






全文目录:
- 开篇语
- 一、从“集群堆叠”到“操作系统”:重新理解 Kurator 的角色
- 二、生态拼图:Kurator 集成的“八大件”与整体架构想象
- 三、Karmada + Kurator:把多集群当成一个“逻辑集群”来用
- 四、Istio / Nginx + Rollout:把流量当成一等公民的发布中枢
- 五、Prometheus + Thanos + Grafana:从监控走向 SLO 驱动
- 六、KubeEdge + Volcano:云边一体的 AI / 计算场景畅想
- 七、从 DevOps 到 Platform Engineering:Kurator 提供的“黄金路径”
- 八、面向未来的 Kurator:社区协作与方向建议
- 九、结语:Kurator 不是“多一个工具”,而是“少一堆碎片”
- 文末
开篇语
今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
一、从“集群堆叠”到“操作系统”:重新理解 Kurator 的角色
过去几年,容器和 Kubernetes 基本成了“标配”,但真正把业务摊开来看,很多团队会发现:
- 公有云上有几套集群(可能来自不同厂商);
- 私有云里有一套历史悠久的 K8s;
- 边缘节点上还跑着若干 KubeEdge 或轻量发行版;
- 数据批处理、AI 训练、推理工作负载时不时还会用到 Volcano 一类专用调度器。
问题不在于“有没有 K8s”,而在于:所有这些东西加起来是不是一个“能管、能观、能控”的整体。
Kurator 的出现,其实不是再造一个“新 Kubernetes”,而是希望在 K8s 之上,提供一个面向分布式场景的统一操作系统层:
- 利用 Karmada 解决“多集群调度与编排”;
- 利用 Istio / Nginx / Kuma 解决“服务间的流量治理与安全”;
- 利用 Prometheus + Thanos + Grafana 建出“跨集群统一观测平面”;
- 利用 KubeEdge 把边缘节点纳入云原生统一管理;
- 利用 Volcano、Tekton、Kyverno 等组件,在算力调度、CI/CD、策略与安全上补齐能力。
Kurator 做的事情,是把这些能力装进一个有清晰边界、有统一 API、有演进路线的平台里。
换个比喻:
Kubernetes 是“分布式内核”,各类开源项目是“驱动与库”,Kurator 则在尝试扮演一个“多云操作系统”的角色。
带着这个理解再去看 Kurator 的架构、插件体系和未来方向,会更容易抓住重点,而不只是停留在“又多了一套控制器”的层面。
如下正是Kurator产品架构图,仅供参考:
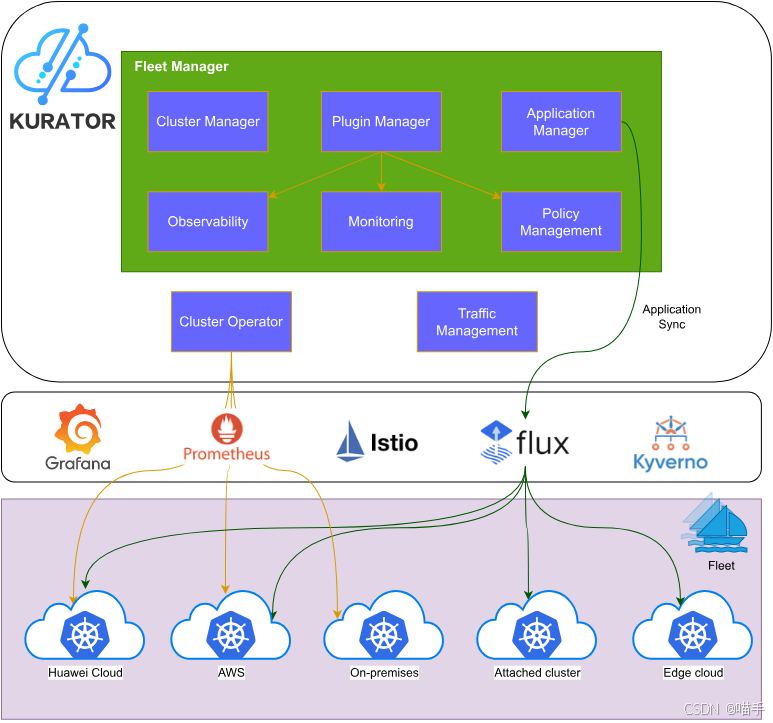
二、生态拼图:Kurator 集成的“八大件”与整体架构想象
从工程视角看,Kurator 不是自己重新造轮子,而是围绕分布式云原生场景,把关键领域的“头部开源项目”串联成一个有机整体:
- Kubernetes:一切的基础运行时;
- Karmada:多集群编排与调度层;
- Istio / Nginx / Kuma:流量治理与服务网格;
- Prometheus + Thanos + Grafana:可观测性平面;
- FluxCD / ArgoCD:GitOps 式应用分发;
- KubeEdge:云边协同桥梁;
- Volcano:面向 AI / 批任务的高阶调度;
- Tekton + Tekton Chains / Kyverno:流水线与供应链安全、策略治理。
Kurator 在其之上,提供了几类关键抽象:
- Cluster / AttachedCluster / Fleet:把「具体集群」抽象为可以被组织、分组、纳管的资源对象;
- Application / Rollout:把「应用及其生命周期」抽象为多集群范围内可统一编排的实体;
- Plugin(metric、policy、pipeline 等):通过插件机制把监控、策略、流水线等能力挂载到 Fleet 上;
- 控制面组件(Fleet Manager、Cluster Operator、Application Controller 等):负责解释这些抽象,并同底层项目交互。
如果用一句话概括:
Kurator 用 CRD 把一堆松散的“云原生乐高”拼成了一套带语义的“分布式平台 DSL”。
后面每一节,我们会分别选一个“生态拼图块”,结合 Kurator 的抽象谈谈它的创新点,并穿插一些配置与代码示例,从一个更偏“设计与前瞻”的视角聊 Kurator 能做到什么、还可以做到什么。
三、Karmada + Kurator:把多集群当成一个“逻辑集群”来用
3.1 多集群调度的两类极端做法
在没有 Karmada / Kurator 的年代,多集群调度一般有两种极端做法:
-
极端一:完全手动
- 每个集群一份 Deployment / Helm values;
- 通过人手或脚本进行分发与升级;
- 优点是简单,缺点是极易“版本漂移”。
-
极端二:自建控制面
- 自己写控制器拉取各集群指标,再决定调度策略;
- 对团队要求高,很难在复杂业务压力下保持迭代与稳定。
Karmada 试图提供的是一种“标准化的多集群 Kubernetes API”:你可以像对单集群操作那样,用 CRD 描述多集群分发逻辑与覆盖策略。
Kurator 则在 Karmada 之上,组织出“Fleet 级别”的管理形态,让多集群调度和应用分发、策略、监控等能力更自然地协同起来。
3.2 基于 PropagationPolicy 的差异化调度示例
假设你希望在三个集群中部署某个网关服务:
cluster-prod-main:生产主集群,部署 5 副本;cluster-prod-backup:同城备集群,部署 2 副本;cluster-oversea:海外集群,部署 3 副本,但需要自定义域名。
你可以利用 Karmada 的 PropagationPolicy + OverridePolicy 能力(Kurator 管控的前提下使用),示例 YAML 如下(内容基于官方 API 样式重新组织):
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: gw-propagation
namespace: gateway
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: edge-gateway
placement:
clusterAffinity:
clusterNames:
- cluster-prod-main
- cluster-prod-backup
- cluster-oversea
---
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: gw-override
namespace: gateway
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: edge-gateway
overrideRules:
- targetCluster:
clusterNames:
- cluster-prod-main
overriders:
replicasOverrider:
value: 5
- targetCluster:
clusterNames:
- cluster-prod-backup
overriders:
replicasOverrider:
value: 2
- targetCluster:
clusterNames:
- cluster-oversea
overriders:
replicasOverrider:
value: 3
plaintext:
- path: /spec/template/spec/containers/0/env/0/value
operator: replace
value: "https://gw-oversea.example.com"
在 Kurator 的世界里,这些 Karmada 资源并不是“孤立存在”,而是会与 Fleet 中的 clusters 绑定,从而让你在 Fleet 维度理解“这条策略是给哪个多集群业务域用的”。
3.3 前瞻构想:多维调度和智能决策
站在前瞻角度看,Karmada + Kurator 的组合还有非常大的想象空间,例如:
- 把 成本、碳排放、能效 指标加入调度维度;
- 和业务侧的 SLA / SLO 紧密结合,按“用户体验损伤最小”的方式搬迁工作负载;
- 在 Fleet 层做“策略模板”,允许业务方只声明“我想保证 99.95% 可用、延迟 < 100ms”,具体调多少副本、放在哪个集群由平台自动完成。
这些都需要在 Kurator 的 CRD 设计和控制器逻辑中进一步抽象,现在已经有了不错的底座,剩下就是“把数学和工程填进去”的问题了。😉
正如如下云原生LOGO一样,未来可期:

四、Istio / Nginx + Rollout:把流量当成一等公民的发布中枢
4.1 从“版本驱动”到“流量驱动”的发布范式
传统的发布逻辑是“版本驱动”的:
- 改镜像 tag;
- Rolling Update 或直接替换;
- 如果挂了,就回滚。
在多集群、多区域业务场景里,这种方式的风险与不确定性迅速放大——一个版本问题同时冲击多个区域,恢复成本难以承受。
现代云原生发布更偏向“流量驱动”:
- 先把新版本部署好,但不立即切大量流量;
- 通过金丝雀 / A/B / 蓝绿等策略,按照流量梯度、用户分组来渐进放量;
- 决策依据来自指标、日志与用户反馈,而不只是“发布脚本执行成功”。
Kurator 的 Rollout 抽象,正是在服务网格(Istio 等)之上,提供了一套更声明式、与 Application / Fleet 深度集成的发布控制 DSL。
4.2 Rollout + VirtualService 的协同示例
假设我们有一个 recommendation 服务,通过 Istio 暴露为 recommendation.default.svc.cluster.local,我们想实现这样的策略:
- 初始阶段 5% 流量进入 v2;
- 每 3 分钟评估一次 Prometheus 指标;
- 只要错误率小于 0.5%,并且 95 分位延迟低于 200ms,就继续增加 10% 流量;
- 如果任一条件超出阈值,则自动停止放量并回滚。
可以用 Kurator Rollout + Istio VirtualService 配合完成(示意 YAML):
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: recommendation-canary
namespace: default
spec:
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: recommendation
traffic:
istio:
virtualService: recommendation-vs
stableSubset: v1
canarySubset: v2
metrics:
- name: error-rate
query: |
sum(rate(istio_requests_total{
destination_workload="recommendation",
response_code=~"5.."
}[1m]))
/
sum(rate(istio_requests_total{
destination_workload="recommendation"
}[1m]))
thresholdRange:
max: 0.005
- name: p95-latency
query: |
histogram_quantile(0.95,
sum(
rate(istio_request_duration_milliseconds_bucket{
destination_workload="recommendation"
}[1m])
) by (le)
) / 1000.0
thresholdRange:
max: 0.2
strategy:
canary:
initialWeight: 5
stepWeight: 10
maxWeight: 80
stepInterval: 3m
Istio 的 VirtualService 可以保持比较“标准的”配置,例如:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: recommendation-vs
namespace: default
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
subset: v1
weight: 95
- destination:
host: recommendation
subset: v2
weight: 5
Rollout 控制器在每次评估指标后,会自动更新 VirtualService 中的权重配置,从而完成“以指标驱动的流量渐进调整”。
4.3 展望:把业务实验与发布策略打通
未来完全可以想象 Kurator 在 Rollout 层做更多事,例如:
- 与 A/B Testing 平台打通,把“实验组划分”直接映射成流量路由规则;
- 与业务 BI 指标(转化率、留存率)相结合,在微服务粒度实施“业务表现优先”的自动发布决策;
- 提供统一的“发布实验 API”,供算法团队或者产品团队创建对照试验。
一旦这些能力沉淀在 Kurator 的 CRD 与控制器中,平台团队就可以为企业构建出一套真正“以试验和用户价值为中心”的发布体系,而非单纯追求“上线成功率”。
如下为Kurator产品架构图,仅供参考:
五、Prometheus + Thanos + Grafana:从监控走向 SLO 驱动
5.1 多集群监控的结构化抽象
在 Kurator 的设计里,“统一监控”并不只是“把多个 Prometheus 的指标聚合到一起看”,而是把监控视为 Fleet 级别、跨集群的基础能力:
- 成员集群:运行 Prometheus,用于本地采集指标;
- 管理平面:运行 Thanos / 聚合查询服务;
- Grafana:面向最终使用者提供统一看板。
对用户来说,最重要的不是“部署了几套监控”,而是:
- 可以在一张图上看到“所有用户-facing 服务”的 全局错误率;
- 可以在多集群间对比某服务的 QPS、延迟、资源占用;
- 可以为某个“产品功能”定义 SLO,并追踪是否达标。
5.2 基于 Thanos 的跨集群全局错误率示例
假设我们想要定义一个电商网站 checkout 接口的全局错误率指标(跨集群):
sum by (status_class) (
rate(
http_requests_total{
app="checkout",
status_class=~"5xx"
}[5m]
)
)
/
sum(
rate(
http_requests_total{
app="checkout"
}[5m]
)
)
在 Thanos 视角下,只要每个集群的指标符合同一套 label 规范,就可以自然做到“跨集群求和再求比率”。
配合 Kurator 提供的统一监控插件(在 Fleet spec 中开启 metric 插件),平台团队可以规定:
- 每个纳入 Fleet 的集群必须以统一方式部署指标采集;
- 应用团队只要遵守统一 label 约定(如
app、status_class等); - SRE 团队则可以在 Grafana 中构建全局 SLO 看板,甚至在 Kurator 上层用 CRD 形式定义 SLO。
5.3 前瞻:把 SLO 写进 CRD
一种很自然的前瞻设想是:在 Kurator 中引入 SLO CRD,例如:
apiVersion: slo.kurator.dev/v1alpha1
kind: ServiceSLO
metadata:
name: checkout-slo
namespace: observability
spec:
selector:
app: checkout
objective:
availability: "99.95"
latency:
thresholdMs: 200
percentile: 95
window: 7d
errorBudgetPolicy:
burnRateAlerts:
- shortWindow: 5m
longWindow: 1h
threshold: 4
- shortWindow: 30m
longWindow: 24h
threshold: 2
配合 Thanos / Prometheus 的 query,Kurator 完全可以实现:
- 自动生成对应的告警规则;
- 在 Fleet 范围内推送相同的 SLO 定义;
- 在平台 UI 中展示 error budget 消耗情况。
这就是从“采指标”迈向“以 SLO 驱动平台运行”的关键一步。
Kuasar Architecture相关架构图如下所示:
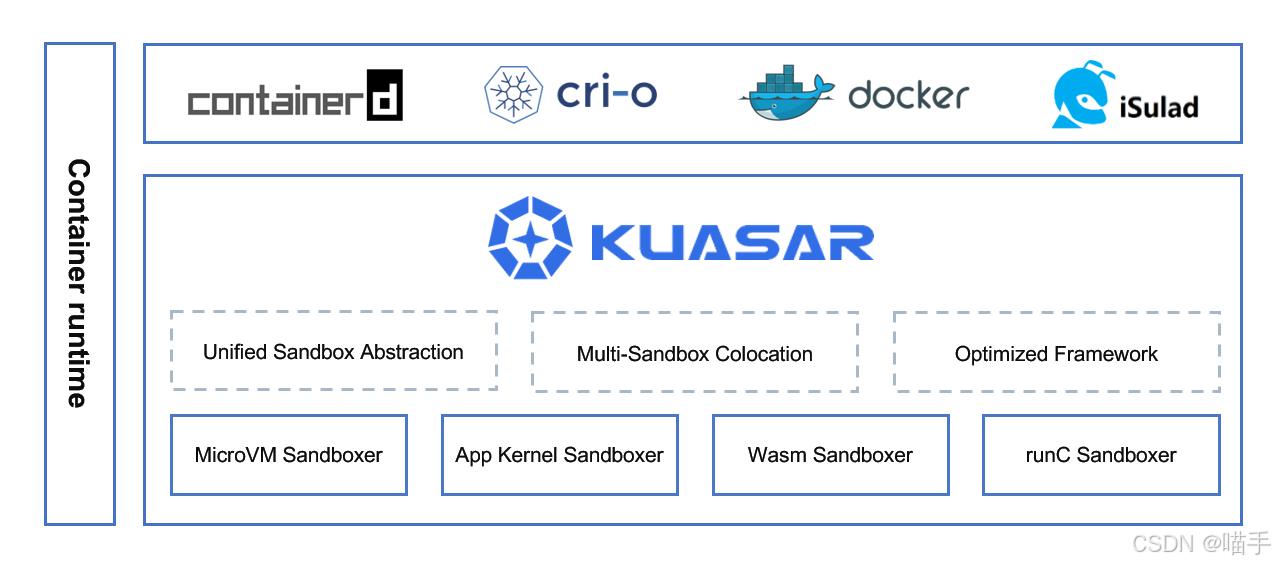
六、KubeEdge + Volcano:云边一体的 AI / 计算场景畅想
6.1 云边协同的典型痛点
在 IoT、工业互联网、视频分析、车路协同等场景里,经常会出现这样的需求组合:
- 边缘节点上需要实时处理(如视频流、人流统计、即时告警等);
- 云侧负责模型训练与集中调度;
- 边缘算力有限,希望把某些批量任务“推回云上”处理;
- 同时要保证网络不稳定时系统仍能工作。
KubeEdge 在“让边缘节点变成 K8s Worker”这件事上提供了很好的基础设施,Volcano 则专注于批任务 / AI 训练调度。
如果我们在 Kurator 中把某一类 Fleet 定义为“Edge Fleet”,并在其中启用 KubeEdge / Volcano 相关插件,就可以构想出一套非常统一的云边协同工作流。
6.2 Edge Fleet + Volcano Job 示例
假设我们有一批边缘网关,需要周期性地把本地采集的数据打包发送云侧做离线分析,同时希望利用 Volcano 对这些批任务进行更精细的资源调度。
首先在 Kurator 中定义一个 Edge Fleet(示意):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: edge-fleet
namespace: default
spec:
clusters:
- name: edge-cluster-1
kind: AttachedCluster
- name: edge-cluster-2
kind: AttachedCluster
plugin:
edge:
kubeEdge:
enabled: true
tunnel:
mode: websocket
batch:
volcano:
enabled: true
然后,在云侧为批处理任务定义一个 Volcano Job:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: offline-analytics
namespace: analytics
spec:
minAvailable: 3
schedulerName: volcano
tasks:
- replicas: 3
name: data-cruncher
template:
spec:
containers:
- name: cruncher
image: registry.example.com/analytics/offline-cruncher:v1
resources:
requests:
cpu: "4"
memory: "8Gi"
limits:
cpu: "8"
memory: "16Gi"
restartPolicy: Never
通过 Karmada / Kurator 的多集群编排能力,这个 Volcano Job 可以选择在某些具有较强算力、靠近数据源的集群上运行。
再进一步,如果我们把“边缘数据汇聚、清洗、上传”的任务也纳入 Kurator 的 Application / Pipeline 中,就可以构建出:
- 边缘侧:轻量推理 + 数据缓存;
- 云侧:批处理 / 训练任务由 Volcano 管理;
- Fleet 层:统筹资源与策略;
- 整体通过 GitOps 与 Rollout 控制升级。
6.3 前瞻:AI Native 架构下的 Kurator 位置
在 AI Native 趋势下,未来应用将更加依赖 GPU / NPU 等专用算力、多地域调度与数据分级存储。Kurator 结合 Volcano、KubeEdge 的能力,有机会在以下方向上发挥更大价值:
- 统一抽象“算力池”,让业务只关心“我要 N 张 A10 / H100”,具体在哪个云、哪个机房由平台调度;
- 提供 AI 工作流级别的 Rollout / Chaos / 观测能力;
- 在 Fleet 层支持“算力租户”的隔离与计费。
这些都不是“一两行 YAML 就能搞定”的功能,但 Kurator 已经具备了构建这些能力的骨架,社区和用户的反馈,会直接决定它未来的演进深度。
MicroVM Sandboxer流程图示意如下:
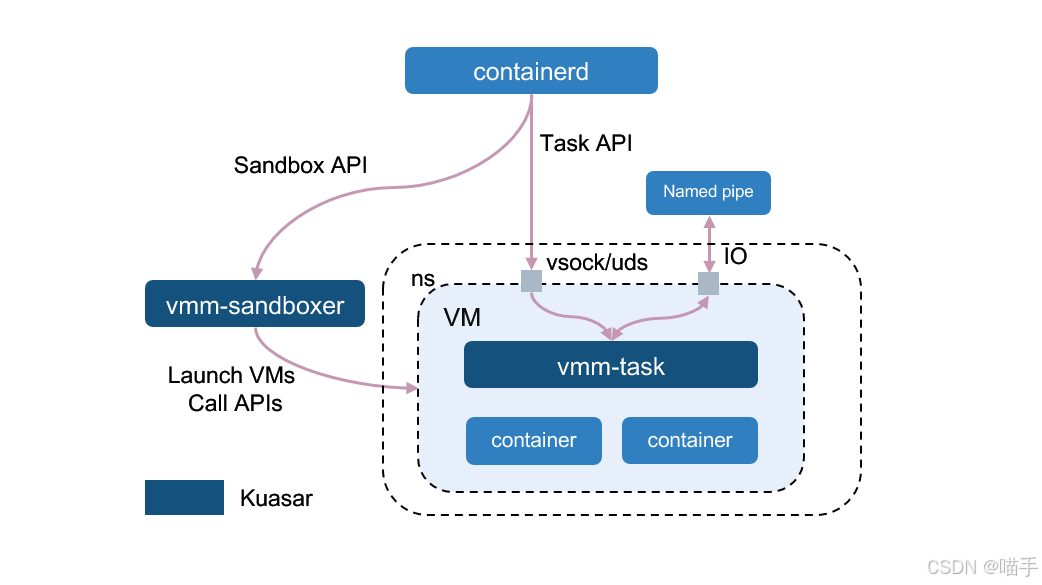
七、从 DevOps 到 Platform Engineering:Kurator 提供的“黄金路径”
7.1 用一条“黄金路径”串起来开发、发布与治理
Platform Engineering 的核心思想是:
给开发者一条“内建安全、可观测、可扩展”的黄金路径,而不是塞给他们一堆工具。
在 Kurator 的语境下,这条黄金路径大致可以长成这样:
- 开发者:把业务代码 push 到 Git 仓库;
- Pipeline(Tekton):自动执行测试、构建镜像、生成 SBOM、做安全扫描并签名;
- GitOps(Flux / Application):接到镜像更新信息后,更新多集群应用配置;
- Rollout:按策略进行渐进式发布,并以指标为依据决策;
- Policy(Kyverno):在 Fleet 范围内强制执行安全基线和资源配额;
- Metric / Logging:通过统一监控查看业务健康与 SLO 达成情况。
开发者看到的是一个“简单”的体验:
- 推一次代码;
- 过几分钟收到通知:测试通过、版本已在几个区域“金丝雀 10%”;
- 如果表现良好,就自动放量甚至完成全量切换。
而平台工程团队看到的,则是一套“从代码到多云、多集群平台”的连贯控制面。
7.2 Pipeline 示例:把安全嵌进 CI/CD
下面是一个更偏“DevSecOps”视角的 Kurator Pipeline 资源示例(结构基于 Tekton 典型用法改写):
apiVersion: pipeline.kurator.dev/v1alpha1
kind: Pipeline
metadata:
name: checkout-ci
namespace: cicd
spec:
repo:
url: https://github.com/example-org/checkout-service.git
revision: main
tasks:
- name: clone
template: git-clone
params:
- name: depth
value: "1"
- name: unit-test
template: go-test
runAfter: ["clone"]
- name: build-image
template: build-and-push-image
runAfter: ["unit-test"]
params:
- name: image
value: registry.example.com/checkout-service:$(revision)
- name: generate-sbom
template: syft-sbom
runAfter: ["build-image"]
params:
- name: image
value: registry.example.com/checkout-service:$(revision)
- name: vuln-scan
template: grype-scan
runAfter: ["generate-sbom"]
- name: sign-image
template: cosign-sign
runAfter: ["vuln-scan"]
params:
- name: image
value: registry.example.com/checkout-service:$(revision)
chainSecurity:
enabled: true
attestation:
type: in-toto
store:
type: oci
url: registry.example.com/attestations
在 Kurator 的控制面上,这条 Pipeline 可以与 Application / Rollout 进一步打通:
- 只有当
vuln-scan通过、sign-image成功,才更新 GitOps 仓库中的版本号; - Rollout 在部署新版本时,校验镜像签名与 SBOM 元数据;
- Policy 层还可以规定“未通过扫描的镜像禁止调度到生产 Fleet”。
当然,它的开源社区也做的非常棒:
7.3 使用 Go 客户端操作 Kurator CRD 的示例代码
对部分平台团队而言,光靠 YAML 还不够,他们需要编写 Go / Java 等工具,自动化操作 Kurator 的 CRD。下面是一个简化的 Go 示例,演示如何通过 client-go 创建一个 Fleet 资源(仅示意):
package main
import (
"context"
"flag"
"fmt"
"k8s.io/client-go/dynamic"
"k8s.io/client-go/tools/clientcmd"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime/schema"
"k8s.io/apimachinery/pkg/apis/meta/v1/unstructured"
)
var fleetGVR = schema.GroupVersionResource{
Group: "fleet.kurator.dev",
Version: "v1alpha1",
Resource: "fleets",
}
func main() {
kubeconfig := flag.String("kubeconfig", "/path/to/kubeconfig", "kubeconfig path")
flag.Parse()
cfg, err := clientcmd.BuildConfigFromFlags("", *kubeconfig)
if err != nil {
panic(err)
}
client, err := dynamic.NewForConfig(cfg)
if err != nil {
panic(err)
}
fleet := &unstructured.Unstructured{
Object: map[string]interface{}{
"apiVersion": "fleet.kurator.dev/v1alpha1",
"kind": "Fleet",
"metadata": map[string]interface{}{
"name": "auto-created-fleet",
"namespace": "default",
},
"spec": map[string]interface{}{
"clusters": []interface{}{
map[string]interface{}{
"name": "cluster-a",
"kind": "AttachedCluster",
},
map[string]interface{}{
"name": "cluster-b",
"kind": "AttachedCluster",
},
},
},
},
}
ctx := context.Background()
result, err := client.Resource(fleetGVR).
Namespace("default").
Create(ctx, fleet, metav1.CreateOptions{})
if err != nil {
panic(err)
}
fmt.Printf("Created Fleet %s\n", result.GetName())
}
这种方式使得平台团队可以根据业务目录结构、CMDB、成本数据等,在自身系统里计算好“应该有哪些 Fleet、应该纳管哪些集群”,再通过 Kurator 的 CRD 统一落地,从而真正把 Kurator 融入企业现有系统。
App Kernel Sandboxer:
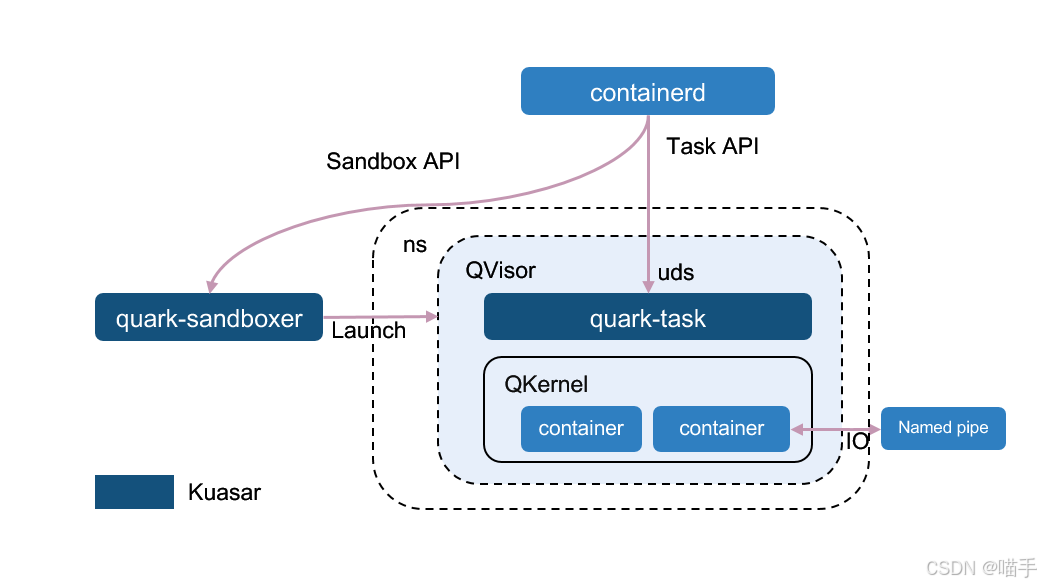
八、面向未来的 Kurator:社区协作与方向建议
8.1 可以一起做的几件事(社区贡献视角)
虽然本篇以“前瞻创想”为主,但如果你想按【贡献经历】方向投稿,其实完全可以基于以下几个角度展开:
-
文档与实践指南
- 基于自己行业(金融、制造、运营商等)的经验,补充更贴近行业的实践文档;
- 完善多云 / 边缘场景下的“最佳实践”章节;
-
插件与集成扩展
- 为 Kurator 开发新的插件(例如日志、APM、成本分析);
- 把公司内部的身份系统、审计系统以插件形式接入 Kurator;
-
CRD 设计与控制器逻辑优化
- 提出更通用的 CRD 设计建议,例如 SLO、CostPolicy、ChaosPlan 等;
- 在 Issue / PR 中反哺你在大规模集群上的实践经验。
在这些方向上做出的贡献,既能解决自己的真实问题,又能推动社区向更加工程化、可落地的方向演进,是典型的“双赢”。
8.2 对分布式云原生未来的几点个人看法
结合 Kurator 以及周边生态的发展,我觉得未来的分布式云原生大概率会沿着下面几条主线继续演化:
-
控制面“可组合化”
- 不同企业会按需选择 Karmada / Istio / Cilium / Volcano 等组件;
- 像 Kurator 这样的项目,需要提供更灵活、可插拔的控制面组合方案。
-
策略语言统一化
- 从 NetworkPolicy、PodSecurityPolicy(或 Pod Security)、RBAC、Kyverno Policy,到各类自定义业务策略,现在策略表达非常碎片化;
- 未来很可能需要某种“统一策略 DSL”,Kurator 完全可以担当“策略编排中枢”的角色。
-
智能调度与自动运维(AIOps)深入融合
- 监控与日志不再只是“画图看”,而是驱动自动化诊断、修复和容量规划;
- Fleet / Rollout / Application 都可能成为 AI 系统的“动作执行器”,自动完成调度与治理。
-
安全与合规前置化
- 在软件供应链攻击日益增多的背景下,从 SBOM、镜像签名到运行时策略,需要“默认安全”和“全路径可溯”;
- Kurator 已经开始把 Tekton Chains、Kyverno 等能力拉进统一平台,未来可以进一步打通 DevSecOps 闭环。
在这些方向上,任何一次真实的大规模实践心得、一次针对 CRD 设计的深入讨论,甚至一个“踩坑总结”,对社区都是非常宝贵的推动力。
同时也提供了开源项目信息阐述:
九、结语:Kurator 不是“多一个工具”,而是“少一堆碎片”
如果一定要用一句话来收尾这篇【前瞻创想】,我会说:
Kurator 的价值,不在于“多提供了一个新工具”,而在于让你能“少维护一堆彼此不了解的工具”。
它尝试提供的是一种 更有结构的分布式云原生世界观:
- 集群不是一个个孤立的“资源池”,而是可以被编队成 Fleet 的“舰船”;
- 应用不是堆在 YAML / Helm 里的配置,而是具有生命周期、版本、发布策略和观测目标的实体;
- 监控、策略、安全、流水线也不再是平行宇宙,而是聚合在同一套控制面上的协同能力。
无论你今天把 Kurator 当成多集群管理平台、多云控制平面、还是平台工程的基础底座,它都提供了一个值得持续投入的方向——用开源的方式,为自己的分布式云原生“操作系统”打底。
Wasm Sandboxer:
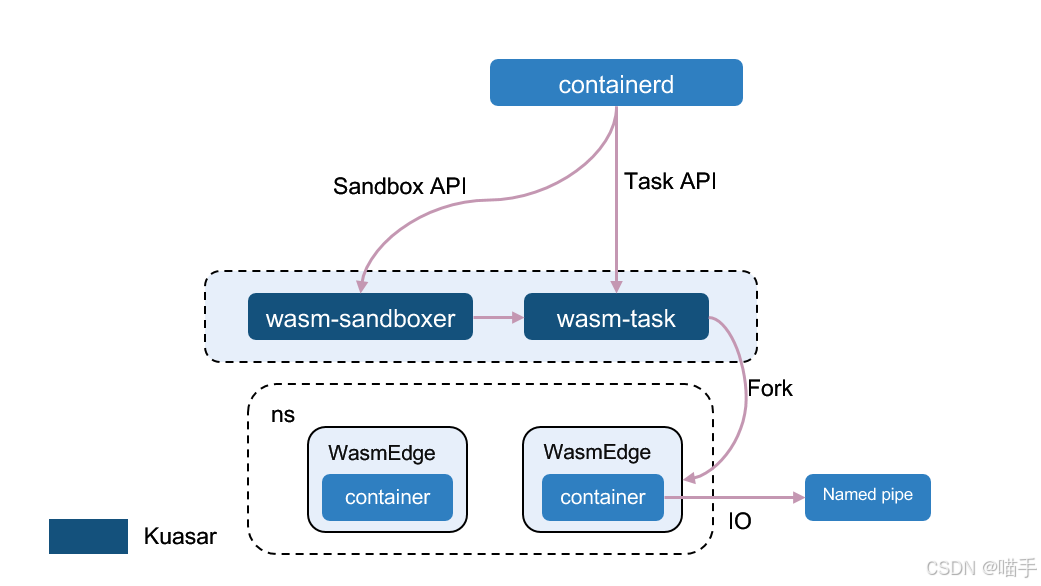
… …
文末
好啦,以上就是我这期的全部内容,如果有任何疑问,欢迎下方留言哦,咱们下期见。
… …
学习不分先后,知识不分多少;事无巨细,当以虚心求教;三人行,必有我师焉!!!
wished for you successed !!!
⭐️若喜欢我,就请关注我叭。
⭐️若对您有用,就请点赞叭。
⭐️若有疑问,就请评论留言告诉我叭。
版权声明:本文由作者原创,转载请注明出处,谢谢支持!

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









