



本内容主要参照参考列出的文章,然后结合个人理解新增和删减部分内容形成。目前比较混乱 等我彻底弄懂了之后再整理一下
一、Transformer概念
样本的重要性(既一个样本与其他样本之间的相关性)具体是如何计算的
在NLP的世界中,序列数据中的每个样本都会被编码成一个向量,其中文字数据被编码后的结果被称为词向量,时间序列数据则被编码为时序向量。
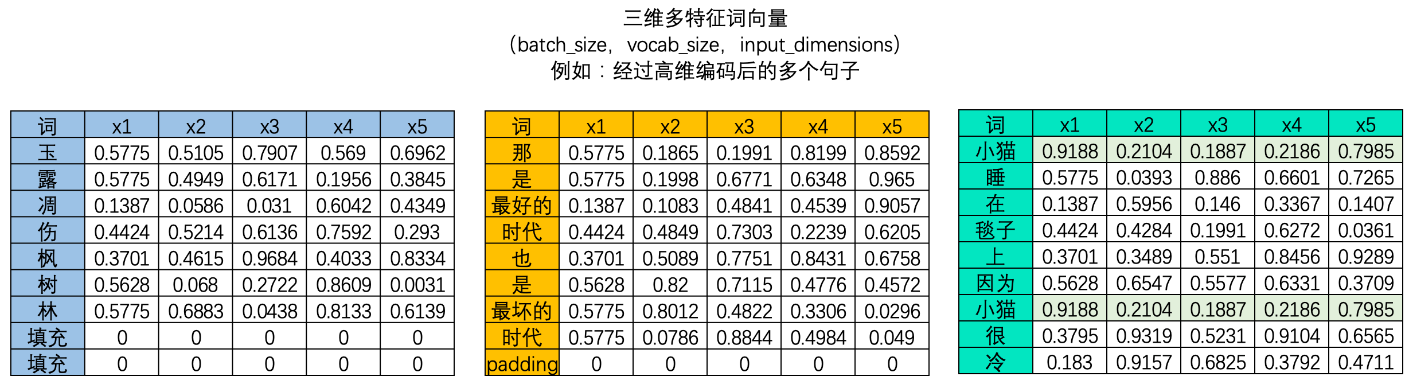
因此,要计算样本与样本之间的相关性,本质就是计算向量与向量之间的相关性。**向量的相关性可以由两个向量的点积来衡量**。如果两个向量完全相同方向(夹角为0度),它们的点积最大,这表示两个向量完全正相关;如果它们方向完全相反(夹角为180度),点积是一个最大负数,表示两个向量完全负相关;如果它们垂直(夹角为90度或270度),则点积为零,表示这两个向量是不相关的。因此,向量的点积值的绝对值越大,则表示两个向量之间的相关性越强,如果向量的点积值绝对值越接近0,则说明两个向量相关性越弱。
在NLP的世界当中,我们所拿到的词向量数据或时间序列数据一定是具有多个样本的。我们需要求解**样本与样本两两之间的相关性**,综合该相关性分数,我们才能够计算出一个样本对于整个序列的重要性。在这里需要注意的是,在NLP的领域中,样本与样本之间的相关性计算、即向量的之间的相关性计算会受到向量顺序的影响。**这是说,以一个单词为核心来计算相关性,和以另一个单词为核心来计算相关性,会得出不同的相关程度**。
因此,假设数据中存在A和B两个样本,则我们必须计算AB、AA、BA、BB四组相关性才可以。在每次计算相关性时,作为核心词的那个词被认为是在“询问”(Question),而作为非核心的词的那个词被认为是在“应答”(Key),AB之间的相关性就是A询问、B应答的结果,AA之间的相关性就是A向自己询问、A自己应答的结果。
这个过程可以通过矩阵的乘法来完成。假设现在我们的向量中有2个样本(A与B),每个样本被编码为了拥有4个特征的词向量。如下所示,如果我们要计算A、B两个向量之间的相关性,只需要让特征矩阵与其转置矩阵做乘法就可以了——
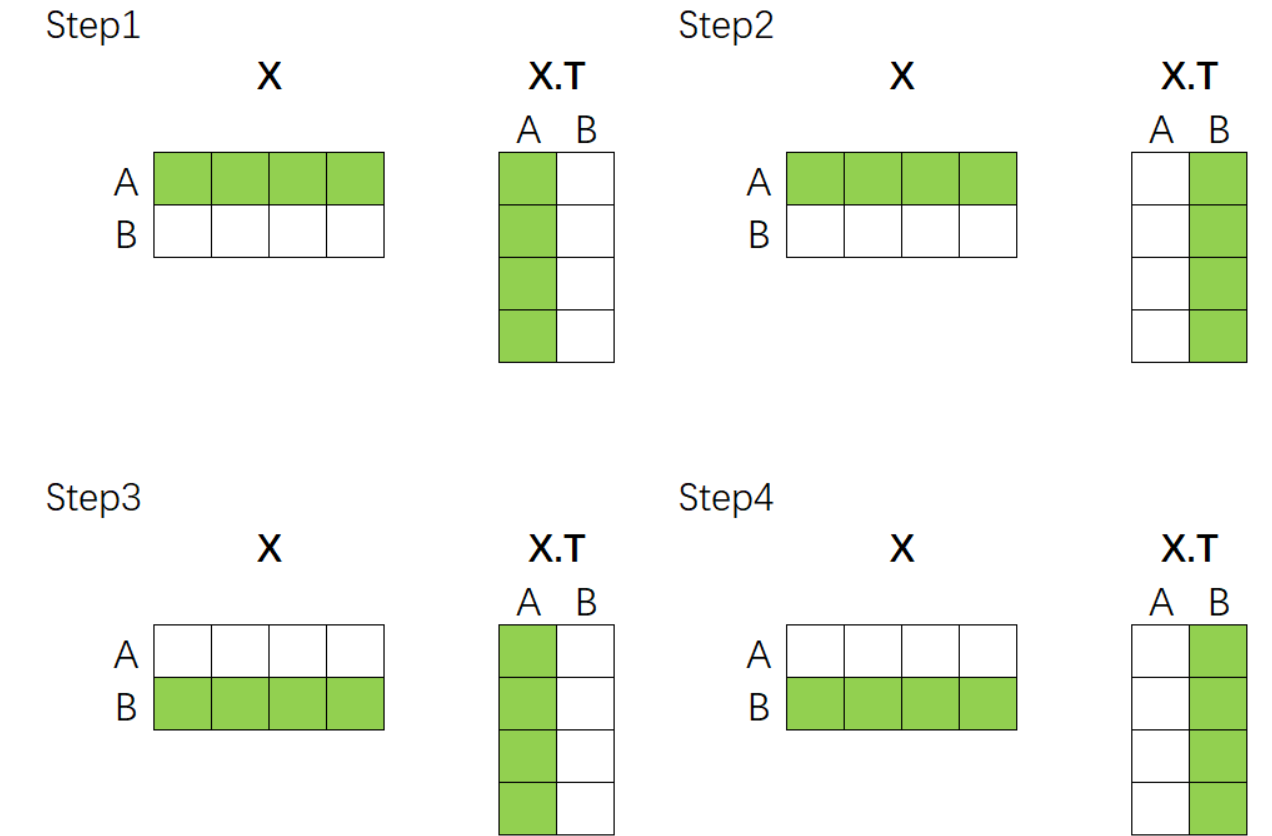
该乘法规律可以推广到任意维度的数据上,因此面对任意的数据,我们只需要让该数据与自身的转置矩阵相乘,就可以自然得到样本与样本之间的相关性构成的相关性矩阵了。
当然,在实际计算相关性的时候,我们一般不会直接使用原始特征矩阵并让它与转置矩阵相乘,**因为我们渴望得到的是语义的相关性,而非单纯数字上的相关性**。因此在NLP中使用注意力机制的时候,**我们往往会先在原始特征矩阵的基础上乘以一个解读语义的w参数矩阵,以生成用于询问的矩阵Q、用于应答的矩阵K以及其他可能有用的矩阵**。
在实际进行运算时,w是神经网络的参数,是由迭代获得的,因此w会依据损失函数的需求不断对原始特征矩阵进行语义解读,而我们实际的相关性计算是在矩阵Q和K之间运行的。使用Q和K求解出相关性分数的过程,就是自注意力机制的核心过程。

Transformer 模型
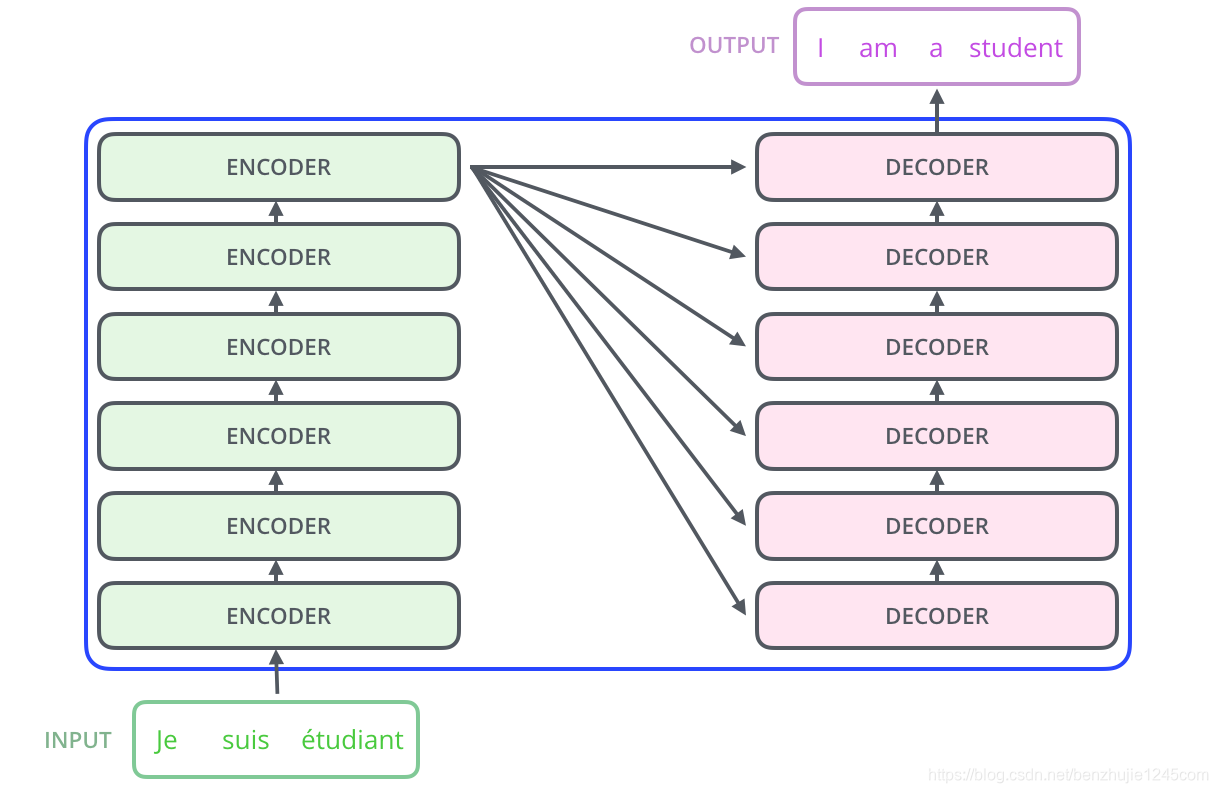
2017 年,Google 在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。Transformer 的整体模型架构如图所示:
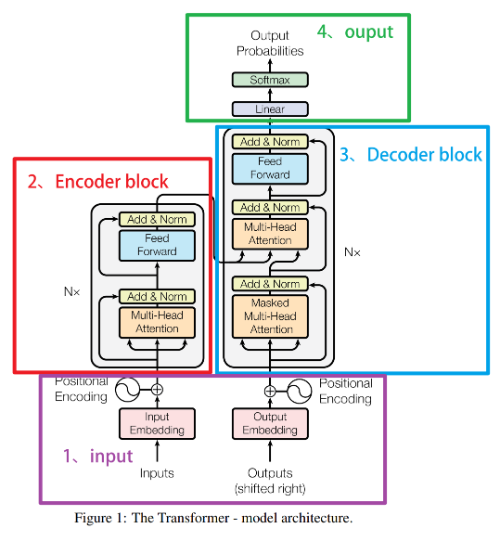


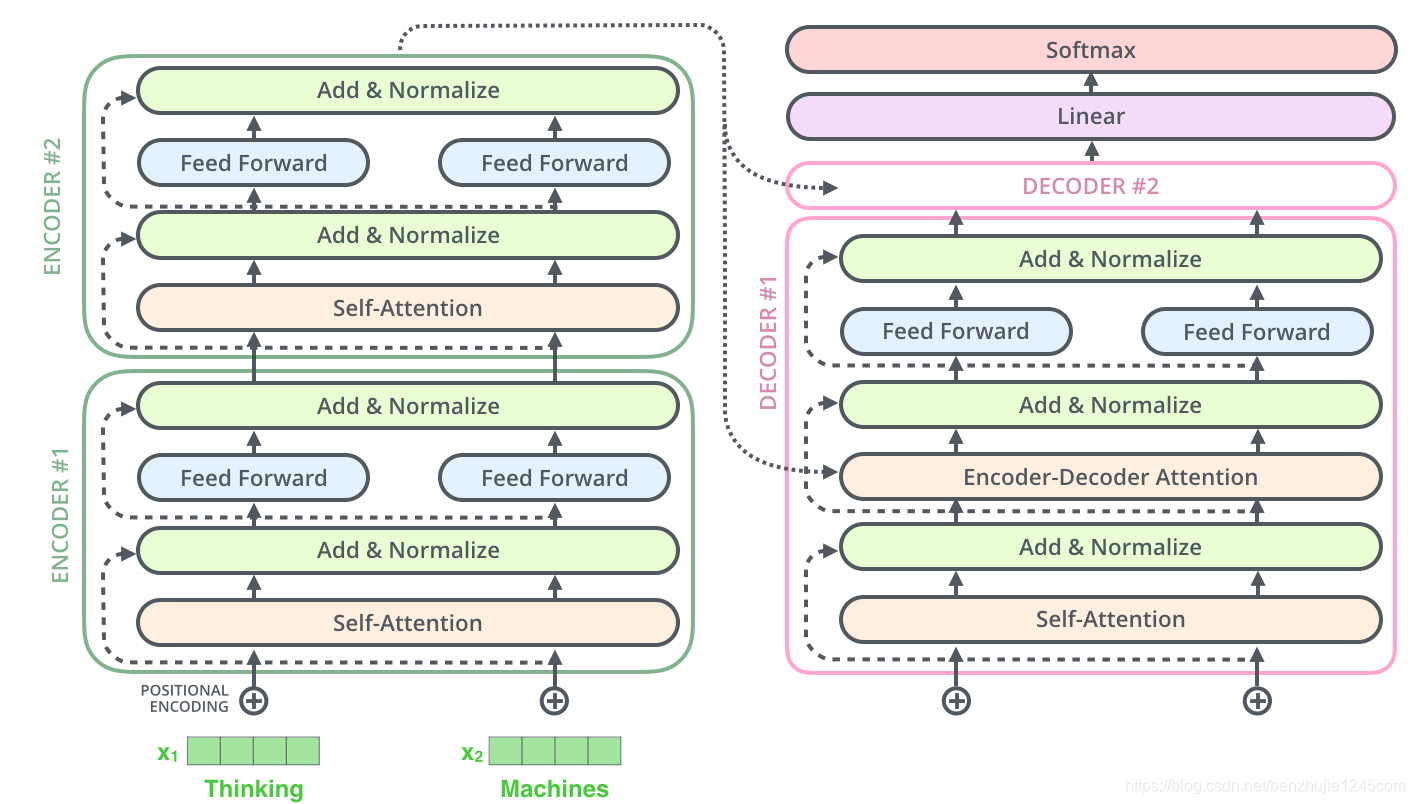
Transformer 本质上是一个 Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:编码组件和解码组件。如图所示:
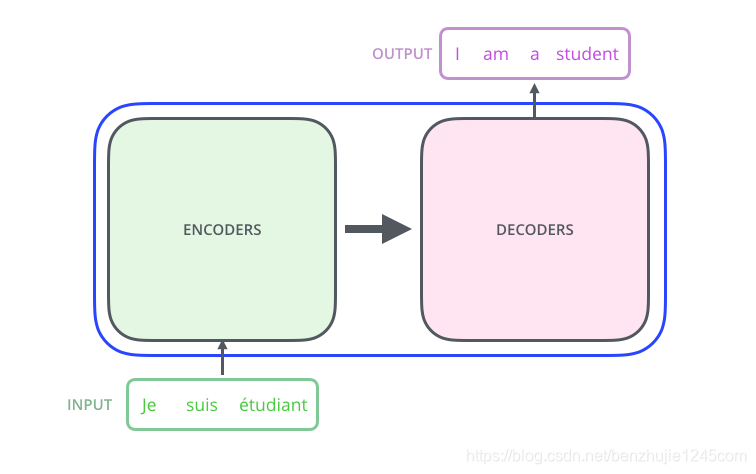
其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了 6 层编码器,在实际使用过程中你可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。如图 所示:
 每个编码器由两个子层组成:Self-Attention 层(自注意力层)和 Position-wise Feed Forward Network(前馈网络,缩写为 FFN)如图所示。每个编码器的结构都是相同的,但是它们使用不同的权重参数。
每个编码器由两个子层组成:Self-Attention 层(自注意力层)和 Position-wise Feed Forward Network(前馈网络,缩写为 FFN)如图所示。每个编码器的结构都是相同的,但是它们使用不同的权重参数。
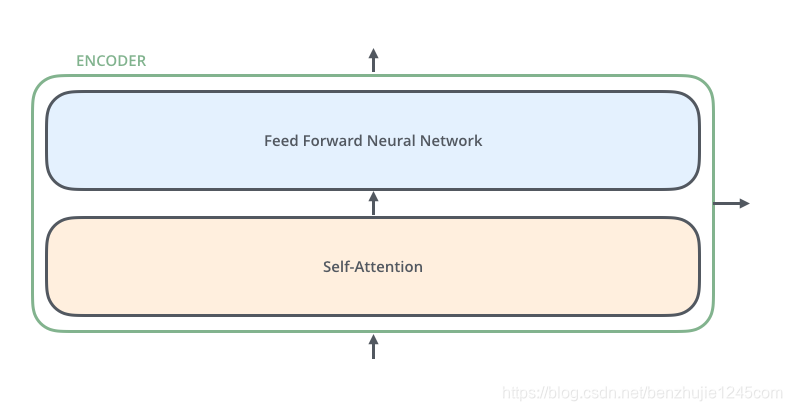
编码器的输入会先流入 Self-Attention 层。它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息)。然后,Self-Attention 层的输出会流入前馈网络。
解码器也有编码器中这两层,但是它们之间还有一个注意力层(即 Encoder-Decoder Attention),其用来帮忙解码器关注输入句子的相关部分(类似于 seq2seq 模型中的注意力)。

数据预处理
1、TOKEN化:Token化(或分词),是将句子、段落、文章等长文本分解为以字词(token)为单位的数据结构。人话讲就是先把你的input拆分成计算机能处理的token,token就是一串整数数字,因为计算机是无法储存文字的,所以任何字符最终都得用数字来表示,有了数字表示的文本之后,再给它传入嵌入层。
2、Embedding:词嵌入,将一个token(标记)转化为一个向量,向量的信息更丰富,可以捕捉到token之间的语义和语法关系。
人话讲就是,嵌入层的作用是为了让每一个token用向量来表示。维度越大,向量长度越大,数据丰富度越大。
那么问题来了,token是一串整数数字,那向量也是一串整数数字,这两个数字有啥不一样呢?
答:这是因为token本身仅是表示自身,但是那个嵌入曾的向量里面就包含了词汇之间的语法语义关系。词向量更能处理词与词之间的关系。在论文里,向量的长度是512,GPT3是12288.所以可以想象一个词可以包含的信息有多么丰富。
通过编码器的嵌入词得到向量后,下一步是....
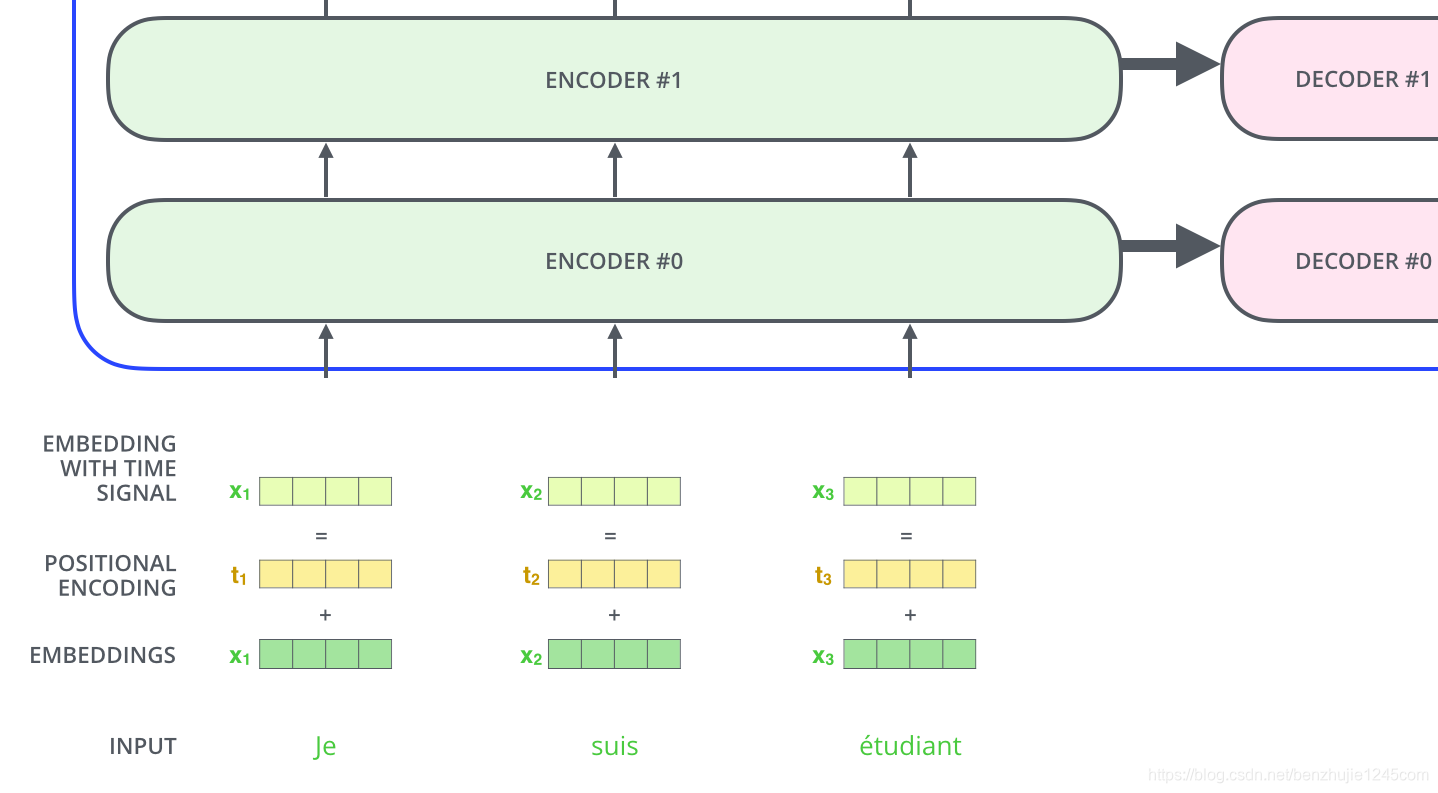
3、Position Encoding:加入位置编码,捕捉词在句子中的顺序关系,维度和嵌入层一样,得到一个包含位置信息的新向量。
也就是把用于表示各个词在文本里顺序的向量和上一步嵌入层得到的词向量做向量相加,最终把结果传给编码器。这样以来,模型既可以理解每个词的意义,又能捕捉词在句中的意思,从而理解不同词之间的顺序关系,最终得到语法、语义、位置信息的向量。
二、 Self-Attention
Self-Attention 的具体机制。其基本结构如图 所示:

对于 Self Attention 来讲,Q(Query),K(Key)和 V(Value)三个矩阵均来自同一输入,并按照以下步骤计算:
首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以其中
为 Key 向量的维度。然后利用 Softmax 操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示。整个计算过程可以表示为:
三、多头注意力机制(Multi-head Attention)
在 Transformer 论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。具体做法:首先,通过 h hh 个不同的线性变换对 Query、Key 和 Value 进行映射;然后,将不同的 Attention 拼接起来;最后,再进行一次线性变换。基本结构如图。
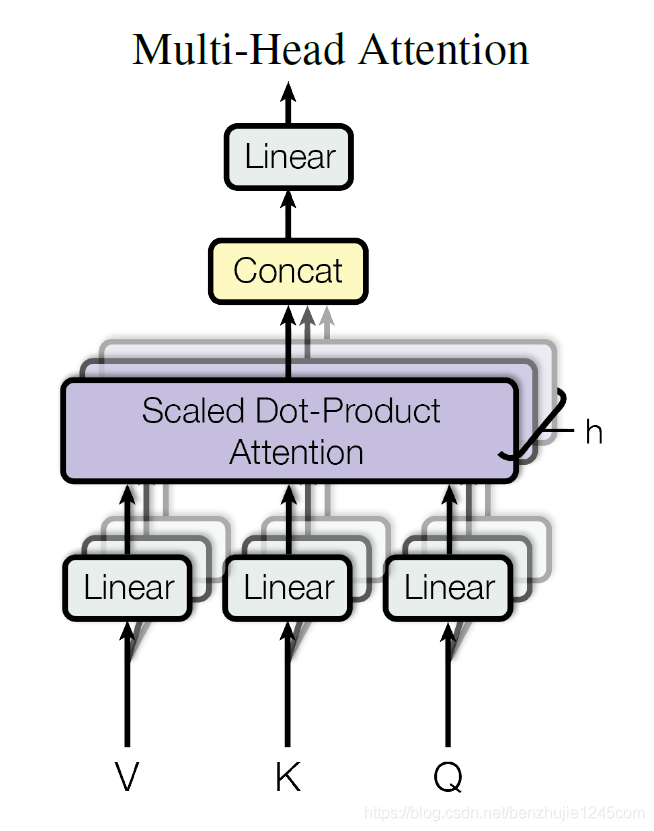
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。多头注意力下,我们为每组注意力单独维护不同的 Query、Key 和 Value 权重矩阵,从而得到不同的 Query、Key 和 Value 矩阵。如前所述,我们将乘以
、
和
矩阵,得到 Query、Key 和 Value 矩阵。
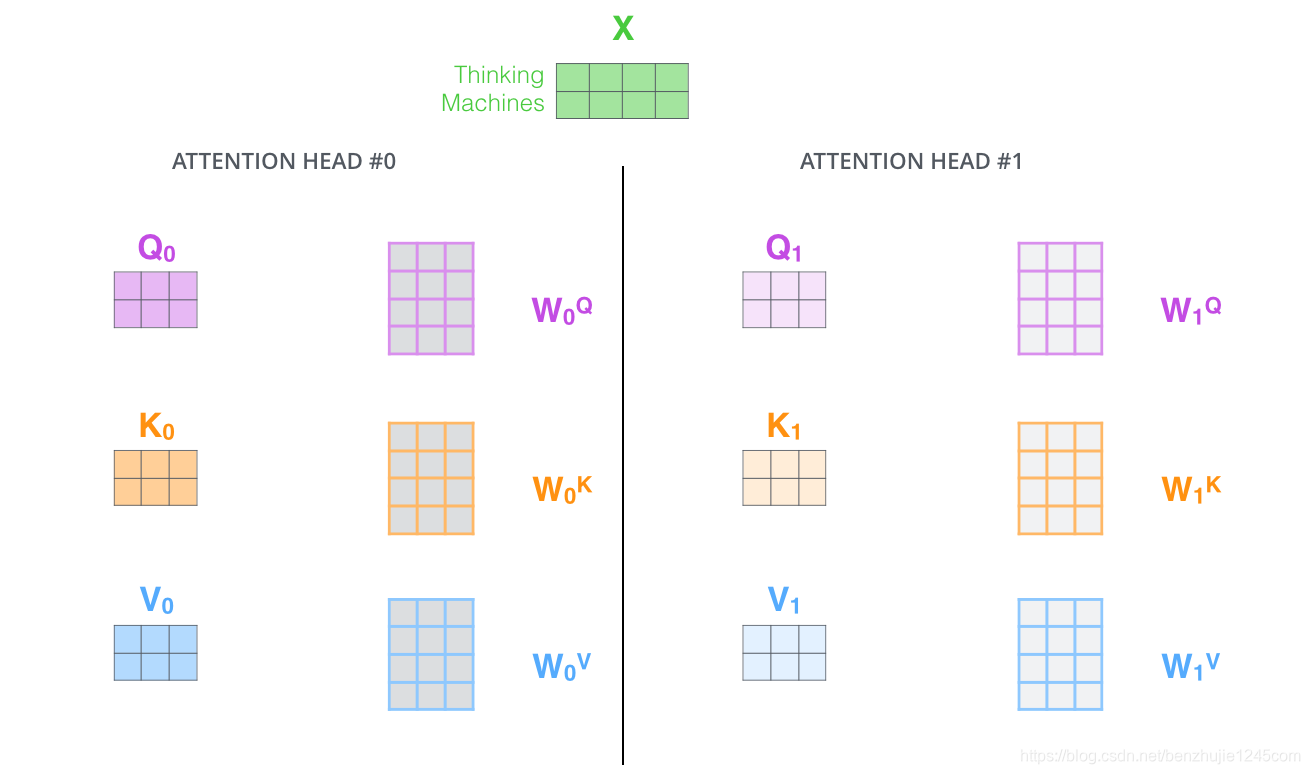
按照上面的方法,使用不同的权重矩阵进行 8 次自注意力计算,就可以得到 8 个不同的 Z 矩阵。
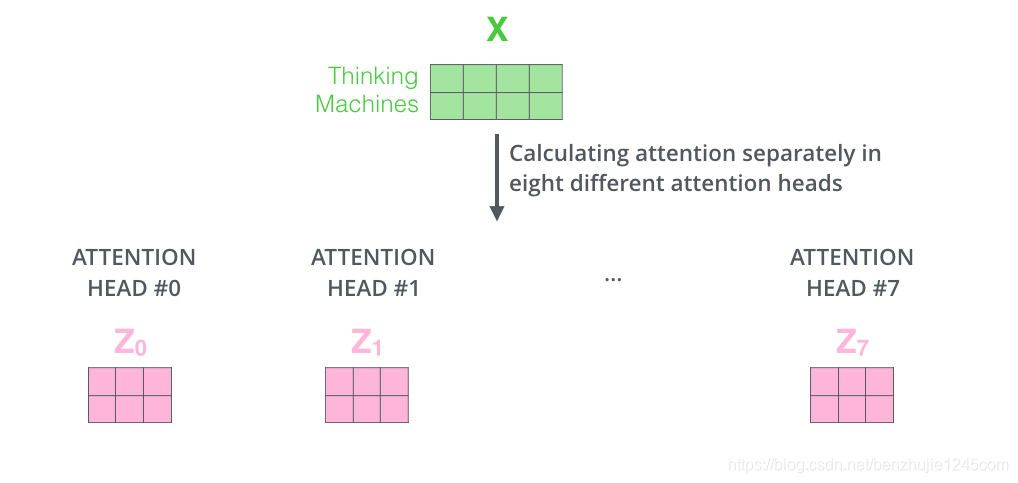
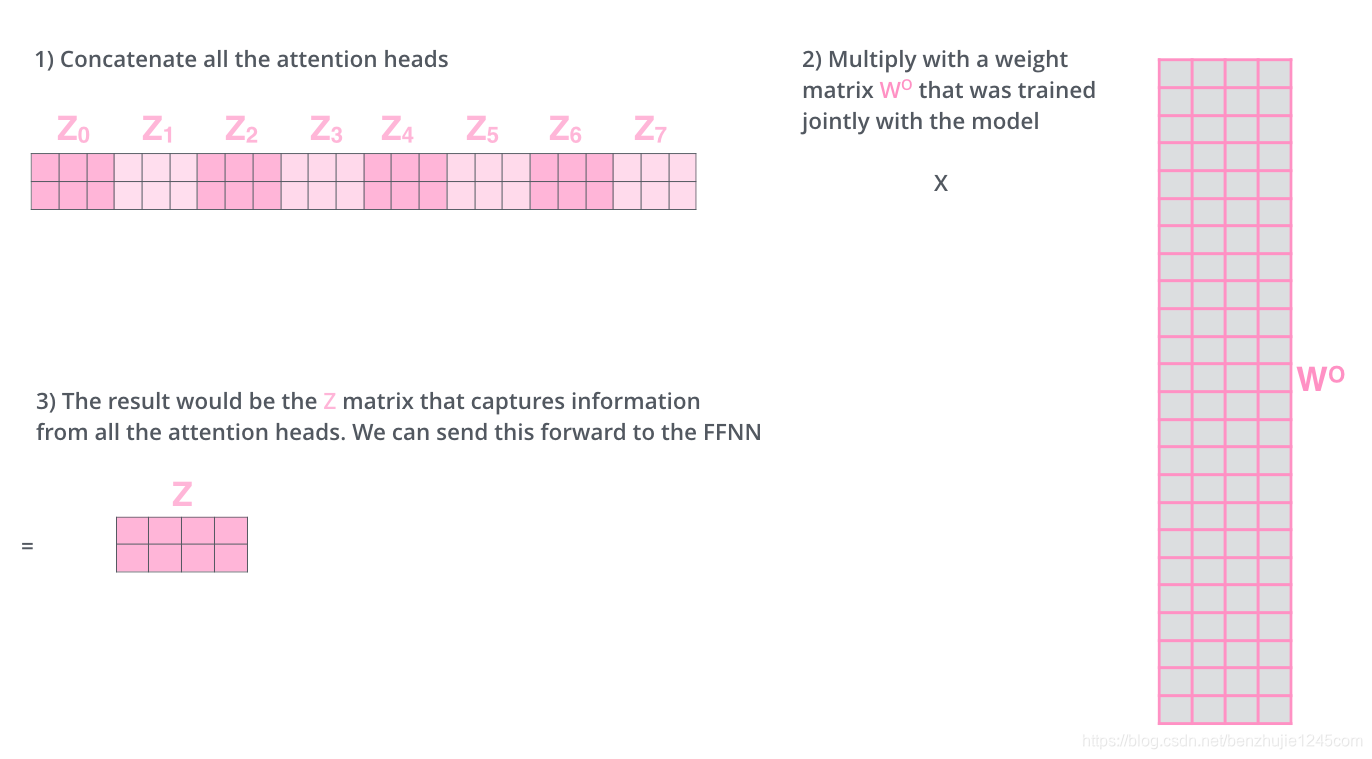
接下来就有点麻烦了。因为前馈神经网络层接收的是 1 个矩阵(每个词的词向量),而不是上面的 8 个矩阵。因此,我们需要一种方法将这 8 个矩阵整合为一个矩阵。具体方法如下:
- 把 8 个矩阵
拼接起来。
- 把拼接后的矩阵和一个权重矩阵
相乘。
- 得到最终的矩阵
这个矩阵包含了所有注意力头的信息。这个矩阵会输入到 FFN 层
这差不多就是多头注意力的全部内容了。下面将所有内容放到一张图中,以便我们可以统一查看。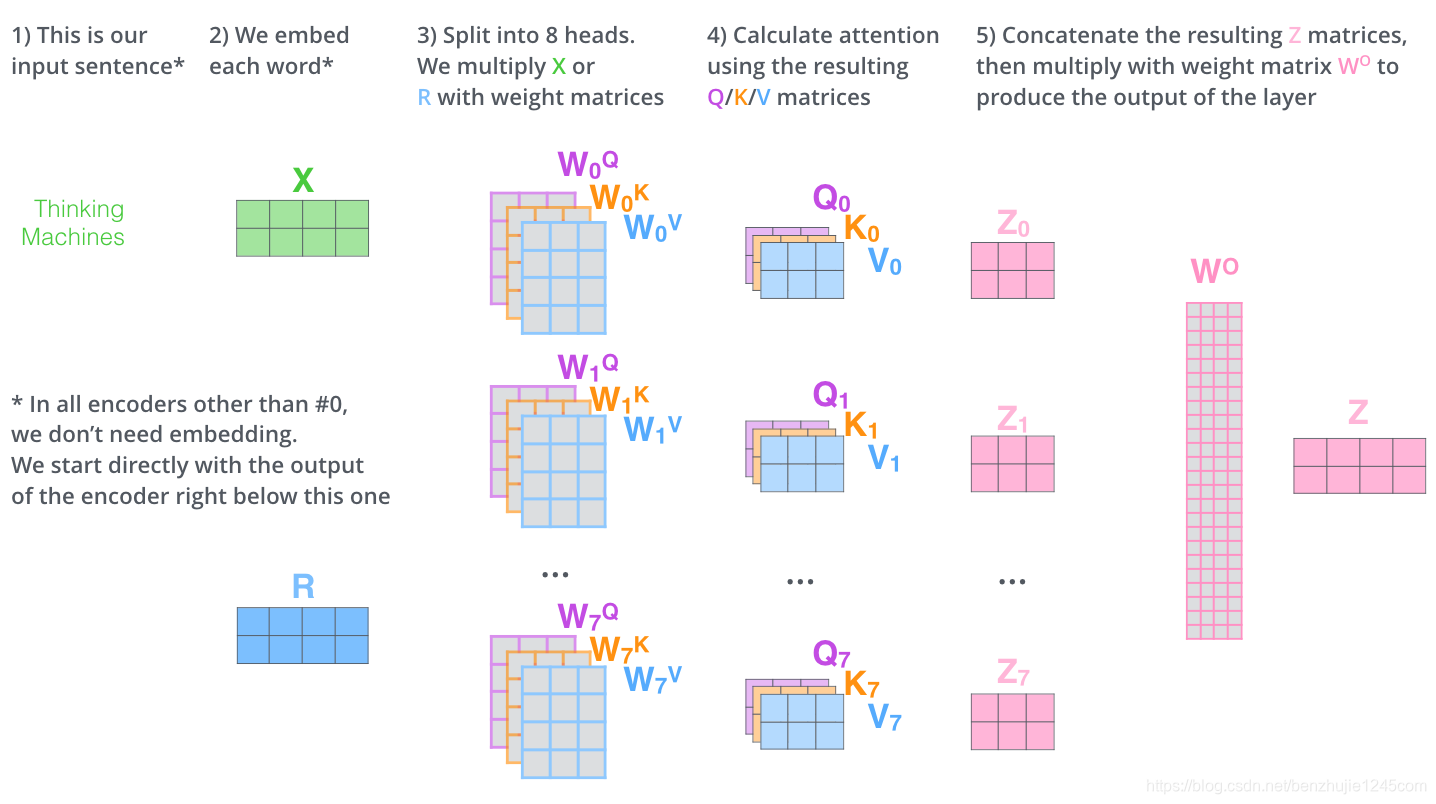
对一个句子“it”进行编码时,不同的注意力头关注的位置分别在哪:

当我们对“it”进行编码时,一个注意力头关注“The animal”,另一个注意力头关注“tired”。从某种意义上来说,模型对“it”的表示,融入了“animal”和“tired”的部分表达。
Multi-head Attention 的本质是,在参数总量保持不变的情况下,将同样的 Query,Key,Value 映射到原来的高维空间的不同子空间中进行 Attention 的计算,在最后一步再合并不同子空间中的 Attention 信息。这样降低了计算每个 head 的 Attention 时每个向量的维度,在某种意义上防止了过拟合;由于 Attention 在不同子空间中有不同的分布,Multi-head Attention 实际上是寻找了序列之间不同角度的关联关系,并在最后拼接这一步骤中,将不同子空间中捕获到的关联关系再综合起来。
四、位置前馈网络(Position-wise Feed-Forward Networks)
位置前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,即两个全连接层组成,第一个全连接层的激活函数为 ReLU 激活函数。可以表示为:
在每个编码器和解码器中,虽然这个全连接前馈网络结构相同,但是不共享参数。整个前馈网络的输入和输出维度都是=512d ,第一个全连接层的输出和第二个全连接层的输入维度为
。
五、残差连接和层归一化
编码器结构中有一个需要注意的细节:每个编码器的每个子层(Self-Attention 层和 FFN 层)都有一个残差连接,再执行一个层标准化操作,整个计算过程可以表示为:
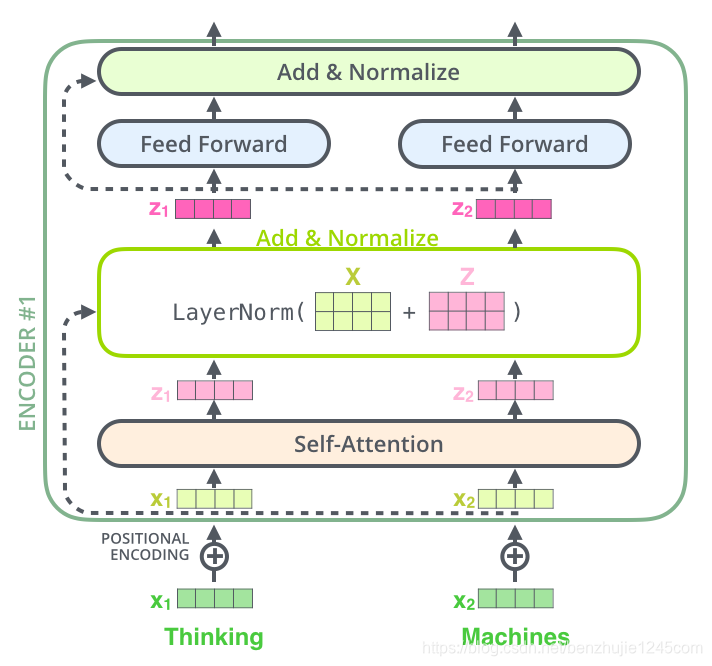
上面的操作也适用于解码器的子层。假设一个 Transformer 是由 2 层编码器和 2 层解码器组成,其如下图所示:
六、位置编码
到目前为止,所描述的模型中缺少一个东西:表示序列中词顺序的方法。为了解决这个问题,Transformer 模型为每个输入的词嵌入向量添加一个向量。这些向量遵循模型学习的特定模式,有助于模型确定每个词的位置,或序列中不同词之间的距离。
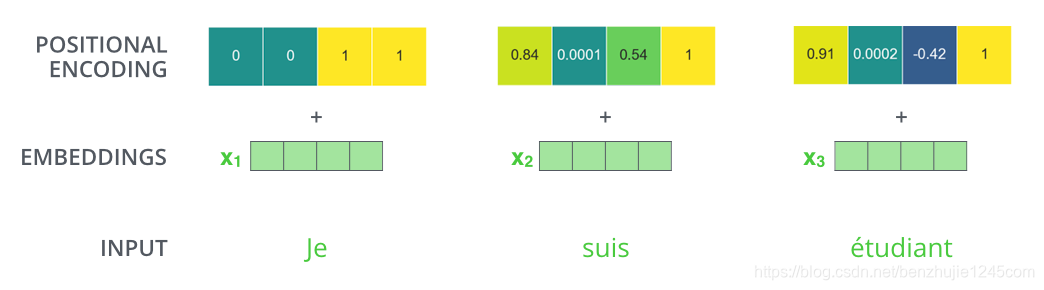
如果假设词嵌入向量的维度是 4,那么实际的位置编码如下:
七、解码器
现在已经介绍了编码器的大部分概念,我们也了解了解码器的组件的原理。现在让我们看下编码器和解码器是如何协同工作的。已经了解第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量 Key 和 Value。这些向量将在每个解码器的 Encoder-Decoder Attention 层被使用,这有助于解码器把注意力集中在输入序列的合适位置。
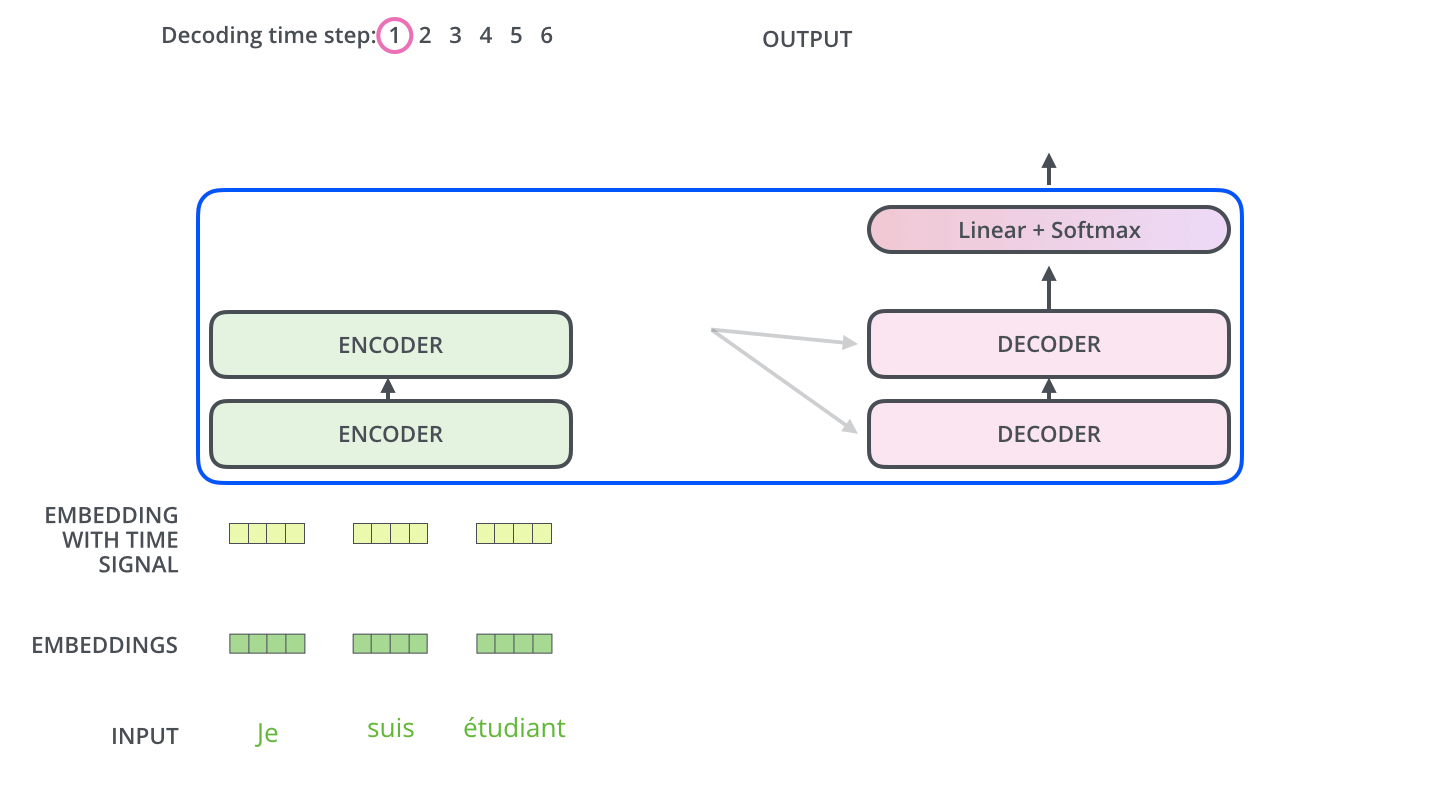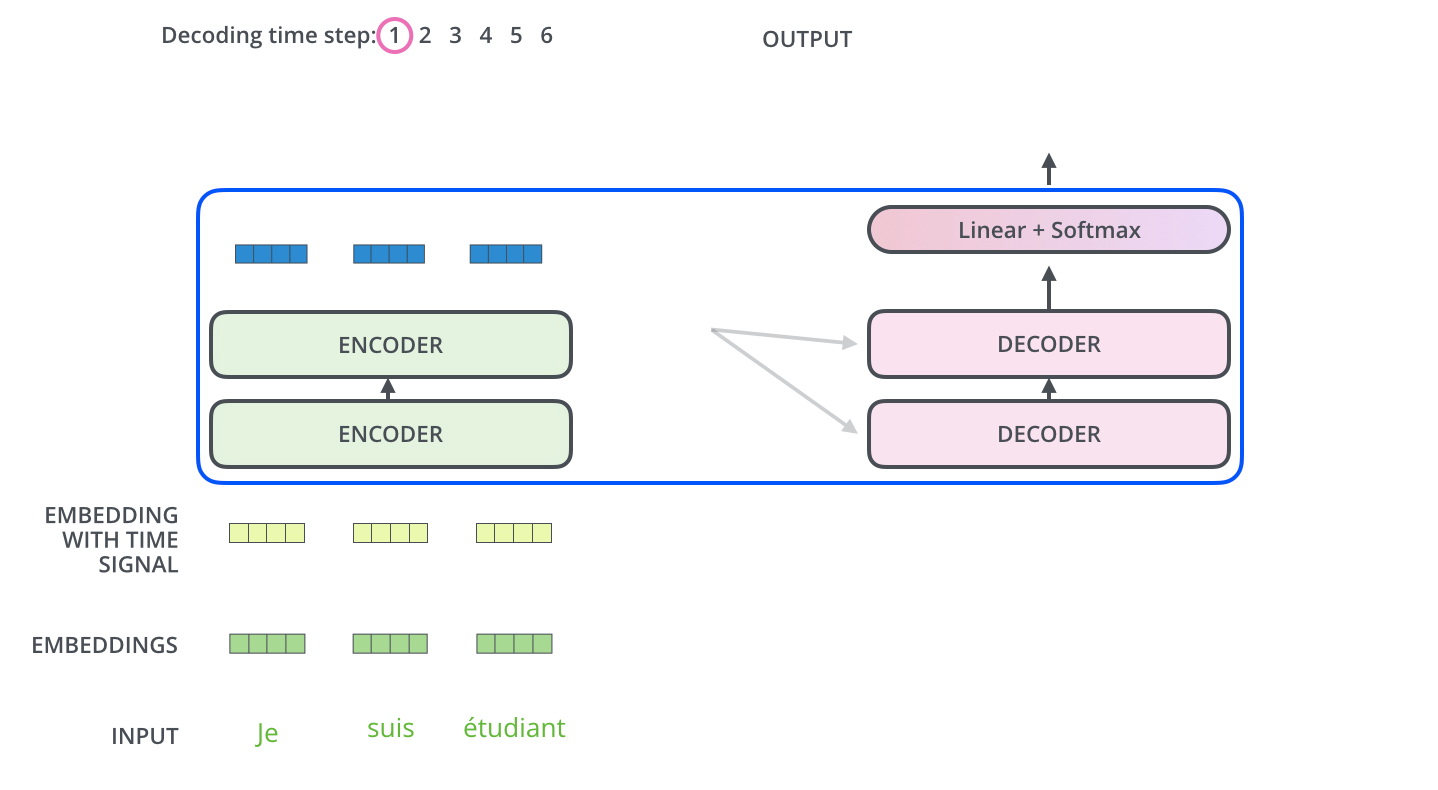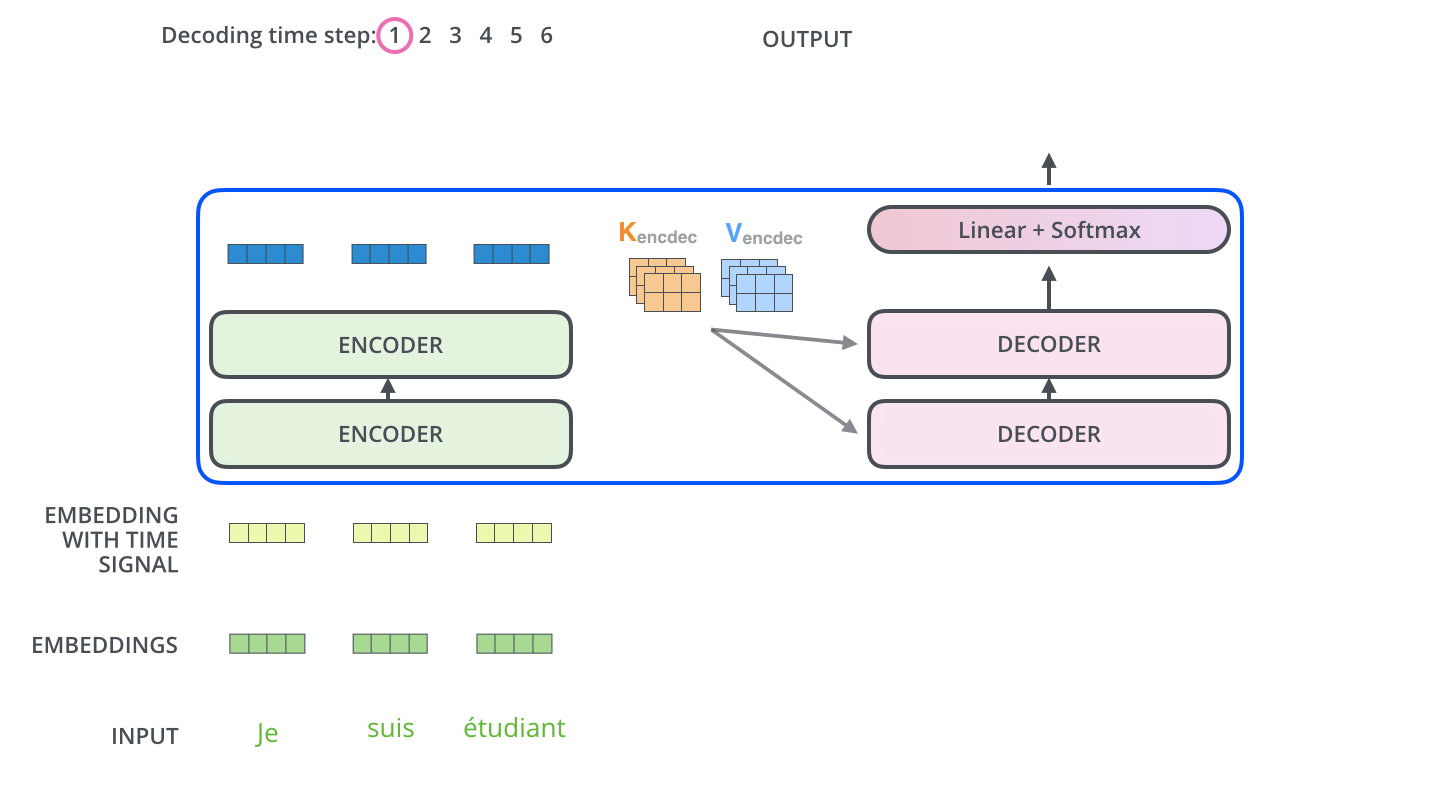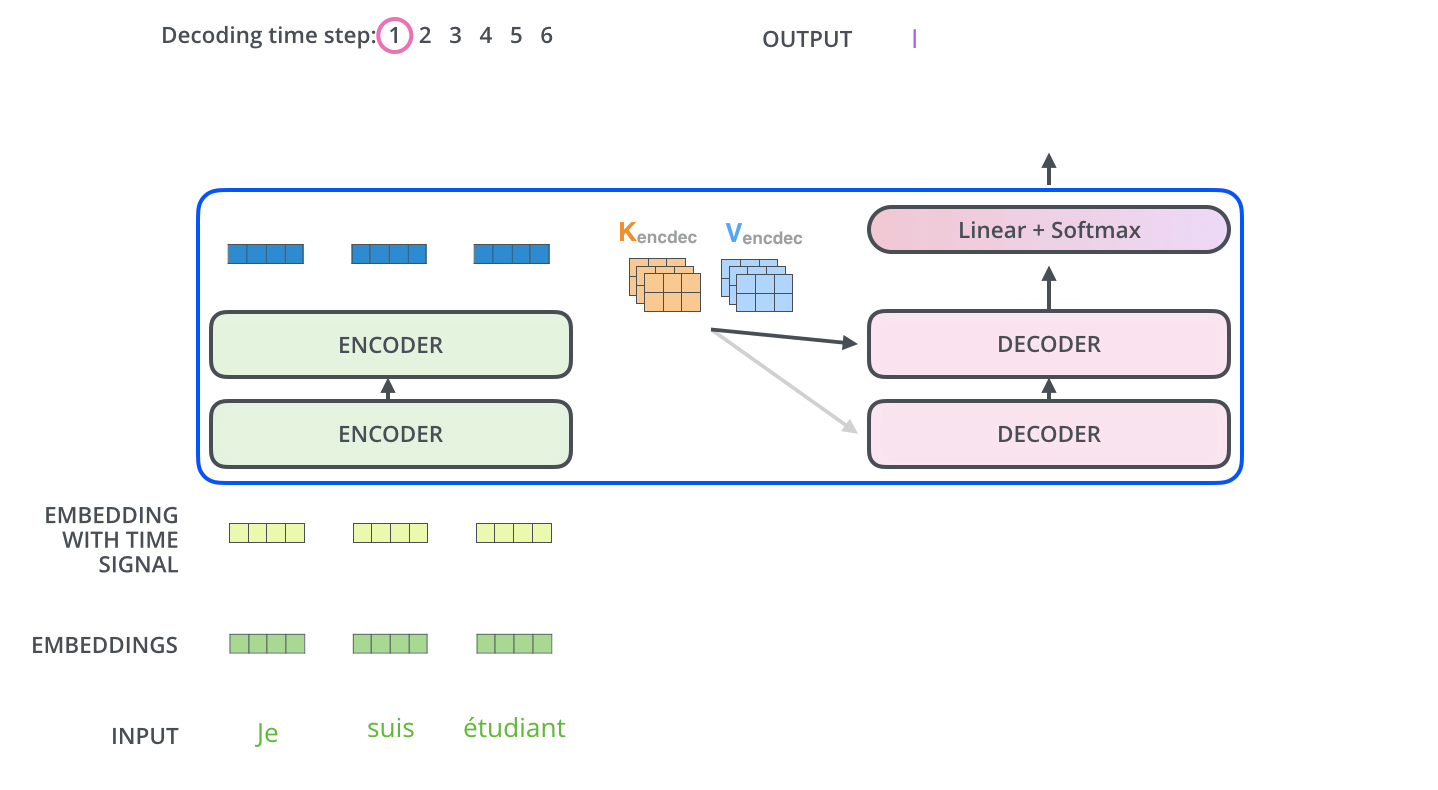
在完成了编码阶段后,开始解码阶段。解码阶段的每个时间步都输出一个元素。接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。就像我们处理编码器输入一样,我们也为解码器的输入加上位置编码,来指示每个词的位置。
八、最后的线性层和 Softmax 层
解码器栈的输出是一个 float 向量。我们怎么把这个向量转换为一个词呢?通过一个线性层再加上一个 Softmax 层实现。
线性层是一个简单的全连接神经网络,其将解码器栈的输出向量映射到一个更长的向量,这个向量被称为 logits 向量。
现在假设我们的模型有 10000 个英文单词(模型的输出词汇表)。因此 logits 向量有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。最后选择最高概率所对应的单词,作为这个时间步的输出。

参考:
原文链接:https://blog.csdn.net/benzhujie1245com/article/details/117173090

















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









