




前言:跨境电商数据采集痛点与需求
随着跨境电商、数据驱动决策以及AI模型训练的需求不断增长,开发者与企业需要稳定、合规、可规模化 的网页数据抓取方案。但实际落地往往困难重重:高强度抓取、IP无法访问、JS渲染、数据格式不统一,这些让数据采集的技术门槛与成本居高不下。本篇将带你实操IPIDEA网页抓取API,并构建一个 可直接投入使用的eBay商品信息采集工具,一步步完成抓取、解析到下载的全过程,帮助你快速掌握全球电商数据采集的核心方法。
为什么需要网页抓取API
在跨境电商运营、市场竞品调研、AI模型训练等核心业务场景中,企业与开发者往往需要获取公开的电商商品信息、竞品动态等关键数据,但直接开展数据采集工作会面临三大核心痛点:
抓取门槛居高不下:Amazon、eBay等主流平台普遍部署了验证码校验、IP访问管理、JS动态渲染等多重抓取机制,若自研抓取系统,不仅需要持续投入人力进行技术突破与迭代,还会面临采集稳定性差、数据获取中断等问题,综合成本居高不下
合规风险难以规避:未经合规授权的公开数据采集行为,容易触碰GDPR、CCPA等国际数据合规法规;同时普通代理IP无法满足 “真实住宅IP + 合规访问链路” 的合规采集要求,进一步放大了业务的风险
效率与成本严重失衡:自研采集工具需同步兼顾多平台适配、原始数据清洗、多格式转换等全流程工作,这对中小团队而言,开发与长期维护的成本难以承担;且自研方案的单条数据采集耗时较长,往往超出业务对数据时效性的容忍阈值
IPIDEA网页抓取API可精准化解数据采集三大痛点:依托全球合规IP资源,能稳定适配主流平台访问防护要求;全链路符合国际数据法规,从根源规避合规风险;同时托管代理管理、数据解析等复杂流程,以按成功结果计费模式降低成本,实现高效低成本的数据采集。
IPIDEA网页抓取API核心功能与优势
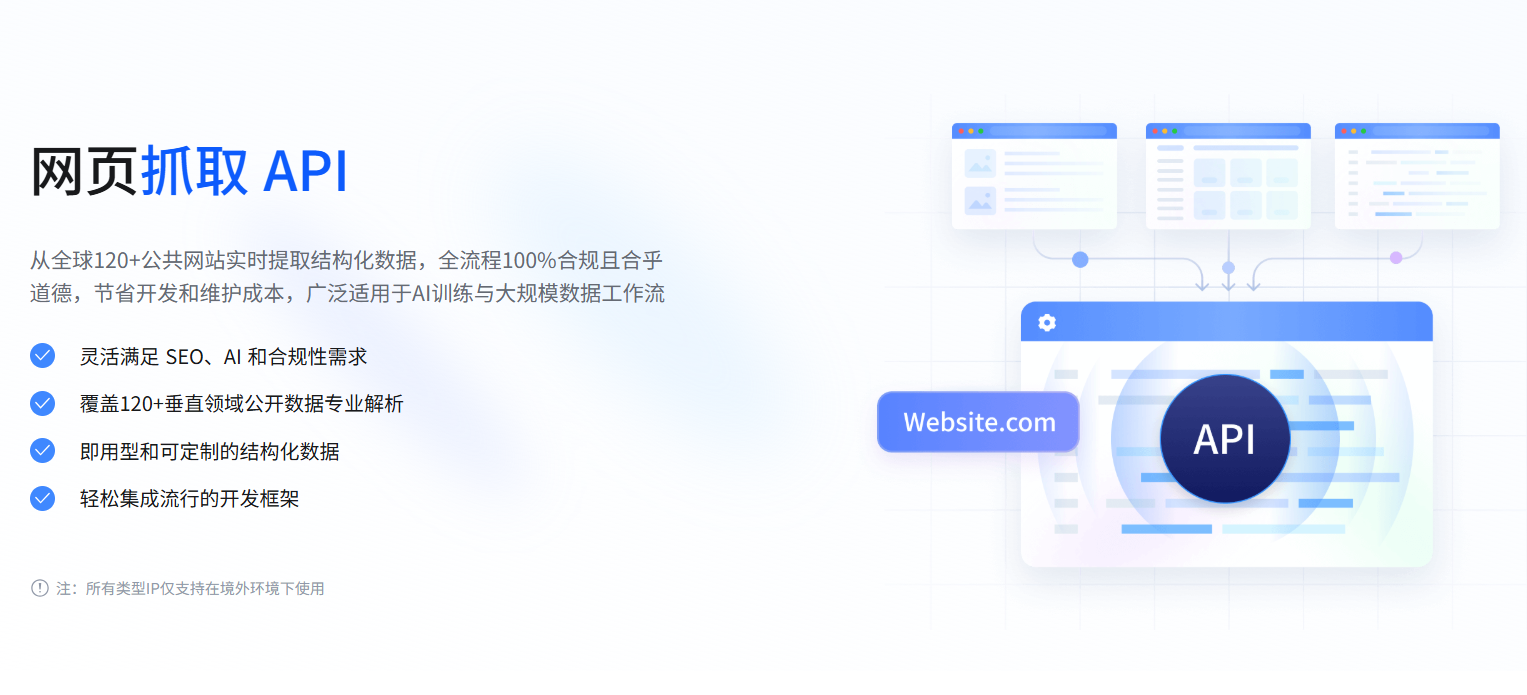
IPIDEA的网页抓取API是一款面向企业及开发者的数据采集工具,依托覆盖全球 220 多个国家和地区的1亿多个合规住宅IP,可从120+垂直领域公共网站实时提取结构化数据,全流程符合GDPR、CCPA等国际法规;该工具具备ML驱动代理轮换、自动验证跳过、JS渲染、自定义解析器、定时调度等能力,支持JSON、CSV、XLSX等多格式输出,能一行代码接入主流开发框架且可无缝集成ChatGPT、LangChain等 AI 平台;其采用仅对成功结果计费的模式,提供多档位积分套餐与专属定制服务,配套7×24小时技术支持,可低门槛、高稳定地满足AI模型训练、电商竞品监控、SEO监测、社媒舆情分析等多场景的大规模数据采集需求。
- 合规化采集:依托全球220多个国家和地区的1 亿 +合规住宅IP,全流程符合GDPR、CCPA等,从根源规避数据采集风险
- 智能化抓取适配:具备 ML 驱动代理交换、自动验证码处理、JS动态渲染等核心能力,可高效适配各类高防护网站,保障大规模数据采集的稳定性与持续性
- 低成本集成:支持JSON、CSV、XLSX等多格式输出,能一行代码接入主流开发框架并无缝对接ChatGPT等AI平台,同时采用仅对成功结果计费的模式,大幅降低技术落地与数据获取成本
前提准备:注册与配置IPIDEA
这次登录IPIDEA官网我发现界面版本更新了,左边是旧界面,右边是新版本界面可以看出来,新版本界面非常简洁,将功能按代理产品抓取方案分类整合,还把产品特点、价格等核心信息分层突出展示,同时新增智能推荐等快捷入口,视觉更清爽,也缩短了操作路径
实战案例:使用IPIDEA网页抓取API抓取eBay商品信息
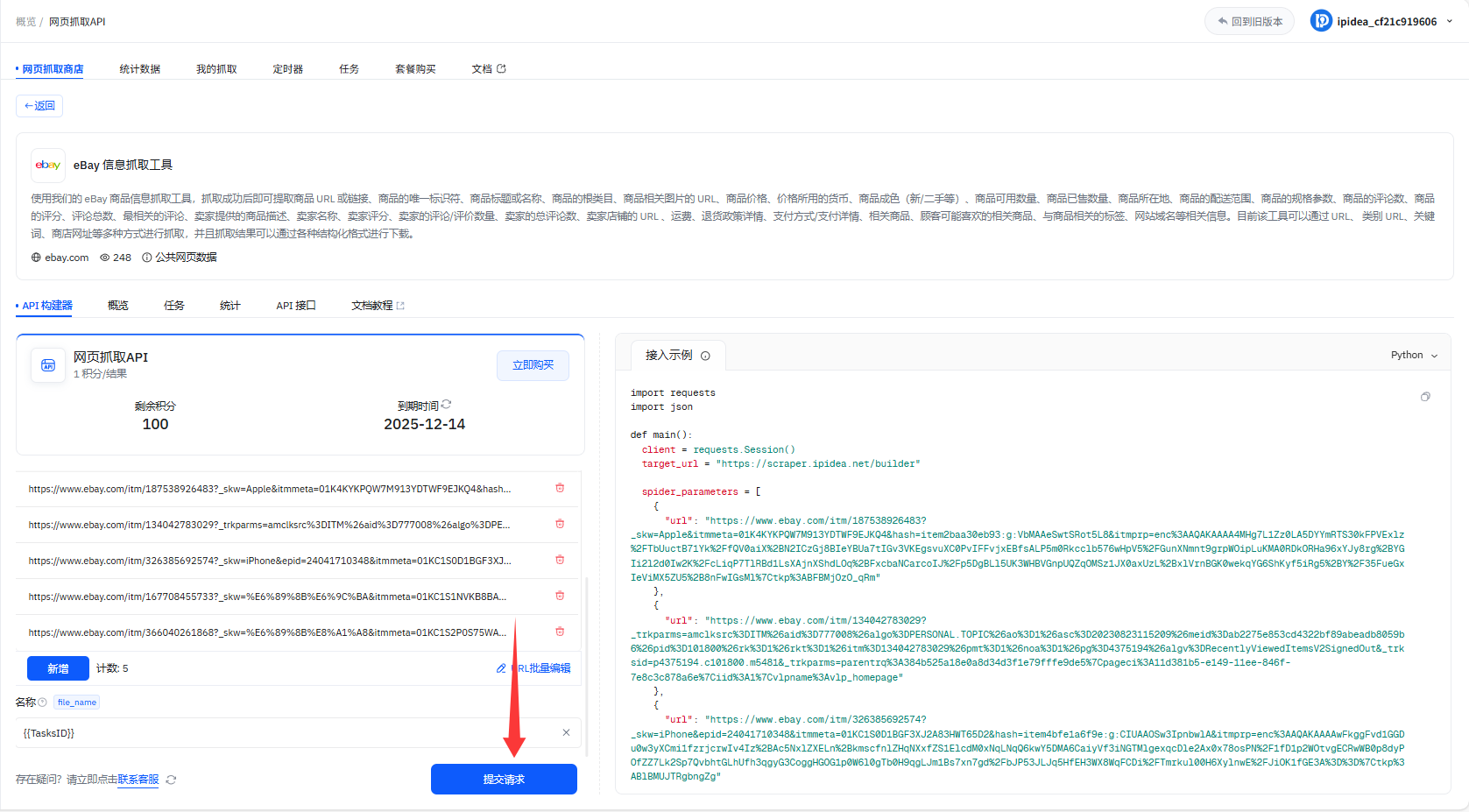
1、左侧找到网页抓取API,选择eBay信息抓取工具
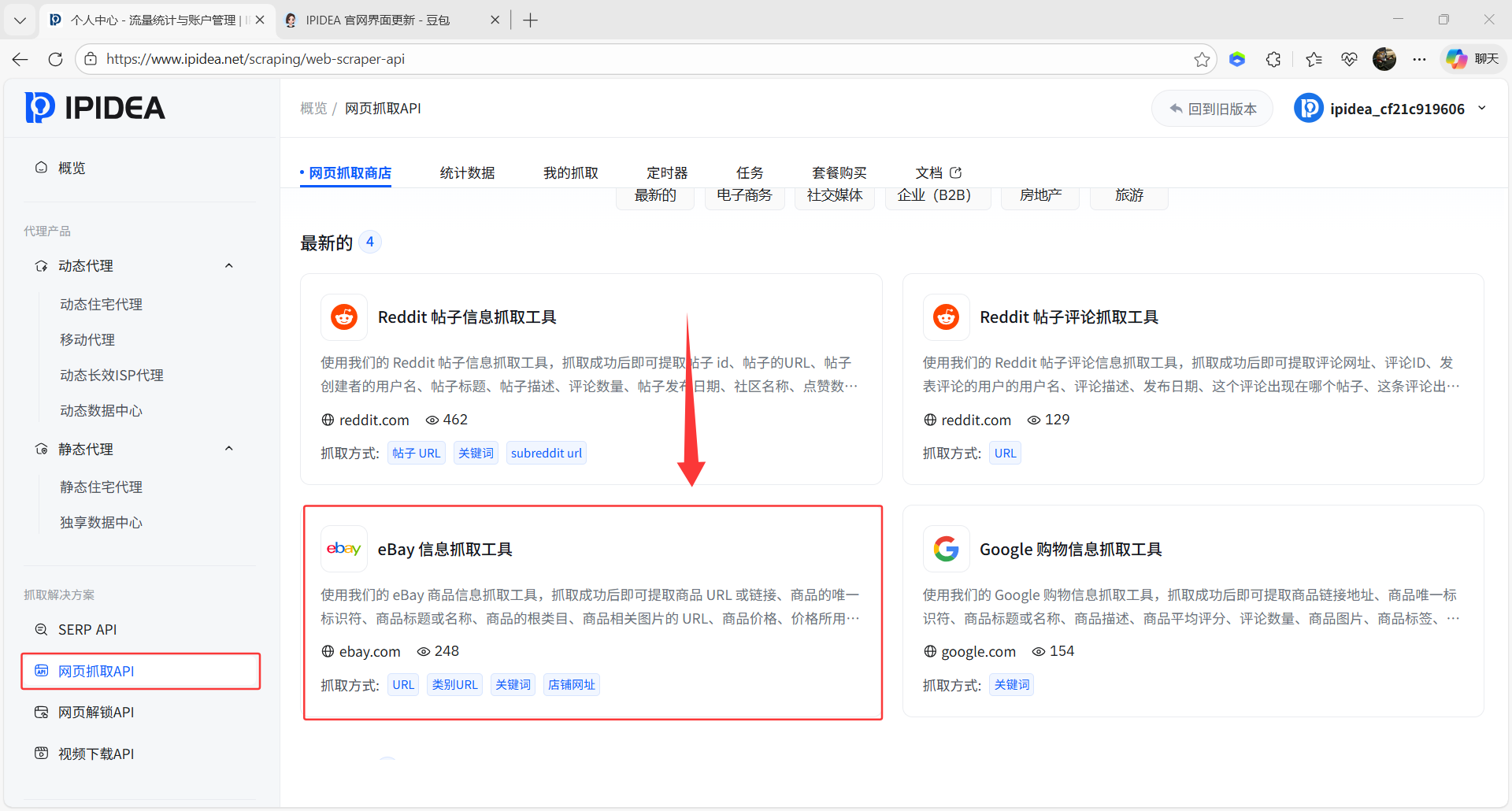
2、如下是eBay抓取工具的关键配置项:Token是抓取通行证,抓取方式选抓信息的形式,eBay URL填目标商品链接,名称则是给结果文件命名
3、Token:这是你用工具抓取信息的通行证,没它没法启动抓取,是必须填对的关键码
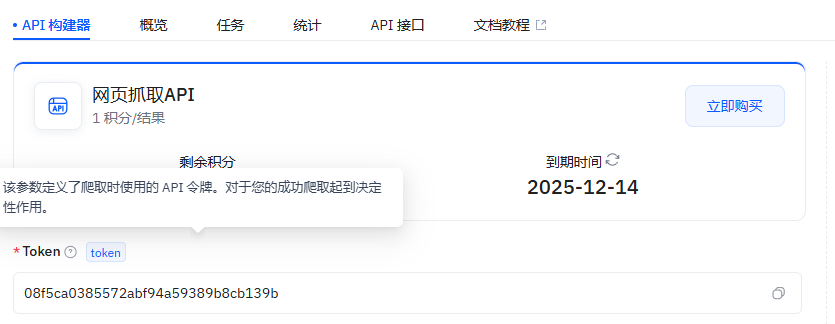
4、抓取方式:就是选你想用啥形式来抓信息比如按链接、按关键词这些,点选对应的方式就行
5、eBay URL:把你要抓的那个eBay商品链接复制到这,工具就知道要去扒哪个商品的信息了
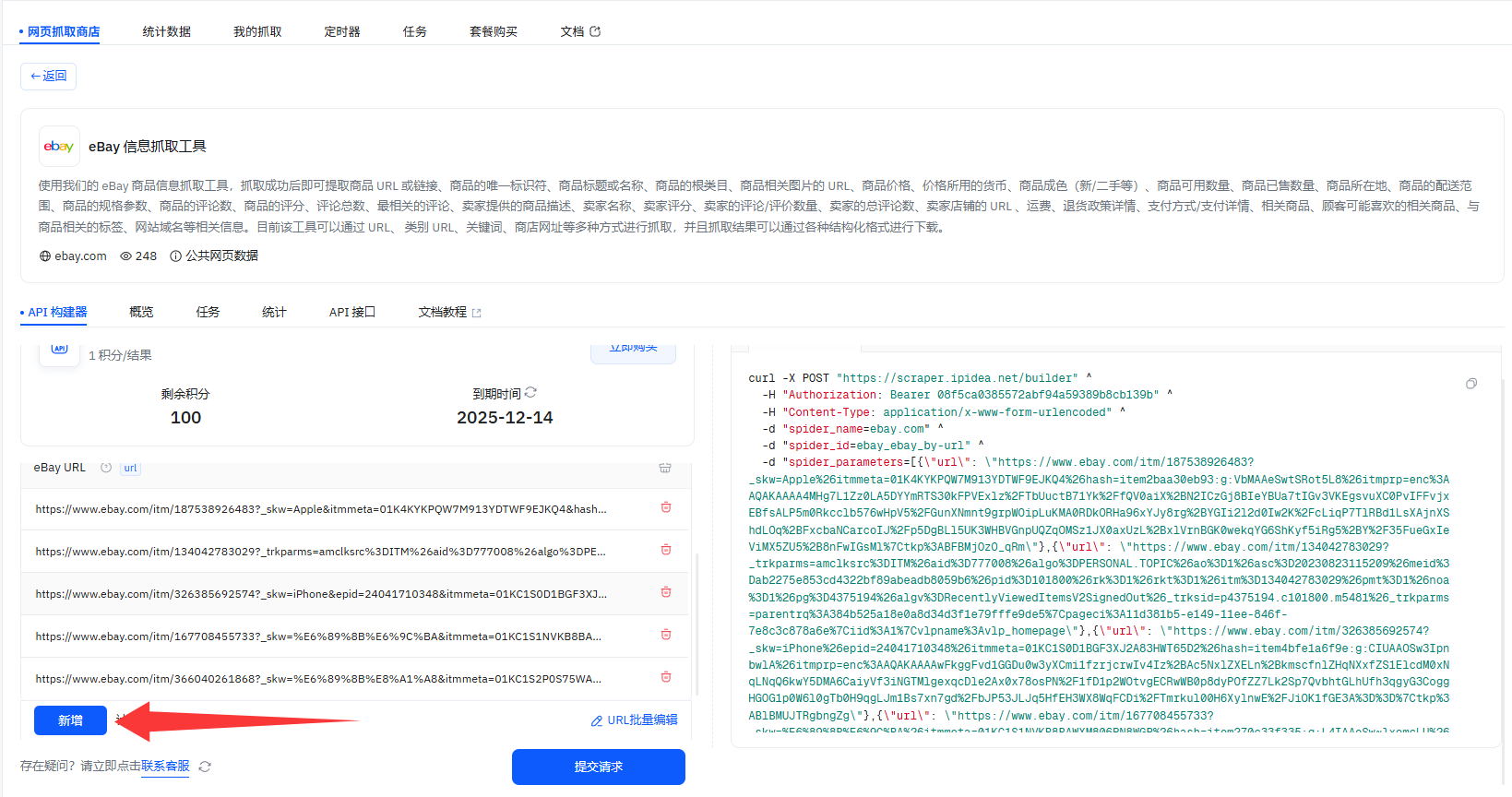
6、名称:给抓到的结果文件起个名,不同平台有默认规则,比如Amazon的内容,默认用任务 ID 当文件名;抓YouTube的,默认用视频ID当文件名
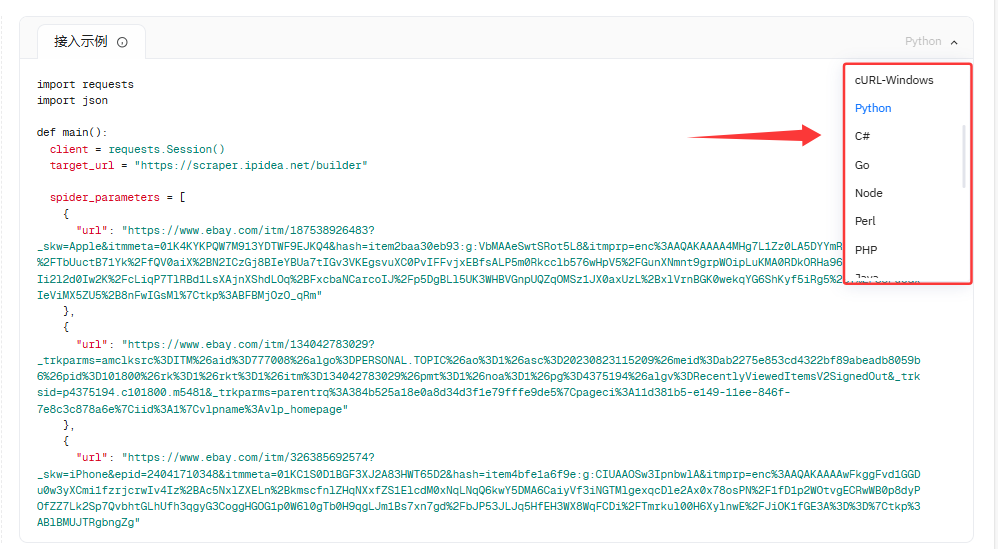
7、左侧配置好参数后,就能选对应的示例代码来接入工具了,支持的类型有这些(此处我选择的是Python,我一般Python抓取比较多,大家根据自己的合适选择即可)
- 系统环境类:cURL-Linux、cURL-Windows
- 编程语言类:Python、C#、Go、Node、Perl、PHP、Java、Ruby
import requests
import json
def main():
client = requests.Session()
target_url = "https://scraper.ipidea.net/builder"
spider_parameters = [
{
"url": "https://www.ebay.com/itm/187538926483?_skw=Apple&itmmeta=01K4KYKPQW7M913YDTWF9EJKQ4&hash=item2baa30eb93:g:VbMAAeSwtSRot5L8&itmprp=enc%3AAQAKAAAA4MHg7L1Zz0LA5DYYmRTS30kFPVExlz%2FTbUuctB71Yk%2FfQV0aiX%2BN2ICzGj8BIeYBUa7tIGv3VKEgsvuXC0PvIFFvjxEBfsALP5m0Rkcclb576wHpV5%2FGunXNmnt9grpWOipLuKMA0RDkORHa96xYJy8rg%2BYGIi2l2d0Iw2K%2FcLiqP7TlRBd1LsXAjnXShdLOq%2BFxcbaNCarcoIJ%2Fp5DgBLl5UK3WHBVGnpUQZqOMSz1JX0axUzL%2BxlVrnBGK0wekqYG6ShKyf5iRg5%2BY%2F35FueGxIeViMX5ZU5%2B8nFwIGsMl%7Ctkp%3ABFBMjOzO_qRm"
},
{
"url": "https://www.ebay.com/itm/134042783029?_trkparms=amclksrc%3DITM%26aid%3D777008%26algo%3DPERSONAL.TOPIC%26ao%3D1%26asc%3D20230823115209%26meid%3Dab2275e853cd4322bf89abeadb8059b6%26pid%3D101800%26rk%3D1%26rkt%3D1%26itm%3D134042783029%26pmt%3D1%26noa%3D1%26pg%3D4375194%26algv%3DRecentlyViewedItemsV2SignedOut&_trksid=p4375194.c101800.m5481&_trkparms=parentrq%3A384b525a18e0a8d34d3f1e79fffe9de5%7Cpageci%3A11d381b5-e149-11ee-846f-7e8c3c878a6e%7Ciid%3A1%7Cvlpname%3Avlp_homepage"
},
{
"url": "https://www.ebay.com/itm/326385692574?_skw=iPhone&epid=24041710348&itmmeta=01KC1S0D1BGF3XJ2A83HWT65D2&hash=item4bfe1a6f9e:g:CIUAAOSw3IpnbwlA&itmprp=enc%3AAQAKAAAAwFkggFvd1GGDu0w3yXCmi1fzrjcrwIv4Iz%2BAc5NxlZXELn%2BkmscfnlZHqNXxfZS1ElcdM0xNqLNqQ6kwY5DMA6CaiyVf3iNGTMlgexqcDle2Ax0x78osPN%2F1fD1p2WOtvgECRwWB0p8dyPOfZZ7Lk2Sp7QvbhtGLhUfh3qgyG3CoggHGOG1p0W6l0gTb0H9qgLJm1Bs7xn7gd%2FbJP53JLJq5HfEH3WX8WqFCDi%2FTmrkul00H6XylnwE%2FJiOK1fGE3A%3D%3D%7Ctkp%3ABlBMUJTRgbngZg"
},
{
"url": "https://www.ebay.com/itm/167708455733?_skw=%E6%89%8B%E6%9C%BA&itmmeta=01KC1S1NVKB8BAWXM806PN8WGP&hash=item270c33f335:g:L4IAAeSw~lxomcLU&itmprp=enc%3AAQAKAAAA4FkggFvd1GGDu0w3yXCmi1dXhMyPzT94WKoVVKtBam3Gz%2B7sXC4f0Uepi4oSviIEWY6yCAp5suO6yAt8tnwvdzsdLN%2FmH3bPS7TdRAufmVWkmQgZV5ZeETuSRIUw9Cfd%2FNG8ixw2LB22vH3jCmIQkDiJ3O23sYnWyCQ6SChQXRZpC1%2Fr8oSu3b7P1hJZWC7FISa0RJoUR6DkF7DHRKQt4cdxVTgRJiWzNzTSxF2HR2jMFBCqYw%2FS%2B5DqDAdU3e4ivLu6XCu9M7rHWOa%2B2I0U0pmEmB%2B62EHJIK9o5213wtM7%7Ctkp%3ABFBM_N2GueBm"
},
{
"url": "https://www.ebay.com/itm/366040261868?_skw=%E6%89%8B%E8%A1%A8&itmmeta=01KC1S2P0S75WAQMT0D4N110ZA&hash=item5539b324ec:g:eSIAAeSw79Jo2jp~&itmprp=enc%3AAQAKAAAAwFkggFvd1GGDu0w3yXCmi1dINrxh%2BCoy0q58AorXep7huCMnTJ0Dx4wv8jcQJ8UTZTM8j2gRw4j4RDWurrG%2FrtoNL2P57qa8Mm9yzz80KoQnxXr93mXt0HIQ9MjD6g5Y99Ivz%2FMe2QH140m%2Fzv2s4%2BhVIa82np%2FJxdyO7KBUN4zJSh564Qi8lkuI15RHookxuV9EtUas4v8ttAmeK8%2F4fOOcoNXNC7HH3YLpq1IxL95vYU%2FoNhwlFXTF1auaTMFIyw%3D%3D%7Ctkp%3ABk9SR8jgirngZg"
}
]
spider_parameters_json = json.dumps(spider_parameters)
form_data = {
"spider_name": "ebay.com",
"spider_id": "ebay_ebay_by-url",
"spider_parameters": spider_parameters_json,
"spider_errors": "true",
"file_name": "{{TasksID}}"
}
headers = {
"Authorization": "Bearer 08f5ca0385572abf94a59389b8cb139b",
"Content-Type": "application/x-www-form-urlencoded"
}
try:
resp = client.post(target_url, data=form_data, headers=headers)
resp.raise_for_status() # Raises an HTTPError for bad responses
print(f"Status Code: {resp.status_code}")
print(f"Response Body: {resp.text}")
except requests.exceptions.RequestException as e:
print(f"Error sending request: {e}")
if __name__ == "__main__":
main()
8、提交请求
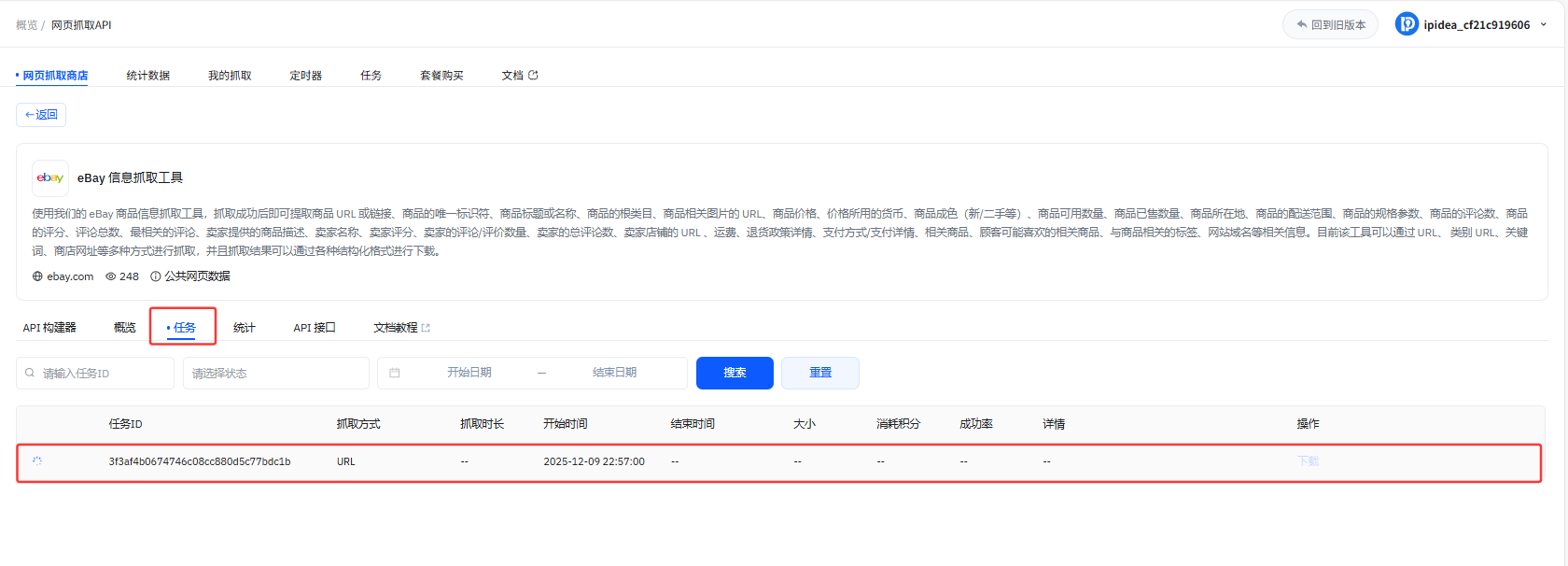
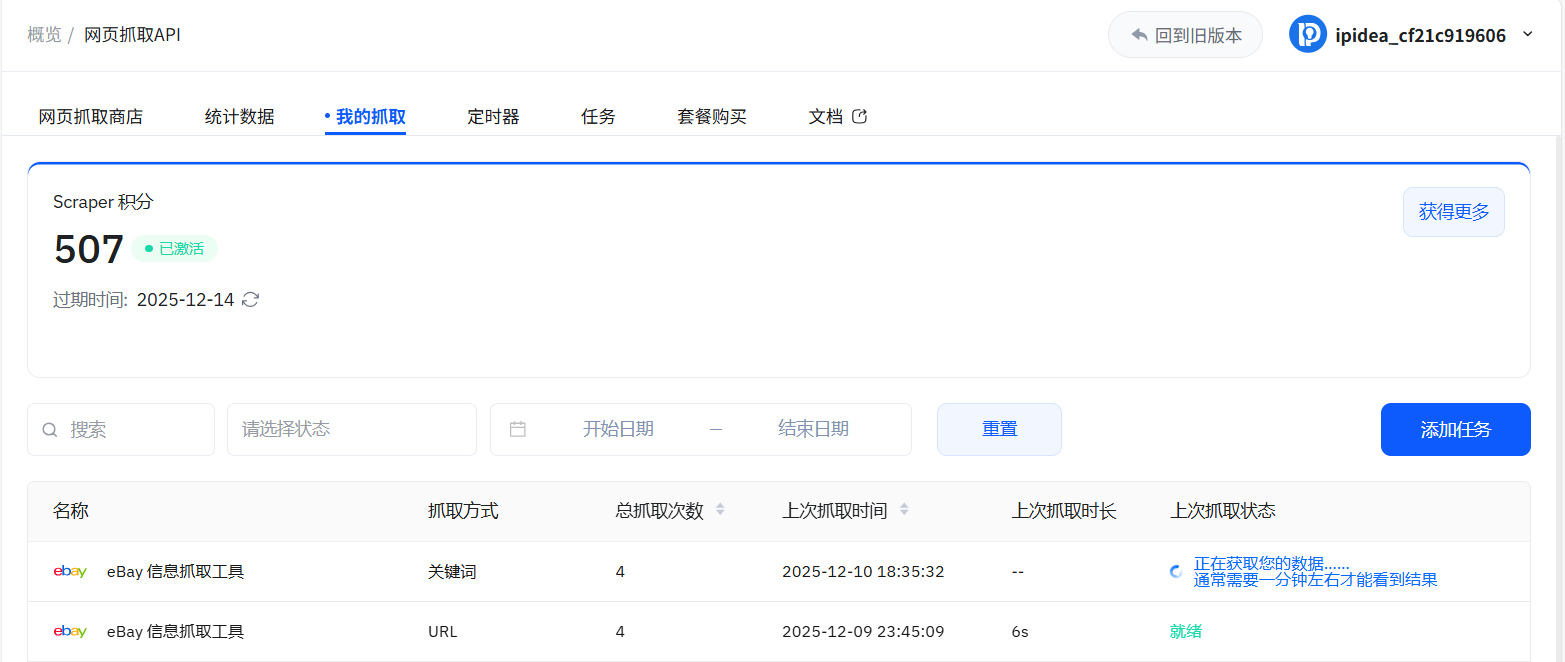
9、任务中可以查看抓取任务
10、抓取成功后,可选择多种结构化格式下载数据,支持JSON、CSV、XLSX三种文件类型
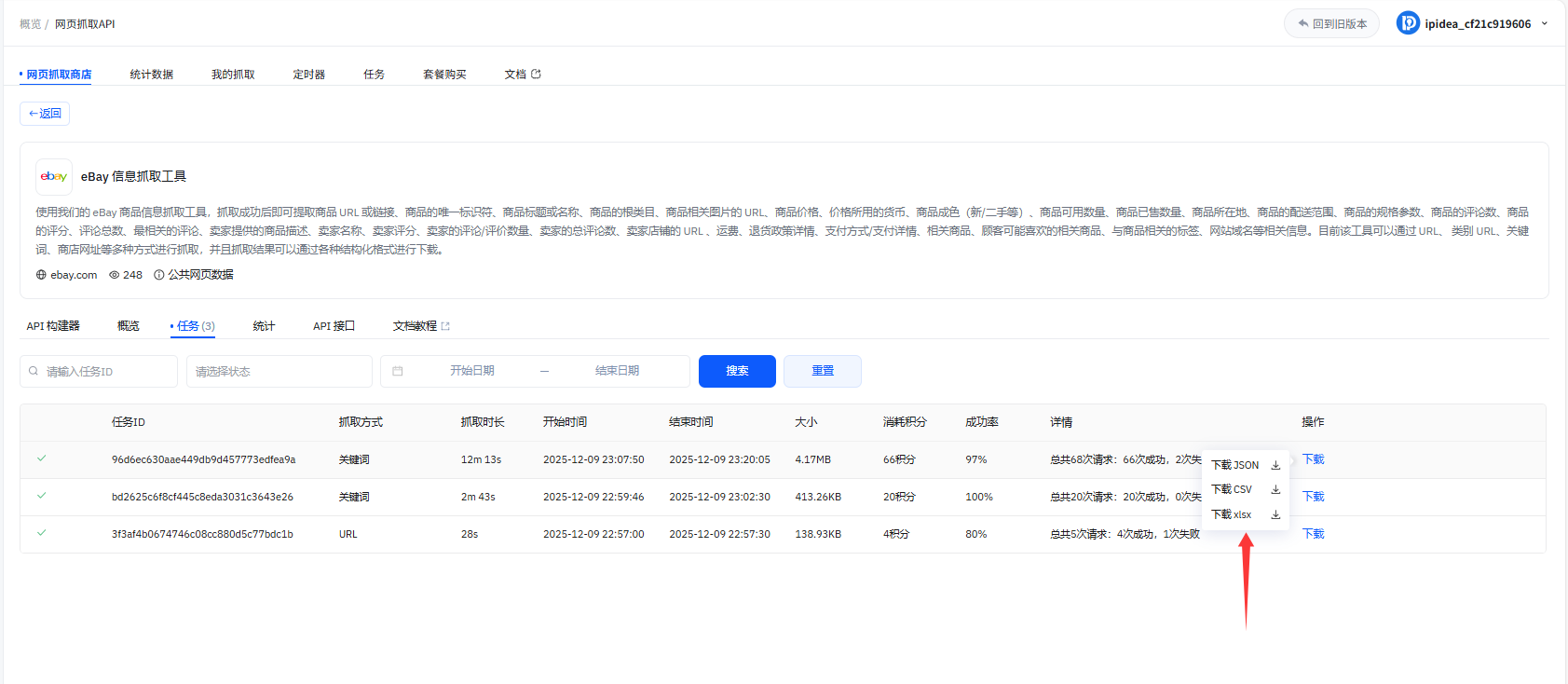
11、下载XLSX类型可以获取抓取后的数据
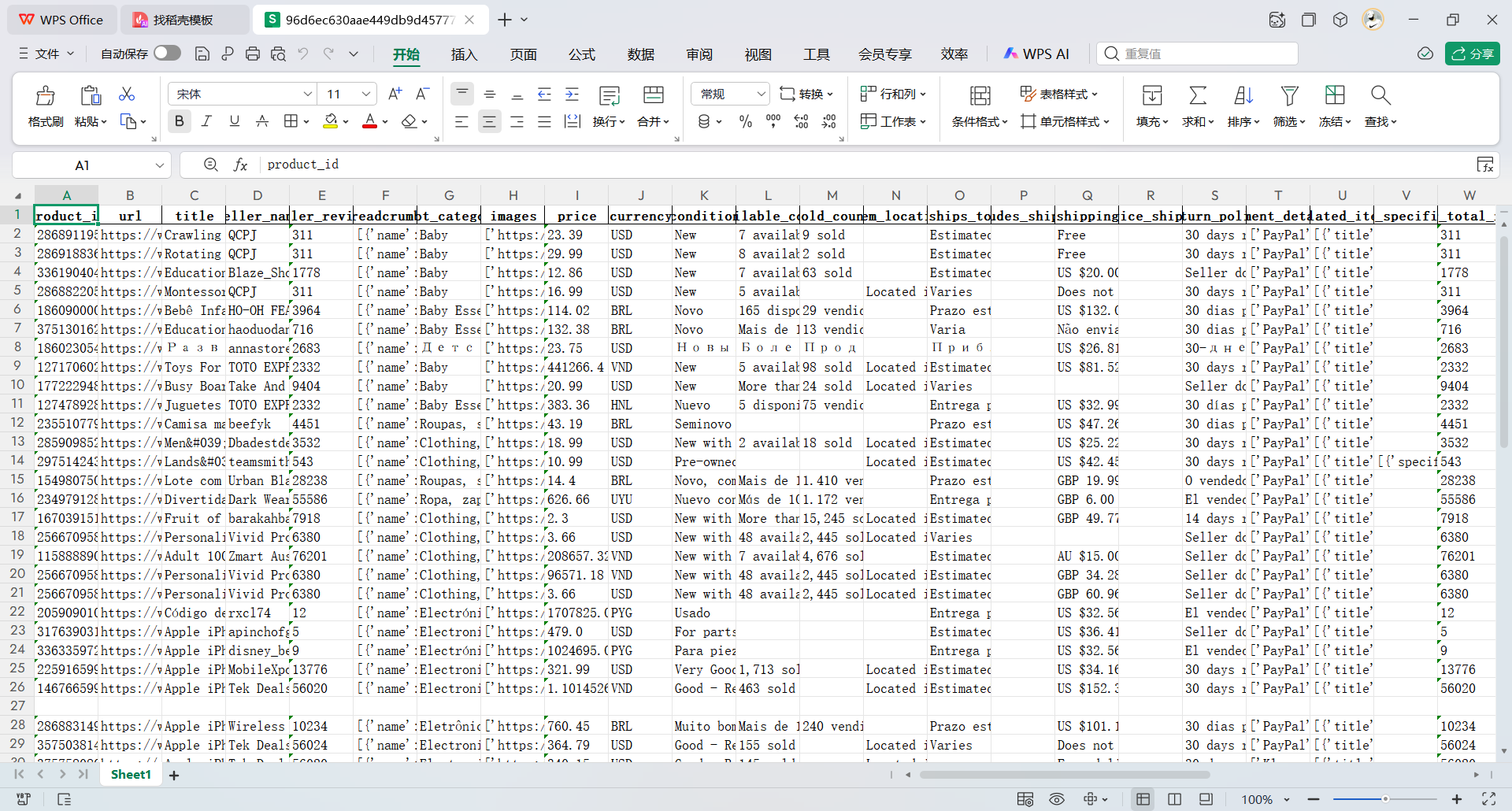
12、统计数据面板可以可视化看到积分消耗情况
13、另外支持创建定时任务(设置自动抓取的规则,先给任务命名并开启功能,再通过分钟、每小时、每日等周期选项设置重复频率,指定开始时间,还能选择关联的抓取API工具,配置完成后点确定,就能自动周期性执行抓取任务)
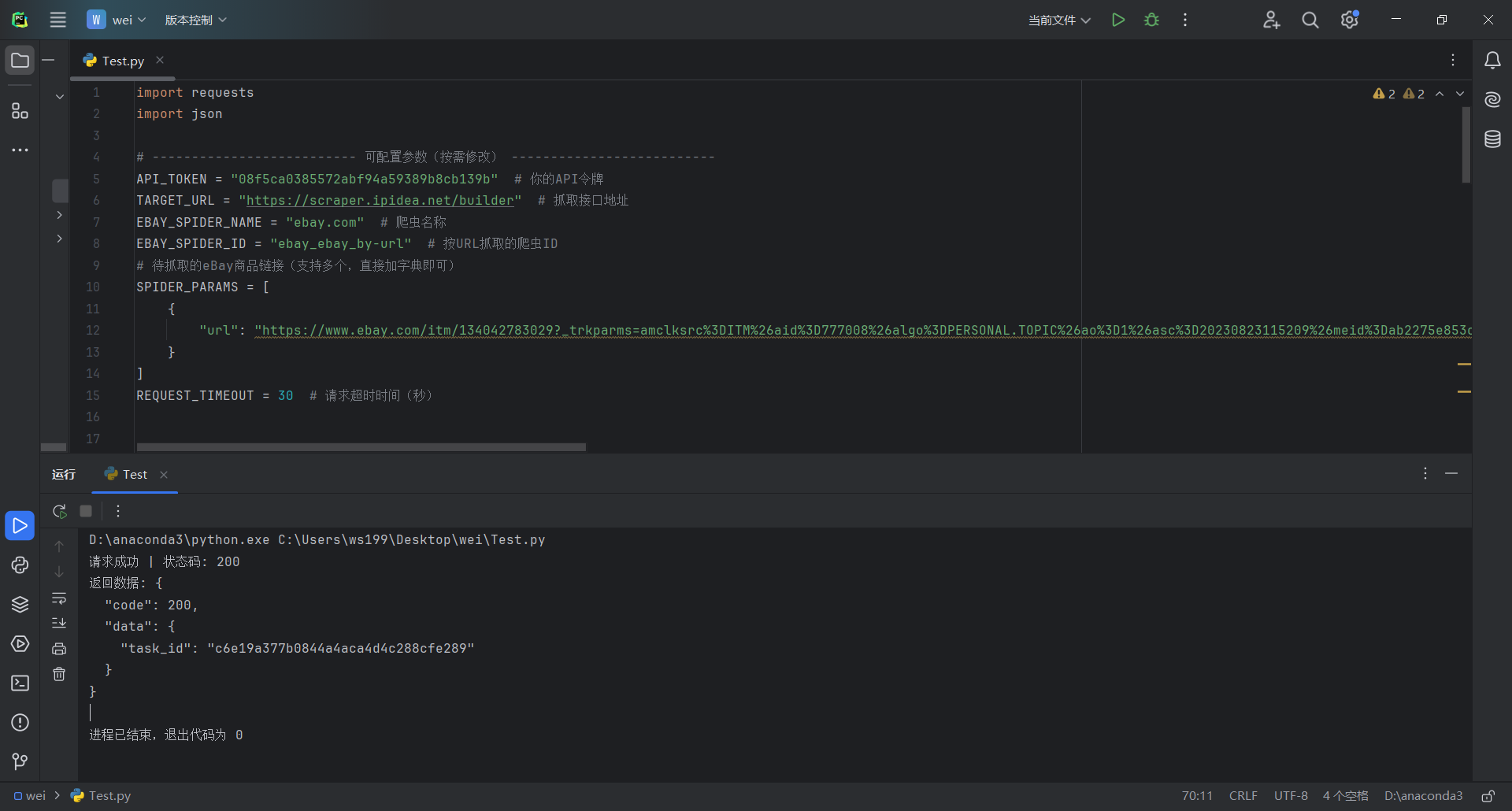
14、另外我使用本地Pycharm调用接口示例来进行抓取任务(这段Python代码基于requests库调用IPIDEA的eBay抓取API,可配置API令牌、目标链接等参数,通过POST请求提交按URL抓取eBay商品的任务,设置30秒请求超时,同时细化捕获HTTP错误、超时、JSON解析等异常,成功请求后解析并打印JSON格式的接口返回数据)
import requests
import json
# -------------------------- 可配置参数(按需修改) --------------------------
API_TOKEN = "08f5ca0385572abf94a59389b8cb139b" # 你的API令牌
TARGET_URL = "https://scraper.ipidea.net/builder" # 抓取接口地址
EBAY_SPIDER_NAME = "ebay.com" # 名称
EBAY_SPIDER_ID = "ebay_ebay_by-url" # 按URL抓取的ID
# 待抓取的eBay商品链接(支持多个,直接加字典即可)
SPIDER_PARAMS = [
{
"url": "https://www.ebay.com/itm/134042783029?_trkparms=amclksrc%3DITM%26aid%3D777008%26algo%3DPERSONAL.TOPIC%26ao%3D1%26asc%3D20230823115209%26meid%3Dab2275e853cd4322bf89abeadb8059b6%26pid%3D101800%26rk%3D1%26rkt%3D1%26itm%3D134042783029%26pmt%3D1%26noa%3D1%26pg%3D4375194%26algv%3DRecentlyViewedItemsV2SignedOut&_trksid=p4375194.c101800.m5481&_trkparms=parentrq%3A384b525a18e0a8d34d3f1e79fffe9de5%7Cpageci%3A11d381b5-e149-11ee-846f-7e8c3c878a6e%7Ciid%3A1%7Cvlpname%3Avlp_homepage"
}
]
REQUEST_TIMEOUT = 30 # 请求超时时间(秒)
# ---------------------------------------------------------------------------
def main():
# 初始化会话(复用连接,提升效率)
client = requests.Session()
# 构造请求参数
form_data = {
"spider_name": EBAY_SPIDER_NAME,
"spider_id": EBAY_SPIDER_ID,
"spider_parameters": json.dumps(SPIDER_PARAMS, ensure_ascii=False),
"spider_errors": "true",
"file_name": "{{TasksID}}"
}
# 请求头(Bearer认证)
headers = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/x-www-form-urlencoded"
}
try:
# 发送POST请求(加超时)
resp = client.post(
url=TARGET_URL,
data=form_data,
headers=headers,
timeout=REQUEST_TIMEOUT
)
resp.raise_for_status() # 触发HTTP错误(4xx/5xx)
# 解析JSON响应(API返回一般为JSON)
resp_json = resp.json()
print(f"请求成功 | 状态码: {resp.status_code}")
print(f"返回数据: {json.dumps(resp_json, indent=2, ensure_ascii=False)}")
# 捕获HTTP请求错误(如401令牌无效、404接口不存在等)
except requests.exceptions.HTTPError as e:
print(f"HTTP请求错误: {e}")
print(f"错误响应内容: {resp.text if 'resp' in locals() else '无'}")
# 捕获超时错误
except requests.exceptions.Timeout:
print(f"请求超时(超过{REQUEST_TIMEOUT}秒),请检查网络或接口状态")
# 捕获JSON解析错误
except json.JSONDecodeError:
print(f"接口返回非JSON格式,原始内容: {resp.text}")
# 其他请求异常(如网络不通、域名错误等)
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
if __name__ == "__main__":
main()
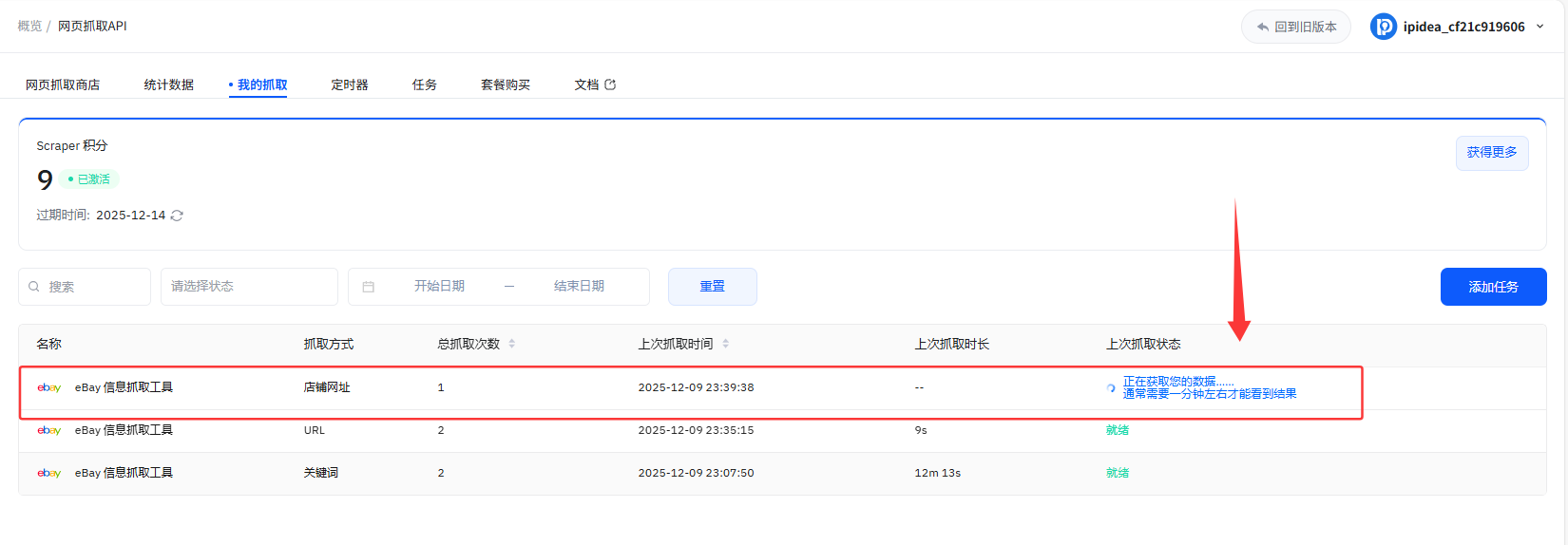
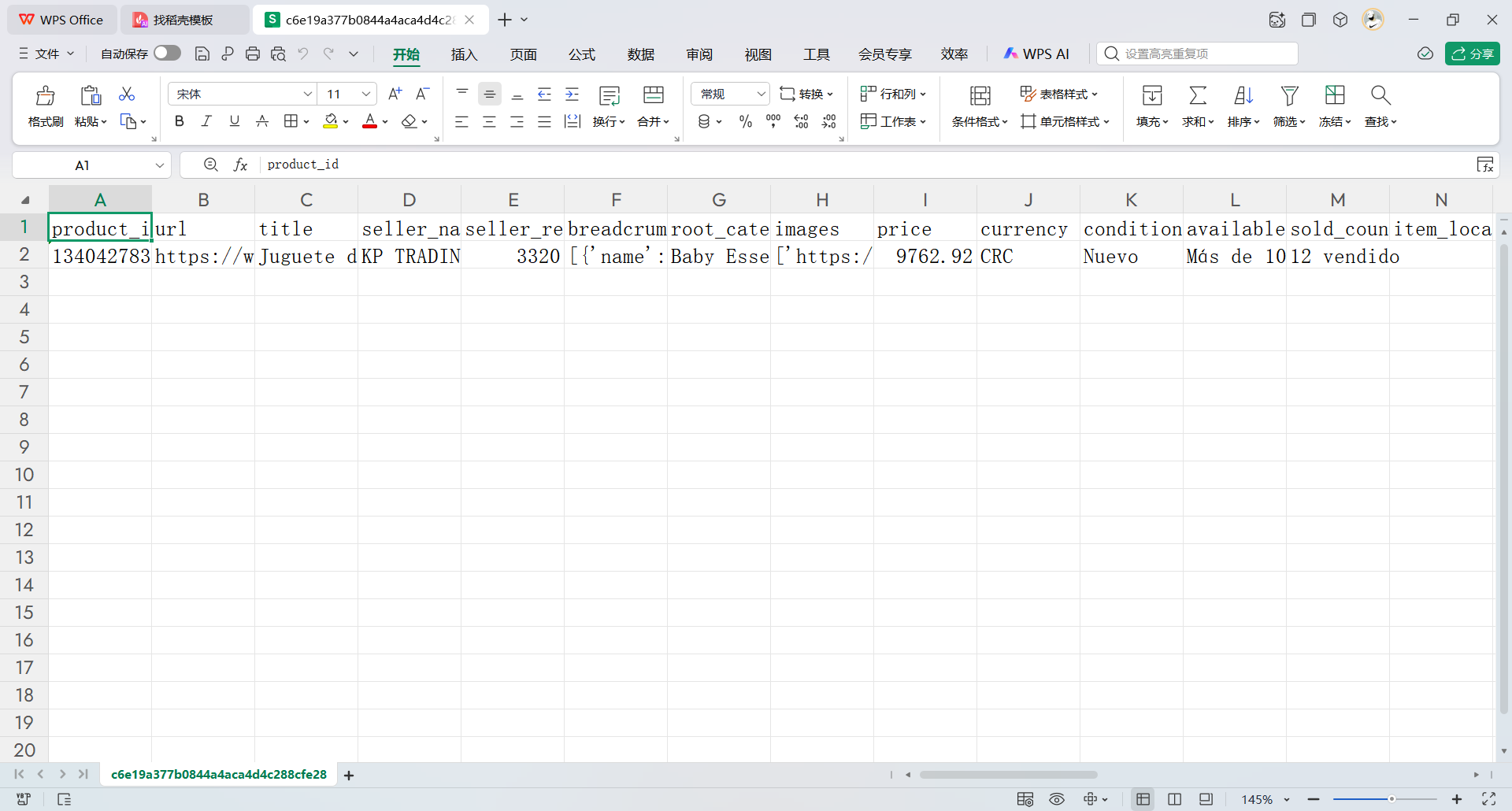
如下是按照店铺网址抓取,抓取的一条数据
IPIDEA助力电商类目数据抓取:eBay耳机数据案例分析
1、抓取方式选择关键词
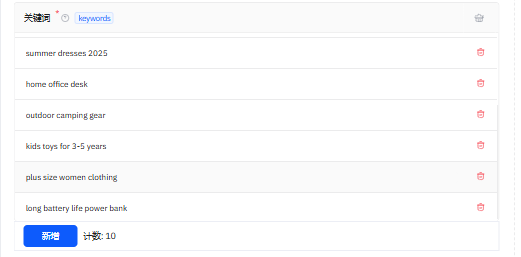
2、添加抓取关键词(关键词覆盖数码、美妆、服饰等多电商类目,含时效2025趋势款、人群3-5岁玩具、功能长续航充电宝标签,可支撑跨品类趋势、细分人群偏好、商品卖点的核心电商数据分析)
3、接入示例代码复制,用本地Pycharm运行
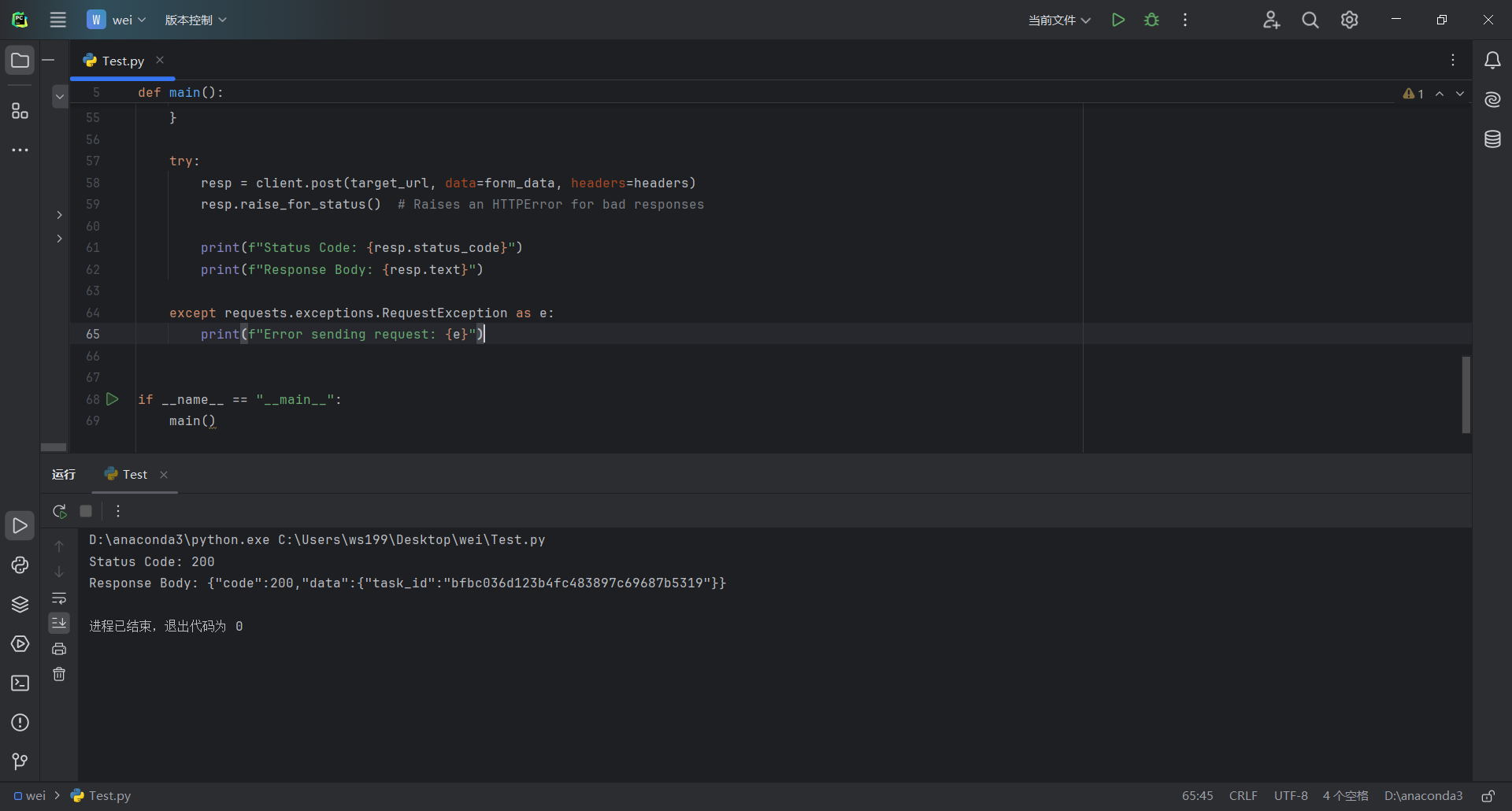
4、Pycharm运行执行代码
import requests
import json
def main():
client = requests.Session()
target_url = "https://scraper.ipidea.net/builder"
spider_parameters = [
{
"keywords": "wireless headphones"
},
{
"keywords": "laptop accessories"
},
{
"keywords": "skincare set"
},
{
"keywords": "2025 trending gadgets"
},
{
"keywords": "summer dresses 2025"
},
{
"keywords": "home office desk"
},
{
"keywords": "outdoor camping gear"
},
{
"keywords": "kids toys for 3-5 years"
},
{
"keywords": "plus size women clothing"
},
{
"keywords": "long battery life power bank"
}
]
spider_parameters_json = json.dumps(spider_parameters)
form_data = {
"spider_name": "ebay.com",
"spider_id": "ebay_ebay_by-keywords",
"spider_parameters": spider_parameters_json,
"spider_errors": "true",
"file_name": "{{TasksID}}"
}
headers = {
"Authorization": "Bearer 08f5ca0385572abf94a59389b8cb139b",
"Content-Type": "application/x-www-form-urlencoded"
}
try:
resp = client.post(target_url, data=form_data, headers=headers)
resp.raise_for_status() # Raises an HTTPError for bad responses
print(f"Status Code: {resp.status_code}")
print(f"Response Body: {resp.text}")
except requests.exceptions.RequestException as e:
print(f"Error sending request: {e}")
if __name__ == "__main__":
main()
5、查看IPIDEA抓取后台任务是否运行,等待加载完成就可以下载抓取的数据
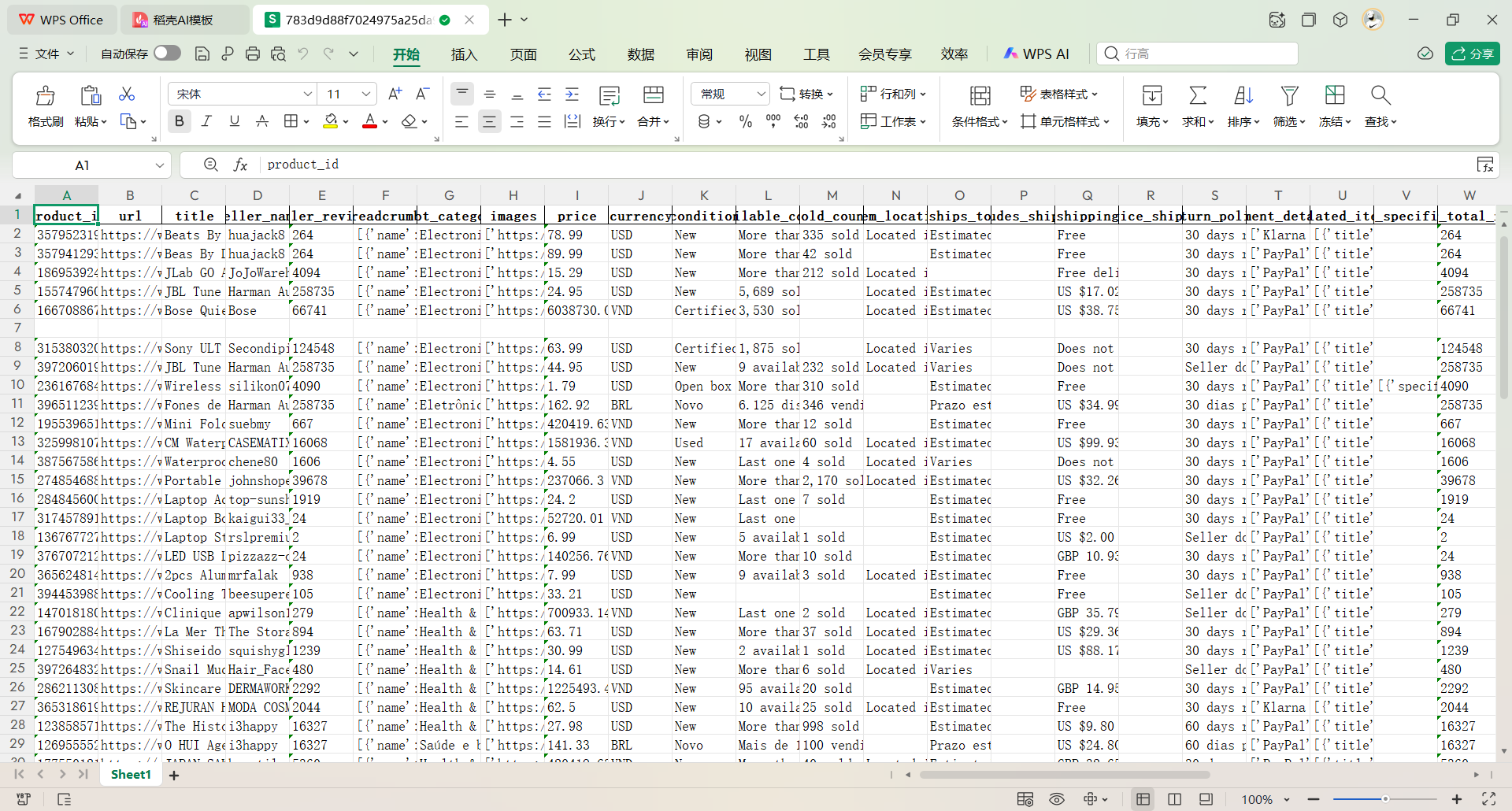
6、根据前几条信息可以清楚分析出来,eBay三款耳机抓取信息核心:Beats Studio3/Solo3(78.99-89.99美元)由深圳卖家供应,Studio3销量335件带主动降噪,JLab平价耳塞(15.29美元)美国发货支持快速配送且口碑突出,三款均库存充足、支持30天退货及多渠道支付
IPIDEA API抓取流程解析
IPIDEA网页抓取API的整体流程非常清晰:开发者只需要在控制台选择对应的平台抓取工具,如eBay信息抓取工具,填写Token、抓取方式以及目标商品URL等基础参数,系统即可自动生成对应语言的示例代码。将代码复制到本地运行后,IPIDEA会在后台自动完成代理调度、页面渲染、数据结构化提取,以JSON或CSV的方式返回可直接使用的商品详情数据,实现真正的零门槛、全自动化网页抓取体验
- 选择目标抓取工具,例如eBay信息抓取工具
- 填写Token、抓取方式和目标URL
- 复制系统生成的示例代码到本地运行
- IPIDEA自动完成代理、渲染与抓取处理
- 返回JSON或CSV格式的结构化抓取结果
总结:构建高效可扩展的全球电商采集体系
IPIDEA 网页抓取API通过全球合规住宅IP、智能抓取、自动验证码跳过及多格式结构化解析,解决了跨境电商数据采集中的IP不能用、合规难与开发成本高的问题。依托可视化配置 + 一行代码接入的方式,不论是抓取Amazon、eBay还是其他全球电商平台,可以实现稳定、高成功率、低成本的数据获取。本次实战以eBay商品采集为例,从配置、抓取到结果下载完整复现,展示了如何快速构建一个可直接投入业务的全球电商数据采集工具。


















 9875
9875













 到【灌水乐园】发言
到【灌水乐园】发言









