






相信很多进行数据处理工作的小伙伴都遇到过这种需求,比如已经有了各个销售员的销售业绩,现在需要给各个销售业绩进行一个分档,诸如未完成任务,完成任务,超额完成任务等。要完成分档需要先对销售业绩的数值进行判断,然后再根据判断的结果进行一个分类,那么大家都是怎样进行分类的呢?
实际上,上述需求是要对连续型的数值进行分箱操作,实现的方法有N种,但是效率有高有低,这里我们介绍一种效率比较高而且也容易理解的方法,运用DataFrame种的一个函数,叫做pd.cut()实现分箱操作。
pd.cut()参数介绍
先来看一下这个函数都包含有哪些参数,主要参数的含义与作用都是什么?
pd.cut( x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', )
x : 一维数组(对应前边例子中提到的销售业绩)
bins :整数,标量序列或者间隔索引,是进行分组的依据,
- 如果填入整数n,则表示将x中的数值分成等宽的n份(即每一组内的最大值与最小值之差约相等);
- 如果是标量序列,序列中的数值表示用来分档的分界值
- 如果是间隔索引,“ bins”的间隔索引必须不重叠
right :布尔值,默认为True表示包含最右侧的数值
- 当“ right = True”(默认值)时,则“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]
- 当
bins是一个间隔索引时,该参数被忽略。
labels : 数组或布尔值,可选.指定分箱的标签
- 如果是数组,长度要与分箱个数一致,比如“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3个区间,则labels的长度也就是标签的个数也要是3
- 如果为False,则仅返回分箱的整数指示符,即x中的数据在第几个箱子里
- 当bins是间隔索引时,将忽略此参数
retbins: 是否显示分箱的分界值。默认为False,当bins取整数时可以设置retbins=True以显示分界值,得到划分后的区间
precision:整数,默认3,存储和显示分箱标签的精度。
include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边。
duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一
ok,所有参数的含义与作用就是这些了,纯文字解释怎么都不如代码跑一遍来的直观,我们在代码中实现一下再结合上述文字解释就很容易理解了。而且并不是所有参数都是常用的,有些参数很少用到!
pd.cut()代码示例
先来看一下数据源
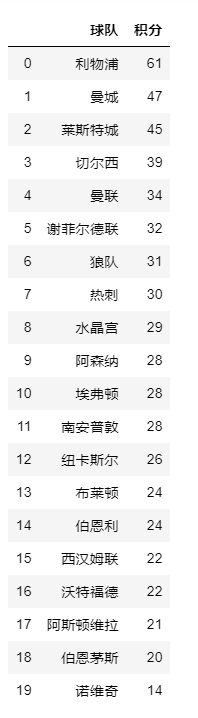
df_f = pd.read_excel(r"D:\data\football\球队排名比分2019.xlsx")
df_f读入的数据是2019年英超各球队的积分:
进行分箱
bins取整数,即指定箱子个数
我们对积分数据进行分箱,先来最简单的:
pd.cut(df_f.积分,bins=3,labels=["低","中","高"]) #分成3箱并指定标签分箱结果:
0 高
1 高
2 中
3 中
4 中
5 中
6 中
7 中
8 低
9 低
10 低
11 低
12 低
13 低
14 低
15 低
16 低
17 低
18 低
19 低
Name: 积分, dtype: category
Categories (3, object): [低 < 中 < 高]直接指定箱子个数,分成等宽的3份,感兴趣的同学可以求一下每个箱子内的极值,应该是约相等的。
前边有提到,这种分箱方式看不到分界值是多少,但是可以通过参数进行设置显示分界值:
pd.cut(df_f.积分,3,labels=["低","中","高"],retbins=True) #retbins=True显示分界值分箱结果:
(0 高
1 高
2 中
3 中
4 中
5 中
6 中
7 中
8 低
9 低
10 低
11 低
12 低
13 低
14 低
15 低
16 低
17 低
18 低
19 低
Name: 积分, dtype: category
Categories (3, object): [低 < 中 < 高],
array([13.953 , 29.66666667, 45.33333333, 61. ]))是不是能明显的看出和上一次代码结果相比多了一个 array([13.953 , 29.66666667, 45.33333333, 61. ]),这就是分箱的分界值啦,我们就能知道分箱的时候是以那个数值作为分界点进行分箱的了。
如果不指定每个箱子的标签是什么
pd.cut(df_f.积分,3,labels=False) #只显示数据位于第几个箱子里分享结果:
0 2
1 2
2 1
3 1
4 1
5 1
6 1
7 1
8 0
9 0
10 0
11 0
12 0
13 0
14 0
15 0
16 0
17 0
18 0
19 0
Name: 积分, dtype: int64只显示每个位置上的数值属于第几个箱子
bins取标量序列
pd.cut(df_f.积分,[0,30,40,70],labels=["低","中","高"]) #默认right = True指定分箱时候的分界点,即0~30,30~40,40~70一共三个箱体,有默认的right = True,即分箱的时候,30包含在0~30的箱体中,40包含在30~40的箱体中,70包含在40~70的箱体中,我们来看下结果,是不是和描述一致:

这里红框部分是要和下边更改参数right后的结果进行对比的,我们来看下:
pd.cut(df_f.积分,[0,30,40,70],labels=["低","中","高"],right=False)分箱结果:
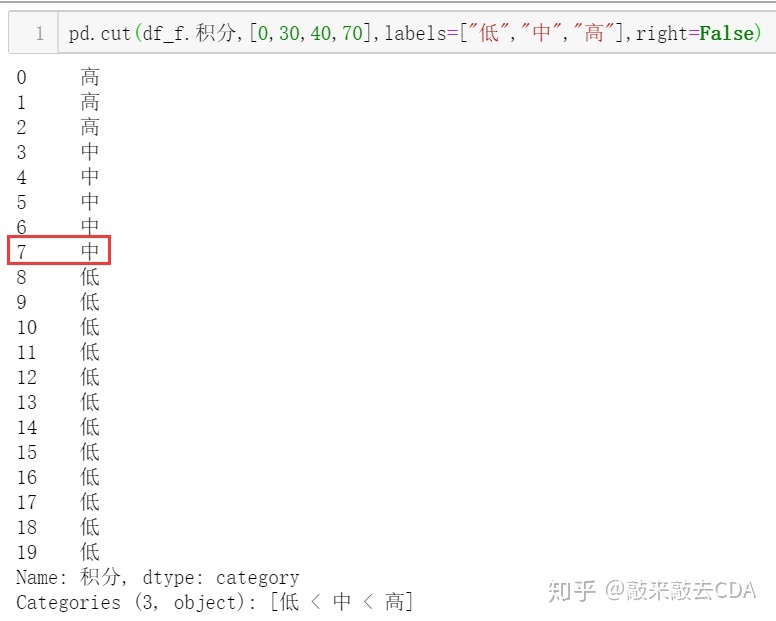
能够看到,right参数设置对分箱结果的影响。为什么会有这样的影响呢?我们回顾下我们的原数据:

能够发现分享发生变化的数值正好是我们分箱的临界值,可以通过参数进行设置临界值被划分到哪一边的箱体中。
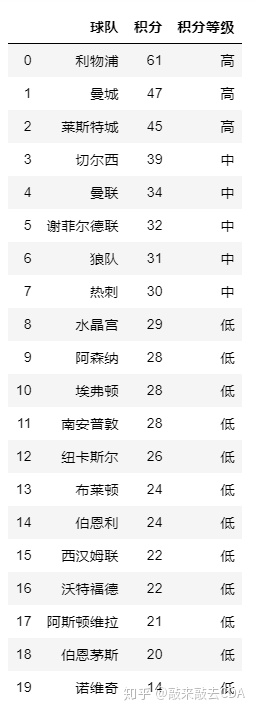
如果需要将分箱的结果展示在原数据框中,直接赋值一列进去就可以了:
df_f.loc[:,"积分等级"]=pd.cut(df_f.积分,[0,30,40,70],labels=["低","中","高"],right=False)
df_f结果如下:
对于pd.cut()函数常用的参数设置就是这些了,小伙伴们还有哪些疑问或者新发现欢迎一起讨论啊!

















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









