



目录
一、IO流的概念
I表示Input,把硬件文件的数据读入到内存的过程,称为输入,负责读。
O表示output,把内存中的数据写出到硬盘文件的过程,称之输出,负责写。
二、字节操作(字节流)
1.InputStream输入流(读)
InputStream就是Java标准库提供的最基本的输入流。它位于java.io这个包里。java.io包提供了所有同步IO的功能。要特别注意的一点是,InputStream并不是一个接口,而是一个抽象类,它是所有输入流的超类。
1.1 方法
(1)int read():读取输入流的下一个字节。/读取一个8位的字节,把它转换为0~255之间的整数,并返回这个整数。/读到末尾,返回-1,遇到-1代表文件中的数据已经被读取完毕。
(2)int read(byte b[]):每次读取N个字节,存入byte[]字节数组中。/int的返回值是读取字节的长度。/读到末尾,返回-1。
(3)public void close():关闭此输入流,并释放与此流相关联的任何系统。
原因:在IO流进行操作时,当前IO流占用到一定的内存,由于系统资源宝贵,因此在进行IO操作结束后,调用close方法关闭流,从而释放资源。
public class Demo02 {
public static void main(String[] args) throws IOException {
try (InputStream is=new FileInputStream("E:\\YuanJiuYuan\\a.txt");){
//1.int read()一个字节一个字节读取,赋值给返回值,直至末尾返回-1
// int data1=is.read();
// System.out.println(data1);
// int data2=is.read();
// System.out.println(data2);
// int data3=is.read();
// System.out.println(data3);
// int data4=is.read();
// System.out.println(data4);
//循环读取
// int data;
// while ((data=is.read())!=-1){
// System.out.println((char)data);
// }
//2.int read(byte b[]) 每次读取N个字节,把字节放到字节数组中,读取到末尾返回值-1
byte[] bytes=new byte[10];//存放每次读取到的字节信息
int len;//每次读取的长度
//读取操作
while((len=is.read(bytes))!=-1){
System.out.println("读取到的长度为:"+len+"读取到的内容:"+new String(bytes,0,len));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
1.2 实现类
1.2.1 FileInputStream类
是基于磁盘中字节内容的输入流。
构造方法:
(1)FileInputStream(File file); 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
(2)FileInputStream(String name) 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
public class Demo01 {
public static void main(String[] args) throws FileNotFoundException {
//注意路径:一定是一个文件路径,路径一定要存在,如果不存在则出异常
//public FileInputStream(String name)
InputStream is1=new FileInputStream("E:\\YuanJiuYuan\\a.txt");
System.out.println(is1);
//FileInputStream(File file)
InputStream is2=new FileInputStream(new File("E:\\YuanJiuYuan\\a.txt"));
System.out.println(is2);
}
}1.2.2 BufferedInputStream类
BufferedInputStream是缓冲输入流。它继承于FilterInputStream。BufferedInputStream的作用是为另一个输入流添加一些功能,例如,提供“缓冲功能”以及支持“mark()标记”和“reset()重置方法”。
BufferedInputStream本质上是通过一个内部缓冲区数组实现的。例如,在新建某输入流对应的BufferedInputStream后,当我们通过read()读取输入流的数据时,BufferedInputStream会将该输入流的数据分批的填入到缓冲区中。每当缓冲区中的数据被读完之后,输入流会再次填充数据缓冲区;如此反复,直到我们读完输入流数据位置。
作用:没有缓冲区,就好像逛超市没有推车,一次只拿一样东西去结账,缓冲区可以暂时放一堆数据直到满为止。
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class Demo03 {
public static void main(String[] args) {
//缓冲字节输入流依然是字节对象,缓冲流的底层帮助我们维护了一个数组-8192个字节
//缓冲流不具备读写功能,真正读写的还是FileInputStream
try(InputStream is=new FileInputStream("E:\\YuanJiuYuan\\a.txt");
BufferedInputStream bis=new BufferedInputStream(is)){
byte[] bytes=new byte[10];
int len;
while ((len=bis.read(bytes))!=-1){
System.out.println(new String(bytes,0,len));
}
}catch (IOException e){
}
}
}1.2.3 ObjectInputStream类
是对象输入流,进行反序列化操作。
2.OutputStream输出流(写)
2.1 方法
(1)write(int b):写入一个字节。
(2)write(byte b[]):把这个b字节数组中的所有数据写到关联的设备中(设备包括文件、网络或者其他任何地方)。
(3) write(byte b[],int off,int len):把数组b字节中的数据从下标off位置开始往出写,共计写len个元素。
(4)public void close():关闭从输出流并释放与此流相关联的任何系统资源。
close方法,当完成流的操作时,必须调用此方法,释放系统资源。
public class Demo05 {
public static void main(String[] args) {
try {
OutputStream os=new FileOutputStream("E:\\YuanJiuYuan\\IoTest\\a.txt");
//1.write(int data)写入一个字节
os.write(97);
os.write(98);
os.write(99);
//2.write(byte b[])把这个b字节数组中的所有数据写到关联的设备中(设备包括文件、网络或者其他任何地方)。
os.write("庆祝反法西斯胜利80周年".getBytes());
//3.write(byte b[],int offset,int len)从指定下标开始,写出指定个字节信息
os.write("ajsiwhdewbdeu".getBytes(),1,5);
System.out.println("end");
} catch (IOException e) {
e.printStackTrace();
}
}
}2.2 实现类
2.2.1 FileOutStream类
是基于磁盘中字节内容的输出流。
public class Demo04 {
public static void main(String[] args) throws FileNotFoundException {
//1.字节输出流路径一定要是一个文件路径
//2.输出流文件对象可以不存在,但是父路径一定要存在
//FileOutputStream(String name)如果路径中有内容,会将原路径中的内容给覆盖掉
OutputStream os=new FileOutputStream("E:\\YuanJiuYuan\\IoTest\\a.txt");
System.out.println(os);
//FileOutputStream(File file)
OutputStream os1=new FileOutputStream(new File("E:\\YuanJiuYuan\\IoTest\\a.txt"));
System.out.println(os1);
}
}public class Demo06 {
public static void main(String[] args) throws IOException {
//使用追加写的方式进行字节流的输出,不会对原文件信息进行覆盖
OutputStream os=new FileOutputStream("E:\\YuanJiuYuan\\IoTest\\a.txt",true);
os.write("字节输出流的学习".getBytes());
//使用追加写的方式进行字节流的输出,不会对原文件信息进行覆盖
OutputStream os1=new FileOutputStream(new File("E:\\YuanJiuYuan\\IoTest\\a.txt"),true);
os.write("你好中国".getBytes());
}
}2.2.2 BufferedOutStream类
是带有缓冲区的输入流。
public class Demo07 {
public static void main(String[] args) throws IOException {
//使用追加写的方式进行字节流的输出,不会对原文件信息进行覆盖
try (OutputStream os = new FileOutputStream("D:\\IOTest\\a.txt", true);
BufferedOutputStream bos = new BufferedOutputStream(os);){
//window换行写:\r\n
//linux换行:\r
//mac换行:\n
bos.write('a');//写出一个字节信息
bos.write("\r\n".getBytes());//写出一个换行信息
bos.write("我本将心向明月\r\n".getBytes());//写出一个字节数组信息
//获取系统换行符
String str = System.lineSeparator();
for (int i = 0; i < 5; i++) {
String s1 = UUID.randomUUID().toString().substring(0, 8);
bos.write((s1 + str).getBytes());
}
//bos.flush();//刷新缓冲流
//bos.close(); 关闭流
bos.write("站着还能睡着吗".getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.2.3 ObjectOutputStream类
对象输出流,进行序列化操作。
操作的最小单元:包含音频视频图片等。
三、字符操作(字符流)
1. Writer输出流(写)
1.1 方法
(1)void write(int data);//写出一个字符的数据。
(2)void write(char[] array);
(3)void write(char[] array,int offset,int len);
(4)void write(String str);
(5)void write(String str,int offset,int len);
(6)void flush();刷新输出流并强制任何缓冲数据的字符被输出到目标位置。
(7)void close();调用close方法的时候,底层会把缓冲区中的数据写出到目标位置。
import java.io.IOException;
import java.io.Writer;
public class Demo02 {
public static void main(String[] args) {
try {
Writer w1=new FileWriter("E:\\YuanJiuYuan\\IoTest\\a.txt");
//1.w1.write('')写出一个字符信息
w1.write('你');
w1.write('好');
w1.write('a');
w1.write('!');
String separator=System.lineSeparator();
w1.write(separator);//写出换行符
//2.write(char cbuf[])写出字符数组
w1.write("我本将心向明月".toCharArray());
w1.write(separator);
//3.write(char cbuf[], int off, int len) 写出字符数组中指定的下标的元素
w1.write("奈何明月照沟渠".toCharArray(),4,3);
w1.write(separator);
//4.write(String str)写出字符串
w1.write("白日依山尽");
w1.write(separator);
//5.write(String str, int off, int len)写出字符串中指定范围的字符
w1.write("黄河入海流",0,4);
w1.write(separator);
w1.flush();
System.out.println("写出结束");
} catch (IOException e) {
e.printStackTrace();
}
}
}1.2 实现类
1.2.1 FileWriter类
构造方法:
(1)public FileWriter(String path);
(2)public FileWriter(File path);
(3)public FileWriter(String path,boolean append);
(4)public FileWriter(File path,boolean append);
//调用下面构造方法的时候,底层会创建一个长度是 8192的byte数组(缓冲区) //写出的字符要先转换成byte数组,存入缓冲区中 //当缓冲区 存满 或者 显示的调用flush方法,会把缓冲区中的数据写出到目标。
public class Demo01 {
public static void main(String[] args) throws IOException {
//FileWriter(String fileName) 覆盖写
Writer w1=new FileWriter("E:\\YuanJiuYuan\\IoTest\\a.txt");
System.out.println(w1);
//FileWriter(File file) 覆盖写
Writer w2=new FileWriter(new File("E:\\YuanJiuYuan\\IoTest\\b.txt"));
System.out.println(w1);
//FileWriter(String fileName) 追加写
Writer w3=new FileWriter("E:\\YuanJiuYuan\\IoTest\\c.txt",true);
System.out.println(w3);
//FileWriter(File file) 追加写
Writer w4=new FileWriter(new File("E:\\YuanJiuYuan\\IoTest\\d.txt"),true);
System.out.println(w4);
}
}1.2.2 BufferedWriter类
方法:
(1)void write(String str) 写入一整行。
(2)void newLine( ) 创建新行,输出换行符(根据操作系统不同,输出不同的换行符,windows是\r\n,Linux和Mac OS是\n)。
public class Demo03 {
public static void main(String[] args) {
try (BufferedWriter bw=new BufferedWriter(new FileWriter("E:\\YuanJiuYuan\\IoTest\\d.txt"))){
bw.write("你好");
bw.newLine();//换行操作
bw.write("白日依山尽",0,3);
bw.newLine();
bw.flush();//刷新
bw.close();//关闭,用了try-with-resource,所以不用关了
} catch (IOException e) {
e.printStackTrace();
}
}
}public class Demo04 {
public static void main(String[] args) throws IOException {
//缓冲区大小验证
FileWriter f1=new FileWriter("E:\\YuanJiuYuan\\IoTest\\c.txt",true);
for (int i = 0; i <8192 ; i++) {
f1.write('a');
}
f1.write('b');
System.out.println("写出结束");
}
}2. Reader输入流(读)
2.1 方法
(1)int read()读取一个字符的数据,如果没有数据则返回-1。
(2)int read(char buf[]) 读取数据存入char数组中,返回读取的长度,如果没有数据则返回-1。
(3)void close(); 关闭此流并释放与此流相关联的任何系统资源。
public class Demo06 {
public static void main(String[] args) {
try (Reader r1=new FileReader("E:\\YuanJiuYuan\\IoTest\\a.txt");
){
//读取单个字符,返回字符对应码表值,当为-1读取结束
// int data=r1.read();
// System.out.println((char)data);
//循环读取
// int data;
// while ((data=r1.read())!=-1){
// System.out.println((char)data);
// }
//int read(char buf[]) 读取数据存入char数组中,如果没有数据则返回-1
char[] chars=new char[10];
int len;
while ((len=r1.read(chars))!=-1){
System.out.print(new String(chars,0,len));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.2 实现类
2.2.1 FileReader类
构造方法:
(1)public FileReader(String path);
(2)public FileReader(File path);
public class Demo05 {
public static void main(String[] args) throws FileNotFoundException {
//创建字符输入流
//FileReader(String fileName)
Reader r1=new FileReader("E:\\YuanJiuYuan\\IoTest\\a.txt");
System.out.println(r1);
//FileReader(File file)
Reader r2=new FileReader(new File("E:\\YuanJiuYuan\\IoTest\\a.txt"));
System.out.println(r2);
}
}2.2.2 BufferedReader类
方法:
String readLine():读取一整行。/读取至末尾,返回null。
public class Demo08 {
public static void main(String[] args) {
try (BufferedReader br=new BufferedReader(new FileReader("E:\\YuanJiuYuan\\IoTest\\a.txt"))
){
//按行读取内容,当读取到末尾时返回值为null
String str;
while ((str=br.readLine())!=null){
System.out.println(str);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}操作的最小单元:txt文本文件或者java文件。
四、读取classpath资源文件
很多Java程序或框架启动的时候,都需要读取配置文件。
1.Properties类简介
Properties 是 Hashtable 的子类,专门用于处理属性文件(以 .properties 为后缀的文件,不过这里是直接在代码里操作),它的键和值都是 String 类型,常用于存储配置信息。
import java.util.Properties;
import java.util.Set;
public class Demo01 {
public static void main(String[] args) {
Properties p1=new Properties();
//setProperty(String key, String value)给对象赋值
p1.setProperty("姓名","张三");
p1.setProperty("年龄","18");
System.out.println(p1);
//getProperty(String key)获取键对应的值
String str=p1.getProperty("姓名");
System.out.println(str);
//getProperty(String key, String defaultValue)获取键对应的值,若不存在,返回默认值
String str1=p1.getProperty("姓名1","不知道");
System.out.println(str1);
//Set<String> stringPropertyNames()获取所有的键
Set<String> set=p1.stringPropertyNames();
System.out.println(set);
}
}代码分析:
创建一个 Properties 对象 p1,用于存储键值对。
使用 setProperty 方法向 Properties 对象 p1 中添加键值对,这里添加了 “姓名 - 张三” 和 “年龄 - 18” 两组键值对。setProperty 方法内部其实是调用了 Hashtable 的 put 方法,不过对参数做了 String 类型的限制 。
直接打印 Properties 对象,会按照类似 {键1=值1, 键2=值2} 的格式输出,这里会输出 {姓名=张三, 年龄=18} 。
获取指定键的值:使用 getProperty 方法根据键 “姓名” 获取对应的值,会输出 张三 。
获取指定键的值(带默认值):使用 getProperty 方法获取键 “姓名 1” 对应的值,因为 p1 中不存在该键,所以返回指定的默认值 “不知道” 。
获取所有键的集合:通过 stringPropertyNames 方法获取 p1 中所有键的集合,这里会输出 [姓名, 年龄] ,返回的 Set 集合可以用于遍历等操作,方便获取所有配置项的键 。
public class Demo02 {
public static void main(String[] args) throws IOException {
Properties p1=new Properties();
p1.setProperty("姓名","张三");
p1.setProperty("年龄","18");
p1.setProperty("性别","男");
Writer w1=new FileWriter("b.txt");
//将输出流和p1对象结合,进行p1对象的内容输出
p1.store(w1,"helloworld");
w1.close();
}
}这段代码的功能是将 Properties 对象中的键值对数据写入到 b.txt 文件中,以下是详细解析:
核心逻辑
创建 Properties 对象并添加数据:
通过 setProperty 方法向 Properties 对象 p1 中添加了三组键值对(姓名 = 张三、年龄 = 18、性别 = 男)。
将数据写入文件:
使用 FileWriter 创建一个指向 b.txt 的字符输出流 w1。
调用 p1.store(w1, "helloworld") 方法,将 Properties 中的键值对通过输出流写入文件:
第二个参数 "helloworld":注释信息,会被写入文件的第一行(以 # 开头)。
第一个参数 w1:用于写入数据的输出流。
输出文件b.txt的内容示例:
#helloworld
#Mon Jul 28 15:30:00 CST 2025
性别=男
姓名=张三
年龄=18- 第一行是注释信息
#helloworld。 - 第二行是自动生成的时间戳(格式为
#星期 月 日 时:分:秒 时区 年)。 - 后续行是
Properties中的键值对,顺序可能与添加顺序不一致(因为Properties底层是哈希表实现)。
在 Java 的 Properties 类中,store() 方法用于将 Properties 对象中存储的键值对数据写入到输出流(如文件、网络流等),通常用于将配置信息持久化到文件中(如 .properties 文件)。
store() 方法的核心作用
(1)持久化配置:将内存中 Properties 对象的键值对(如程序中的配置参数)写入到外部存储(如本地文件),便于下次程序启动时读取复用。
(2)格式规范:写入的数据会遵循 .properties 文件的格式(键值对用 = 或 : 分隔,注释用 # 开头),并自动添加时间戳注释。
关键特点
(1)写入文件时,会自动在第一行添加注释(若指定),第二行添加当前时间戳(格式如 #Mon Jul 28 16:00:00 CST 2025)。
(2)键值对的顺序不保证与添加顺序一致(因 Properties 底层基于哈希表)。
(3)支持中文,但通过 store(OutputStream, ...) 写入时会自动转为 Unicode 编码(如 张三 转为 \u5F20\u4E09),而 store(Writer, ...) 则依赖 Writer 的编码。
public class Demo03 {
public static void main(String[] args) throws IOException {
Properties p1=new Properties();
Reader r1=new FileReader("b.txt");
//将输入流获取到的所有信息传递给p1对象
p1.load(r1);
Set<String> set=p1.stringPropertyNames();
for (String s1:set) {
System.out.println(s1+"__"+p1.getProperty(s1));
}
}
}这段代码的功能是从 b.txt 文件中读取键值对数据,并通过 Properties 对象进行解析和打印。以下是详细解析:
核心逻辑
(1)创建 Properties 对象:Properties p1 = new Properties() 用于存储从文件中读取的键值对。
(2)读取文件内容:
通过 FileReader 创建字符输入流 r1,关联到 b.txt 文件,然后调用 p1.load(r1) 将文件中的数据加载到 Properties 对象中。
load() 方法会自动解析文件中的键值对(遵循 .properties 格式,如 key=value),忽略注释行(# 开头)和空行。
(3)遍历并打印数据:
通过 p1.stringPropertyNames() 获取所有键的集合,然后遍历集合,通过 getProperty(s1) 获取对应的值并打印。
执行代码后,输出结果会是:
性别__男
姓名__张三
年龄__18关键说明
文件路径:new FileReader("b.txt") 表示读取项目根目录下的 b.txt,若文件不存在会抛出 FileNotFoundException。
load() 方法特性:
自动忽略注释行(# 或 ! 开头)和空行。
支持 key=value、key:value 或 key value(空格分隔)三种键值对格式。
若文件中有中文,FileReader 默认使用平台编码,可能导致乱码,建议指定编码。
这段代码是 Properties 类 “读文件” 功能的典型应用,与之前的 store() 方法(写文件)形成对应,共同实现了配置信息的持久化存储与读取。
public class Demo04 {
public static void main(String[] args) throws IOException {
//Class对象的getResourceAsStream()可以从classpath中读取指定资源
InputStream is=Demo04.class.getResourceAsStream("/jdbc.properties");
Properties p1=new Properties();
p1.load(is);//输入流和p1结合
//打印键值对
for (String key:p1.stringPropertyNames()) {
System.out.println(key+"__"+p1.getProperty(key));
}
is.close();
}
}
这段代码的功能是从类路径(classpath)中读取 jdbc.properties 配置文件,并通过 Properties 类解析和打印其中的键值对,以下是详细说明:
核心逻辑解析
读取类路径资源
通过 Demo04.class.getResourceAsStream("/jdbc.properties") 从类路径根目录获取 jdbc.properties 文件的输入流:
路径中的 / 表示类路径的根目录(通常对应项目的 src/main/resources 目录,编译后会被打包到 classes 目录)。
若文件存在,返回 InputStream 对象;若不存在,返回 null(这也是之前可能出现空指针异常的原因)。
加载配置到 Properties
p1.load(is) 方法将输入流中的配置内容(键值对)加载到 Properties 对象中,自动解析 .properties 格式的内容(忽略注释和空行)。
遍历并打印配置
通过 p1.stringPropertyNames() 获取所有键的集合,遍历后使用 getProperty(key) 获取对应值并打印,实现配置信息的读取展示。
关闭资源
手动调用 is.close() 关闭输入流,释放系统资源。
注意事项
文件位置:确保 jdbc.properties 确实在类路径根目录(如 src/main/resources),且文件名大小写正确(区分大小写)。
路径写法:
带 /(如 /jdbc.properties):从类路径根目录查找。
不带 /:从当前类(Demo04)所在的包路径下查找。
资源关闭优化:推荐使用 try-with-resources 自动关闭流,避免遗漏关闭导致的资源泄漏。
异常处理:若文件不存在,is 会为 null,调用 p1.load(is) 会抛出 NullPointerException,可添加判空逻辑提前处理。
五、Serializable序列化
1.概述
序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。
为什么要把Java对象序列化呢?因为序列化后可以把byte[]保存到文件中,或者把byte[]通过网络远程传输。这样,就相当于把Java对象存储到文件或者通过网络传输出去了。有序列化,就有反序列化,即把一个二进制内容(也就是byte[]数组)变回Java对象。有了反序列化,保存到文件中的byte[]数组又可以“变回”Java对象,或者从网络上读取byte[]并把它“变回”Java对象。
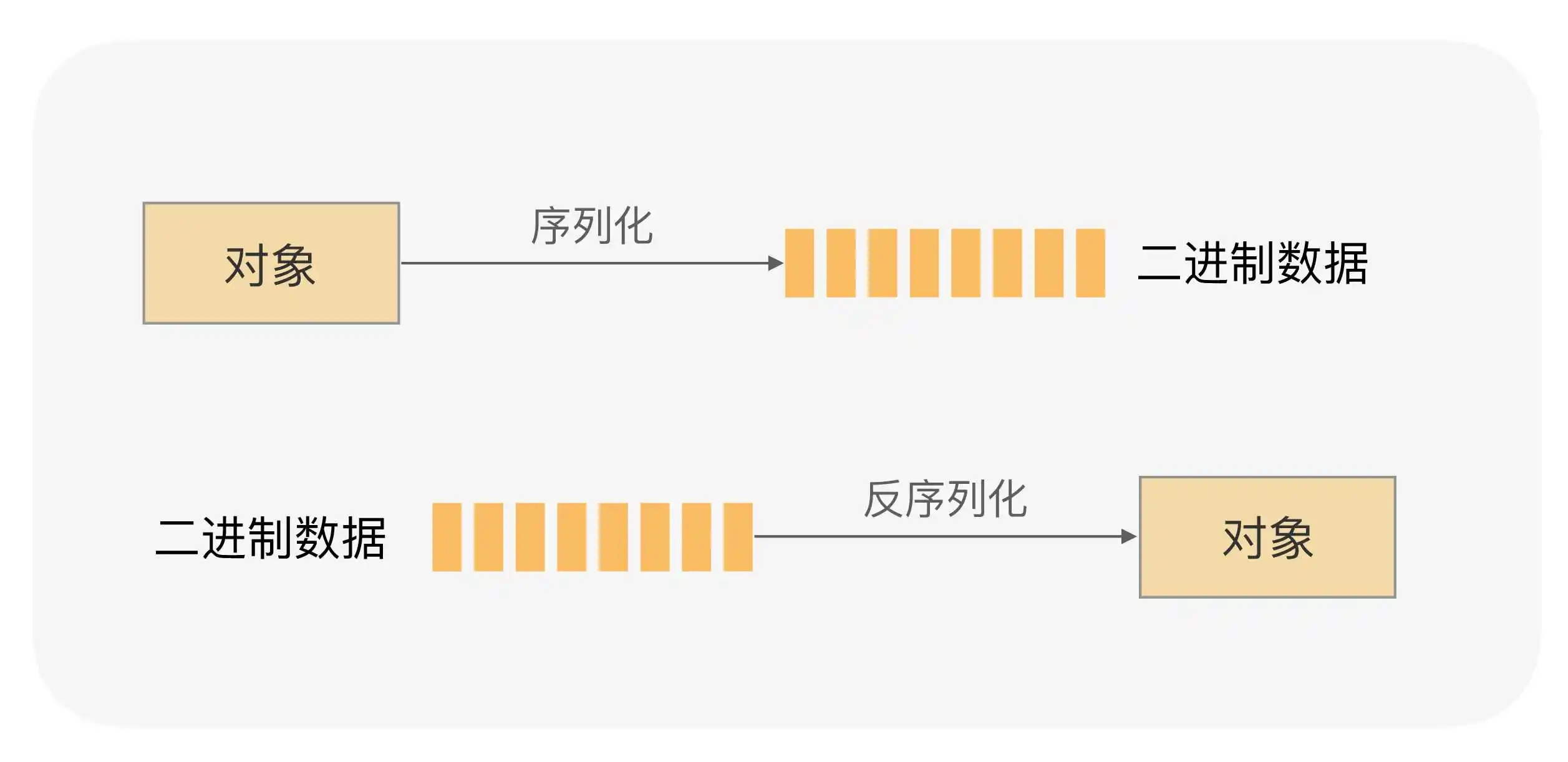
一个Java对象要能序列化,必须实现一个特殊的java.io.Serializable接口,它的定义如下:
public interface Serializable {
}Serializable接口没有定义任何方法,它是一个空接口。我们把这样的空接口称为“标记接口”(Marker Interface),实现了标记接口的类仅仅是给自身贴了个“标记”,并没有增加任何方法。
2.序列化
把一个Java对象变为byte[]数组,需要使用ObjectOutputStream。它负责把一个Java对象写入一个字节流。ObjectOutputStream既可以写入基本类型,如int,boolean,也可以写入String(以UTF-8编码),还可以写入实现了Serializable接口的Object。因为写入Object时需要大量的类型信息,所以写入的内容很大。
import java.io.*;
import java.util.Arrays;
public class Main {
public static void main(String[] args) throws IOException {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
try (ObjectOutputStream output = new ObjectOutputStream(buffer)) {
// 写入int:
output.writeInt(12345);
// 写入String:
output.writeUTF("Hello");
// 写入Object:
output.writeObject(Double.valueOf(123.456));
}
System.out.println(Arrays.toString(buffer.toByteArray()));
}
}
3.反序列化
和ObjectOutputStream相反,ObjectInputStream负责从一个字节流读取Java对象:
try (ObjectInputStream input = new ObjectInputStream(...)) {
int n = input.readInt();
String s = input.readUTF();
Double d = (Double) input.readObject();
}除了能读取基本类型和String类型外,调用readObject()可以直接返回一个Object对象。要把它变成一个特定类型,必须强制转型。
readObject()可能抛出的异常有:
-
ClassNotFoundException:没有找到对应的Class。InvalidClassException:Class不匹配。
对于ClassNotFoundException,这种情况常见于一台电脑上的Java程序把一个Java对象。例如:Person对象序列化以后,通过网络传给另一台电脑上的另一个Java程序,但是这台电脑的Java程序并没有定义Person类,所以无法反序列化。
对于InvalidClassException,这种情况常见于序列化的Person对象定义了一个int类型的age字段,但是反序列化时,Person类定义的age字段被改成了long类型,所以导致class不兼容。
为了避免这种class定义变动导致的不兼容,Java的序列化允许class定义一个特殊的serialVersionUID静态变量,用于标识Java类的序列化“版本”,通常可以由IDE自动生成。如果增加或修改了字段,可以改变serialVersionUID的值,这样就能自动阻止不匹配的class版本:
public class Person implements Serializable {
private static final long serialVersionUID = 2709425275741743919L;
}要特别注意反序列化的几个重要特点:反序列化时,由JVM直接构造出Java对象,不调用构造方法,构造方法内部的代码,在反序列化时根本不可能执行。
4.安全性
因为Java的序列化机制可以导致一个实例能直接从byte[]数组创建,而不经过构造方法,因此,它存在一定的安全隐患。一个精心构造的byte[]数组被反序列化后可以执行特定的Java代码,从而导致严重的安全漏洞。
实际上,Java本身提供的基于对象的序列化和反序列化机制既存在安全性问题,也存在兼容性问题。更好的序列化方法是通过JSON这样的通用数据结构来实现,只输出基本类型(包括String)的内容,而不存储任何与代码相关的信息。
5.小结
(1)可序列化的Java对象必须实现java.io.Serializable接口,类似Serializable这样的空接口被称为“标记接口”(Marker Interface);
(2)反序列化时不调用构造方法,可设置serialVersionUID作为版本号(非必需);
(3)Java的序列化机制仅适用于Java,如果需要与其它语言交换数据,必须使用通用的序列化方法,例如JSON。


















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









