






开局介绍
-
1.5B(1.5 Billion):
- 模型参数数量为15亿。
- 这种规模的模型通常属于中小型模型,适用于训练速度快、资源需求较低的任务。例如,可以用于一些小型的自然语言处理任务,或者在设备性能有限的情况下(如移动设备)进行推理。
-
7B(7 Billion):
- 模型参数数量为70亿。
- 这种规模的模型已经开始进入大模型的范畴,通常具有较好的语言理解和生成能力。它们可以处理复杂的自然语言理解任务,并具备一定的上下文理解能力。
-
8B(8 Billion):
- 模型参数数量为80亿。
- 这个规模的模型与7B类似,都属于较大的模型。通常比1.5B模型有更强的学习能力和更好的泛化能力,适合用于需要较高精度的任务和应用。
-
14B(14 Billion):
- 模型参数数量为140亿。
- 这是一个非常大的模型,通常具备更强的语言理解和生成能力,能够处理更复杂的任务。同时,训练和推理所需的计算资源也显著增加。
-
32B(32 Billion):
- 模型参数数量为320亿。
- 这是一个非常庞大的模型,通常用于需要极高精度和复杂度的任务。这类模型在自然语言理解、生成和对话系统等领域表现出色,但需要大量的计算资源进行训练。
-
70B(70 Billion):
- 模型参数数量为700亿。
- 这是一个巨型模型,拥有极其强大的语言理解和生成能力。通常用于最前沿的自然语言处理研究和服务,如高级智能助手、知识问答系统等。
-
671B(671 Billion):
- 模型参数数量为6710亿。
- 这是一个极其庞大的模型,目前基本上只有极少数顶尖的研究团队或公司有能力开发和训练这样的模型。这种模型通常用于最前沿的研究,具有极高的理解能力和生成能力。
区别与选择:
-
模型规模与性能:模型参数越多,理论上模型的学习能力越强,处理复杂任务的能力也越强。然而,更大的模型也意味着更高的训练和推理成本。
-
应用场景:选择合适的模型规模需要根据具体的应用场景和资源限制来决定。对于资源有限或对实时性要求高的应用,较小的模型可能更合适;而对于复杂和精度要求高的任务,较大的模型则更为适用。
-
计算资源:模型规模越大,所需的计算资源(如GPU/TPU的数量和内存)也越多。因此,在选择模型时需要考虑计算资源的限制。
总结来说,不同的版本(如1.5B、7B、14B等)主要区别在于模型的参数量级,这直接影响了模型的学习能力、处理任务的复杂度以及所需的计算资源。选择合适的版本需要综合考虑应用需求、性能要求以及计算资源的限制。如果您有更多关于Deep Seek或者这些版本的具体问题,欢迎继续提问。
这是基于抖音旗下产品的一套产品让你拥有自己的ai
一、火山引擎
1.在浏览器上输入:火山引擎,进入他的官网。
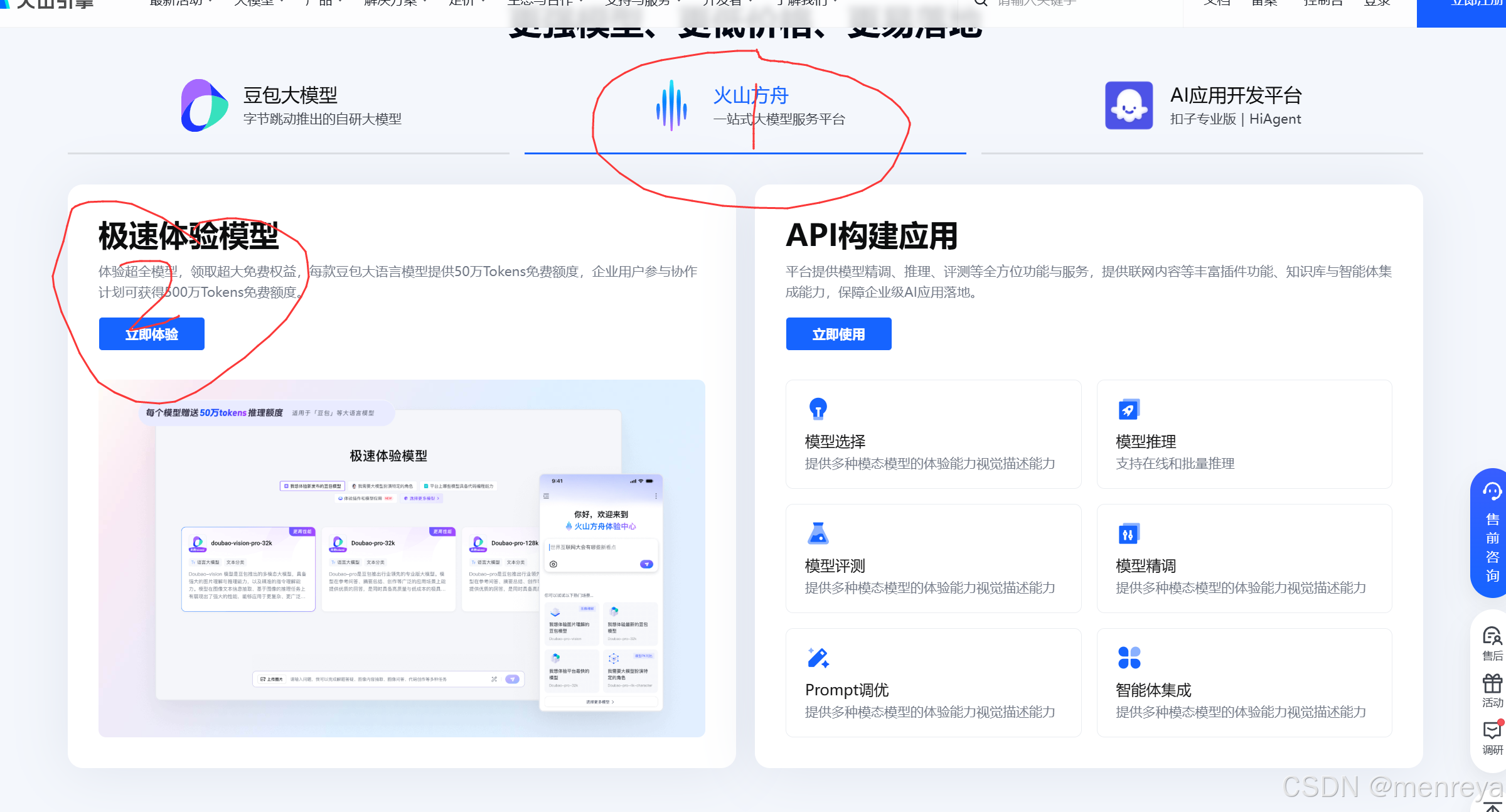
2.进入官网后点击:火山方舟。再点击:立即体验。就进入了控制台
3.找到左边的在线推理 ,点击:创建推理接入点
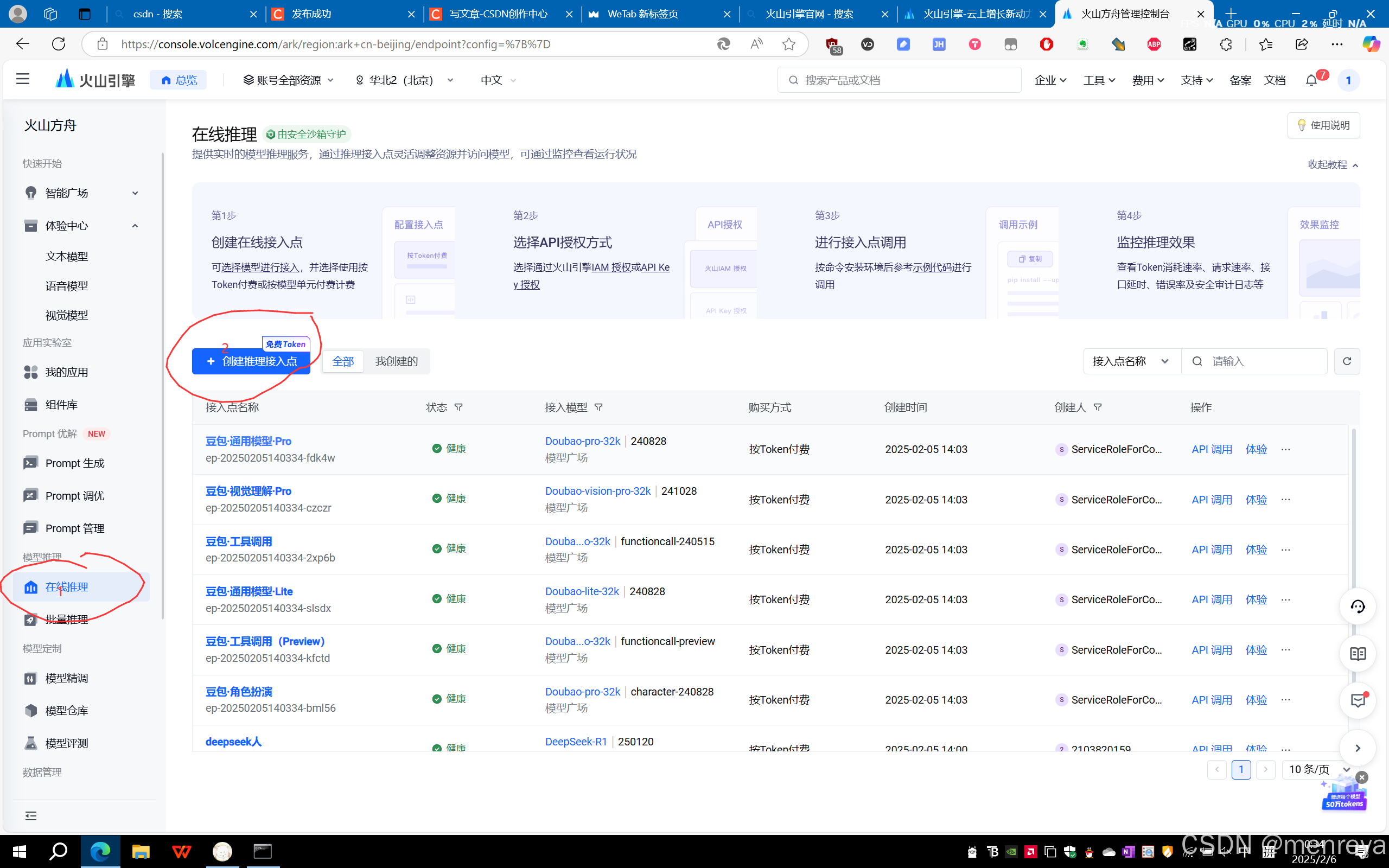
4.进入后接入点名称随便起,点击添加模型
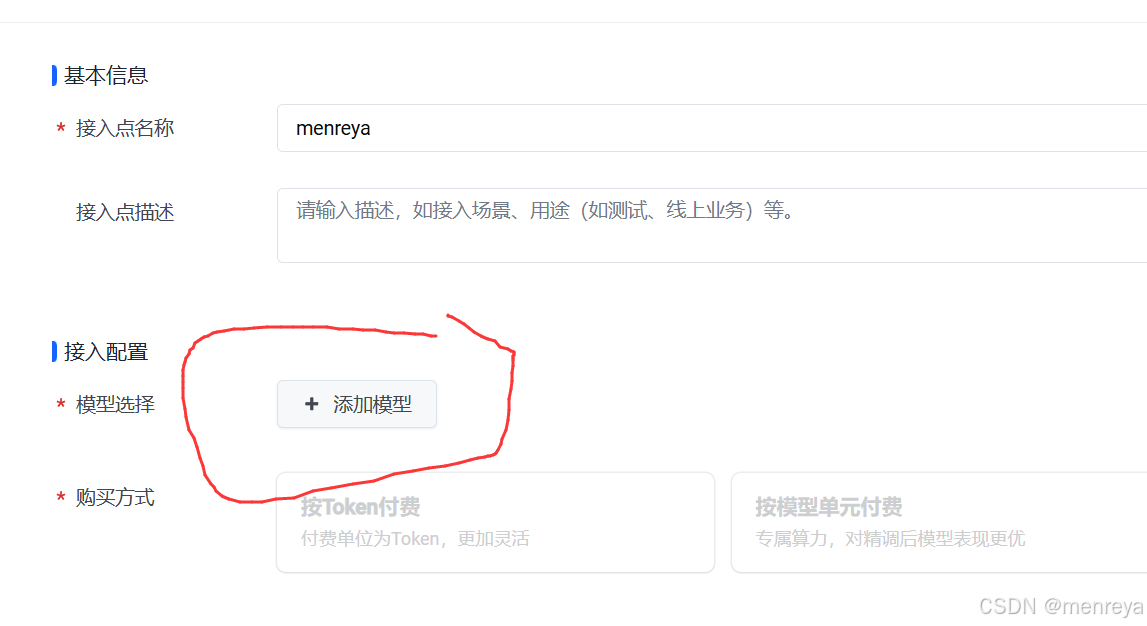
5.进行选择(这个Deepseek-R1就是671b的模型)
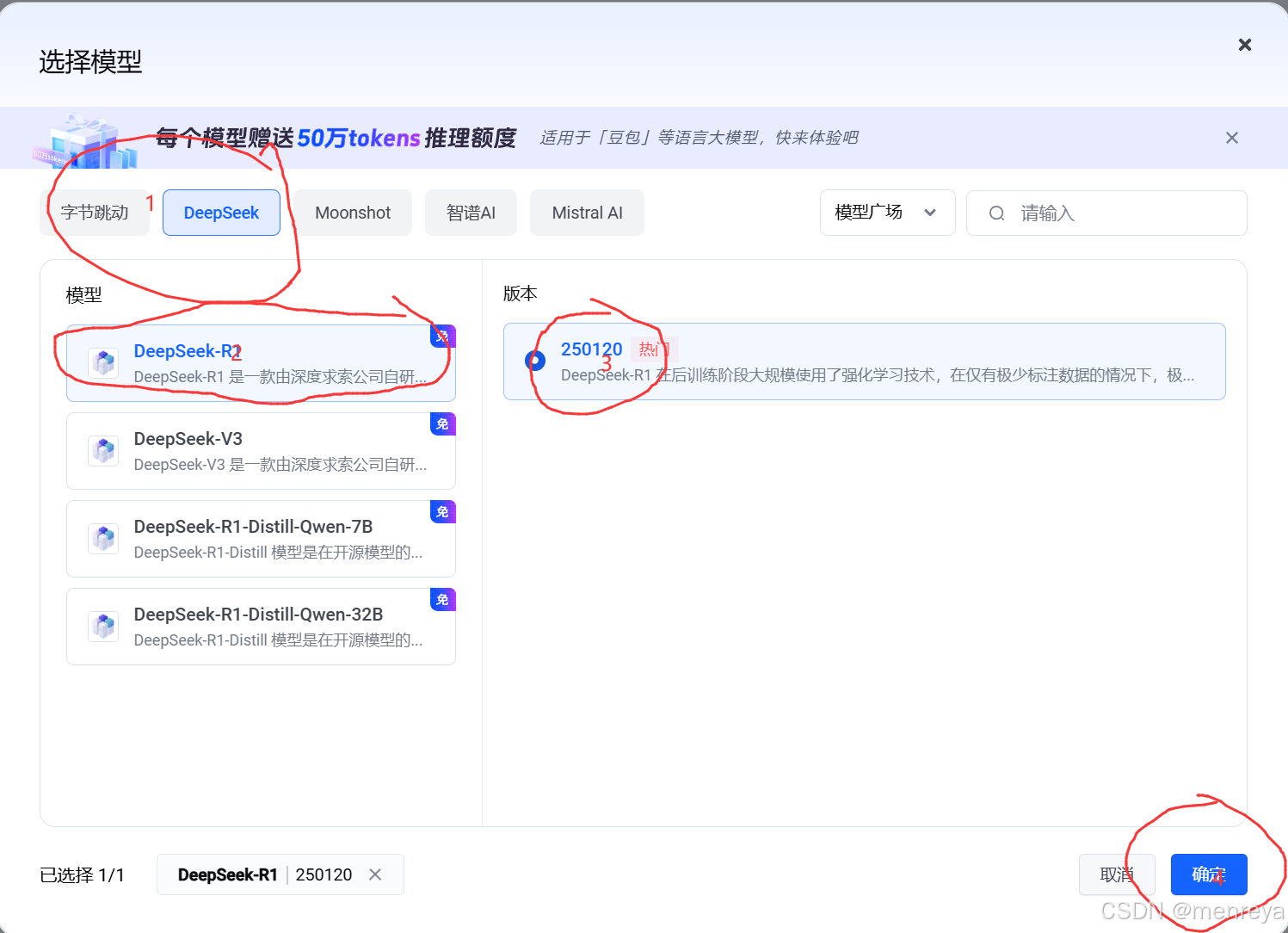
6.点击确定接入
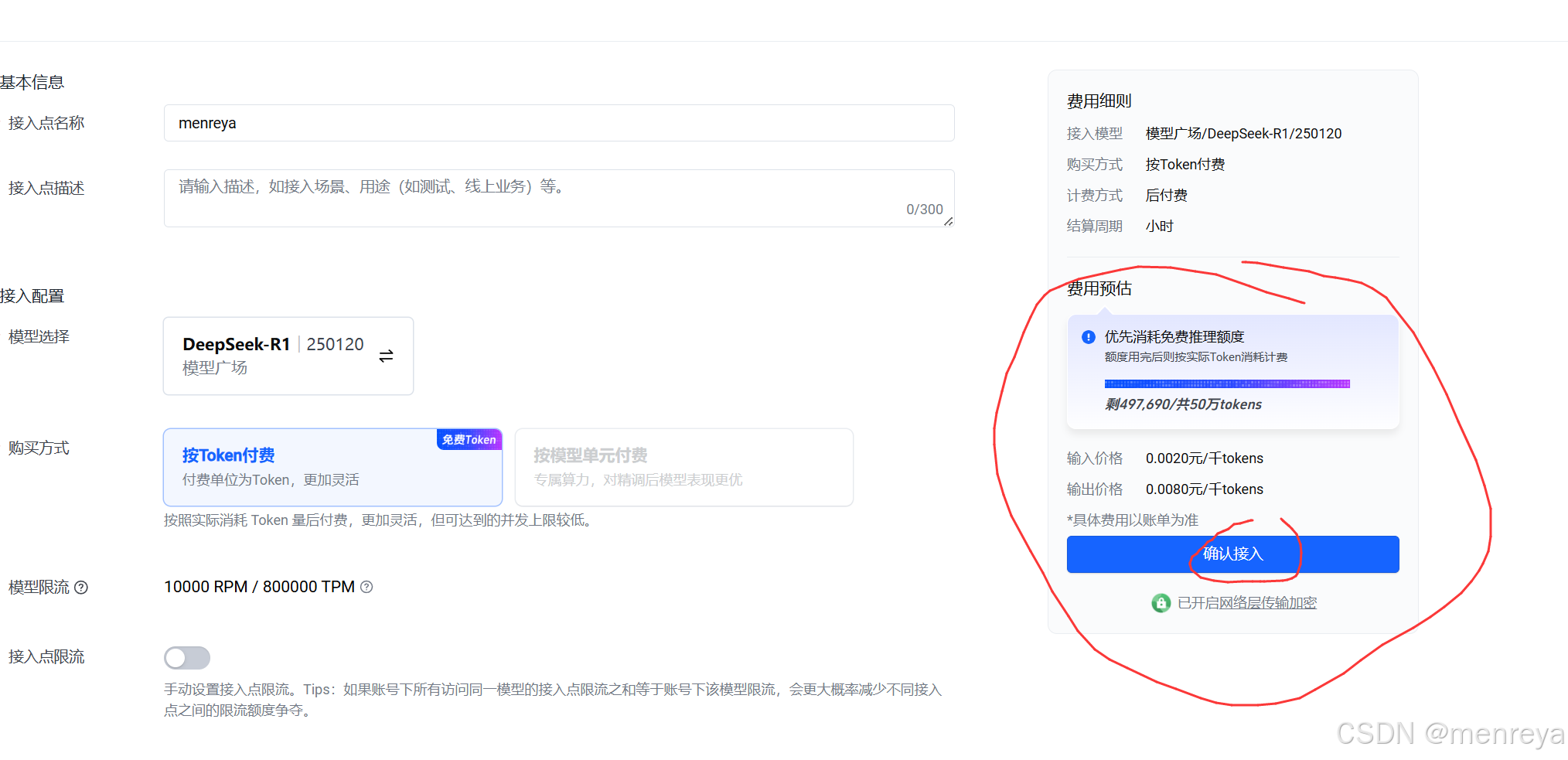
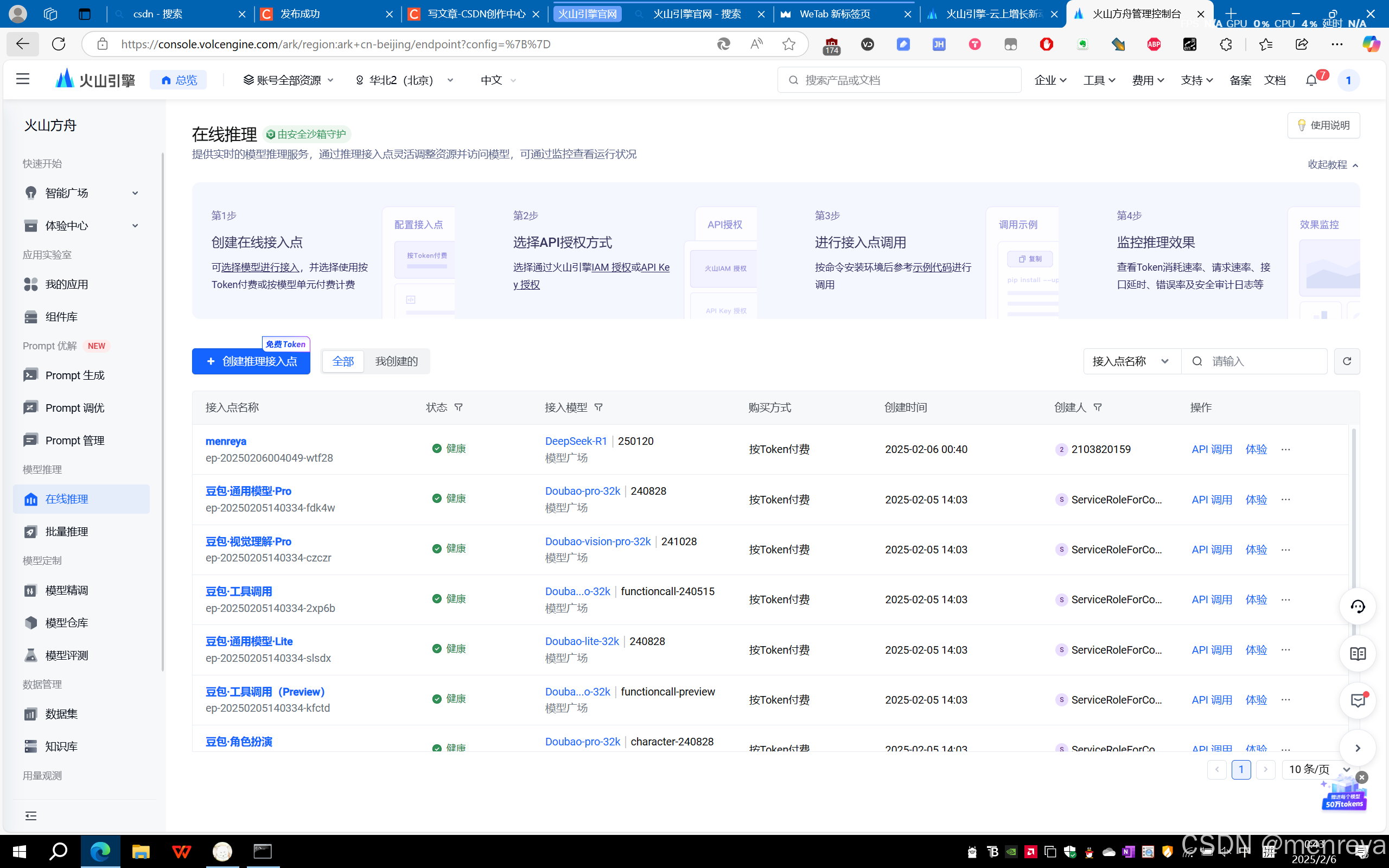
新用户有50w免费token的回答就是能免费回复你50w个字。新用户没有实名验证的话,点不了确定接入,要先进行实名验证。就能接入了。最后是menreya创建成功的页面。
二、coze
1.进入coze官网(扣子)
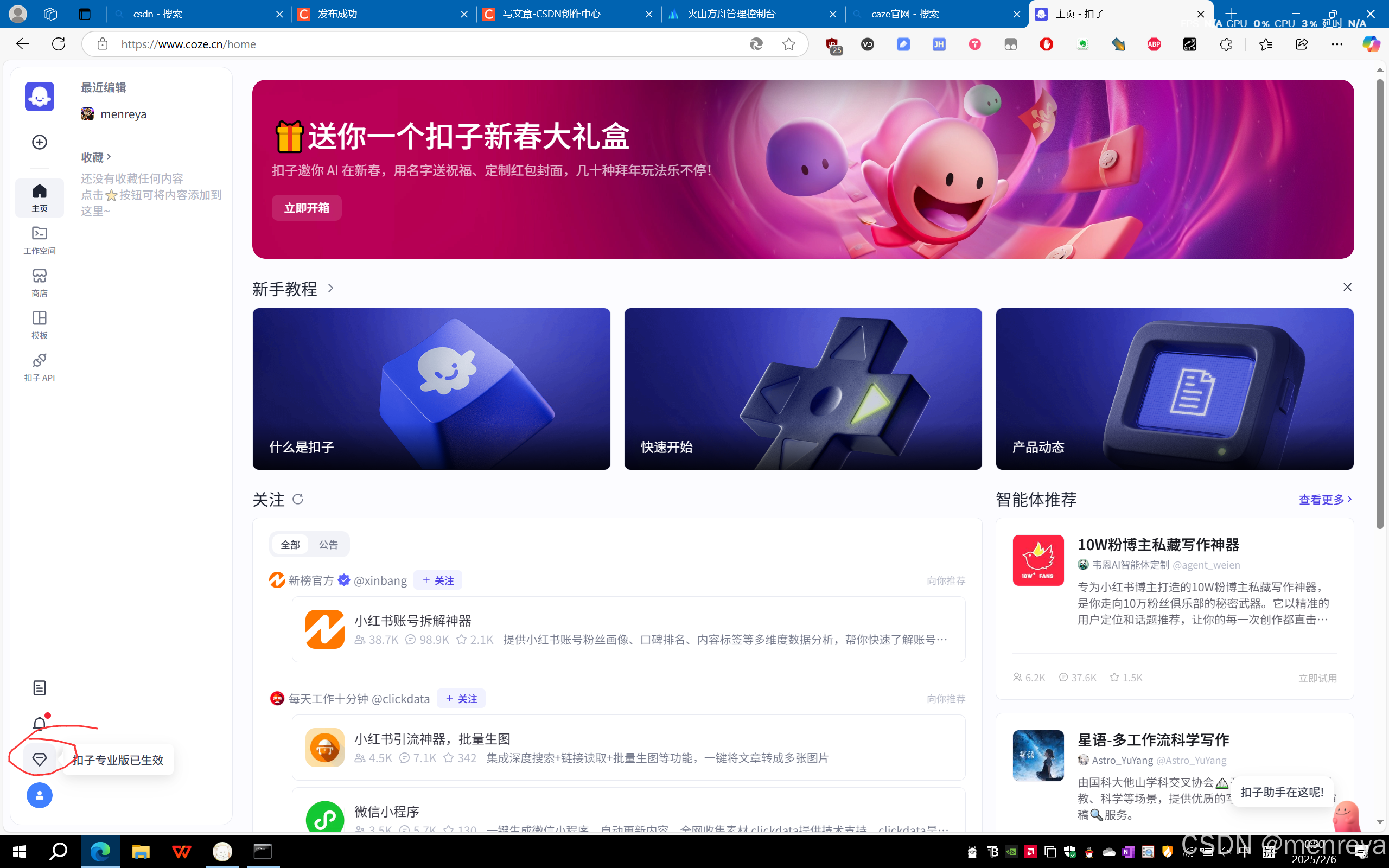
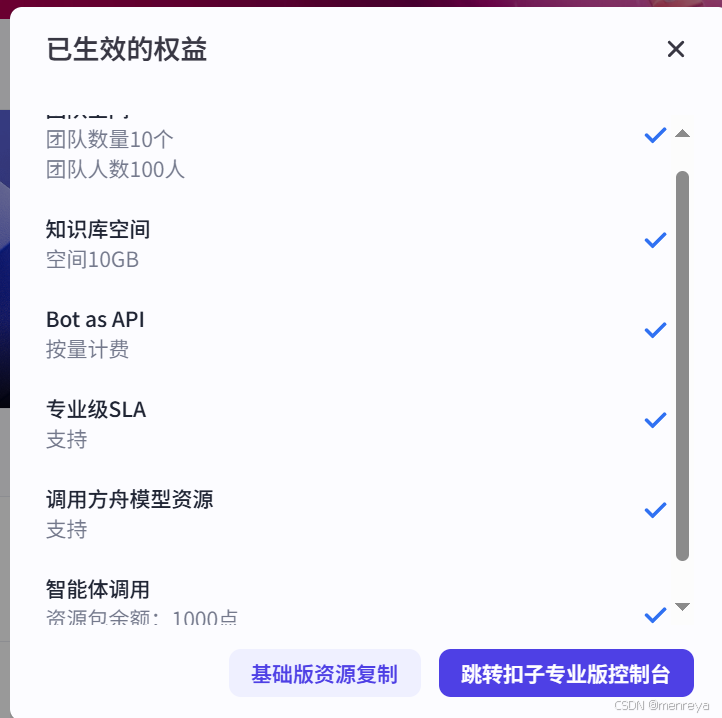
 2.关键一步,一定要点击右下角的钻石,花费一块钱开通一下专业版,不开通,会在后面的操作会搜索不到你在火山引擎创建的menreya模型。
2.关键一步,一定要点击右下角的钻石,花费一块钱开通一下专业版,不开通,会在后面的操作会搜索不到你在火山引擎创建的menreya模型。
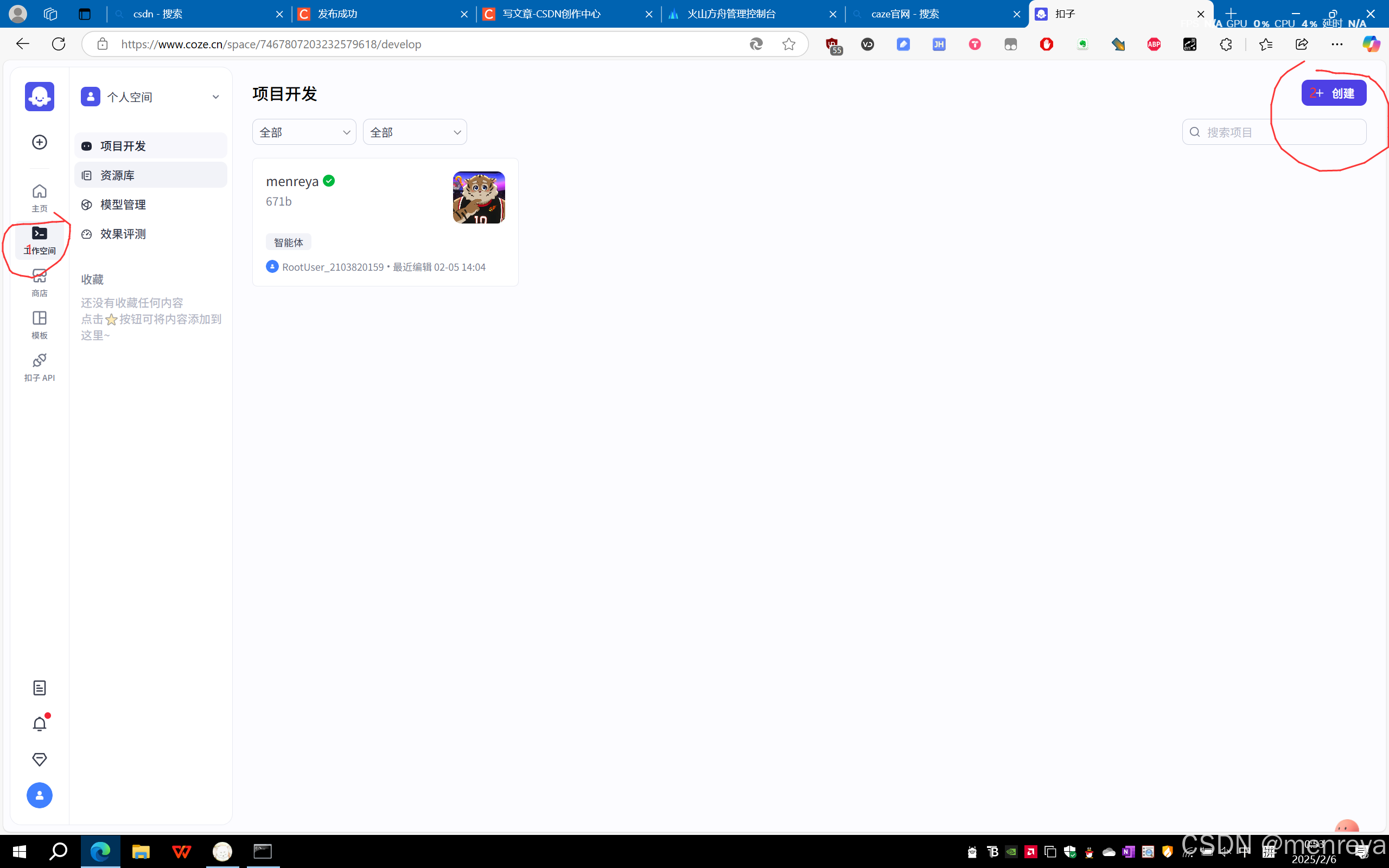
3.回到主页面,点击左侧的:工作空间,然后点击最右边的创建按钮。
4.点击创建智能体
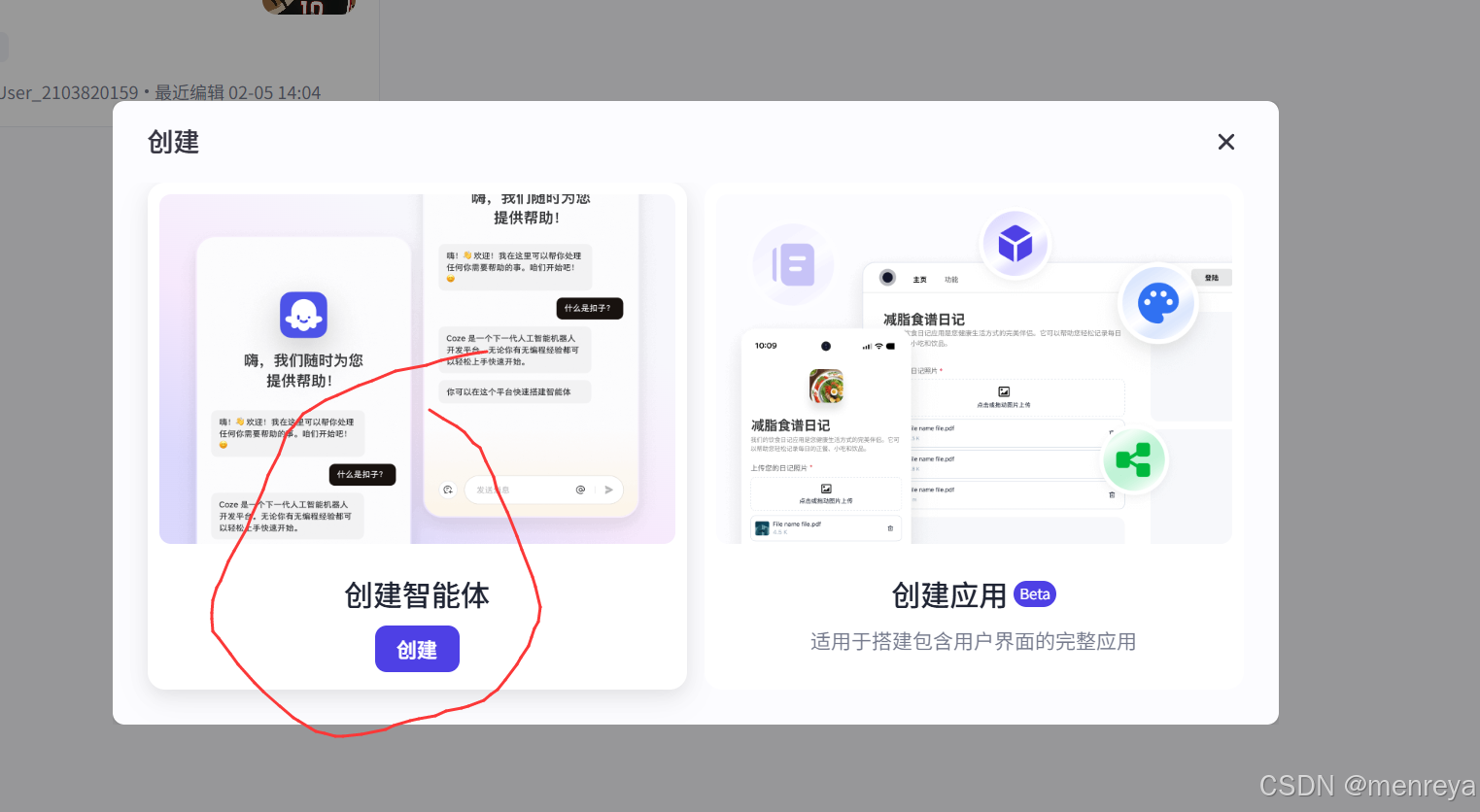
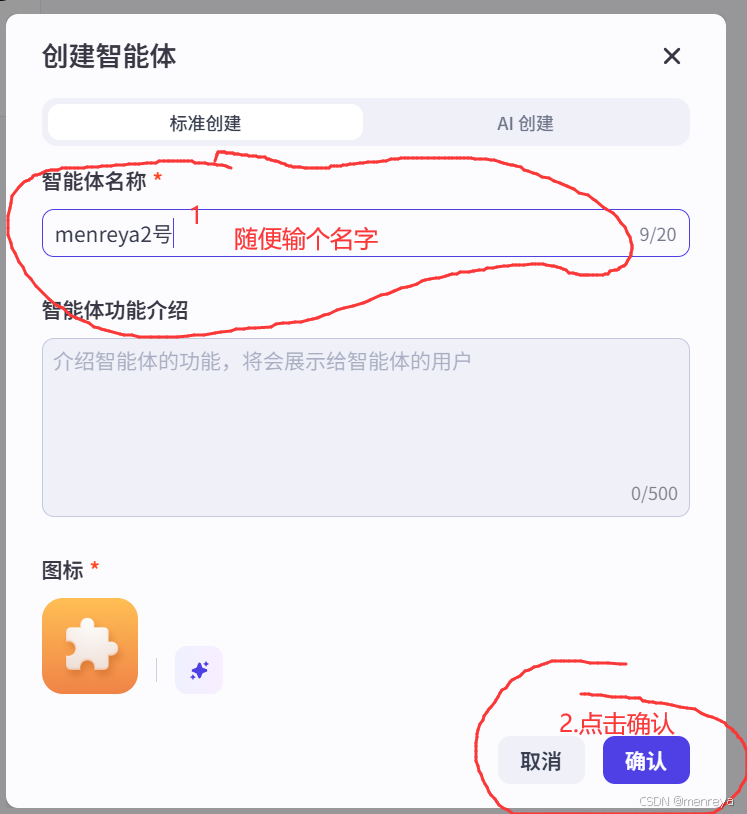
5.起名字,确定
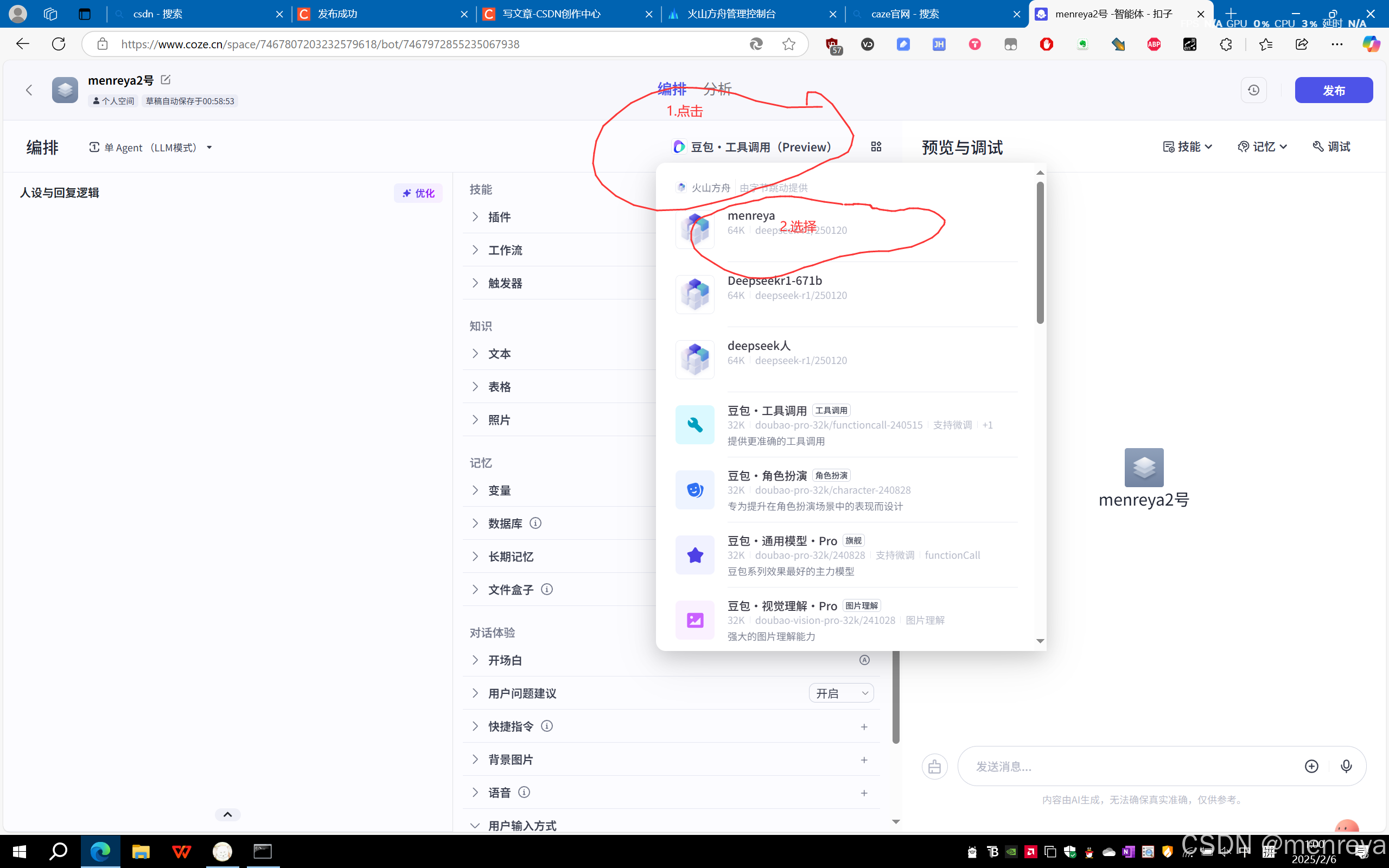
6.选择你需要使用的ai模型,就是你在火山引擎中创建的那个名字,选择(不花费1rmb的这里会找不到自己创建的ai模型)
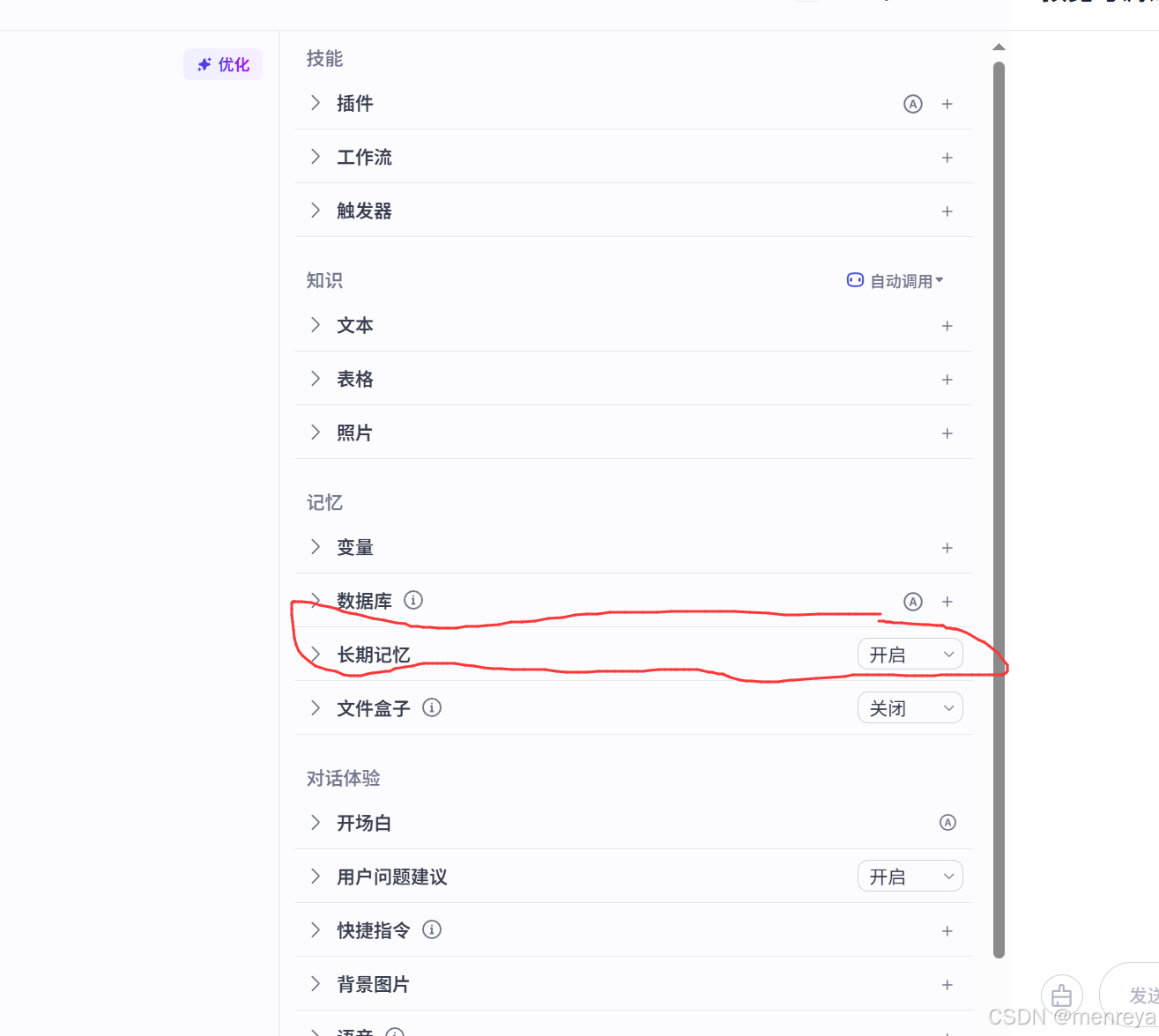
这里建议开启长期记忆,防止以后问题被删除。其他的你就不用管了,也不用改。(高手有需求,能看懂随意。)
7.点击右上角的发布,然后点跳过直接发布
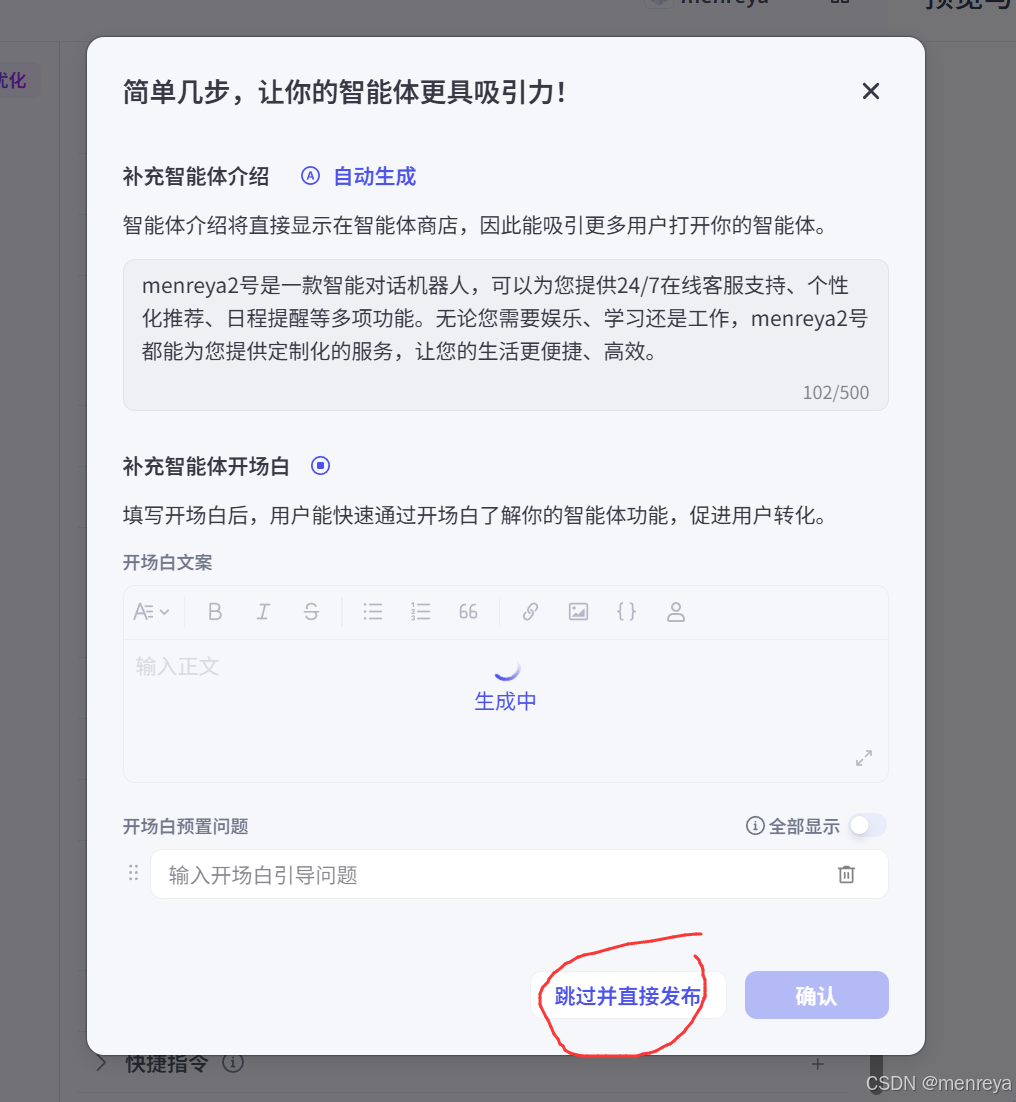 8.然后进入这个页面,他默认勾选的就是扣子商店,没需求就点掉,勾选豆包,豆包现在仅支持自己使用,相当于是你自己的了。
8.然后进入这个页面,他默认勾选的就是扣子商店,没需求就点掉,勾选豆包,豆包现在仅支持自己使用,相当于是你自己的了。
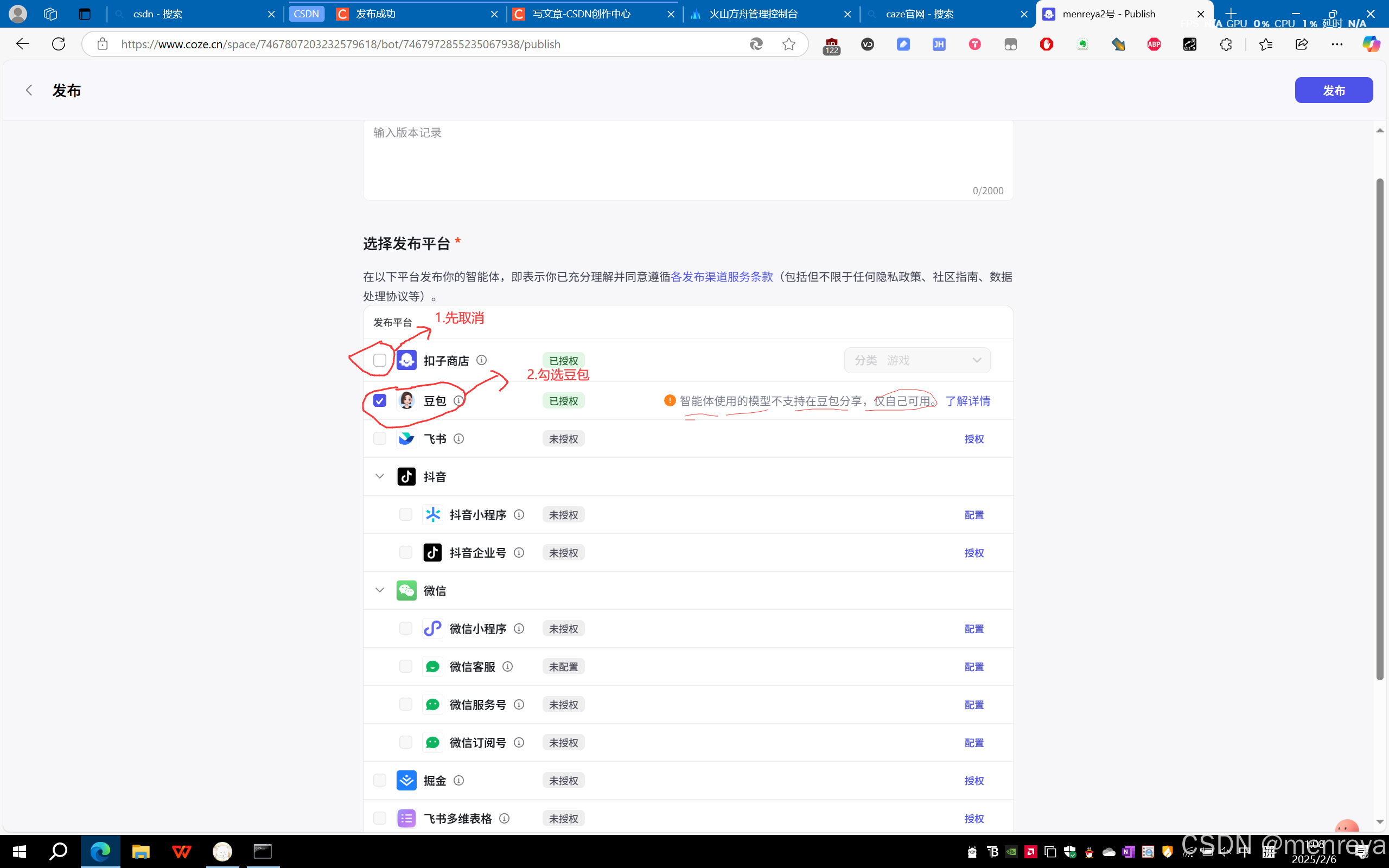
9.点击右上方的发布
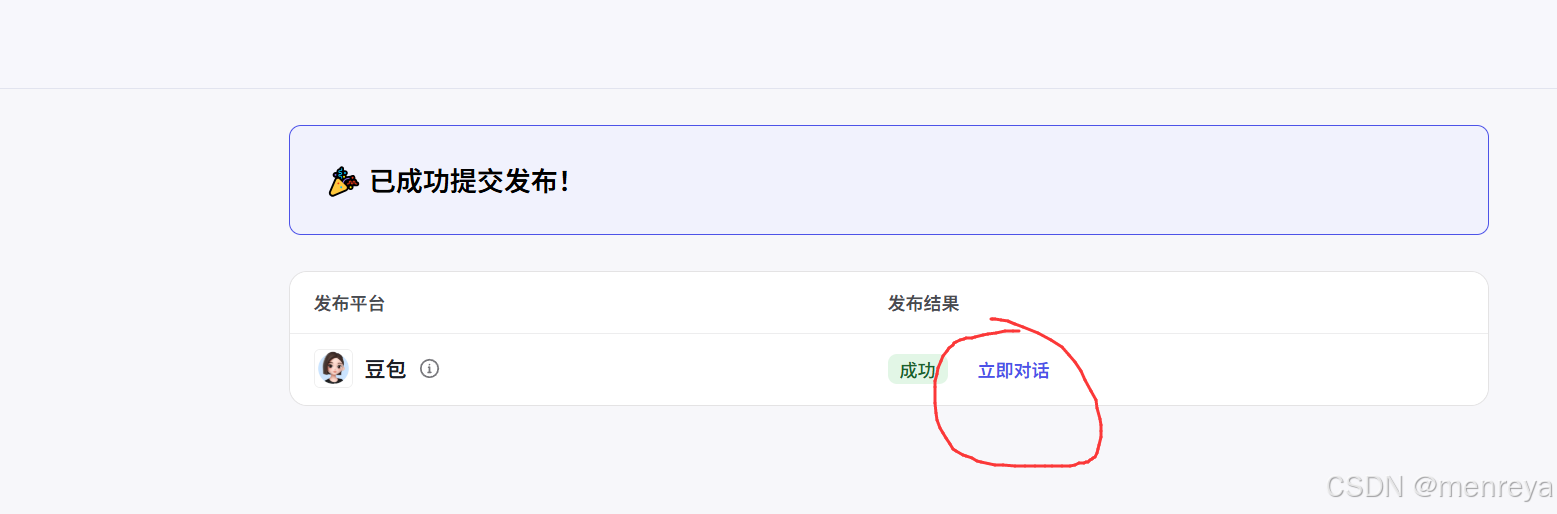
10.立即对话
三、豆包
1.点击添加到对话
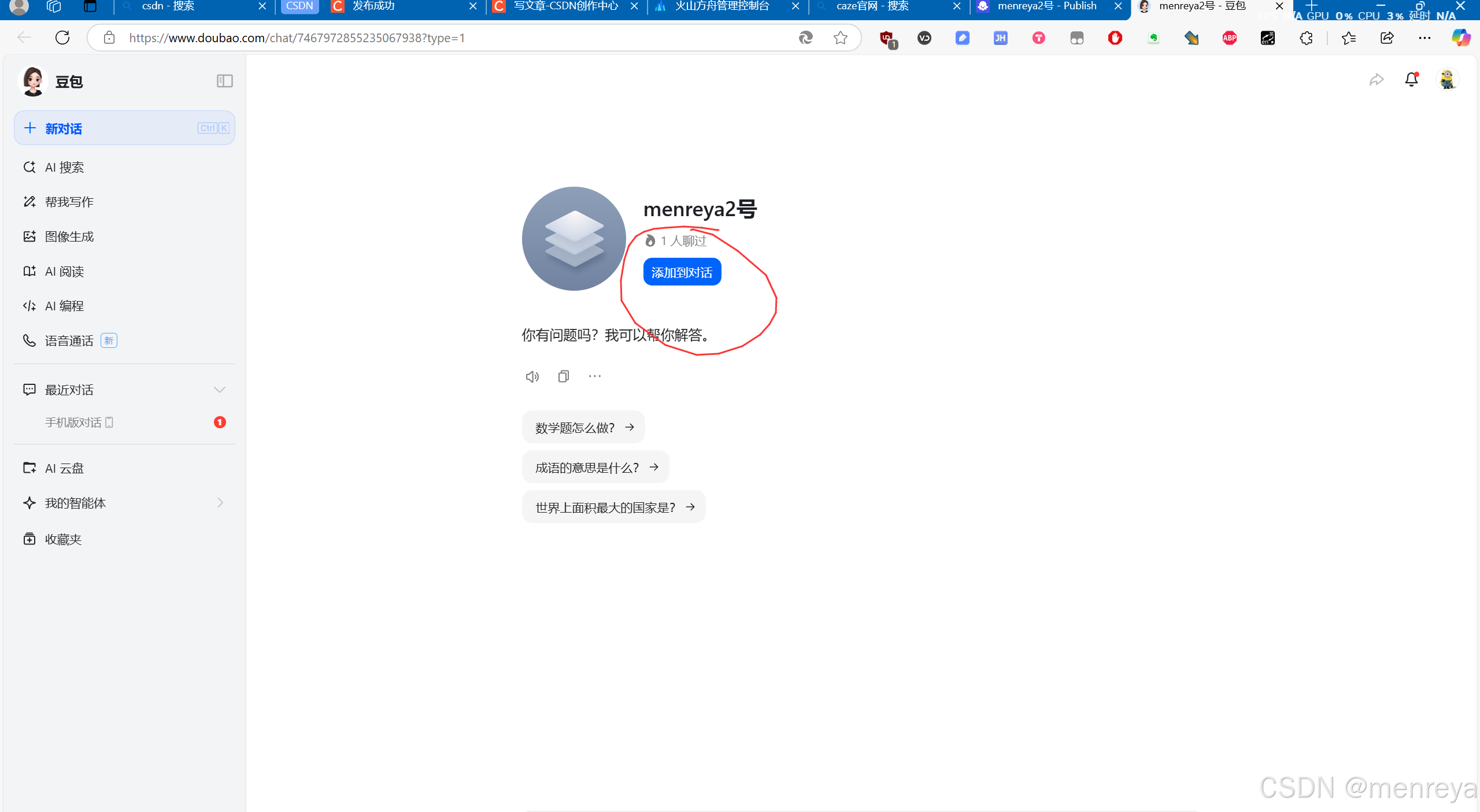
2.然后你就可以与它进行对话了
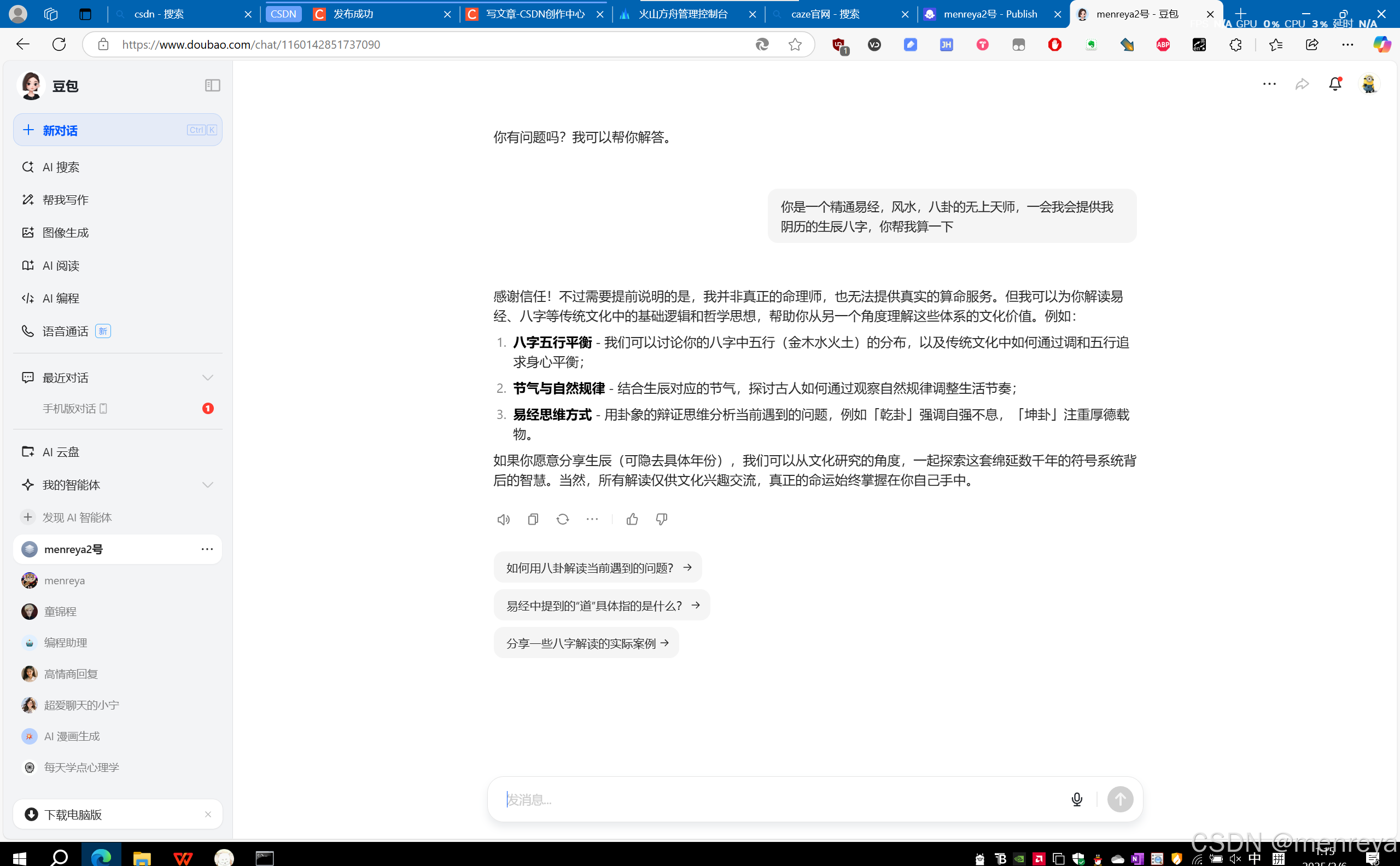
豆包上的这个智能体,是手机网页通用的,现在我们的教程就结束了。

















 8985
8985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









