






论文核心思想
现有的模型总是将ID与其他模态的信息混合输入,但是这并不正确。
ID只是反映了items之间的共线关系
项目通道(文本、图片等)反映对用户细粒度偏好
既然混合有效果,那拆分后精细化操作应该会更好
存在问题
如何在item层面有效地表征ID和模态?
不同的模态之间有巨大的语义鸿沟
在没有监督信号的情况下,如何在会话水平上分离ID和通道效应?
作者的解决方案
- ID和模态表示学习模块,在商品层面对ID和模态信息进行解耦。首先,对于ID信息,DIMO设计了一个共现表示机制,显式地将商品共现关系注入到 ID 表示中。同时,对于模态信息,DIMO 通过自然语言处理和计算机视觉技术将异质的模态信息转换到相同的语义空间,实现了统一的模态表示。
- 多视角自监督解耦模块,包括代理机制和反事实推断,在缺乏监督信号的情况下在会话层面区分 ID 和模态信息的不同效应。
- 预测模块,基于解耦的ID和模态效应,通过因果推断预测用户未来的行为。
- 解释生成模块,创建了两个模板,共现模板和特征模板,利用ID和模态信息所代表的不同用户行为逻辑,对推荐结果进行了解释说明。
总览图
共现表示
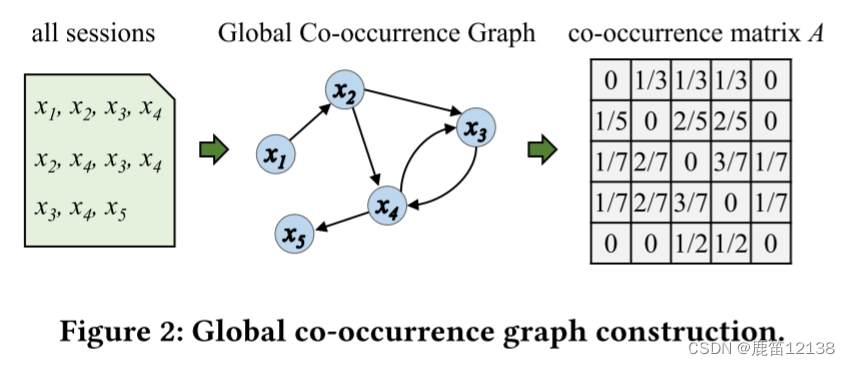
将会话序列建模成共现,图
为最右边表中对应格子内的计算方式𝑐𝑜𝑢𝑛𝑡(𝑥𝑖,𝑥𝑘)统计两个项目在所有会话中同时出现的次数,而𝑁𝑖是由在与𝑥𝑖的会话中出现的项目组成的项目集。基于共现矩阵,可以显示的知道商品之间的关系(这里这么做是因为会话推荐中用户是匿名的,不知道用户信息则无法得到CF,所以只能得到一个初步的共现信息)
ID与模态表征学习
ID表征:
共现矩阵A、单位矩阵I、embedding 矩阵 E~hat
通过共现矩去更新embedding表
通过让ei更靠近共现次数多的物品而不是没有共现的样本,使得ID的embeding中包含共现信息
模态表征:
把图片转文本,然后用BERT建模所有的文本描述,对于一个item其emedding就是所以文本emedding的一个总和
最后把两个表征序列通过不同的自注意力层,分别表示会话级别的共现模式和用户细粒度偏好。
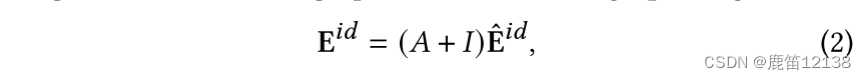
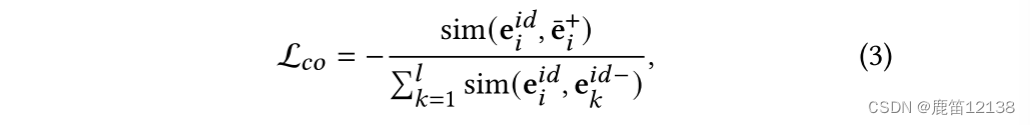
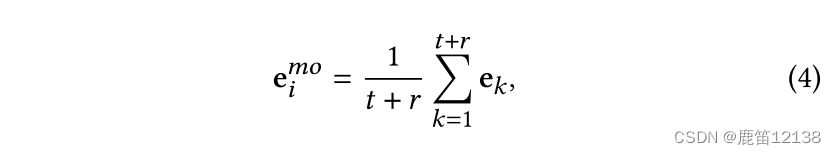
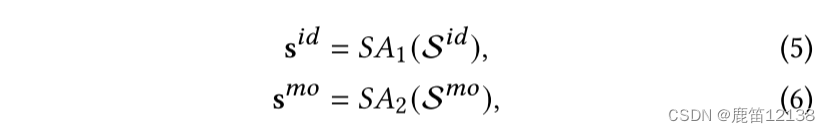
多视点自监督解缠
在这一部分中,作者提出了一种包括代理机制和反事实推理在内的多视角自我监督解缠,以区分会话级别的ID效应和模态通道效应。
代理机制:
代理机制旨在为原因及其代理具有相似语义的每个原因找到代理。在此之后,我们可以推动原因及其代理关闭,同时将不同的原因分开,以解开原因的纠缠。
具体地说,我们对S𝑖𝑑和S𝑚𝑜执行平均池化以获得代理
表示代理(池化后的向量 公式7.8)和原因(自注意力之后的向量 公式5.6)的方式不同是因为:
(1) 通过不同的方法在会话中聚合信息使学习到的嵌入显示出细微的差异,同时保留了总体相似的语义,有助于随后的解缠;
(2) 平均操作是无参数的,不会给DIMO带来额外的复杂性。在形式上,我们通过以下方式理清不同的原因
通过下面的操作去解纠缠
反事实推断:
"What if ID or modality cause is gone?"通过去除两个变量中的一个,去证明用户的行为是根据另外一个引起的
具体来说:如果一个标签项和当前会话中的项没有共现关联,我们可以推断用户选择它是因为她在通道后面的细粒度偏好。也就是说,通道效果主导用户选择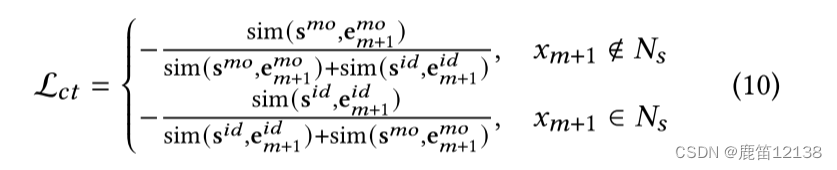
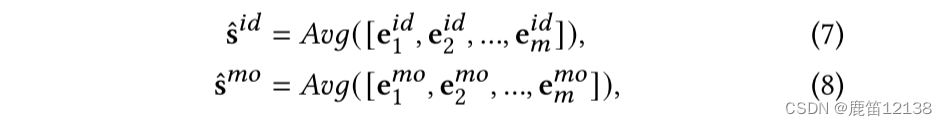
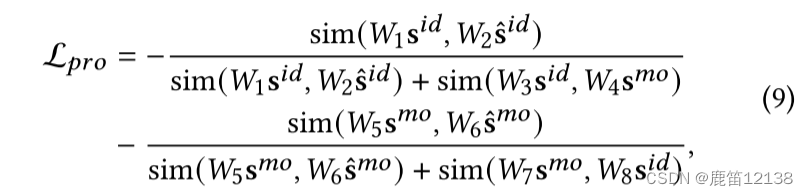
因果推理预测
直接使用下列公式简单的从两个维度去衡量一个物品是否可能是会话的下一个推荐
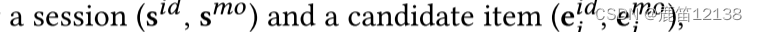
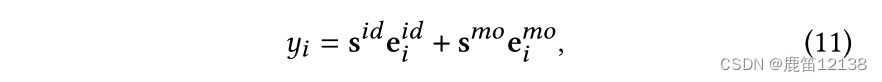
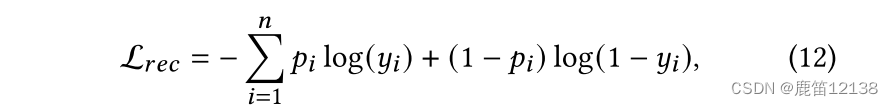
多任务学习
最后将其作为一个多任务学习,将多个loss相加作为总loss去更新
实验
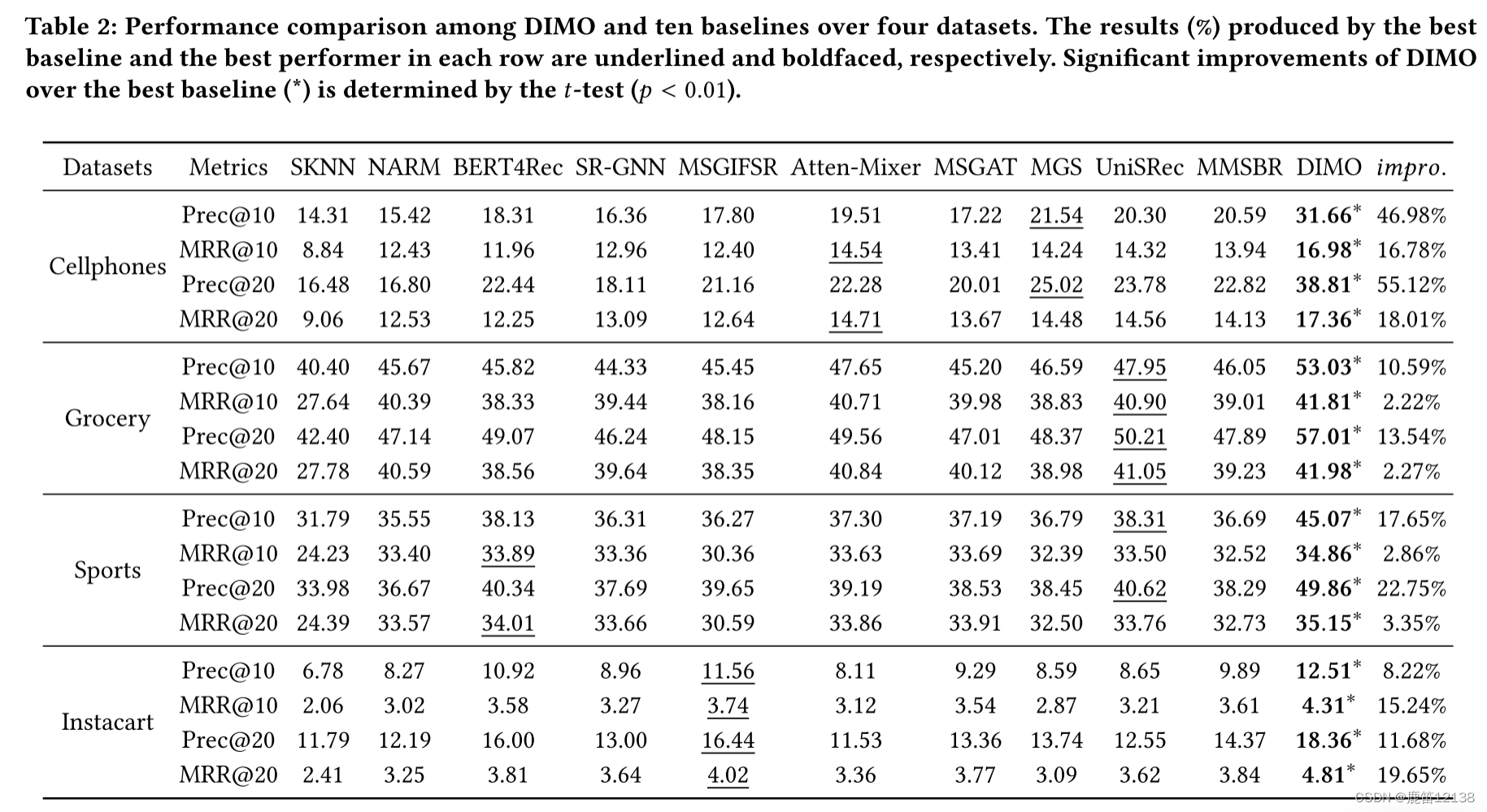 参数细节
参数细节

总结一下,这篇主要的亮点还是在显示加入了CF信息
中间的部分解构其实也没有那么合理,自监督训练的思想和双塔自监督的思想非常相似
可以从分解彻底性,LLM应用等方向去发展
总体来说是一篇很不错的文章,值得学习!















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









