






前言
上一节讲解了为什么我们需要回收,在此基础上,我们还介绍了 Thread Cache 是如何将一个一个的内存对象的回收流程。
而在上一文中,在介绍完 Thread Cache 最终是如何尾删一段批量的链表后,就会交给 Central Cache 中,那这一文就来介绍 Central Cache 是如何回收内存,然后逐次往下到 PageCache 传递的。
前置工作
问题
我们现在回顾一下 Central Cache 是怎么将空间交给 Thread Cache,其实本质是通过 Span 来管理一个一个的页,通过对页的切割拆分,从而获得一个对齐数的空间大小,然后交由给 Thread Cache 随后再交由线程。
那在这里就会存在一个很严重的问题,从 Thread Cache 还回来的内存对象,它们并不一定都来自于一个 Span 的页,因此当我们计算出还回来的对象应该还给central cache的哪一个桶后,还需要知道这些对象到底应该还给这个桶当中的哪一个span。
解决措施
总结问题,就是我们无法得知 某个页它是属于哪个 Span 的。
所以解决的方法,我们不妨使用哈希表来建立页号与 Span 的映射。
那什么时候开始建立映射呢?
还记得我们在实现 Page Cache 时,我们是怎么建立从堆申请 128 个页的吗,我们是对 128 页做了拆分,所以我们回归到最开始,我们就可以在 Page Cache 申请内存的时候将映射建立起来!
class PageCache
{
public:
/* 获取从对象到span的映射 */
Span* MapObjectToSpan(void* obj);
private:
std::unordered_map<PAGE_ID, Span*> _idSpanMap;
};
建立映射
// 获取一个 k 页的 Span
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0 && k < NPAGES);
// 1. 若 k 位置的桶,不为空
if (!_spanLists[k].IsEmpty())
{
Span* kSpan = _spanLists[k].PopFront();
// 建立映射
for (PAGE_ID i = 0; i < kSpan->_n; ++i)
_idSpanMap[kSpan->_pageId + i] = kSpan;
return kSpan; // 直接返回
}
// 2. 为空
// 检查一下后面的桶里面有没有 Span,如果有可以将其进行切分
for (int i = k; i < NPAGES; ++i)
{
if (!_spanLists[i].IsEmpty())
{
// 找到了个不为空的桶
Span* span = _spanLists[i].PopFront(); // 获取第一个 Span
assert(span);
// 开始切分
Span* bigSpan = new Span;
bigSpan->_pageId = span->_pageId + k; // 获得新页号
bigSpan->_n = span->_n - k; // 获得新页数
span->_n = k; // 更新页数
// 将切下来的 bigSpan,放在新的桶上
_spanLists[bigSpan->_n].PushFront(bigSpan);
// 建立映射
for (PAGE_ID i = 0; i < span->_n; ++i)
{
_idSpanMap[span->_pageId + i] = span;
}
return span;
}
}
// 后面的桶,都没有 Span 了, 这时就向堆申请一个 128 页的 Span
Span* largeSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1); // 获得一个大页
// ptr 为大页的起始地址,>>= PAGE_SHIFT 就可以获得页号
largeSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
largeSpan->_n = NPAGES - 1;
_spanLists[largeSpan->_n].PushFront(largeSpan);
// 尽量避免代码重复,递归调用自己
return NewSpan(k);
}
在上述代码的第 11 行和第 39 行都加上了建立映射的操作,具体的实施可以画图来研究,同时正好可以回顾一下当时的 Page Cache 的申请空间流程。
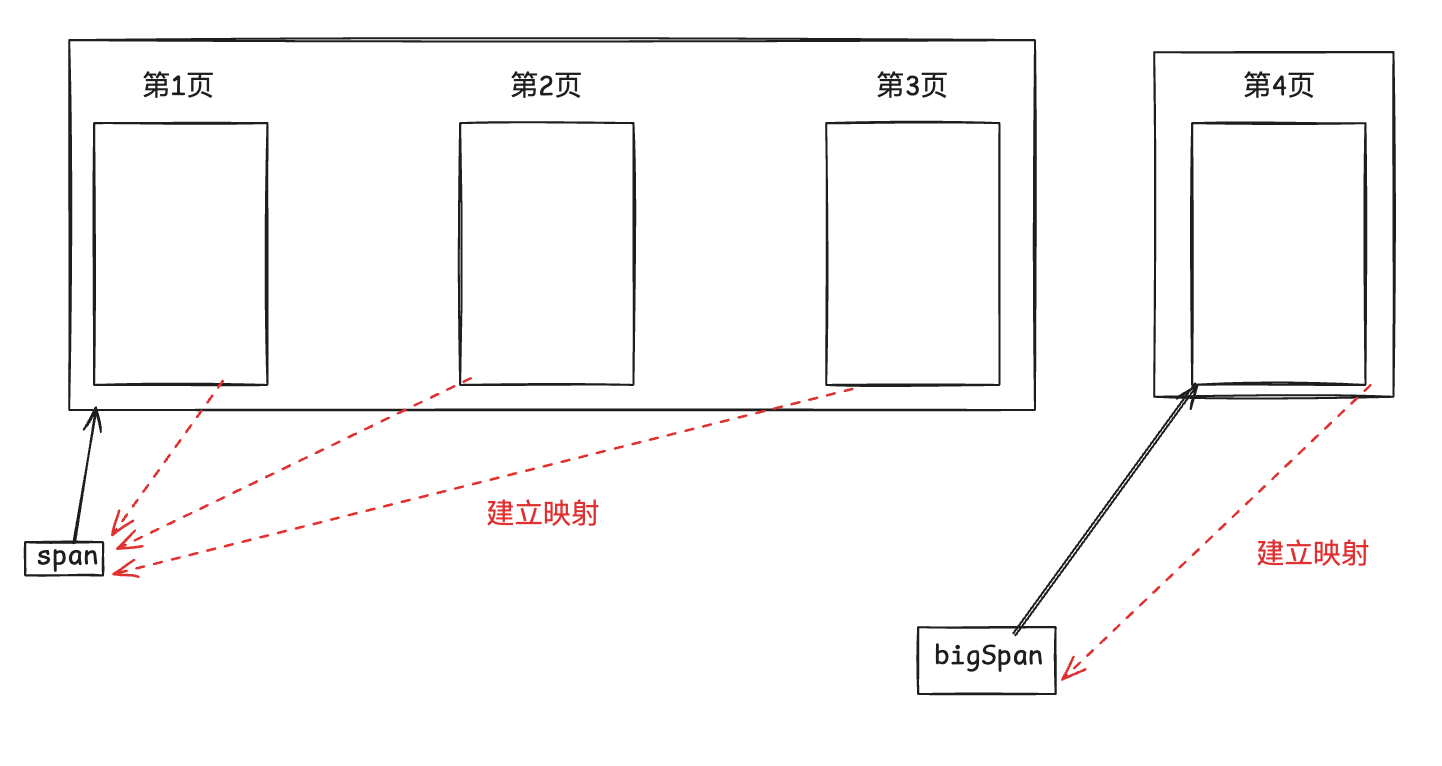
通过地址找到 Span
现在我们回到 Thread Cache 在尾删的部分,已经保存好了那个一连串的内存对象
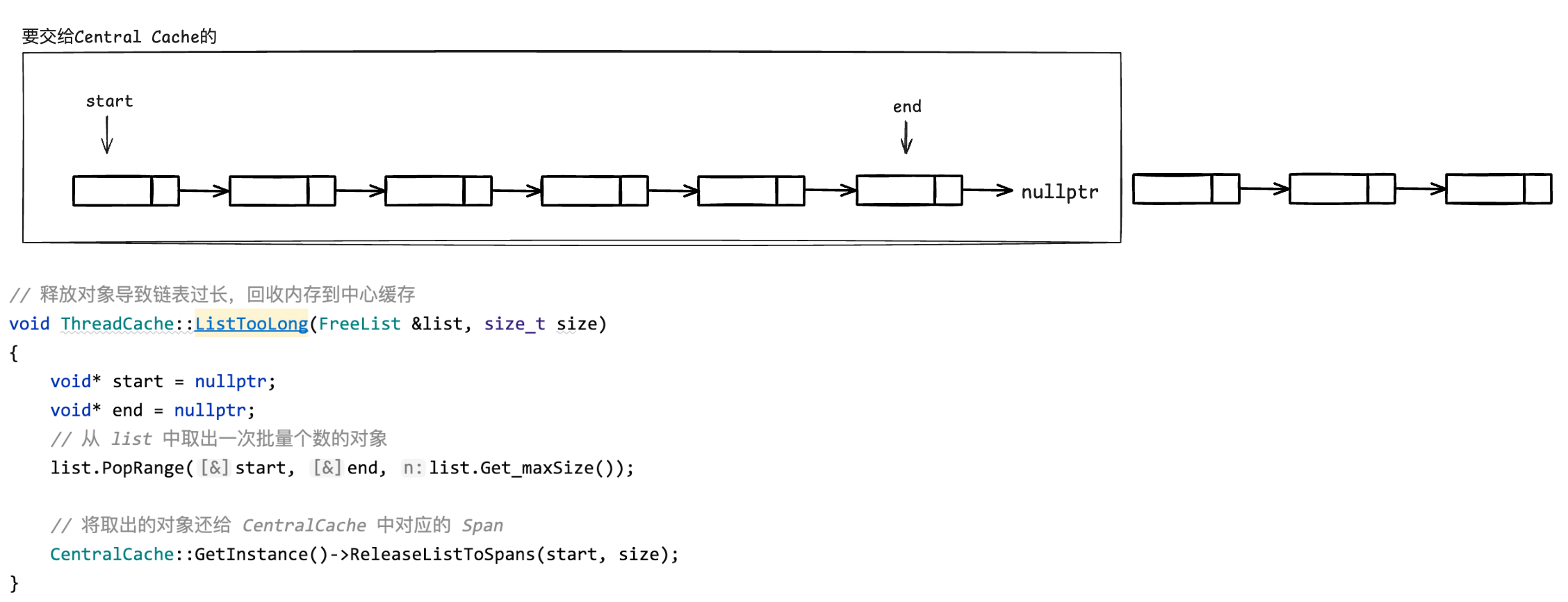
但是我们这里只有 start 这一个 void*指针,我们还需要通过这个指针找到对应的 Span 啊。
是的,但是一点也不难,因为我们之前讲解过了地址和页号之间的关系,只需要除上页大小,不就能过获得了页号了吗?
那在通过哈希表的映射,不就能过获得对应的 Span 了吗?
没错就是这样,这次从 Thread Cache 回收的内存对象中,每个内存对象是属于谁的,也就一清二楚了!
Span *PageCache::MapObjectToSpan(void *obj)
{
assert(obj);
PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT; // 获得页号
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end()) // 找到了就直接返回
return ret->second;
assert(false);
return nullptr;
}
回收
现在前置工作完成了,剩下的也就很简单理解了。
首先,每一个 Span 都有一个成员变量,_useCount,这个成员变量的意思就是记录给出去了多少个内存对象,那既然是从 Thread Cache 那里回收,那对应的内存对象****从哪来的就会回到哪里,所以每个 Span 对应的 _useCount 也会减少,如果减到了为 0 了,那就代表着我现在的 Span 是一个满的状态,那我就可以考虑交给 PageCache 了!
没错回收的总流程就是上述,但是其中有一些细节需要注意,比如将尾巴置为空,加锁提高效率等等,不过这些并不是重点,因此直接上代码


















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











