



1、常⻅的集合有哪些?(537/1759=30.5%)
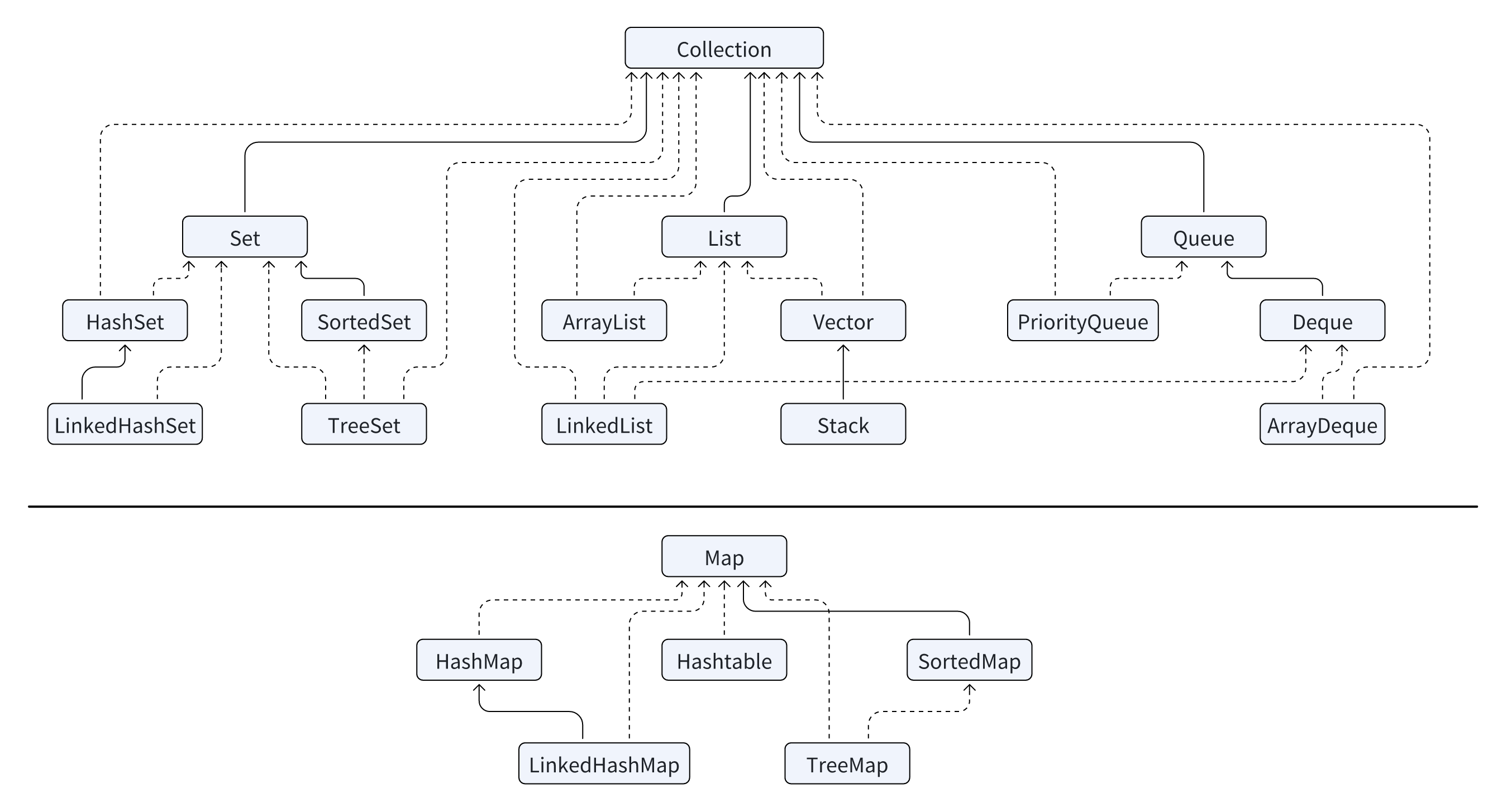
Java 集合框架分为单列集合和双列集合两大类。
首先是单==列集合==,它以 Collection 为核心接口,主要分为三种:
第一种是 List,用于==存储有序且可重复==的元素,比如 ArrayList 基于动态数组,访问快但插入删除慢;LinkedList 基于双向链表,插入删除快但访问慢;Vector 是线程安全的老版本实现。
第二种是 Set,用于==存储无序且不可重复的元素==,比如 HashSet 基于哈希表,查找快但无序;LinkedHashSet 保留插入顺序;TreeSet 基于红黑树,按顺序存储。
第三种是 Queue,用于==队列操作==,比如 PriorityQueue 基于堆实现按优先级处理,ArrayDeque 是双端队列支持栈和队列操作。
接下来是==双列集合==,它以 Map 为核心接口,用于存储键值对,比如:HashMap 基于哈希表,键无序且查找快;LinkedHashMap 保留插入顺序;TreeMap 基于红黑树,按键的自然顺序排序;Hashtable 是线程安全的老版本实现。
List → “爱(A)连(L)薇(V)” → ArrayList、LinkedList、Vector
Set → “哈(H)连(L)树(T)” → HashSet、LinkedHashSet、TreeSet
Queue → “排(P)啊(A)” → PriorityQueue、ArrayDeque
双列集合:
Map → “哈(H)连(L)树(T)表(H)” → HashMap、LinkedHashMap、TreeMap、Hashtable
拓展:
1.Java 集合框架图
2.为什么要使用集合?
集合的引入源于开发过程中对高效数据存储和操作的需求。在早期的程序开发中,虽然可以使用数组和链表来存储和操作数据,但这些传统的数据结构存在许多==局限性==,无法满足实际复杂场景中的需求。
(1)数组的局限性:
- 固定大小: 数组长度在创建时必须指定,且无法动态扩容。
- 操作不灵活: 删除或插入元素需要手动移动数组中的数据,效率低下。
- 无重复性控制: 无法直接限制元素的重复性,也无法方便地去重。
(2)链表的不足:
查找效率低: 链表需要线性遍历才能查找指定元素,效率较低。
没有顺序控制: 无法快速获取数据的有序排列。
(3)无法满足常见需求:
去重和无序存储: 实际开发中,经常需要存储一组不重复的元素,但数组和链表没有内置的去重功能。
快速查找: 对于大规模数据,程序需要高效的查找和访问方式。
动态扩容: 数据量变化时,无法高效地动态调整存储大小。
3.学生名单的去重问题假设一个班级有 100 个学生,但由于系统问题,学生报名时可能会重复登记。我们希望存储一份不包含重复学生的名单。
传统方法(数组):
如果用数组存储学生姓名,我们需要手动遍历数组检查是否已经存在相同的学生,这会随着数据量增大变得非常低效。在添加新学生时,还可能需要动态调整数组大小,这进一步增加了复杂性。
使用集合:
使用 HashSet 存储学生名单:它会自动过滤掉重复的学生(基于哈希算法)。不需要手动调整大小或遍历去重,只需调用 add() 方法即可完成操作。代码逻辑简单,执行效率高,即使学生数量增大到几千甚至几万,性能仍然优异。
4.如果只有单列集合,没有双列集合,会发生什么?
双列集合最核心的特性是以==键值对形式存储数据,每个键唯一且对应一个值==。如果没有双列集合,会导致:
需要==手动管理键值关系==: 开发者需要用单列集合(如List)分别存储键和值,自己维护它们的对应关系,增加了开发复杂度。
效率低下: 查找某个键对应的值需要遍历整个键的集合,而不是像Map一样通过哈希或排序快速定位。
例子:学生学号与姓名的关系
使用Map,可以直接存储学号作为键,姓名作为值,通过学号快速找到对应的学生。
如果只有单列集合,你需要用两个List分别存储学号和姓名,并在查找时遍历学号列表,效率低且容易出错。
2、ArrayList和LinkedList的区别?(479/1759=27.2%)
==ArrayList 和 LinkedList 都是常用的线性数据结构,但它们在存储方式、访问效率、插入删除操作以及适用场景==上存在显著差异。接下来,我将具体说明这些方面的区别。
第一点是存储空间上的差异
ArrayList:底层是基于==数组实现的,要求物理内存上必须是连续的。==
LinkedList:底层是基于==双向链表实现的,逻辑上是连续的,但物理内存不需要连续。==
第二点是随机访问效率的差异
ArrayList:由于底层是==数组,支持按索引进行 O(1)== 的随机访问。
LinkedList:由于是==链表结构==,随机访问需要从头遍历到目标位置,时间复杂度为 O(N)。
第三点是头插效率的差异
ArrayList:头插时,需要移动大量元素来腾出空间,效率较低,时间复杂度为 O(N)。(由于 ArrayList 是基于数组实现的,当你在头部插入元素时,所有已有的元素都需要向后移动一个位置)
LinkedList:头插时,只需修改指针的指向,效率高,时间复杂度为 O(1)。(是基于链表实现的)
(Java 是没有显式指针的,所有的指针操作都通过引用来实现。在 Java 中,指针的概念是由引用(reference)代替的,引用指向内存中的对象。
在 LinkedList 中,当我们说“修改指针的指向”时,实际上是修改节点的 引用。具体来说,链表的每个节点都有一个指向下一个节点的引用(通常称为“next”)。在头插操作中,我们通过修改头节点的引用,让新的节点指向原来的头节点,而头节点的引用指向新的节点。)
第四点是扩容效率的差异
ArrayList:插入时,如果空间不足需要扩容,扩容会新建一个更大的数组,并将旧数据复制过去,影响性能。
LinkedList:没有容量的概念,插入时只需更新节点指针,不涉及扩容操作。
第五点是应用场景的差异
ArrayList:适合用于对元素的==高效存储和频繁访问的场景。==
LinkedList:适合==任意位置插入和删除频繁==的场景。
拓展:
1.数组和链表在JAVA中的区别?
数组的内存是连续分布的,每个元素大小固定,这使得它可以通过内存地址加上下标 * 元素大小直接计算出目标元素的访问地址,从而实现 O(1) 的高效随机访问。但正因为数组必须保证内存连续性,如果在中间插入或删除元素,就需要移动后续所有元素来保持这种连续性,导致==操作效率较低。
![[Pasted image 20251105150654.png]]
链表则不同,它的内存不需要连续分布。链表中的每个节点通过指针连接,这使得链表的内存申请更加灵活,不受连续内存的限制。然而,为了维护这些指针关系,链表需要额外的内存空间存储指针信息,因此总体内存开销会高于数组。链表的随机访问效率较低,因为无法直接通过下标定位目标节点,必须从头节点(或尾节点,在双向链表中)开始遍历,时间复杂度为 O(n)==。不过,链表在插入和删除操作上更具优势,只需调整相关指针,无需像数组那样进行大规模的内存拷贝。
![[Pasted image 20251105150710.png]]
2.空间局部性
从 CPU 缓存亲和性的角度来看,数组占据一定优势。由于数组存储连续,符合空间局部性(spatial locality)原理:当一个存储单元被访问时,它附近的单元很可能会在不久后被访问。
那什么情况下内存中的数据会被提前加载到缓存中呢?答案是当某个元素被用到的时候,那么这个元素地址附近的元素会被提前加载到缓存中。
举个例子,现创建一个整形数组,里面存储1,2,3,4四个整数,当程序用到了数组中的某个元素时(比如1),由于CPU认为既然1被用到了,那么紧邻它的元素2,3,4被用到的概率就很大,所以会提前把2,3,4加载到缓存中,这样CPU再次执行的时候如果用到了2,3,4,直接从缓存里取就行了,能提升不少性能。
而对于链表来说,由于链表的每个结点在内存中都是随机分布的,只是通过指针联系在一起,所以这些结点的地址并不相邻,自然无法利用程序局部性原理来提前加载到缓存中来提升性能了。
3、HashMap的原理是什么?(643/1759=36.6%)
HashMap 是一种基于哈希表的键值对存储数据结构,它的查找很高效,存储性能较好,被广泛用于高效管理和访问数据。HashMap 的实现基于==数组和链表或红黑树,JDK 8之前是数组+链表,JDK 8及之后是数组+链表+红⿊树==。接下来我会讲述它的存储和查找的详细过程。
当==存储一个键值对==时,
首先,HashMap 会用哈希函数计算出键的哈希值(hash code)。
其次,然后用哈希值决定键值对存放的位置(也就是数组的索引)。
然后,如果对应位置的“桶”(数组位置)是空的,键值对会直接存进去。
最后,如果“桶”里已经有其他键值对了(发生哈希冲突),HashMap 会用链表或红黑树来存储多个键值对。
当你==用键去查找对应的值==时,
首先,根据键计算哈希值,快速定位到对应的“桶”(数组索引)。
其次,如果桶内只有一个键值对,直接返回其值。
然后,如果桶内有多个键值对(链表或红黑树,即发生哈希冲突),逐一比对键(equals),找到匹配的目标键。
最后,返回匹配键对应的值。
拓展:
2.为什么采用红黑树而不是采用B+树?
在 HashMap 的实现中,链表长度超过一定阈值(默认 8)时会转换为红黑树,而不是 B+ 树,主要原因如下:
时间复杂度:红黑树是一种平衡二叉搜索树,查找、插入、删除的时间复杂度是 O(log n)。B+ 树虽然在数据库中有优势,但其设计更适合磁盘存储和范围查询,不适合频繁的动态操作。
内存占用:红黑树的内存使用率较低,而 B+ 树由于每个节点存储更多指针,内存开销较大,且不必要。
HashMap 的设计目标:HashMap 的目标是==高效查找,而红黑树能很好地满足这一点,并且它与内存结构更契合。B+ 树则更适合大规模外存数据管理。==
3.哈希值是如何计算出来的?怎么保证尽可能不重复?
哈希值的计算: 在 Java 中,哈希值由对象的 hashCode() 方法生成,默认使用对象的内存地址。但用户可以重写 hashCode() 方法,根据对象的属性计算哈希值。
示例:字符串的 hashCode 算法:
s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
其中,s[i] 是字符串的第 i 个字符,31 是一个常用的素数,可以减少冲突。
尽可能不重复的保障:
使用==素数作为乘法因子==:素数能更好地避免哈希值冲突。
结合对象的多个属性:比如组合使用对象的多个字段,生成独特的哈希值。
确保 equals() 方法和 hashCode() 方法的一致性:两个对象相等时,其哈希值也必须相同。
4.哈希冲突的解决办法有哪些?
当不同的键经过哈希函数计算后,可能产生相同的哈希值,从而映射到哈希表的同一个桶中。
哈希桶(Hash Bucket)是哈希表(Hash Table)中的一个概念,用来存储通过哈希函数计算得出的哈希值相同的元素。哈希表通过哈希函数将元素映射到桶中,而哈希桶则是这些元素的容器。在哈希表中,桶的数量通常取决于哈希表的大小,而每个桶中的元素是通过哈希冲突解决策略来存储的。
解决办法一般有3种,
==拉链法(Chaining):将==所有映射到同一哈希桶中的元素存储为链表(或红黑树)。当冲突较少时,链表的查找复杂度为 O(n),当链表转为红黑树后复杂度降为 O(log n)。
开放地址法(Open Addressing):如果一个位置已经被占用,尝试探查周围其他位置,用来存储冲突的元素。线性探测,依次检查下一个位置。二次探测,按平方步长检查下一个位置。双哈希,使用第二个哈希函数计算探测步长。
==再哈希(Rehashing):==当哈希表负载因子过高时,扩容并重新计算所有键的哈希值,减少冲突。
![[Pasted image 20251105162428.png]]
4、HashMap如何扩容?(671/1759=38.1%)
HashMap 在存储过程中可能会遇到哈希冲突,因此需要使用链表或红黑树来解决这些冲突。然而,随着数据量的增加,冲突可能会加剧,导致访问的时间复杂度无法维持在 O(1) 的水平。此时,就需要进行扩容。
在 HashMap 中有一个阈值的概念,HashMap 在元素数量超过阈值时,就会触发扩容,例如,如果我们创建一个大小为 16 的 HashMap,那么默认的阈值为 16 * 0.75 = 12。这意味着一旦 HashMap 中的元素数量超过 12,就会触发扩容。(0.75是负载因子)
扩容时HashMap 会==先新建一个数组,新数组的大小是老数组的两倍==,然后会将 HashMap 内的元素重新哈希,映射并搬运到新的数组中。
在JDK 1.8 及之后对扩容进行了改进,通过==位运算判断新下标位置==,而不需要每个节点都重新计算哈希值,提高了效率。
举例来说,如果旧数组的长度是 16(在二进制中表示为 010000),而新数组的长度是 32(在二进制中表示为 100000)。
所以重点就在 key 的 hash 值(32位)的从右往左数第五位(最高位,如果时32和64则为第六位)是否是 1,如果是1说明需要搬迁到新位置,且新位置的下标就是原下标+16(原数组大小),如果是0说明吃不到新数组长度的高位,那就还是在原位置,不需要迁移。
如果货物编号的二进制高位(第五位)为 1,就放到新仓库的高位;如果是 0,位置不变。
拓展:
1.为什么采用2倍扩容,而不是1.5倍或者3倍扩容?
HashMap 采用 2 倍扩容,是为了性能优化、空间利用率和实现简单性的综合平衡,避免了 1.5 倍或 3 倍扩容带来的复杂性和资源浪费问题。
(1)保持哈希分布均匀性
HashMap 扩容后需要重新计算键值对的位置。如果新数组大小是 2 的幂,则通过==位运算(key.hash & (newCapacity - 1))来定位数组索引。这种位运算是非常高效的,避免了取模运算(%)的性能开销。如果选择其他扩容倍数(如 1.5 倍或 3 倍),就无法简单通过位运算完成定位,计算索引的效率会降低==。
(2)节约内存碎片,防止浪费空间
1.5 倍扩容:扩容后的数组大小无法保证是 2 的幂。这样 HashMap 的存储空间利用率可能下降,影响键值对的哈希分布,增加哈希冲突。
3 倍扩容:虽然可以减少扩容的频率,但扩容时占用内存会瞬间大幅增加,浪费内存空间。尤其在数据量大的情况下,内存分配的压力会显著增加。
(3)减少扩容频率与内存占用的平衡
扩容过小(如 1.5 倍)会导致频繁扩容,而扩容过大(如 3 倍)会导致一次性占用过多内存。2 倍扩容在扩容频率和扩容成本之间取得了一个平衡:扩容后内存增长速度适中,只需重新分配内存并搬移数据,避免了频繁扩容的性能开销。
(4) 兼容性与实现简单性
Java 中 HashMap 的容量始终是 2 的幂次方。2 倍扩容后,容量仍然是 2 的幂,哈希计算和分布规则无需额外调整。如果使用 1.5 倍或 3 倍扩容,则数组长度不再是 2 的幂,导致实现变得复杂。比如,哈希计算的规则需要调整,哈希分布也可能变得不均匀。
5、JDK 1.7和1.8中HashMap的区别?(498/1759=28.3%)
为了提升性能,JDK 1.8 对 HashMap 进行了显著优化,使得其查找效率更高,并有效解决了一些潜在的多线程问题。以下从==数据结构、数据重哈希方式、扩容机制的改进、重新计算存储位置的方式和扩容触发机制优化==这5个方面来进行详细说明。
1.数据结构的变化:
在 J==DK 1.7 及之前,HashMap 的数据结构是“数组+链表”。当发生哈希冲突时,多个键值对以链表形式存储在同一个“桶”中。 在 JDK 1.8 中,引入了红黑树优化。当链表长度超过 8 时,会自动转换为红黑树==,这将时间复杂度从 O(n) 降低到 O(logN),大幅提高查找效率。
2.数据重哈希的优化:
JDK 1.7:直接使用 hashCode 的==低位进行哈希运算,这样当 table 长度较小时,高位没有参与计算,导致哈希分布不均==。
JDK 1.8:在重新计算哈希值时,引入==高 16 位和低 16 位的异或运算,让高位也参与运算,从而提高了哈希分布的均匀性==,减少了哈希冲突。
3.扩容机制的改进:
JDK 1.7:在==扩容时使用“头插法”插入新元素==。这种方式会导致链表顺序反转,在多线程环境下,可能引发环形链表问题,导致程序死循环。
JDK 1.8:改为“尾插法”插入,保证链表顺序一致,避免了扩容中的死循环问题。此外,尾插法与红黑树的结合,也提高了整体的扩容效率。
4.重新计算存储位置的方式:
JDK 1.7:扩容时需要为每个元素重新计算哈希值,直接使用 hash & (table.length - 1)。
JDK 1.8:利用位运算的特性,判断元素是否需要迁移,如果 hash & oldCapacity == 0,元素保持在原位置;否则,迁移到原位置 + oldCapacity。这种方法避免了重新计算哈希值,提升了扩容效率。
5.扩容触发机制优化:
JDK 1.7:扩容是“先扩容后插入”,无论是否发生哈希冲突,都会执行扩容操作,可能导致无效扩容。
JDK 1.8:扩容变为“先插入再扩容”,仅在插入后元素总量超过阈值,或某条链表因哈希冲突长度超过 8 且当前数组容量未达到 64 时,才会触发扩容,减少了不必要的操作。
拓展:
1.HashMap能不能无限扩容?
HashMap 的扩容最终受限于 JVM 所能提供的内存。当 HashMap 的容量增长到超过 JVM 可用的==堆内存大小时,扩容操作将无法成功,可能会导致 OutOfMemoryError。适用于中小规模的数据存储,实际开发中,由于 HashMap 的扩容和 rehashing 都是相对昂贵的操作,大量的元素插入可能会导致系统性能的显著下降==。
2.树化后删除元素能不能回退成链表?
当红黑树中的元素数量减少到 6 时,HashMap 会将红黑树退化回链表,红黑树的结构维护成本较高,涉及复杂的旋转和调整操作。如果元素数量较少,链表反而更加高效。
3.“头插法”是如何引发环形链表的
(建议再去观看一些视频,加强理解)
多线程的时候会形成“环形链表”
初始状态
HashMap 初始容量为 4,所有桶均为空。线程 A 和线程 B 计算出它们的键值对 (k1, v1) 和 (k2, v2) 的哈希值均为 0,因此它们将尝试将数据插入到桶 0。
插入过程
线程 A 开始插入,线程 A 计算出键 k1 的哈希值,确定它应该放入桶 0。检查发现桶 0 为空,线程 A 准备将 (k1, v1) 插入到桶 0 的头部。
线程 B 同时插入,线程 B 计算出键 k2 的哈希值,得出同样的结果,也决定将 (k2, v2) 插入到桶 0。此时线程 B 检查桶 0,发现它仍为空(因为线程 A 的插入还未完成),于是开始准备将 (k2, v2) 插入到桶 0 的头部。
线程 A 完成插入,线程 A 将 (k1, v1) 插入到桶 0,当前桶 0 的状态为:[k1 -> v1]。
触发扩容
插入 (k1, v1) 后,HashMap 达到扩容阈值。HashMap 创建了一个容量翻倍的新数组,并开始将原数组中的元素重新分配到新的数组中。线程 A 负责将桶 0 中的 (k1, v1) 搬迁到新数组中。
线程 B 的并发操作
在线程 A 正在进行扩容的同时,线程 B 插入 (k2, v2), 线程 B 检查桶 0,发现此时不为空,于是通过头插法将 (k2, v2) 插入桶 0 的头部。插入后,桶 0 的状态变为:[k2 -> v2 -> k1 -> v1]。
并发引发问题
链表指针混乱:此时,线程 A 正在按照原先的链表结构将 (k1, v1) 搬迁到新数组,而线程 B 已改变了桶 0 的链表结构。当线程 A 重新分配 (k1, v1) 时,它可能仍认为 (k1, v1) 是链表的头部,但实际上 (k2, v2) 已成为头部。
形成环形链表:如果线程 A 在扩容时没有正确维护链表的结构,可能会导致 k1 的 next 指针错误地指向 k2,而 k2 的 next 又指向 k1。最终,链表结构变为一个闭环:[k1 -> v2 -> k2 -> v1 -> …],从而导致死循环。

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









