49.234.237.1----49.234.237.30 适用于运维部
固定ip
一、设置固定ip
①打开 vim /etc/sysconfig/network-scripts/ifcfg-ens33
②编辑 :BOORPROTO ="none"
IPADDR=新ip地址
GATEWAY=网关地址
PREFIX=24
DNS1=114.114.114.114
③完成
二、添加ip
添加临时ip:ip a a Ip地址 dev ens33
删除临时ip:ip a d IP地址 dev ens33
三、开启路由转发
(1)临时设置:echo 1 > /proc/sys/net/ipv4/ip_forward #默认是零,没有开路由。1表示开启
(2)永久设置:
①打开 vim /etc/sysctl.conf---添加如下内容 ②net.ipv4.ip_forward = 1
③sysctl -p #立即生效
四、配置本地解析
ls /etc/hosts :本地域名解析文件
ls /etc/resolv.conf :外网DNS配置文件
五、查看mac地址
arping -I ens33 ip地址
4月第二阶段
shell编程 细节的小东西
一、定义函数
echo $RANDOM 生成(0--65535)随机数
echo $((RANDOM% 100 + 1 )) 生成(1--100)的随机数
定义函数 :
函数名(){
函数体
}
将里面的函数体定义给函数名
调用函数:直接使用函数名进行调用。
二、环境变量和自定义变量
1、环境变量:可以影响到当前终端以及当前终端下的所有子终端【但是、不能向上传递】
自定义变量前+export 改变为环境变量
①/etc/profile 【存储变量的文件】
②/etc/profile.d/*.sh 【存储变量的子文件】
③/etc/bashrc 【存储别名】
④source /etc/profile 【加载配置文件】
④unset 变量名 【取消变量】
2、自定义变量: 只能影响当前shell终端,不能影响其他终端。
①~/.bash_profile 【用户存储变量的文件】
②~/.bashrc 【存储别名】
三、通配符
1、 * 匹配任意多个,任意字符
2、 {} 集合
3、 [] 占位符效果,匹配方括号[]内任意一个符号
例如:[abc]yxl -------> ayxl 、byxl、cyxl
4、 ? 占位符效果,匹配任意一个,任意字符
例如:?yxl ------------------>问号可以是任意一个字符
5、 ! 取反
例如:[!yxl]------------------->除却yxl中的任意一个字符
6、[a-Z] 他是先a A 、b、B ..............z 、Z 这样去展示的
四、六种执行脚本方法
在/root/1.sh存在一个脚本
① bash 1.sh
② sh 1.sh
③ /root/1.sh
④./1.sh
⑤source 1.sh
⑥ . 1.sh
五、变量的类型
1、$$ 当前终端的终端号
2、$? 命令执行后的返回状态:0为执行正确 ,非0为执行错误
3、$# 总共位置参数的数量
4、$* 把所有参数都一一列(显示)出来
5、$! 上一个后台进程的PID (wait命令中使用,后面讲)
六、变量的引用
1、完全引用(单引号):' ' 强引用 硬引。指的是被引号包围起来的变量名不会进行解析,原样变量名原样输出 。适合:定义显示纯字符串的情况,不希望解析变量、命令等的场景。
2、部分引用(双引号):"" 弱引用 软引 。指的是被引号包围起来的变量名会先进行解析,然后将变量的解析结果输出来。适合:字符串中附带有变量和命令并且想将其解析后再输出的变量定义。
3、取消屏幕显示
stty -echo 输入任何命令在终端都看不到
stty echo 回复正常
如果不换行,再下一行再执行一次echo然后进行下面的操作即可。
4、运算方式有三种
反引号和$()
(()) [] exper
5、定义(规定)字符长度 :

七、运算符比较大小
| 运算符 | 作用 |
|---|---|
| -eq | 等于 (=) |
| -ne | 不等于(!=) |
| -gt | 大于 (>) |
| -lt | 小于 (<) |
| -le | 小于等于 (≤) |
| -ge | 大于等于(≥) |
if,case,for ,while ,语句
一、if循环语句
if [判断条件]
then
执行命令
elif [判断条件]
then
执行命令
else
执行命令
fi
二、case循环
case $变量名 in
1)
执行命令
;;
2)
执行命令
;;
*)和if的else功能一样,
执行命令
esac
三、for循环语句
1、for模版
for i(变量名) in {取值范围}
do
循环体
done
i++ 先赋值再运算
++i 先运算再赋值
2、【注意】:将循环体用{}包裹起来 后面加&符号然后for循环外用wait和echo输出一句话例如:
for i in {}
{ 循环体
} &
done
wait
echo “已完成”
wait:等待上面命令后台执行结束后(即上一个的进程终止),在执行下面的echo命令
四、while循环语句
while :(:默认为真)
do
循环体
done
五、循环控制
1、shift 【使位置参数前移(跟下饺子一样,最前面的位置参数消失)】
2、continue 【在循环中不执行continue下面的代码,转而进入一下轮循环】 continue 跳出本次循环 下方代码全部不会执行 但是会重新循环
3、break 【退出整个循环,当出现循环嵌套,跳出距离自己最近的循环】
4、exit 【退出脚本】
六、&&和||
&&:逻辑与,前面执行成功,后面执行。前面命令执行失败,后面也不执行
|| :逻辑或,前面执行失败,后面才执行。前面命令执行成功,后面不执行
一真就真,
1、[ ]支持:
①[ 表达式1 - a 表达式2 ] 和 [ 表达式1] && [ 表达式2]
②[ 表达式1 - o 表达式2 ] 和 [ 表达式1] || [ 表达式2]
2、[[ ]]支持:
①[[ 表达式1 ]] && [[ 表达式2 ]] 和 [[ 表达式1 ]] || [[ 表达式2 ]]
3、[ ] 不支持:
①在调用字符串变量时要加"变量",不能用'变量'
4、[[ ]] 不支持:
①[[ 表达式1 -a 表达式2 ]] 和 [[ 表达式1 -o 表达式2 ]]
函数,数组,正则表达
一、函数
定义:函数名 (){
函数体
}
调用:在函数名前加$符号调用函数。
【注意】必须先定义,再调用。函数是一个特殊变量,本质是变量结构
取消变量 :unset 函数名
函数
二、数组
1、普通数组
①声明普通 declare -a 数组名【默认不声明,直接进行第二步】
②数组名 =([索引]=值 [索引]=值 [索引]=值 ............)
【注意】索引值 只能是数字从数字(0开始)
2、关联数组
①声明关联数组 -------------> declare -A 数组名
②给关联数组进行添加索引和值------------------> 数组名= ([索引]=值 [索引]=值 [索引]=值 ...............)
【注意】关联数组不可以用纯数字。
【注意】 覆盖 /添加 数组名[索引]=值
3、echo ${数组名[*]}------------------>列出数组当中的所有值
例如: echo ${yxl[*]}
echo ${#数组名[*]}-----------------> 数组当中总共有多少个值
例如: echo ${#yxl[*]}
echo ${!数组名[*]}-----------------> 列出数组当中的所有索引
例如 :echo ${!yxl[*]}
【注意】*和@一样都是查看数组中的全部信息
4、shell数组中“*”和“@”的区别
①echo “${数组名[*]}” -------------->把数组当中的所有值当成一个字符串处理
②echo "${数组名[@]}"---------------->依然还是当成数组进行操作
③*和@都不加“”------------------------->两人效果一样,都是列出数组中的所有项目
三、正则表达式
(1)grep -i 忽略大小写
一、基本正则表达式字符
| * | 在[]内表示取反,在[]外表示以什么开头 |
|---|---|
| ^ | 行首定位符 |
| $ | 行尾定位符 |
| . | 匹配任意单个字符 |
| * | 匹配 前导符0次----多次 *前面的第一个字符 |
| .* | 匹配任意多个字符和通配符*一样 |
| [ ] | 匹配括号中任意一个字符 |
| [ - ] | 匹配制定范围内的一个字符 |
| [ ^ ] | 匹配不在这个范围内的字符(和取反差不多) |
| \ | 转义字符 (无意义变有意义,有意义变无意义) |
| \ < | 词首定位符() |
| \ > | 词尾定位符 |
| \ ( \ ) | 匹配后的标签(进行分组标签)不影响原有匹配 。\1第一组最多分九组 |
二、正则表达式扩展元字符
| 字符 | 功能 |
|---|---|
| + | 匹配一次或多次前导符 |
| ? | 匹配0次或1次前导符 |
| a|b | 匹配a或者b |
| x{m} | 字符x重复m次 o{5}匹配出现5次0 |
| x{m,} | 字符x重复m次---无穷次 |
| x{m,n} | 字符x重复m次------n次 |
| () | 字符组 |
正则三剑客grep、sed、awk
一、grep三剑客
grep支持正则不支持扩展正则
egrep支持扩展
i :忽略大小写 -v:反向匹配,只输出不匹配的行 -w:只匹配整个单词,而不是单词的一部分 -n:在每行输出匹配的行号 -c:仅输出匹配的行数 -l:只输出包含匹配项的文件名 -r:递归搜索指定目录下的所有文件 -E:使用扩展正则表达式语法 -F:将模式视为固定字符串而不是正则表达式 -o 是一个非常有用的命令选项,用于在匹配文本中仅输出匹配的部分,而不是整个行或文件。 -A <num> 表示显示匹配行的后 num 行文本 -B <num> 表示显示匹配行的前 num 行文本 -C <num> 表示显示匹配行前后 num 行文本
^(\ <[a-z]+\ >).*\1$ 匹配开头单词与结尾单词一致的行
二、sed三剑客
使用基本元字符集 ^, $, ., *, [], [^], < >,() 使用扩展元字符集 ?, +, { }, |, ( )
1、 sed 搜索替换:s///ig
一次处理一行内容。直到这个文件的结束
sed -r “命令” 文件名
-n 代表静默输出 一般搭配(p)使用
-i 将内容从内存中覆盖到文件。
-e 可以执行多个命令,每个命令前都得加-e
-f 将命令写入脚本中,然后使用 - f 文件名 使用脚本中的命令
2、地址(定值)
d表示个删除行
'1d'------------>删除文件的第一行
'1,2d'------------>删除文件的1-2行
'2,$d'-------------->删除2行到最后一行
'1~2d'-------------->删除奇数行,
'0~2d'--------------->删除偶数行
3、sed流编辑器命令用法及解析
①插入命令-----i
例如:sed -r '2i\111111' -------------->在第二行插入111111
②修改命令-----c
例如:sed -r '4c\22222'----------------->将第四行的内容修改为22222
③由于在使用-i参数时比较危险,所以我们在使用i参数时在后面在.bck就回产生一个备份的文件,以防后悔。
例如:sed -r -i.bak 's/root/ROOT/' passwd
4、sed的常见操作
①sed -ri '/^#/d' ssh_config-------------------->删除配置文件中的#号注释行
②sed -r '2,5s/^/#/' passwd--------------------->给文件2行到5行添加注释
③sed -r 's/^/#/' passwd------------------------->给所有行添加注释
④ sed -ri s/^#baseurl/baseurl/g -------------取消注释
⑤ sed -r s/^mirrorlist/#mirrorlist/g ---------->添加注释
三、awk三剑客
1、awk简介和语法
awk处理过程:依次对每一行进行处理,然后输出,默认分隔符是空格或者tab键
语法:awk -F ":" '{print 1,3}' /etc/passwd
-F 对于每次处理的内容,可以指定一个自定义的输入字段分隔符,默认的分隔符是空白字符(空格或tab键)
2、awk工作原理
(1)使用一行作为输入,并将这一行赋给变量$0,每一行可称作为一个记录,以换行符结束。
(2)然后,行被空格分解成字段,每个字段存储在已编号的变量中,从$1开始。
3、记录字段相关内部变量
$0 : 表示整行
1第一个字段,2第二个字段,$3第三个字段......
FS : 输入字段分隔符
OFS : 输出字段分隔符
RS : 输入记录分隔符
ORS : 输出记录分隔符
NF : 统计字段的个数
$NF: 表示最后一列
NR : 打印记录号
FNR : 可以分开,按不同的文件打印行号
4、awk中使用if语句
①cat /etc/passwd | awk -F":" '{if($3==0) {print $1 " is administrator"}}'---------->显示管理员用户姓名
② cat /etc/passwd | awk -F":" '{if(3>=0 && 3<=1000){i++}} END{print i}'--------->统计用户数量
5、awk中使用for语句
awk '{for(i=1;i<=2;i++) {print $0}}' /etc/passwd------->每行打印两边
6、数组便利--用来统计网站日志的访问量
++i:从1开始加,运算在赋值
i++: 从0开始加,赋值在运算
#按索引遍历:
1.先创建一个test文件,统计用户的数量
# vim test.txt #将文件内容的第一个字段作为数组的值,通过索引获取到值
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
# cat test.txt | awk -F":" '{username[x++]=$1} END{for(i in username) {print i,username[i]}}'
0 root
1 bin
#注意:变量i是索引
7、真实案例
#把要统计的对象作为索引,最后对他们的值进行累加,累加出来的这个值就是你的统计数量
1. 统计/etc/passwd中各种类型shell的数量
# cat /etc/passwd | awk -F: '{shells[$NF]++} END{ for(i in shells){print i,shells[i]} }'
这里面i的值等于shell的类型 ,shells[i]是数字
2.统计nginx日志出现的状态码
# cat access.log | awk '{stat[$9]++} END{for(i in stat){print i,stat[i]}}'
3.统计当前nginx日志中每个ip访问的数量
# cat access.log | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}'
4.统计某一天的nginx日志中的不同ip的访问量
# cat access.log |grep '28/Sep/2019' | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}'
5.统计nginx日志中某一天访问最多的前10个ip
# cat access.log |grep '28/Sep/2019' | awk '{ips[$1]++} END{for(i in ips){print i,ips[i]}}' |sort -k2 -rn | head -n 10
sort:排序,默认升序
-k:指定列数
-r:降序
-n:以数值来排序
6.统计tcp连接的状态---下去自己查各个状态,包括什么原因造成的!
# netstat -n | awk '/^tcp/ {tcps[$NF]++} END {for(i in tcps) {print i, tcps[i]}}'
LAST_ACK 5 (正在等待处理的请求数)
SYN_RECV 30
ESTABLISHED 1597 (正常数据传输状态)
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057 (处理完毕,等待超时结束的请求数)
8、UV和PV统计
============
❤️PV:即访问量,也就是访问你上铺的次数。
今天显示300PV,则证明今天你的上铺被访问了300次
===========
❤️UV: 即访问人数,也就是有多少人来过你的商铺
今天显示50UV,则证明今天有50个人来过你的商铺
===========
四、shell编程-expect
1、先安装expect---------->yum -y install expect
2、expect的语法:
①蛇帮:#/bin/expect
②spawn 是执行expect之后执行的内部命令开启回话。功能:用来执行shell的交互命令
③expect 捕捉命令的返回提示。没有捕捉则会断开,否则等待一段时间后返回,等待通过timeout设置
④send 执行交互动作,将交互的命令发送给交互指令结尾加上\r--------相当于回车
⑤ exp_continue 继续执行接下来的操作
⑥interact -----如果添加interact参数将会等待我们手动交互进行退出。如果不加interact参数在登录成功之后会立刻退出。
⑦timeout-------->返回设置超时时间(秒)
案例:实战非交互式ssh连接
①vim test.sh
②编辑
#!/bin/expect
spawn ssh root@192.168.246.115
expect { "yes/no" { send "yes\r"; exp_continue } "password:" { send "1\r" }; } interact
③chmod a+x test.sh-------------->修改脚本权限
④/root/test.sh---------->启动脚本
⑤完成
日mysql类型、sql语句
一、数据可以的种类:
关系型数据库和非关系型数据库
1、关系型数据库:
①关系型数据库在存储数据时实际就是采用的一张二维表(和 Word 和 Excell 里表格几乎一样)。
②市场占有量较大的是 MySQL 和 Oracle 数据库,而互联网场景最常用的是 MySQL 数据库。
③通过 SQL 结构化查询语言来存取、管理关系型数据库的数据。
④关系型数据库在保持数据安全和数据一致性方面很强,遵循 ACID 理论 ACID指的的事务的4大特性
2、非关系型数据库
①NoSQL 数据库不是否定关系型数据库,而是作为关系数据库的一个重要补充。
②NoSQL 数据库为了灵活及高性能、高并发而生,忽略影响高性能、高并发的功能。
③在NoSQL 数据库领域,当今的最典型产品为 Redis(持久化缓存)、MongoDB、Memcached(纯内存)等。
④NoSQL 数据库没有标准的查询语言(SQL),通常使用数据接口或者查询API。
二、关系数据库和非关系数据库的区别
1、关系型数据库:
优点:
①易于维护:都是使用表格结构,格式一致;
②使用方便:SQL语言通用,可用于复杂查询;
③复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
①读写性能比较差,尤其是海量数据的高效率读写。
②固定的表结构,灵活度稍欠;
③高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
2、非关系型数据库。非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
①格式灵活:存储数据的格式可以是key, value形式,文档形式,图片形式等等,使用灵活,应用场景广泛。
②速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘
③高扩展性
④成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
①不提供sql支持
②无事务处理
③数据结构相对复杂,复杂查询方面稍欠。
三、yum安装mysql步骤
① 关闭防火墙和selinux
②mysql的官方网站下载:www.mysql.com
③wget https://repo.mysql.com//mysql80-community-release-el7-11.noarch.rpm --------------->下载数据库包
④rpm -ivh mysql80-community-release-el7-3.noarch.rpm ---------->安装mysql的yum仓库rpm
⑤vim /etc/yum.repos.d/mysql-community.repo-------------->配置yum源
mysql5.7版本的改为--------------enable=1;gpgcheck=0
mysql8版本的改为----------------enable=0
1表示开启。0表示关闭
⑥yum -y install mysql-community-server ---------------安装数据库
⑦systemctl start mysqld--------------启动数据库
⑧grep password /var/log/mysqld.log--------------------查找数据库初始密码
⑨打开vim /etc/my.cnf 在mysql下面添加validate_password=off----------------通过配置文件设置密码强度。
⑩mysql -u root -p '初始密码'-------------登录数据库
最后一步: set password=password("1");--------将密码修改为1
四、数据库存储引擎
1、InnoDB 存储引擎:默认引擎。最常用的。
特点:支持事务处理,支持外键,支持崩溃修复和并发控制,安全性比较高,回滚(rollback)。多用于银行
2、MYISAM存储引擎
特点:没有第一个安全性高,没有第三个速度快,对新数据来说它的处理高效率
3、MEMORY内存引擎
特点:所有的数据都在内存中,速度最快,但是安全不高。
五、忘记数据库密码,怎么召回
1.修改MySQL的登录设置
# vim /etc/my.cnf
在[mysqld]最后一段加一个设置
skip-grant-tables
保存退出
重启MySQL
service mysqld restart
进入MySQL
#/usr/local/mysql/bin/mysql -u root -p
遇到输入密码,直接回车就可进入MySQL
>update mysql.user set authentication_string=password('QF666!') where user='root' and host='localhost';
>退出MySQL,注释掉/etc/my.cnf添加skip-grant-tables然后保存退出。
>重启msyql
>用修改后的mysql密码登陆mysql
2.
如果遇到
You must reset your password using ALTER USER statement before executing this statement.
必须用下边这一种方法修改密码;
# vim /etc/my.cnf
在[mysqld]最后一段加一个设置
skip-grant-tables
保存退出
重启MySQL
service mysqld restart
进入MySQL
#/usr/local/mysql/bin/mysql -u root -p
遇到输入密码,直接回车就可进入MySQL
>SET password=password('QF666');
>退出MySQL,注释掉/etc/my.cnf添加skip-grant-tables然后保存退出。
>重启msyql
>用修改后的mysql密码登陆mysql
六、sql语句
show databases;-----------------------查看数据库中的所有库
show tables;-------------------------------查看某个数据库中的所有表格
create database 数据库--------------------创建数据库
use 库名------------------------------------------切换数据库
select database();-----------------------------查看当前在哪个库中
create tables 表明(字段1(类型), 字段2(类型)........)--------创建表格
insert into 表名 values(值)-------------------给表添加值
desc 表名------------------------------------------------查看表结构
select * from 库名.表;---------------------------查询某个库某个表的所有信息记录。
drop database/table数据库/表-----------------------------------删除数据库或者表
数据类型和表完整约束
1、整数类型:tinyint、smallint、mediumint、int(最常用)、bigint、
作用:用于存储用户的年龄、游戏的Level、经验值等。
2、浮点数类型:float 、double、decimal(定点数类型,比float更加准确)
作用:用于存储用户的身高、体重、薪水(decimal)等
3、字符串类型:char(0255)、varchar(065535)
作用:用于存储用户的姓名、爱好、电话,邮箱地址,发布的文章等
4、枚举类型: enum(多个选项只能选一个)
5、集合类型:set(多个选项,可以多选)
6、日期类型:year、date、time、datetime、timestamp
作用:用于存储用户的注册时间,文章的发布时间,文章的更新时间,员工的入职时间等
char和varchar的区别:
①char字符串长度是固定的,浪费空间。存取速度比varchar快。范围:0~255
②varchar字符串长度是可变的,节省空间。范围:0~65535
现在区别就是范围不一样,其他都一样。
二、表完整性约束
主键:primary key (pk)一个表里只能有一个主键,不能为空,而且唯一。
外键:foreign key (fk)
允许为空:null 一般默认为null
不能空:not null
唯一性:unique key (uk)唯一性+不能为空=主键。可以存在多个唯一性
自动增长(整数类型,必须是主键):auto_increment
默认值:default
无符号,正数:unsigned
🤩修改表名 rename table 旧表名 to 新表名
❤️添加主键:①alter table t1 add primary key (id);
②create table t1 values ( id int primary key, name char(20) );
❤️删除主键:① alter table t1 drop primary key ;
😍添加唯一性:alter table t1 change name name char(20)unique key;
😍删除唯一性:直接删库
🤡添加自动增长:必须是结合主键使用
①alter table t1 change id id int auto_increment;
② create table t1( id int primary key auto_increment);
🤡删除自动增长:①alter table t1 change id id int;
😎设置默认值:①alter table t1 change id id int default 0;
②alter table t1 alter id set default 0;
😎删除默认值:①alter table t1 change id id int ;
②alter table t1 alter id drop default;
表查询,多表查询
1、添加和删除字段
alter table 表名 add 字段 数据类型;
alter table 表名 add 字段 数据类型 after/first
alter table 表名 drop 字段;
2、修改字段和类型
alter table 表名 change 旧字段 新字段 类型; (主键....自动增长) (具有覆盖效果)
alter table 表名 字段名 数据类型;
3、插入数据
insert into 表名(字段1,字段2) values(记录);
insert into 表名 set 字段名=值..........;
4、修改数据
update 表名 set 修改的字段 where 给谁修改;
5、删除表/库,删除数据
drop table/database 表/库;
delete from 表名 where 条件;
6、单表查询
select * from 表名 where 条件
select (字段1,字段2....) from 表名----------查询某几个字段的信息
select 字段 as 别名,字段 as 别名 from 表名---------显示终端的字段会被临时修改。
7、多表查询
复制表结构+和数据
create table 新表 select * from 旧表;
create table 新表 select 字段 from 旧表 ;
| 函数 | 含义 | 例子 |
|---|---|---|
| and | 和 | select * from 表名 where 工资>5000 and 工资<3000; |
| or | 或 | select * from 表名 where 工资>5000 or 工资<3000; |
| between and | .....和.....之间 | select * from 表名 where 字段 between 3000 and 5000; |
| is null 或者is not null | 找是否某个字段为空 | select name from 表名 where 字段 is (not)null; |
| in() | 集合范围里寻找 | select name,工资 from 表名 where 工资 in(2500,3500,4500); |
| order by | 默认从小到大,如果降序+desc | select * from 表名 order by 工资 (desc); |
| limit | 1,5从第一行打印5行,不包括第一行 | select * from 表名 order by 工资 limit 1,5 |
| group by 字段 | 对字段进行去重、分组 | group by 字段 |
| group_concat(字段) | 将竖排转换成横排 | select group_concat(字段) from 表名 group by 字段 |
函数:
①、字段 as 表名
②、count(字段)统计记录数量
③、distinct 将表里面重复的数据进行合并
④、max()最大值
⑤、min()最小值
⑥、avg()平均值
⑦、now()现在的时间
⑧、sum()计算和
二、多表查询:
左外连接:from 表A left [outer] join 表B on 关联条件,表A是主表,表B是从表 右外连接: from 表A right [outer] join 表B on 关联条件,表B是主表,表A是从表 全外连接:from 表A full [outer] join 表B on 关联条件,两张表的数据不管满不满足条件,都做显示。
总结:sql语句的库、表、字段、数据的增删改查
一、库的增删改查
1、增
create database 库名-------------------添加数据库
2、删
drop database 库名--------------------删除数据库
3、改,没有。
4、查
show database;---------------------------展示所有的库
select database();----------------查看当前在哪个库
二、表的增删改查
三、字段的增删改查
四、数据的增删改查
,mysql索引和用户权限
一、索引分为那几种?
①普通索引(index)
②唯一索引(unique)
③主键索引(primary key)
④全文索引(full text)
二、索引的操作
1、【普通索引】
①create table 表名 (字段1 数据类型 约束条件 ,字段1 数据类型 约束条件 ,.........,index 索引名 (字段(长度)));
②create index 索引名字 on 表名 (字段(长度));
③alter table 表名 add index 索引名 (字段(长度));
2、【唯一索引】
①create table 表名 (字段1 数据类型 约束条件,字段2 数据类型 约束条件,.......,unique index 索引名 (字段(长度)));
②create index 索引名 on 表名(字段名);
【主键索引=主键约束】方法一样。
3、【普通、唯一索引删除】
①drop index 索引名 on 表名;
②alter table 表名 drop index 索引名
4、【主键索引删除】
alter table 表名 drop primary key;
【选择索引的原则】
- 常用于查询条件的字段较适合作为索引,例如WHERE语句和JOIN语句中出现的列 - 唯一性太差的字段不适合作为索引,例如性别 - 更新过于频繁(更新频率远高于检索频率)的字段不适合作为索引 - 使用索引的好处是索引通过一定的算法建立了索引值与列值直接的联系,可以通过索引直接获取对应的行数据,而无需进行全表搜索,因而加快了检索速度 - 但由于索引也是一种数据结构,它需要占据额外的内存空间,并且读取索引也加会大IO资源的消耗,因而索引并非越多越好,且对过小的表也没有添加索引的必要
三、导致sql执行慢的原因?
1、硬件问题。如网络速度慢,内存不足,I/O吞吐小,磁盘空间满了。
2、没有索引或者索引失败。
3、数据过多(分库分表)。
4、服务器调优以及各个参数设置(调整my.cnf)
四、权限管理
远程登录:mysql -u 用户名 -p 密码 -h 对方ip地址 -P 3306
修改用户的主机:
update user set host='%' where user='root';
2、创建用户
create user 用户名@'主机' identified by '设置用户密码'
①%所有主机远程登录
②192.168.107.*-------------------这个网段中的所有主机
③192.168.107.110-----------------制定主机
④localhost-------------------只允许本地用户登录
【修改用户信息】
updata 表名 set 修改字段 where 那个用户
3、权限管理
【刷新权限】flush privileges
【增加权限】
grant 权限 on 库.表 to 用户@'主机';
【删除权限】
revoke 权限 on 库.表 from 用户@'主机';
【查看用户权限】
show grants\G--------查看自己的权限
show grants for 用户@'主机' ----------查看别人的权限
4、删除用户
①drop user '用户'@'localhost'
②delete from mysql.user where user='用户' host='localhost';
,日志数据备份和恢复
概念:
1、为什么要备份数据?
①备份能够防止机械故障以及认为误操作带来的数据丢失,例如数据库文件保存在了其他地方
②数据有多份冗余,但不等备份,只能防止机械故障带来的数据丢失,例如主备模式,数据库集群
2、mysql数据备份需要备份的内容
①备份内容 database binlog my.conf
②所有数据都应该放在非数据库本地,而且建议多份副本。
③测试环境中恢复演练,恢复备份更为重要
3、备份过程中必须要考虑的因素?
①数据的一致性
②服务的可用性
4、物理备份和逻辑备份的区别?
①物理备份:直接复制数据库文件,适用于大型数据库环境,不受存储引擎的限制,但不能恢复到不同的mysql版本
②逻辑备份:备份的是建表、建库、插入等操作所执行的sql语句。
六六六【binlog恢复】
第一步:配置文件打开vim /etc/my.cnf log-bin=/logbin/yxl server-id=1 第二步:创建文件并给文件修改属性 mkdir /logbin chown mysql.mysql /logbin -R 第三步:重启数据库并刷新日志 systemctl restart mysqld flush log 第四步:进入数据中进行创建表,插入数据的操作。 第五步:删除数据库的表,下面进行恢复 【恢复】 第六步:mysqlbinlog /binlog/yxl.000001,找到at的起始位置和结束位置。 第七步:mysqlbinlog --start-position 起始位置 --stop-position 结束位置 binlog文件位置 | mysql -p1 -u root
| 物理备份 | 逻辑备份 | |
|---|---|---|
| 备份方式 | 备份数据库物理文件 | 备份数据库建表、建库、插入sql语句 |
| 优点 | 恢复速度比较快 | 备份文件相对较小,只备份表中的数据与结构 |
| 缺点 | 备份文件相对较大(备份表空间,包含数据与索引) | 恢复速度较慢(需要重建索引,存储过程等) |
| 对业务的影响 | I/O负载加大 | I/O负载加大 |
| 代表工具 | ibbackup、xtrabackup,mysqlbackup | ysqldump |
一、物理备份--xtrabackup---开源免费
物理备份分为:
①热备:数据库处于运行状态
②冷备:备份数据,需要停机,在关闭数据库的时候进行
③温备:备份的时候只读不写,数据库锁定表格的状态下进行
1、完整备份:备份、回滚、恢复、权限
优点:备份与恢复操作简单方便,恢复时一次恢复到位,恢复速度快
缺点:占用空间大,备份速度慢
①innobackupex --user=root --password='1' /a----------------------备份完整数据
②innobackupex --apply-log /a/完整备份的名字--------------回滚
③innobackupex --copy-back /a/完整备份的名字------------恢复
④chown mysql.mysql /var/lib/mysql -R---------权限
2、增量备份:备份 回滚(备份多少,回滚多少) 恢复 权限
优点:备份的数据量小,占用空间小,备份速度快。
缺点:但恢复时,需要从上一次的完整备份起按备份时间顺序,逐个备份版本进行恢复,恢复时间长,如中间某次的备份数据损坏,将导致数据的丢失。
【备份】
创建备份目录
①innobackupex --user=root --passwod=‘1’ /a/-------------------生成完整备份1
②innobackupex --user=root --password=‘1’ --incremental /a --incremental-basedir=/a/完整备份的名字 -------生成增量备份2
③innobackupex --user=root --password=‘1’ --incremental /a --incremental-basedir=/a/上个增量的名字--------生成增量备份3
【恢复备份】
④innobackupex --apply-log --redo-only /a/完整备份--------回滚完整备份
⑤innobackupex --apply-log --redo-only /a/完整备份 --incremental-dir=/a/增量备份-----回滚增量备份
⑥innobackupex --apply-log --redo-onlly /a/完整备份 --incremental-dir=/a/增量备份-----回滚增量备份
⑦innobackupex --copy-back /a/完整数据-------------恢复数据
⑧chown mysql.mysql /var/lib/mysql -R---------权限
3、差异备份:备份 回滚(完整备份和一个差异备份) 恢复 权限
优点:占用空间比增量备份大,比完整备份小,恢复时仅需要恢复第一个完整版本和最后一次的差异版本,恢复速度介于完整备份和增量备份之间。
缺点:空间比增量备份较大
【备份数据】
①innobackupex --user=root --password=‘1’ /a--------生成完整备份1
②innobackupex --user=root --pasword=‘1’ --incremental /a --incremental-basedir=/a/完整备份---------差异备份2
③innobackupex --user=root --password=‘1’ --incremental /a --incremental-basedir=/a/完整备份---------差异备份3
【恢复数据】
④innobackupex --apply-log --redo-only /a/完整备份------回滚
⑤innobackupex --apply-log --redo-only /a/完整备份 --incremental-dir=/a/差异备份3-----回滚差异备份
⑥innobackupex --copy-back /a/完整备份
⑥chown mysql.mysql /var/lib/mysql -R---------权限
二、逻辑备份---mysqldump----开源免费:
-A, --all-databases #备份所有库 -B, --databases #备份多个数据库 -F, --flush-logs #备份之前刷新binlog日志 --default-character-set #指定导出数据时采用何种字符集,如果数据表不是采用默认的latin1字符集的话,那么导出时必须指定该选项,否则再次导入数据后将产生乱码问题。 --no-data,-d #不导出任何数据,只导出数据库表结构。 --lock-tables #备份前,锁定所有数据库表 --single-transaction #保证数据的一致性和服务的可用性 -f, --force #即使在一个表导出期间得到一个SQL错误,继续
❤️备份用mysqldump 恢复用mysql
❤️单库备份不备份库名,需要创建库
❤️ 多个库备份,库名字也备份,不需要创建库
❤️在mysql终端直接 source 备份文件绝对路径,直接恢复结构,表(无法恢复表数据)、
1、【备份表、单库】
备份表 mysqldump -u root -p1 yxl t1 >/a/yxl_t1.sql
备份多个表mysqldump -u root -p1 yxl t1 t2 > /a/yxl_t1_t1.sql
备份一个库mysqldump - u root -p1 yxl > /a/yxl.sql
备份多个库mysqldump -u root -p1 -B yxl yxy > /a/yxl-yxy_DB.sql
2、【恢复表、单库】
恢复表,多表,单库 都需要创建一个空库,
mysql -u root -p 1 新的库名 < /a/要恢复的文件.sql
恢复多库
mysql -u root -p1 < /a/yxl-yxy_DB.sql
3、表结构备份和恢复
1.备份表结构: 语法:mysqldump -uroot -p123456 -d database table > dump.sql [root@mysql-server ~]# mysqldump -uroot -p'qf123' -d company employee5 > /home/back/emp.bak 恢复表结构: 登陆数据库创建一个库 mysql> create database t1; 语法:# mysql -u root -p1 -D db1 < db1.t1.bak [root@mysql-server ~]# mysql -uroot -p'qf123' -D t1 < /home/back/emp.bak
4、表数据备份和恢复
mysql> show variables like "secure_file_priv"; ----查询导入导出的目录。
配置:
修改安全文件目录: 1.创建一个目录:mkdir 路径目录 [root@mysql-server ~]# mkdir /sql 2.修改权限 [root@mysql-server ~]# chown mysql.mysql /sql 3.编辑配置文件: vim /etc/my.cnf 在[mysqld]里追加 secure_file_priv=/sql 不能创建在root目录下面。mysql用户进不去root目录。 4.重新启动mysql.
导出表数据:
1.导出数据 登陆数据查看数据 mysql> show databases; #找到test库 mysql> use test #进入test库 mysql> show tables; #找到它t3表 mysql> select * from t3 into outfile '/sql/test.t3.bak'; mysql优化(包含排错)
导入表数据:
2.数据的导入 先将原来表里面的数据清除掉,只保留表结构 mysql> delete from t3; mysql> load data infile '/sql/test.t3.bak' into table t3; 如果将数据导入别的表,需要创建这个表并创建相应的表结构。
** AB复制**
工作原理:
主服务端(master):①创建授权账号、②查询二进制日志位置以及节点位置。③设置server-id
从服务端(slave):①使用主机创建的授权账号,设置server-id
一、主从复制binlog方式
master主机:
第一步:systemctl stop firewalld 、 setenforce 0
第二步:vim /etc/my.cnf 进行编辑
server-id=1
log-bin=/a/b---------------------二进制日志位置/a 以及b二进制文件每次重启mysql都会生成一个新的二进制文件
第三步:创建文件,并给文件添加权限
mkdri /a
chown mysql.mysql /a -R
【重启msyql】
第四步:进入mysql终端创建授权账号
①create user 用户名@‘主机’ identified by ‘密码’ ----------创建用户
②grant replication on * . * to 用户名 @‘主机’ ---------设置权限
第五步:查看二进制文件地址以及节点位置
show master staus;
slave从机:
第一步:设置配置文件,打开vim /etc/my.cnf 编辑 ---------server-id=2 (不能和主机id一样)并重启mysql
第二步:在mysql终端配置从机
help change master to寻求帮助得到如下代码:
CHANGE MASTER TO MASTER_HOST='主机地址', MASTER_USER='创建的授权账号', MASTER_PASSWORD='密码', MASTER_PORT=3306, MASTER_LOG_FILE='二进制文件名', MASTER_LOG_POS=节点数, MASTER_CONNECT_RETRY=10; ------超时时间设置
第三步:启动slave --------start slave ;
第四步:查看slave状态-------------show slave status;
主从复制第二种方式GTID
主机(master):
第一步:配置环境打开 vim /etc/my.cnf进行编辑
server-id=1 #定义server id master必写
log-bin = /a/b #开启binlog日志,master比写
gtid_mode = ON #开启gtid
enforce_gtid_consistency=1 #强制gtid
第二步:创建二进制日志目录并添加权限:
mkdir /a
chown mysql.mysql /a -R
第三步:重启mysql-------systemctl restart msyqld
第四步:进入mysql终端创建授权账号。
cereate user 用户名@'主机' identified by '密码'
grant replication slave,reload,super on *.* to 用户名@'主机'
从机(slave):
第一步:配置环境打开vim /etc/my.cnf 进行编辑
server-id=2 (不能和主机一样)
gtid_mode = ON
enforce_gtid_consistency=1
master-info-repository=TABLE
relay-log-info-repository=TABLE-id=2
第二步:重启mysql---------systemctl restart mysqld
第三步:进入mysql进行配置:
CHANGE MASTER TO
MASTER_HOST='主机地址',
MASTER_USER='创建的授权账号',
MASTER_PASSWORD='密码',
MASTER_PORT=3306,
master_auto_position=1;
第四步:启动,查看slave状态:
start slave; show slave status;
读写分离
1、什么是读写分离?
在数据库集群架构中,让主库负责处理写入的操作。而从库只负责处理select查询,让两者分工明确达到提高数据库的整体读写能力
2、读写分离的好处?
1. 分摊服务器压力,提高机器的系统处理效率。 2. 在写入不变,大大分摊了读取,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了。 3. 增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务
准备第三台机器,一台是mycat jdk(环境) 、另外两台一台写,一台读。 第一台机器mycat: 第一步: tar xf jdk文件和mycat文件 -C /usr/local 第二步:进行环境配置打开vim /etc/profile进行编辑 export PATH=/usr/local/jdk1.8.0_211/bin/:$PATH 第三步:加载配置文件:source /etc/profile 第四步:配置mycat文件:vim /usr/local/mycat/conf/schema.xml 和server.xml文件配置
schema.xml配置
server.xml配置
写(master)机器的配置: 第一步:创建写机器的用户名和密码 create user 用户名@'主机' identified by '密码' grant all on 库.* to 用户名@'主机' create database 库(和mycat配置一样的真实数据库) 读(slave)机器的配置: 第一步:创建读机器的用户名和密码 create user 用户名@'主机' identified by '密码' grant all on 库.* to 用户名@'主机' create database 库(和mycat配置一样的真实数据库) 【三台机器重启mysql服务】
ansible模块
一、ansible的特点:
1、no agents 不需要客服端:
2、 no server 无服务器端
3、modules in any languages基于模块工作,可以用任意语言进行开发。
4、yaml,not,code使用yaml语言定制愚笨playbook
5、基于ssh工作
6、可实现多级指挥
二、ansible安装和环境配置
**【下载ansible】**
1、下载ailiyun ------------>wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
2、下载ailiyun扩展----------->wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
3、下载ansible------------>yum -y install ansible
【配置环境】
1、配置主机清单 打开vim /etc/ansible/hosts
[组名1 随便写]
主机ip 或者 或者主机名字(需要在vim /etc/hosts中进行本地解析)
[组名2 随便写]
主机ip 或者 或者主机名字(需要在vim /etc/hosts中进行本地解析)
[组名3:children]
组名1
组名2
最后配置:
[组名3:vars] #设置变量,vars--照写 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_private_key_file=/root/.ssh/id_rsa #ansible_ssh_pass=test #也可以定义密码,如果没有互传秘钥可以使用密码。
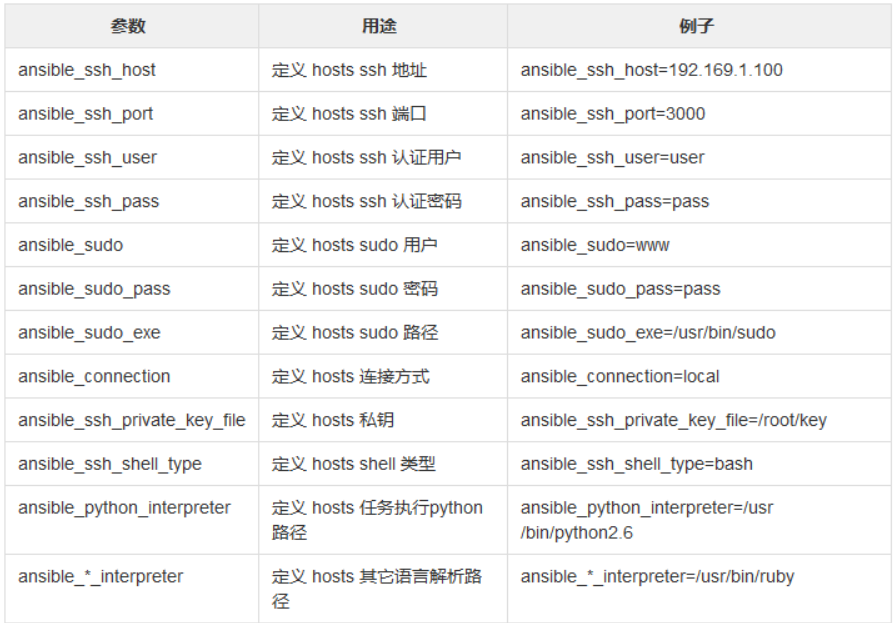
三、-i制定主机清单目录
[root@ansible-server ~]# ansible -i /opt/hostlist all -m ping -o 小注释:如果不通,手动连接第一次,第一次需要手动输入密码。"第一次" -i:指定清单文件 注意:这里的ping并不是真正意义上的ping而是探测远程主机ssh是否可以连接!判断ssh端口是否存活
四、常用模块
1.远程复制备份模块:copy 模块参数详解: src=:指定源文件路径 dest=:目标地址(拷贝到哪里) owner:指定属主 group:指定属组 mode:指定权限,可以以数字指定比如0644 backup:在覆盖之前将原文件备份,备份文件包含时间信息。有两个选项:yes|no [root@ansible-server ~]# ansible weball -m copy -a 'src=/root/a.txt dest=/opt/ owner=root group=root mode=644 backup=true' -o
2.软件包管理 yum模块 安装apache [root@ansible-server ~]# ansible webservers1 -m yum -a "name=httpd state=latest" -o state= #状态是什么,干什么 state=absent 用于remove安装包 state=latest 表示最新的 state=removed 表示卸载 卸载软件: [root@ansible-server ~]# ansible webservers1 -m yum -a "name=httpd state=removed" -o 或者 [root@ansible-server ~]# ansible webservers1 -m yum -a "name=httpd state=absent" -o
3.服务管理service模块 [root@ansible-server ~]# ansible webservers1 -m service -a "name=httpd state=started" #启动 [root@ansible-server ~]# ansible webservers1 -m service -a "name=httpd state=stopped" #停止 [root@ansible-server ~]# ansible webservers1 -m service -a "name=httpd state=restarted" #重启 [root@ansible-server ~]# ansible webservers1 -m service -a "name=httpd state=started enabled=yes" #开机启动 [root@ansible-server ~]# ansible webservers1 -m service -a "name=httpd state=started enabled=no" #开机关闭
4.文件模块file
模块参数详解:
owner:修改属主
group:修改属组
mode:修改权限
path=:要修改文件的路径
recurse:递归的设置文件的属性,只对目录有效
yes:表示使用递归设置
state:
touch:创建一个新的空文件
directory:创建一个新的目录,当目录存在时不会进行修改
#创建一个文件
[root@ansible-server ~]# ansible webservers1 -m file -a 'path=/tmp/youngfit1.txt mode=777 state=touch'
[root@ansible-server ~]# ansible ansible-web2 -m file -a 'path=/tmp/youngfit2.txt mode=777 owner=nginx state=touch'
#创建一个目录
[root@ansible-server ~]# ansible webservers1 -m file -a 'path=/tmp/qf mode=777 state=directory'
被控节点ansible-web2操作:
[root@ansible-web2 tmp]# cd /opt/
[root@ansible-web2 opt]# ll haha
total 0
-rw-r--r--. 1 root root 0 Sep 12 09:41 haha2.txt
-rw-r--r--. 1 nginx root 0 Sep 12 09:41 haha.txt
[root@ansible-server ~]# ansible ansible-web2 -m file -a "path=/opt/haha owner=nginx group=nginx state=directory recurse=yes"
被控节点查看:
[root@ansible-web2 opt]# ll haha
total 0
-rw-r--r--. 1 nginx nginx 0 Sep 12 09:41 haha2.txt
-rw-r--r--. 1 nginx nginx 0 Sep 12 09:41 haha.txt
5.收集信息模块setup [root@ansible-server ~]# ansible webservers1 -m setup #收集所有信息 [root@ansible-server ~]# ansible webservers1 -m setup -a 'filter=ansible_all_ipv4_addresses' #只查询ipv4的地址 filter:过滤
剧本(1)
Playbook介绍
playbook是ansible用于配置,部署,和管理被控节点的剧本。通过playbook的详细描述,执行其中的tasks,可以让远端主机达到预期的状态。playbook是由一个或多个”play”组成的列表。 当对一台机器做环境初始化的时候往往需要不止做一件事情,这时使用playbook会更加适合。通过playbook你可以一次在多台机器执行多个指令。通过这种预先设计的配置保持了机器的配置统一,并很简单的执行日常任务。
ansible通过不同的模块实现相应的管理,管理的方式通过定义的清单文件(hosts)所管理的主机包括认证的方式连接的端口等。所有的功能都是通过调用不同的模块(modules)来完成不同的功能的。不管是执行单条命令还是play-book都是基于清单文件。
playbook格式
playbook由yaml语言编写。YMAL格式是类似于JSON的文件格式,便于人理解和阅读,同时便于书写。
一个剧本里面可以有多个play,每个play只能有一个tasks,每个tasks可以有多个name
核心元素: Playbooks Variables #变量元素,可传递给Tasks/Templates使用; Tasks #任务元素,由模块定义的操作的列表,即调用模块完成任务; Templates #模板元素,使用了模板语法的文本文件; Handlers #处理器元素,通常指在某事件满足时触发的操作; Roles #角色元素
playbook的基础组件:
name:
定义playbook或者task的名称(描述信息),每一个play都可以完成一个任务。
hosts:
hosts用于指定要执行指定任务的主机.
user:
remote_user则用于指定远程主机上的执行任务的用户
tasks:
任务列表play的主体部分是task list. task list中的各任务按次序逐个在hosts中指定的所有主机上执行,即在所有主机上完成第一个任务后再开始第二个。
vars:
定义变量(如果不使用内部变量需要提前定义)
vars_files:
调用定义变量文件
notify:
任务执行结果如果是发生更改了的则触发定义在handler的任务执行
handlers:
用于当前关注的资源发生变化时采取一定指定的操作
实例一:
[root@ansible-server ~]# cd /etc/ansible/
[root@ansible-server ansible]# vim test.yml #创建文件必须以.yml/.yaml结尾
---
- hosts: webservers1
user: root
tasks:
- name: playbook_test
file: state=touch path=/tmp/playbook.txt
===================================================================================
参数解释:
hosts: 参数指定了对哪些主机进行操作;
user: 参数指定了使用什么用户登录远程主机操作;
tasks: 指定了一个任务.
name:参数同样是对任务的描述,在执行过程中会打印出来。
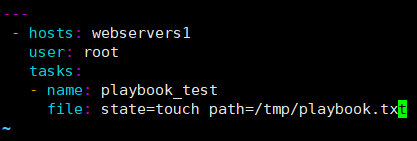
检测语法: [root@ansible-server ansible]# ansible-playbook --syntax-check test.yml playbook: test.yml 运行Playbook: [root@ansible-server ansible]# ansible-playbook test.yml #加剧本名称
实例二
handlers:由特定条件触发的Tasks
handlers:处理器
notify:触发器
语法:
tasks:
- name: TASK_NAME
module: arguments #1.上面任务执行成功,然后
notify: HANDLER_NAME #2.通知他
handlers:
- name: HANDLER_NAME #3.一一对应,这里的描述与notify定义的必须一样
module: arguments #4.执行这个命令
=======================================================
[root@ansible-server ansible]# vim handlers.yml
- hosts: webservers1
user: root
tasks:
- name: test copy
copy: src=/root/a.txt dest=/mnt
notify: test handlers
handlers:
- name: test handlers
shell: echo "abcd" >> /mnt/a.txt
========================================================
说明:只有 copy 模块真正执行后,才会去调用下面的 handlers 相关的操作,追加内容。所以这种比较适合配置文件发生更改后,需要重启服务的操作。
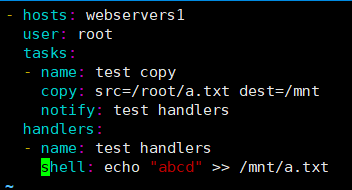
检测语法: [root@ansible-server ansible]# ansible-playbook --syntax-check handlers.yml playbook: handlers.yml [root@ansible-server ansible]# ansible-playbook handlers.yml
案例三
循环:迭代,需要重复执行的任务;
对迭代项的引用,固定变量名为”item”,使用with_items属性给定要迭代的元素;
基于字符串列表元素实战:
[root@ansible-server ansible]# vim list.yml
- hosts: webservers2
remote_user: root
tasks:
- name: install packages
yum: name={{ item }} state=latest #相当于for循环里面的i
loop: #取值 。但是不支持通配符
- httpd
- php
- php-mysql
- php-mbstring
- php-gd
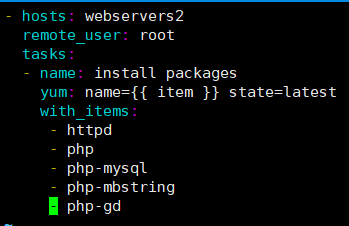
检测语法: [root@ansible-server ansible]# ansible-playbook --syntax-check list.yml playbook: list.yml 执行: [root@ansible-server ansible]# ansible-playbook list.yml
案例四、自定义vars_files变量
变量调用语法:
{{ var_name }}
====================================================
创建变量目录:
[root@ansible-server ~]# mkdir /etc/ansible/vars
[root@ansible-server ~]# cd /etc/ansible/vars/
[root@ansible-server vars]# vim file.yml #创建变量文件。
src_path: /root/test/a.txt
dest_path: /opt/test/
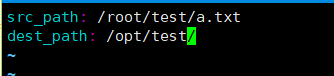
创建一个测试文件
[root@ansible-server vars]# mkdir /root/test
[root@ansible-server vars]# vim /root/test/a.txt #编辑测试文件
123
创建play-book引用变量文件:
[root@ansible-server vars]# cd /etc/ansible/
[root@ansible-server ansible]# vim vars.yml
- hosts: ansible-web1
user: root
vars_files:
- /etc/ansible/vars/file.yml
tasks:
- name: create directory
file: path={{ dest_path }} mode=755 state=directory
- name: copy file
copy: src={{ src_path }} dest={{ dest_path }}
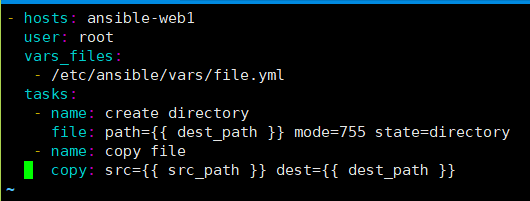
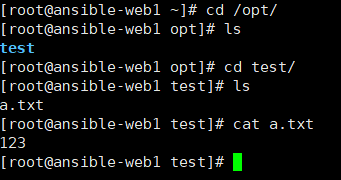
检测语法: [root@ansible-server vars]# cd .. [root@ansible-server ansible]# ansible-playbook --syntax-check vars.yml playbook: vars.yml 执行: [root@ansible-server ansible]# ansible-playbook vars.yml
登录查看:
实战:通过playbook安装apache
1.准备工作:
[root@ansible-server ansible]# vim hosts #添加主机web3
[webservers3]
ansible-web3
2.安装apache,准备配置文件
[root@ansible-server ~]# yum install -y httpd
[root@ansible-server ~]# mkdir /apache
[root@ansible-server ~]# cp /etc/httpd/conf/httpd.conf /apache/ #将配置文件推送到web3
3.修改端口将原来的80修改为8080
[root@ansible-server ~]# vim /apache/httpd.conf
Listen 8080
[root@ansible-server ~]# cd /etc/ansible/ #编写剧本
[root@ansible-server ansible]# vim apache.yml
---
- hosts: webservers3
user: root
tasks:
- name: install apache
yum: name=httpd state=latest
- name: copy conf file
copy: src=/apache/httpd.conf dest=/etc/httpd/conf/httpd.conf
notify: start httpd
handlers:
- name: start httpd
service: name=httpd state=restarted
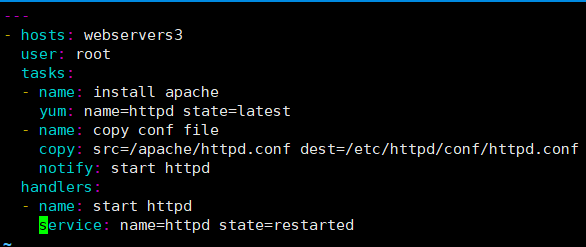
语法检测: [root@ansible-server ansible]# ansible-playbook --syntax-check apache.yml playbook: apache.yml 执行play-book [root@ansible-server ansible]# ansible-playbook apache.yml
登录web3查看:
剧本(2)
ansible-playbook(2)
group模块参数: name参数:必须参数,用于指定组名称。 state参数:用于指定组的状态,两个值可选,present,absent,默认为 present,设置为absent 表示删除组。 gid参数:用于指定组的gid。如果不指定为随机 system参数:如果是yes为系统组。--可选 ========================================================================================= 1.创建多个play [root@ansible ~]# cd /etc/ansible/ [root@ansible ansible]# vim play.yml - hosts: webservers1 user: root tasks: - name: create a group group: name=mygrp gid=2003 system=true - name: create a user user: name=tom group=mygrp system=true - hosts: webservers2 user: root tasks: - name: install apache yum: name=httpd state=latest - name: start httpd service service: name=httpd state=started =========================================================================================
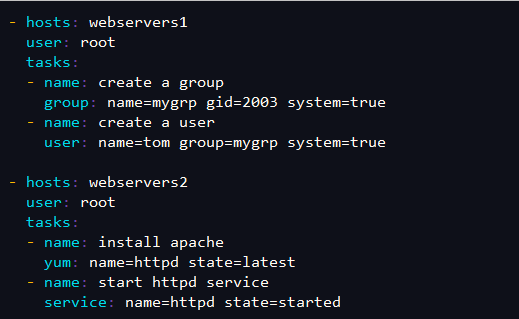
检查并执行 [root@ansible ansible]# ansible-playbook --syntax-check play.yml [root@ansible ansible]# ansible-playbook play.yml
2.条件执行when模块
先判断when条件是否成立
[root@ansible ansible]# cat /etc/ansible/hosts
[webservers1]
ansible-web1
ansible-web2
[root@ansible ansible]# vim when.yml
- hosts: webservers1
user: root
tasks:
- name: use when
file: state=touch path=/tmp/when.txt
- name: insert data
shell: echo 123 >> /tmp/when.txt #2在执行这个模块命令
when: ansible_hostname == "ansible-web1" #1.先条件执行,先判断when是否成立,如果成立则执行上面命令,ansible-web1指的是被控节点上真正的主机名称
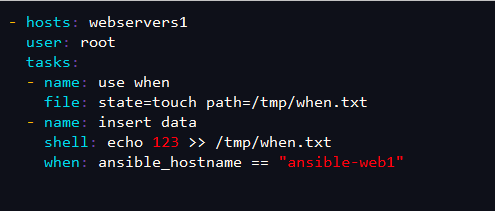
执行 [root@ansible ansible]# ansible-playbook when.yml [root@ansible-web1 ~]# cat /tmp/when.txt 123 [root@ansible-web2 ~]# cat /tmp/when.txt
3.使用变量并不显示搜集主机相关信息
gather_facts参数:指定了在任务部分执行前,是否先执行setup模块获取主机相关信息,默认值为true,改成false之后在执行过程中不会搜集主机相关信息。
==========================================================================================================
[root@ansible ansible]# vim create_user.yml
- hosts: ansible-web1
user: root
gather_facts: false #是否执行setup模块,搜集对方机器的信息
vars: #自定义变量
- user: "jack" #user是自定义变量名称,“jack”是变量值
- src_path: "/root/a.txt" #同上
- dest_path: "/mnt/"
tasks:
- name: create user
user: name={{ user }}
- name: copy file
copy: src={{ src_path }} dest={{ dest_path }}
[root@ansible ansible]# vim /root/a.txt #创建测试文件
123
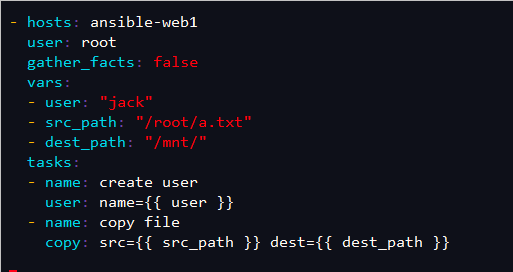
执行: [root@ansible ansible]# ansible-playbook create_user.yml
Role角色
roles则是在ansible中,playbooks的目录组织结构。而模块化之后,成为roles的组织结构,易读,代码可重用,层次清晰。
实战目标:通过role远程部署nginx并配置
两台机器配置本地解析 [root@ansible-server ~]# vim /etc/hosts 192.168.1.9 ansible-server 192.168.1.13 ansible-web4 [root@ansible-web4 ~]# vim /etc/hosts 192.168.1.9 ansible-server 192.168.1.13 ansible-web4 添加主机组 [root@ansible-server ansible]# pwd /etc/ansible [root@ansible-server ansible]# vim hosts [webservers4] ansible-web4 配置免密登录: [root@ansible-server ~]# ssh-copy-id -i 192.168.1.13
1.目录结构:

目录顺序:
role_name/ ---角色名称=目录
files/:存储一些可以用copy调用的静态文件。
tasks/: 存储任务的目录,此目录中至少应该有一个名为main.yml的文件,用于定义各task;其它的文件需要由main.yml进行“包含”调用;
handlers/:此目录中至少应该有一个名为main.yml的文件,用于定义各handler;其它的文件需要由(与notify:名字相同,方便notify通知执行下一条命令)通过main.yml进行“包含”调用;
vars/:此目录中至少应该有一个名为main.yml的文件,用于定义各variable;其它的文件需要由main.yml进行“包含”调用;
templates/:存储由template模块调用的模板文本; (也可以调用变量)
site.yml:定义哪个主机应用哪个角色
=========================================================================================
1.准备目录结构
[root@ansible-server ~]# cd /etc/ansible/roles/ #roles为自带目录,如果不存在可以创建
[root@ansible-server roles]# mkdir nginx/{files,handlers,tasks,templates,vars} -p
2.创建文件
[root@ansible-server roles]# touch site.yml nginx/{handlers,tasks,vars}/main.yml
[root@ansible-server roles]# yum install -y tree
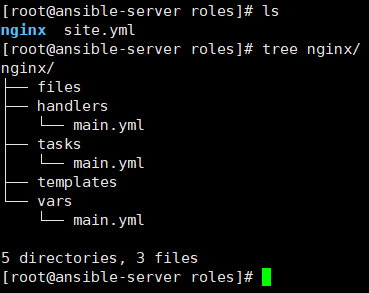
1.创建nginx的测试文件 [root@ansible-server roles]# echo 1234 > nginx/files/index.html 2.安装nginx并配置模板 [root@ansible-server roles]# yum install -y nginx && cp /etc/nginx/nginx.conf nginx/templates/nginx.conf.j2
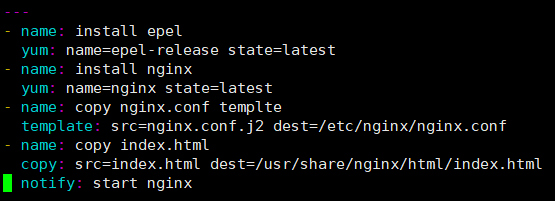
3.编写任务 [root@ansible-server roles]# vim nginx/tasks/main.yml --- - name: install epel yum: name=epel-release state=latest - name: install nginx yum: name=nginx state=latest - name: copy nginx.conf templte template: src=nginx.conf.j2 dest=/etc/nginx/nginx.conf - name: copy index.html copy: src=/etc/ansible/roles/nginx/files/index.html dest=/usr/share/nginx/html/index.html notify: start nginx
4.准备配置文件 [root@ansible-server roles]# vim nginx/templates/nginx.conf.j2 修改成如下内容。自定义变量
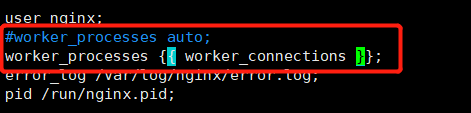
5.编写变量 [root@ansible-server roles]# vim nginx/vars/main.yml #添加如下内容 worker_connections: 2
6.编写handlers [root@ansible-server roles]# vim nginx/handlers/main.yml #编写如下内容 --- - name: start nginx #和notify的名字必须一样 service: name=nginx state=started
7.编写剧本 [root@ansible-server roles]# vim site.yml --- - hosts: webservers4 user: root roles: - nginx
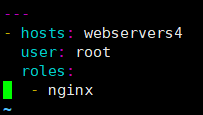
检测语法 [root@ansible-server roles]# ansible-playbook site.yml --syntax-check playbook: site.yml 执行剧本: [root@ansible-server roles]# ansible-playbook site.yml
查看:
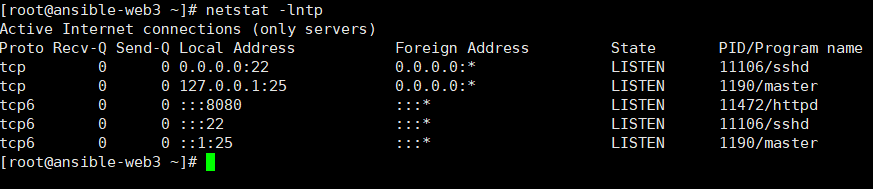
[root@ansible-web4 ~]# netstat -lntp Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 3102/nginx: master tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 926/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1007/master tcp6 0 0 :::80 :::* LISTEN 3102/nginx: master tcp6 0 0 :::22 :::* LISTEN 926/sshd tcp6 0 0 ::1:25 :::* LISTEN 1007/master [root@ansible-web4 ~]# cat /etc/nginx/nginx.conf | grep pro #worker_processes auto; worker_processes 2;
访问:
项目实战:通过ansible上线
批量部署Jdk+Tomcat
[root@ansible-server src]# cat tomcat.yml
- hosts: webservers
user: root
tasks:
##配置JDK,上传jdk、tomcat的安装包到/usr/src
- name: configure Jdk1.8
copy: src=/usr/src/jdk-8u211-linux-x64.tar.gz dest=/usr/src
- name: unzip
shell: tar -xvzf /usr/src/jdk-8u211-linux-x64.tar.gz -C /usr/local
- name: rename to java
shell: mv /usr/local/jdk1.8.0_211 /usr/local/java
- name: configure envirement1
shell: echo "JAVA_HOME=/usr/local/java" >> /etc/profile
- name: configure envirement2
shell: echo 'PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
##Tomcat
- name: copy tomcat
copy: src=/usr/src/apache-tomcat-8.5.45.tar.gz dest=/usr/src
- name: unzip tomcat
shell: tar -xvzf /usr/src/apache-tomcat-8.5.45.tar.gz -C /usr/local
- name: rename to tomcat
shell: mv /usr/local/apache-tomcat-8.5.45 /usr/local/tomcat
- name: copy startup file
copy: src=/usr/src/startup.sh dest=/usr/local/tomcat/bin
notify: start tomcat
handlers:
- name: start tomcat
shell: nohup /usr/local/tomcat/bin/startup.sh &
[root@java-server src]# ls
apache-tomcat-8.5.45 debug kernels tomcat.retry
apache-tomcat-8.5.45.tar.gz jdk-8u211-linux-x64.tar.gz startup.sh tomcat.yml
[root@java-server src]# head -2 startup.sh
#!/bin/sh
source /etc/profile
批量部署Jenkins
项目描述:
1.准备两台机器,一台作为nginx代理。一台为tomcat服务器。
2.tomcat服务器手动部署tomcat服务,并将webapps目录下面的内容提前删掉。
3.将jenkins.war包上传到nginx服务器。通过ansible将war包拷贝过去。并启动tomcat
4.配置nginx反向代理tomcat,实现访问jenkins。
操作如下:
一、tomcat服务器
1.安装jdk与tomcat略。
2.添加tomcat启动脚本中添加环境变量
[root@ansible-web2 ~]# vim /usr/local/tomcat/bin/startup.sh #需要添加如下内容
source /etc/profile
====================================
二、nginx服务器:
1.安装nginx与ansible,上传jenkins的war包略。
2.ansible配置如下:
3.定义变量:
[root@ansible ~]# cd /etc/ansible/
[root@ansible ansible]# mkdir vars
[root@ansible ansible]# vim vars/path.yml
src_path: /root/jenkins.war
dest_path: /usr/local/tomcat/webapps/
4.配置playbook:
[root@ansible ansible]# vim jenkins.yml
- hosts: webserver2
user: root
vars_files:
- /etc/ansible/vars/path.yml
tasks:
- name: copy jenkins.war
copy: src={{ src_path }} dest={{ dest_path }}
- name: start tomcat
shell: nohup /usr/local/tomcat/bin/startup.sh &
[root@ansible ansible]# ansible-playbook jenkins.yml
5.配置nginx反向代理
[root@ansible ansible]# vim /etc/nginx/conf.d/jenkins.conf
server {
listen 80;
server_name localhost;
charset koi8-r;
access_log /var/log/nginx/host.access.log main;
location /jenkins {
proxy_pass http://192.168.62.181:8080;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
6.启动nginx
7.检查nginx与tomcat是否启动成功!
8.访问nginx服务器http://ip/jenkins。
批量部署Jdk+Tomcat+Jenkins
将Jdk、Tomcat、Jenkins的安装包上传到ansbile控制节点的/usr/src下 [root@ansible ansible]# ls /usr/src/

[root@java-server ansible]# head -2 /usr/src/startup.sh //startup.sh是tomcat的启动脚本 #!/bin/sh source /etc/profile #加上此行,是为了启动加载到环境变量
下面是变量文件
变量文件 [root@ansible ansible]# cat /etc/ansible/vars/file.yml
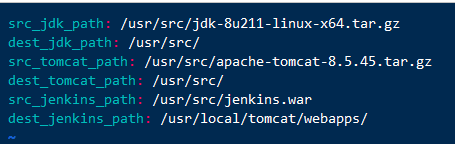
下面是剧本
[root@ansible ansible]# cat jenkins.yml
- hosts: ansible-web1
user: root
vars_files:
- /etc/ansible/vars/file.yml
tasks:
##配置JDK,上传jdk、tomcat的安装包到/usr/src
- name: configure JDK1.8
copy: src={{ src_jdk_path }} dest={{ dest_jdk_path }}
- name: unzip JDK
shell: tar -xvzf /usr/src/jdk-8u211-linux-x64.tar.gz -C /usr/local
- name: rename to java
shell: mv /usr/local/jdk1.8.0_211 /usr/local/java
- name: configure JDK envirement1
shell: echo "JAVA_HOME=/usr/local/java" >> /etc/profile
- name: configure JDK envirement2
shell: echo 'PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
##Tomcat
- name: copy tomcat
copy: src={{ src_tomcat_path }} dest={{ dest_tomcat_path }}
- name: unzip tomcat
shell: tar -xvzf /usr/src/apache-tomcat-8.5.45.tar.gz -C /usr/local
- name: rename to tomcat
shell: mv /usr/local/apache-tomcat-8.5.45 /usr/local/tomcat
- name: copy startup file
copy: src=/usr/src/startup.sh dest=/usr/local/tomcat/bin
##Jenkins
- name: copy jenkins
copy: src=/usr/src/jenkins.war dest=/usr/local/tomcat/webapps/
notify: start jenkins
handlers:
- name: start jenkins
shell: nohup /usr/local/tomcat/bin/startup.sh &
1.了解阿里云价格、基本部署 2.了解华为云价格、基本部署 3.了解腾讯云价格、基本部署
==DNS 解析==
1.了解国内主要的DNS ISP如万网、新网、DNSPOD、阿里DNS
==CDN 技术==
1.了解国内主要的3家CDN ISP,对比其价格、性能、市场的占有率等















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









