




摘要:影响力最大化问题引起了研究者的极大关注,其目的是确定一个有影响力的传播者子集,使其在社交网络中预期的影响力传播最大化。现有的研究工作主要集中在制定非适应性政策上,在识别后的扩散初期,所有的种子都会被点燃。然而,在非适应性策略中,由于一些种子在扩散过程中被其他活动种子自然感染,可能会出现预算冗余。针对棘手的自适应影响最大化问题,研究了自适应播种策略。在深度学习模型的基础上,提出了一种具有自注意力机制机制的图卷积网络(ATGCN)方法,将自适应影响最大化作为回归任务来解决。在自适应播种模型中引入了一个控制参数,在传播延迟和影响覆盖之间进行了权衡。该方法利用自注意力机制机制,对节点表示动态分配重要性权重,有效捕获与自适应影响最大化问题相关的节点影响特征信息。最后,在六个真实社会网络上进行的密集实验结果表明,自适应播种策略比最先进的基线方法更能解决传统的影响最大化问题。同时,与现有最先进的基于贪婪的自适应播种策略相比,所提出的自适应播种策略ATGCN将影响传播率提高了7%。
1. 简介
本文主要研究自适应影响最大化问题(AIM),即基于当前观测到的扩散结果,自适应地播种影响节点,使影响扩散最大化。在这种情况下,现有的观测结果为每一轮当前种子影响覆盖率的未来利润减少提供了反馈。
解决自适应影响最大化问题的挑战是确定何时播种新节点以继续扩散过程,以及哪些节点将最大化预期的影响扩散。
为了解决AIM问题,提出了一种具有自注意力机制机制的自适应策略—图卷积网络。该方法的思想是将AIM问题转化为回归任务,通过预训练的模型来帮助预测节点在现实社会网络中的影响力,然后根据预测值对节点进行排序。在第一阶段,提出的模型是由一个合成Barabási-Albert (BA)网络进行训练。第二阶段,利用训练好的模型预测社会网络中节点可能产生的影响。同时,在策略中引入控制参数β,在扩散延迟和扩散覆盖之间进行权衡。
主要贡献简述如下:
1. 将自适应影响最大化问题视为一个回归问题任务,提出了一种基于自注意力机制机制的自适应播种策略图卷积网络来解决该问题。
2. 基于深度学习的模型只需在合成训练网络上训练一次,然后就可以用于解决现实社会网络中的自适应影响最大化问题。
3. 本研究系统地探讨了何时播种、播种哪些节点以及如何识别种子节点等问题。
4. 在六个真实社会网络上进行的大量仿真表明,自适应策略ATGCN比基线策略表现出更好的性能。
2.相关工作
作者先介绍了IM问题的一些相关工作,基于贪婪、启发式、元启发式的方法,到现在的一些深度学习的方法,之后介绍了AIM问题的一些相关工作。
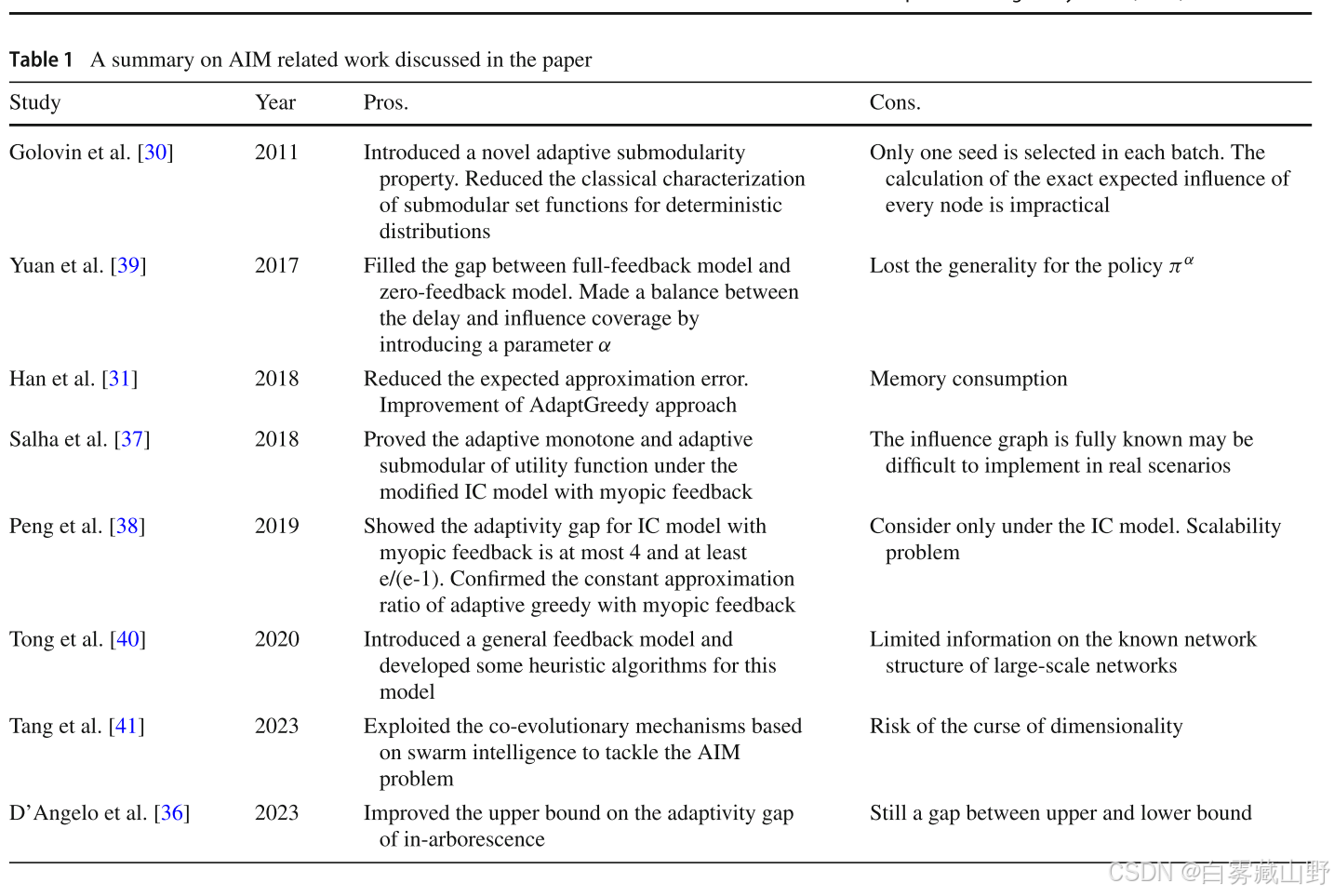
3. 准备工作
本文主要使用独立级联模型
一些定义:
以上图为例,在节点尝试激活的过程中,已经被激活的边进入活边集L,激活失败的边进入死边集D,还未尝试激活的边是未知的,而L和D就是一个实现,如果L和D的并已经包含了所有的边,那么此时的实现就是一个完全实现, 否则就是一个部分实现,而传播过程结束时的实现就是最终实现,当一个实现时另一个实现的子集,那他就是另一个实现的子实现,另一个实现时这个实现的超实现。

策略:在每个时间间隔选择是否感染种子节点,激活哪个种子节点
4. 框架
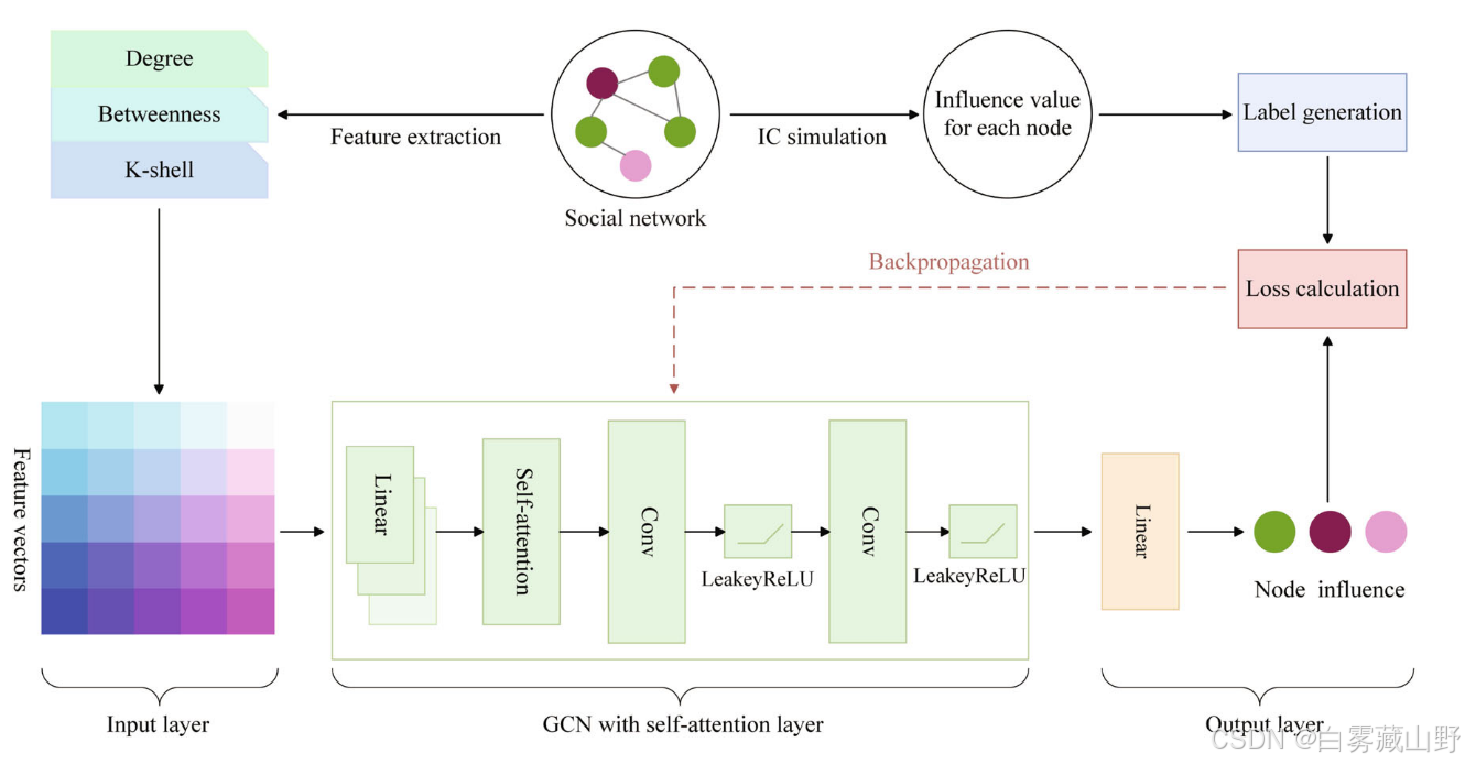
特征提取:
本研究选择了三种典型的中心性度量,即度中心性、介数中心性和k-shell中心性作为节点特征。
在输入层,为了避免过拟合,首先对根据三种基于拓扑的中心性提取的每个节点的特征值进行归一化,使特征值的范围在区间[0,1]内。归一化过程如方程(4)所示。
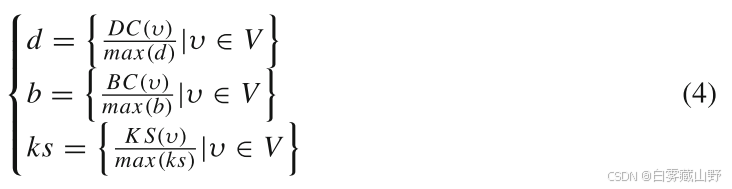

def nodes_features(G):
#度中心性
degree_centrality = nx.degree_centrality(G)
max_degree_centrality = max(degree_centrality.values())
for node in degree_centrality:
degree_centrality[node] /= max_degree_centrality
#介数中心性
betweenness_centrality = nx.betweenness_centrality(G)
max_betweenness_centrality = max(betweenness_centrality)
for node in betweenness_centrality:
betweenness_centrality[node] /= max_betweenness_centrality
#k-shell中心性
k_shell_centrality = nx.core_number(G)
max_k_shell_centrality = max(k_shell_centrality)
for node in k_shell_centrality:
k_shell_centrality[node] /= max_k_shell_centrality
#组合成特征矩阵
node_features = torch.tensor([list(degree_centrality.values()), list(betweenness_centrality.values()), list(k_shell_centrality.values())]).T
#node_features = np.array([list(degree_centrality.values()), list(betweenness_centrality.values()), list(k_shell_centrality.values())]).T
#node_features = torch.tensor(node_features)
return node_features
标签生成:
大多数社交网络没有标签或很少标签与适应性影响最大化任务无关。然而,我们提出的模型是基于回归方法训练的,这需要为每个网络节点明确定义连续标签,以便可以回归值。在社交网络中,每个节点往往具有独特的社会影响力。每个节点的个体影响可以根据3.1节讨论的独立级联扩散模型计算。在IC模型下的信息传播仿真中,感染概率设为0.1。因此,我们通过在每个节点上执行200次IC模拟来获得平均影响值。得到的平均影响值构成网络中相应节点的标签。
def IC_simulation(G, seeds, propagation_prob=0.1, max_rounds=10):
#已激活节点
activated = set(seeds)
newly_activated = set(seeds)
#遍历,找每一轮激活节点
for round in range(max_rounds):
next_newly_activated = set()
for node in newly_activated:
#获取当前节点邻居节点
neighbors = list(G.neighbors(node))
for neighbor in neighbors:
if neighbor not in activated:
#激活节点
if random.random() < propagation_prob:
next_newly_activated.add(neighbor)
#更新种子集
activated.update(next_newly_activated)
newly_activated = next_newly_activated
if not newly_activated:
break
return activated
具有自注意力机制层的GCN:自注意力机制和图卷积网络层。
自注意力机制可以学习计算复杂度较低的输入特征之间的联系和相关性[45]。在学习过程中,利用其集成全局信息的优势,使模型能够动态地在节点之间分配注意权值,提高对整个图结构的理解。具体来说,该机制在查询、键、值和输出之间建立映射,所有这些都是向量。首先,将输入向量X分别乘以权矩阵Wq、Wk、Wv,得到q、k、v,分别称为query、key、value。可以表示为方程(6)。

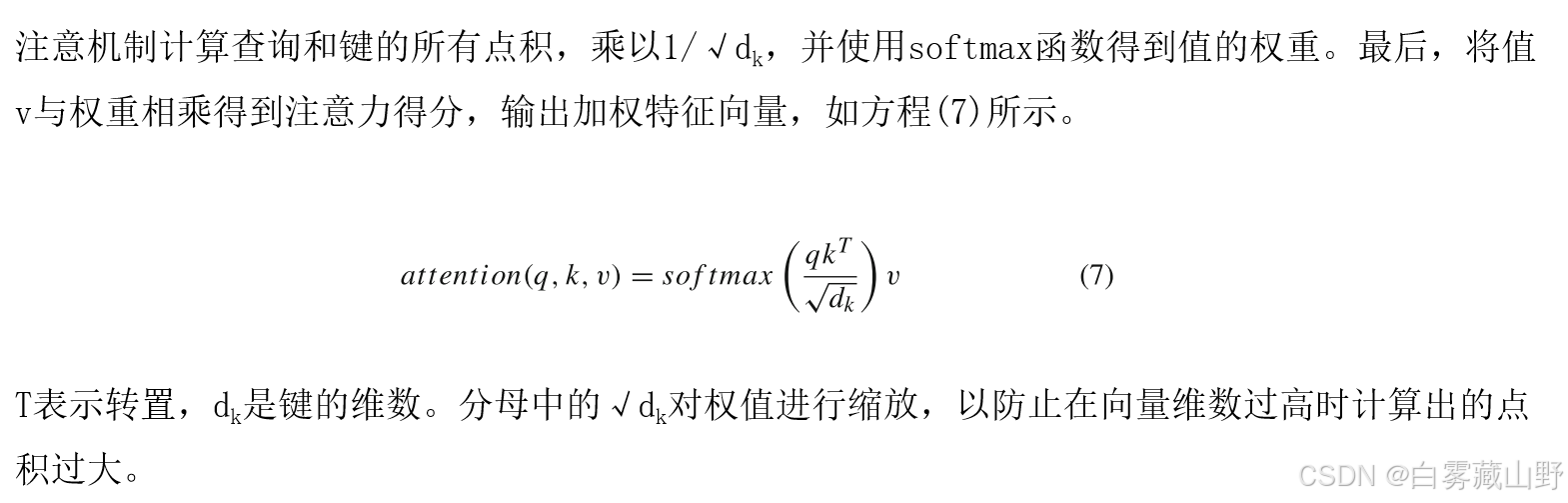
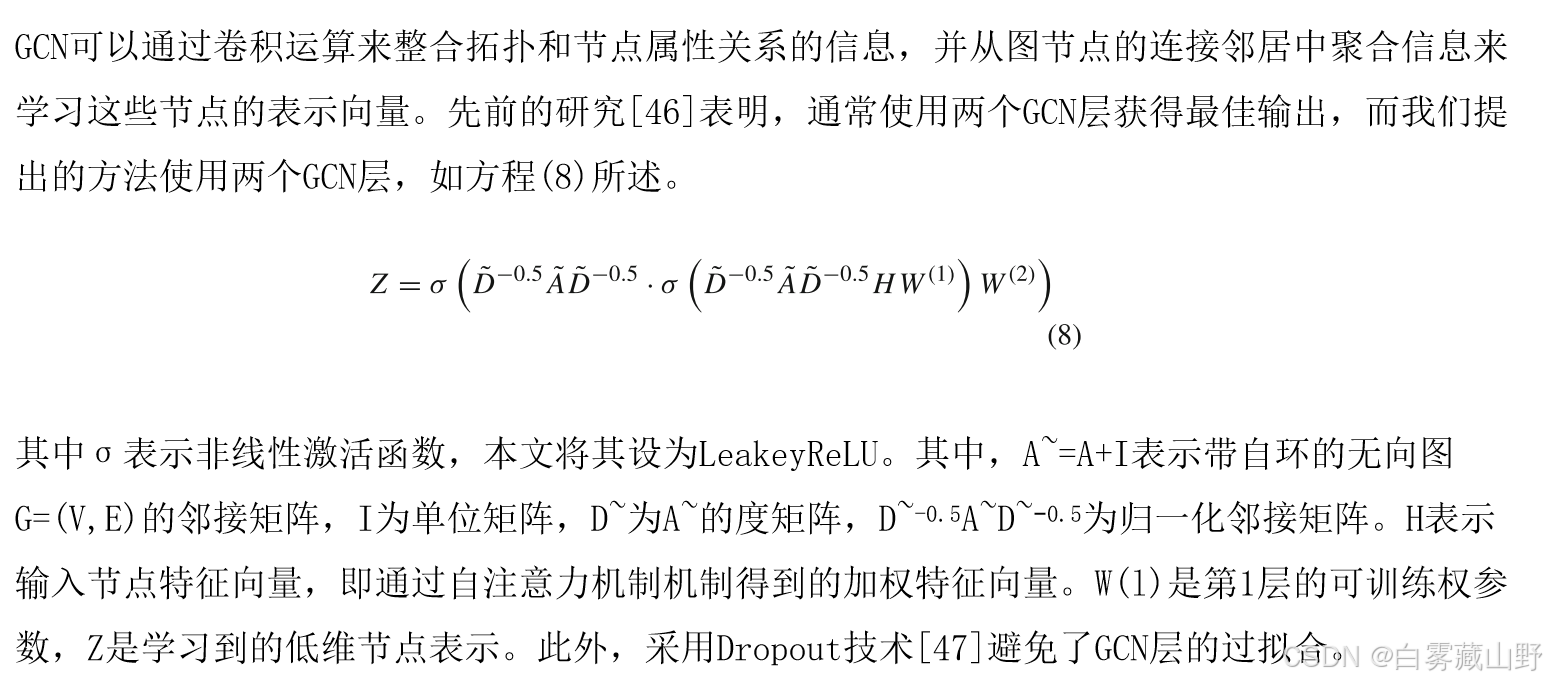
#自注意力
class SelfAttention(nn.Module):
def __init__(self, embed_size):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.value_layer = nn.Linear(embed_size, embed_size)
self.key_layer = nn.Linear(embed_size, embed_size)
self.query_layer = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x):
#获取样本数量和长度
batch_size, seq_length, _ = x.shape
#计算v,k,q
value = self.value_layer(x)
key = self.key_layer(x)
query = self.query_layer(x)
# 计算注意力得分
#矩阵乘
energy = torch.bmm(query, key.transpose(1, 2))
#缩放,softmax归一化
attention_scores = torch.softmax(energy / torch.sqrt(torch.tensor(self.embed_size, dtype=torch.float32)), dim = -1)
# 加权求和
out = torch.bmm(attention_scores, value)
out = self.fc_out(out)
return out
#ATGCN模型
class ATGCN(nn.Module):
def __init__(self,input,hidden,output,dropout_rate = 0.3):
super(ATGCN,self).__init__()
self.gcn1 = GCNConv(input,hidden)
#self.attention = nn.MultiheadAttention(embed_dim=output_dim, num_heads=1)
self.attention = SelfAttention(hidden)
self.gcn2 = GCNConv(hidden,output)
self.output_layer = nn.Linear(output, output)
self.dropout = nn.Dropout(dropout_rate)
#前向传播
def forward(self, X, A):
X = self.attention(X)
X = self.gcn1(X,A)
X = F.relu(X)
X = self.dropout(X)
X = self.gcn2(X,A)
X = self.dropout(X)
X = self.output_layer(X)
return X

损失计算:
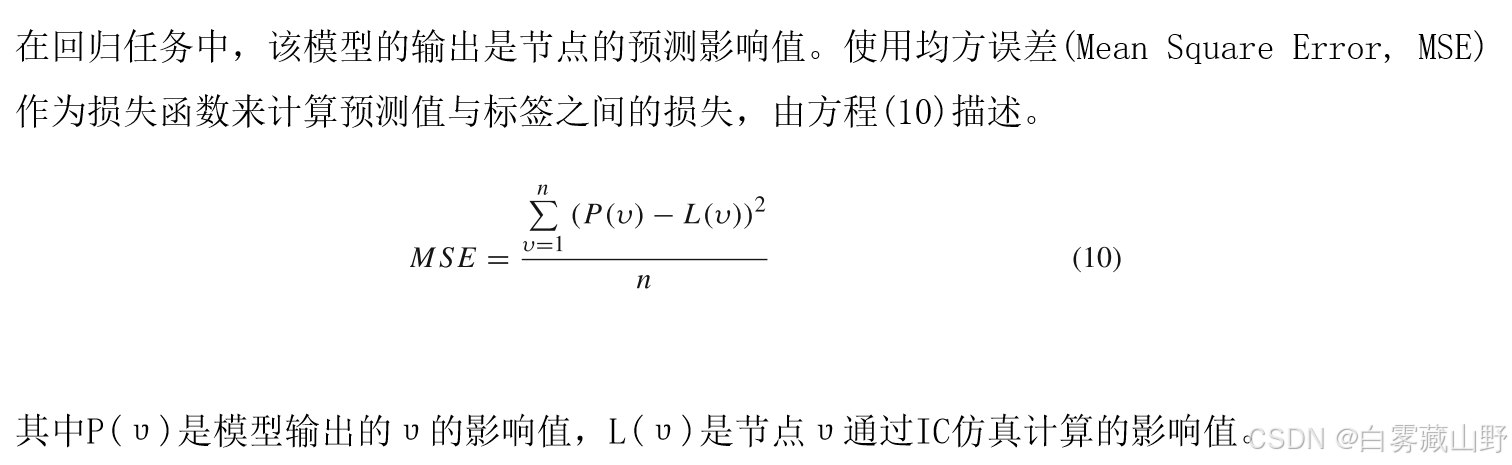

'''
# 更新种子节点集
def update_seeds(G, activated_nodes, current_seeds, budget):
potential_seeds = set()
for node in activated_nodes:
#找邻居节点
neighbors = list(G.neighbors(node))
for neighbor in neighbors:
#
if neighbor not in activated_nodes and neighbor not in current_seeds:
potential_seeds.add(neighbor)
new_seeds = random.sample(potential_seeds, min(budget, len(potential_seeds)))
updated_seeds = current_seeds.union(set(new_seeds))
return updated_seeds
'''
#选择种子节点
def select_seeds(graph, initial_seeds, propagation_prob=0.1, budget=10, num_simulations=200):
current_seeds = set(initial_seeds)
#首先满足预算
while len(current_seeds) < budget:
best_node = None
best_influence = 0
for node in graph.nodes:
if node not in current_seeds:
# 计算将当前节点添加到种子集后的预期影响力
new_seeds = current_seeds.union({node})
influence = expected_influence(graph, new_seeds, propagation_prob, num_simulations)
# 更新最佳节点
if influence > best_influence:
best_influence = influence
best_node = node
if best_node is not None:
current_seeds.add(best_node)
print(f"节点 {best_node} 影响力 {best_influence:.2f}")
return current_seeds
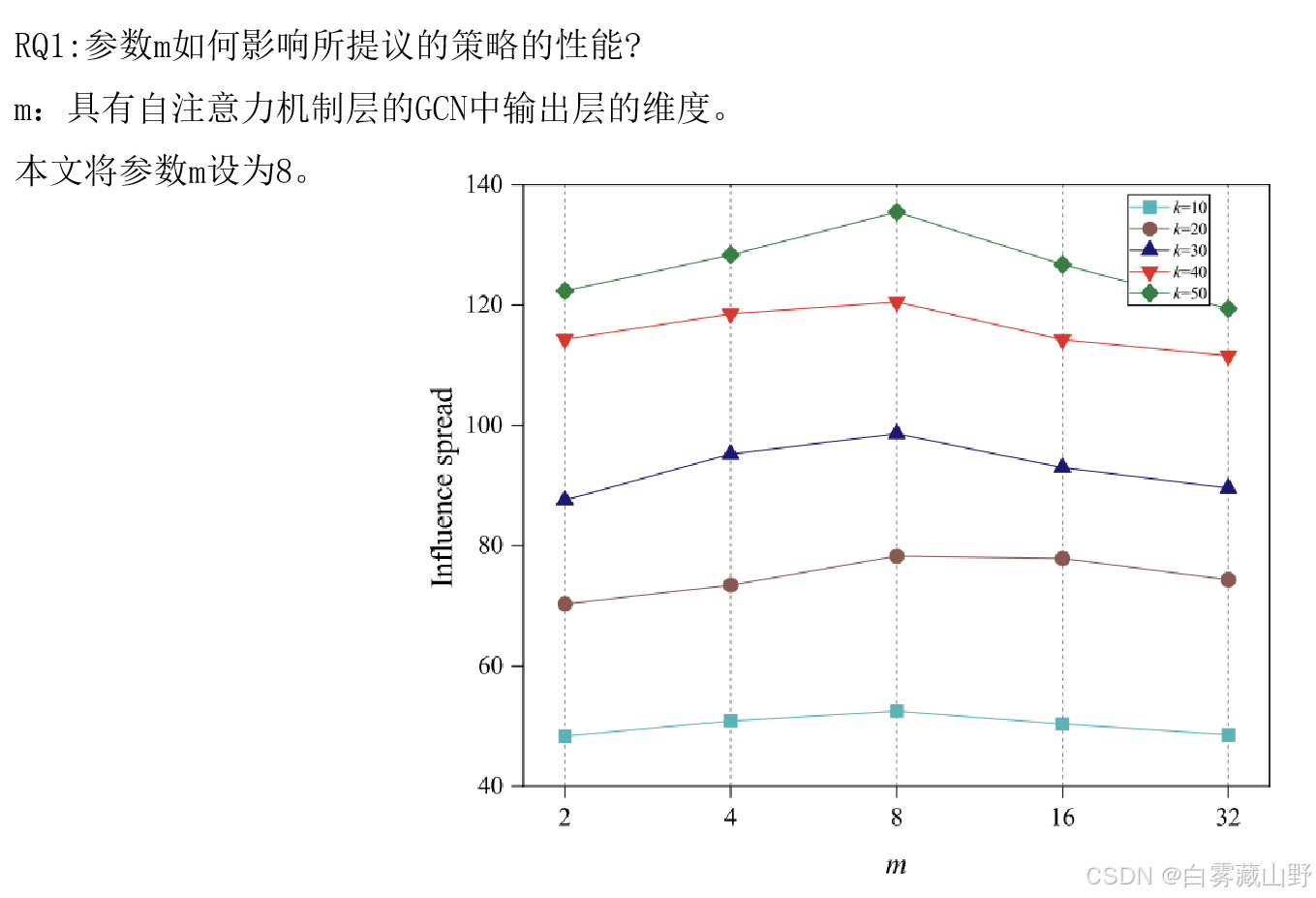
在网络NetScience上进行了实验,以检查m如何影响建议策略的性能。图3显示了不同播种预算下,拟议策略ATGCN在NetScience上实现的影响传播。因此,x轴表示m的值,y轴表示影响范围。预算越大,影响范围越大,如图3所示,因为预算决定了可以选择的种子数量。此外,当m < 8时,可以观察到,随着m的增加,本文方法的性能逐渐提高,而当m大于8时,atgcn的效果逐渐减弱。这是因为较小的m值可能导致信息丢失,这将阻止模型捕获图的关键特征,而较大的m值可能涉及额外的噪声,这将降低模型的泛化能力。因此,本文将参数m设为8。
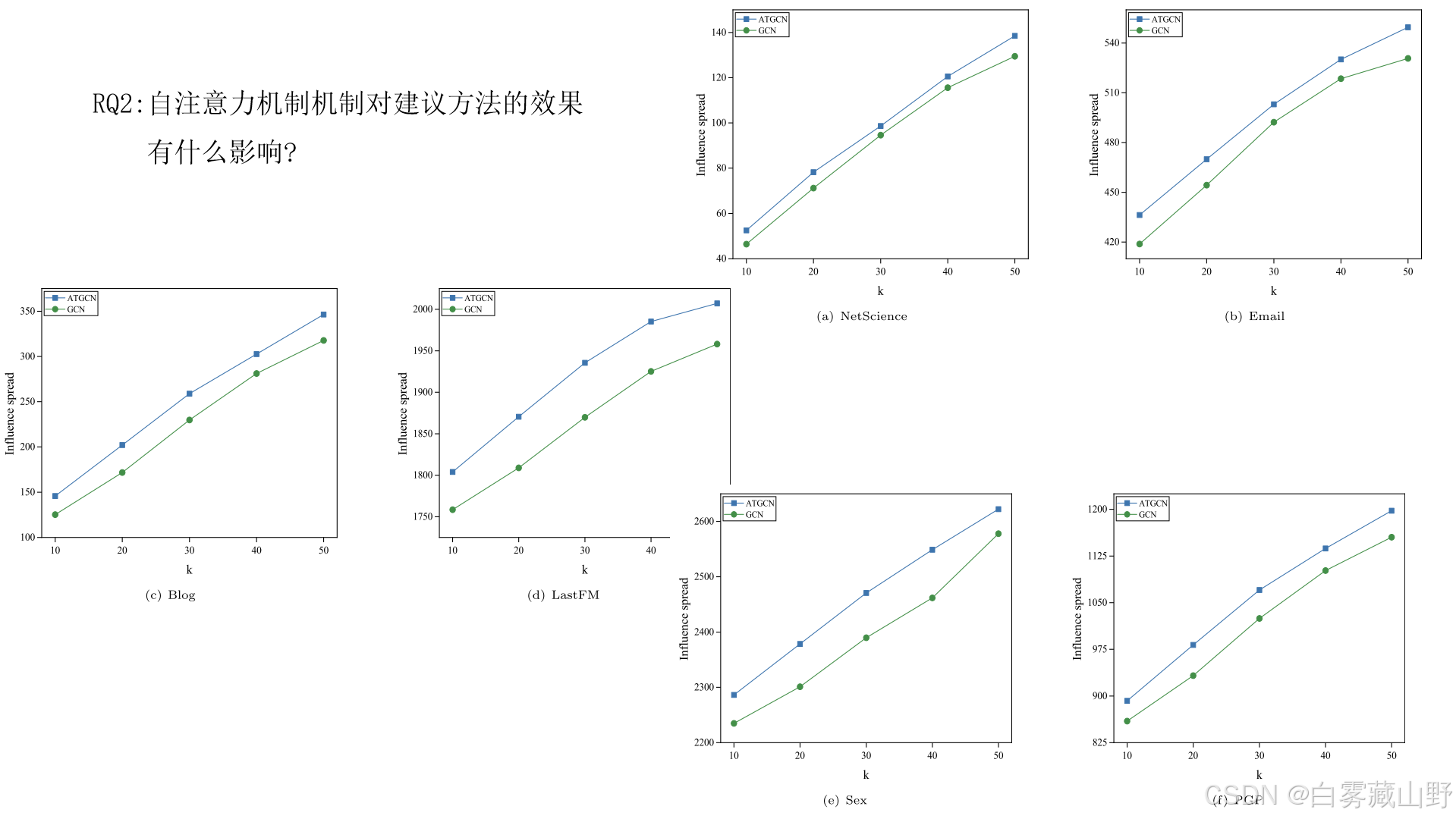
将我们提出的方法datgcn与没有自注意力机制机制(GCN)的ATGCN进行比较,使我们能够检查自注意力机制机制如何提高性能。相应的实验结果如图4所示,其中x轴表示不同的播种预算,y轴表示影响扩散。从图4所示的实验结果可以看出,提出的ATGCN的影响范围明显大于GCN,这意味着在每个网络中不同预算下,ATGCN的性能都优于GCN。结果表明,自注意力机制机制可以更好地捕捉影响扩散动态下的节点特征和网络拓扑信息,从而提高GCN的性能。特别是,该机制可以学习特征之间的联系和相关性,并根据节点自身属性和网络扩散信息动态地为节点分配不同的重要权重,提高了模型生成节点表示的能力。
我们在六个现实世界的社交网络上进行了大量的模拟,以比较在预算k = 10的情况下,所提出的atgcn与L1loss (Mean Absolute Error)、MSE和SmoothL1Loss损失函数的性能。在图中,影响扩展绘制在y轴上,L1loss、MSE和SmoothL1Loss绘制在x轴上。实验分别在这三种损失函数上独立运行100次,计算每个损失函数的平均影响范围。从图中我们可以发现,相对于其他两种损失函数,MSE的影响范围是最大的,说明建议模型中的MSE是最合适的损失函数。另一方面,与其他损失函数相比,在我们的回归任务中采用MSE可以有效地提高模型在节点影响预测方面的预测精度。
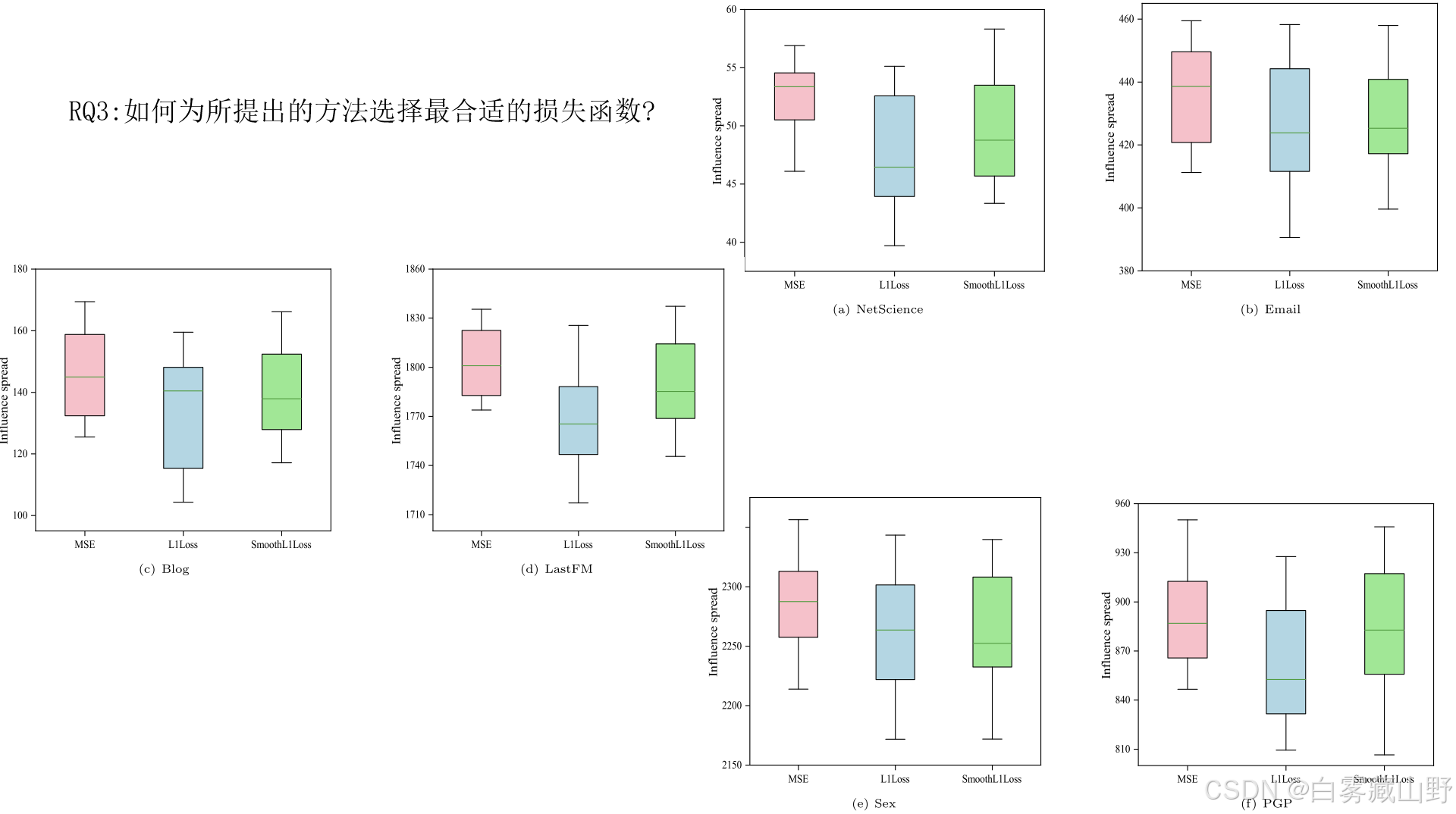 图6描述了不同播种预算场景下,ATGCN和三种传统方法对6个数据集的影响传播情况(相应的实验数据见表6)。从图中可以直观地看出,所提策略优于传统技术。证明自适应策略的性能优于非自适应策略。例如,当预算k = 10时,与CELF[48]、RCNN[12]和DeepIM[13]方法相比,策略ATGCN分别至少有3.5%、7.7%和8.2%的改进。请注意,自适应方法可以根据在传播过程中观察到的实现选择种子,并且具有更大的概率影响在非自适应情况下难以到达的节点。此外,从图6中我们可以看出,在解决传统的影响力最大化问题时,CELF实现的影响力传播优于RCNN[12]和DeepIM[13]。对于传统的基于深度学习的方法,DeepIM[13]在每个网络上的总体表现都不如RCNN[12],这说明在识别影响节点时,RCNN[12]比DeepIM具有更高的预测精度。在图6b-f中,值得注意的是,当预算从20到50时,传统方法曲线的斜率大致是平滑的;换句话说,随着播种预算的增加,影响范围几乎没有变化。存在预算冗余的情况,其中一些可能被邻居自然感染的种子用户不应该被选为初始种子。总之,自适应策略的优势是显著的,因为它可以利用扩散实现,从而增加预期的影响传播增益。
图6描述了不同播种预算场景下,ATGCN和三种传统方法对6个数据集的影响传播情况(相应的实验数据见表6)。从图中可以直观地看出,所提策略优于传统技术。证明自适应策略的性能优于非自适应策略。例如,当预算k = 10时,与CELF[48]、RCNN[12]和DeepIM[13]方法相比,策略ATGCN分别至少有3.5%、7.7%和8.2%的改进。请注意,自适应方法可以根据在传播过程中观察到的实现选择种子,并且具有更大的概率影响在非自适应情况下难以到达的节点。此外,从图6中我们可以看出,在解决传统的影响力最大化问题时,CELF实现的影响力传播优于RCNN[12]和DeepIM[13]。对于传统的基于深度学习的方法,DeepIM[13]在每个网络上的总体表现都不如RCNN[12],这说明在识别影响节点时,RCNN[12]比DeepIM具有更高的预测精度。在图6b-f中,值得注意的是,当预算从20到50时,传统方法曲线的斜率大致是平滑的;换句话说,随着播种预算的增加,影响范围几乎没有变化。存在预算冗余的情况,其中一些可能被邻居自然感染的种子用户不应该被选为初始种子。总之,自适应策略的优势是显著的,因为它可以利用扩散实现,从而增加预期的影响传播增益。
CELF[48]:一种高效的基于贪婪的算法,利用“延迟前向”策略和子模块化进行种子节点选择,并始终运行10,000次蒙特卡罗模拟来近似节点影响。
DeepIM[12]:该算法建立在深度学习模型之上,结合skip-gram模型[23]和CARE[24]学习节点表示。然后将学习到的表示用于种子节点的选择。
RCNN[13]:该算法通过使用创建的特征矩阵和卷积神经网络来训练和预测每个节点的影响。然后根据预测值选择种子。
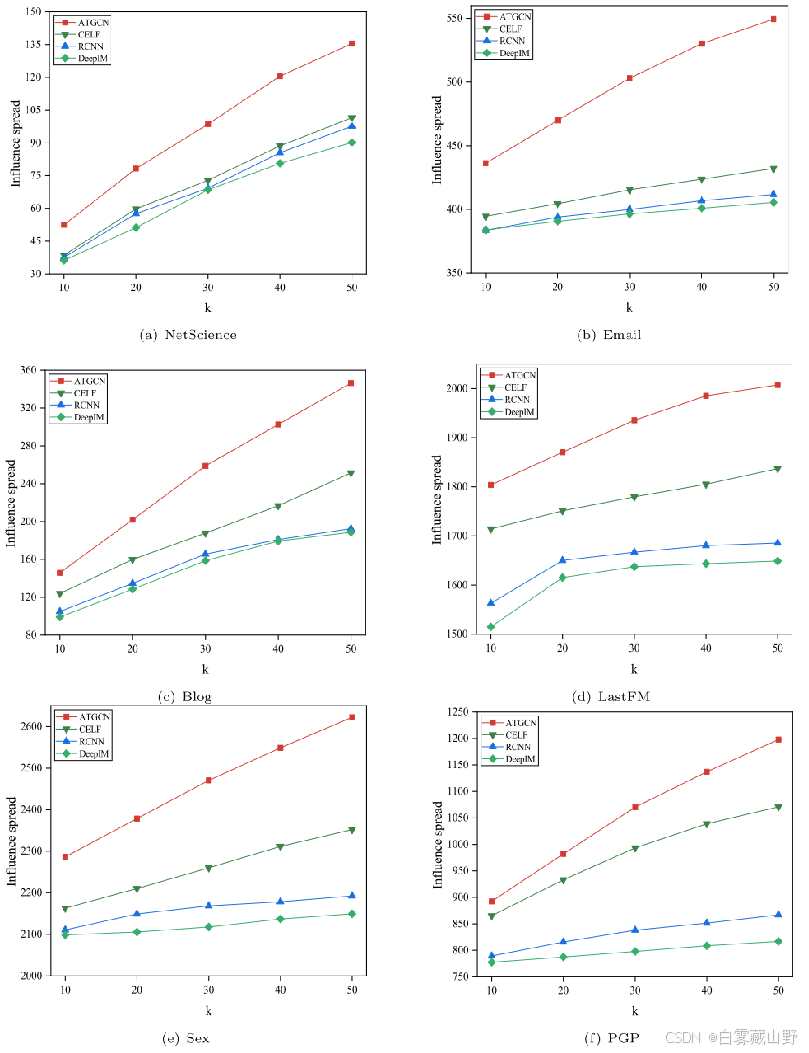
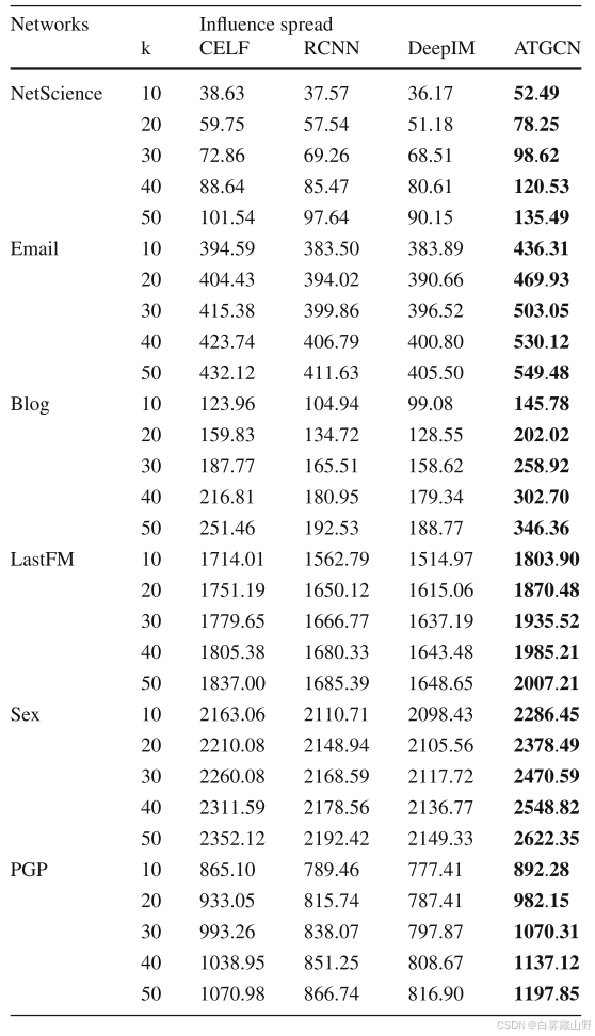
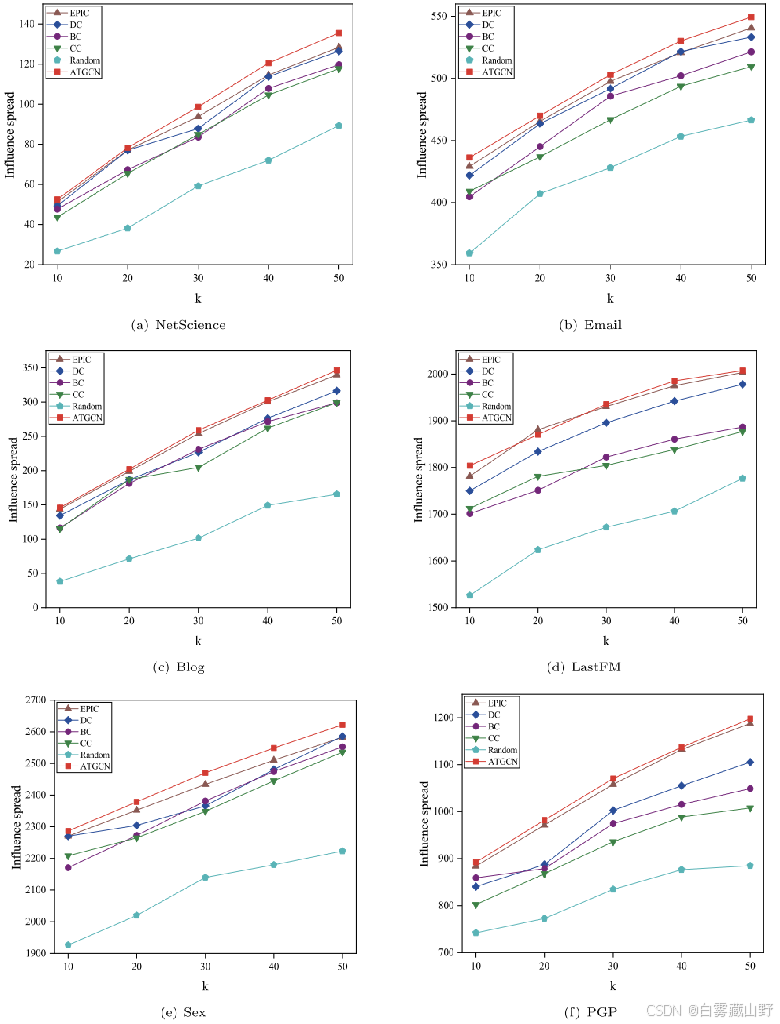
图7显示了控制参数为β = 1的ATGCN、EPIC[49]、DC[6]、BC[43]、CC[43]和Random[6]在6个真实社会网络上5种不同播种预算大小为10、20、30、40和50的实验结果。如图7所示,我们可以直观地肯定,随着播种预算k的增加,影响的传播也随之增加,因为寻求选择更多的种子会导致更广泛的影响传播。从实验结果中可以得出结论,与其他五种基线方法相比,所提出的ATGCN在任何网络下的性能都是最好的,而随机策略的性能一直是最差的。因此,毫无疑问,atgcn的表现是最突出的,证明了我们建议的政策的有效性。值得注意的是,当预算k = 20时,LastFM网络中出现了提议的ATGCN不如EPIC[49]的异常情况,即EPIC[49]选择的种子节点比ATGCN的影响力更大。在基线方法中,由于EPIC[49]是一种基于贪婪的算法,可以获得近似的保证,因此其实现的影响扩展优于其他四种方法。对于启发式中心性策略,由于不同网络中网络的拓扑信息不同,DC[6]、BC[43]和CC[43]在不同网络中的性能不稳定。然而,由于与各种网络相关的扩散实现和结构不同,数据集本身可能会对拟议的ATGCN与其他基线策略之间的差距产生影响,如图图所示。
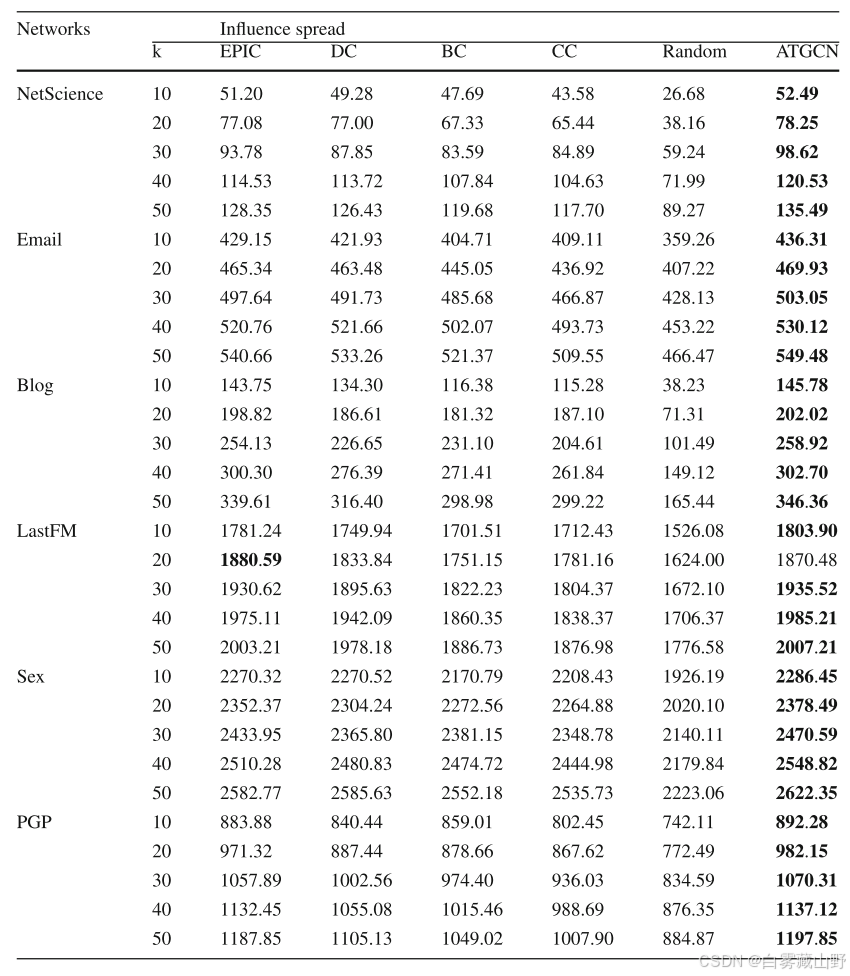
表7显示了建议的ATGCN和五种基线算法在每个网络上的影响范围的总结,k = 10、20、30、40和50。如表7所示,除了在k = 20的LastFM网络上,EPIC[49]返回的场景1880.59之外,基线算法的影响范围都不如ATGCN。我们可以观察到,与现有的最先进的基于贪婪的自适应播种策略相比,所提出的自适应播种策略ATGCN将影响传播率提高了7%。
EPIC[49]:一种基于反向影响抽样机制的贪婪自适应播种策略,获得了(1−exp(pb(ε−1))))个期望逼近保证。
DC[6]:一种流行的基于中心性的启发式算法,它测量一个节点在一跳区域内相邻邻居的数量。 BC[43]:该方法通过计算经过该节点的最短路径的数量来量化该节点的重要性,并表征该节点在网络中的桥梁功能。
CC[43]:这种方法计算一个节点和其他节点之间沿着最短路径行进的整个距离。
Random[6]:传统的基线方法,随机选择种子节点。
局限性:
针对自适应影响最大化问题,提出了一种简单的仅由一个参数β控制的自适应播种策略。一个问题是,是否应该在传播过程结束之前持续收集反馈,而不考虑在每轮中部署额外的播种预算,或者在前几轮中耗尽播种预算更可取。因此,一个潜在的未来方向是探索更有效的自适应播种策略。同时,实验主要是在中小型数据集上进行的,由于计算的限制,尚未验证大型数据集上是否会出现网络结构信息丢失。在未来的工作中,我们将在大规模数据集上验证所建议方法的性能,并开发新的策略来提高所建议策略的性能和鲁棒性,例如通过应用采样方法来修剪图的大小。
总结:
本文研究了种子个体在观察一些扩散结果后自适应选择的适应性影响最大化问题。本文首次提出了一种基于深度学习模型的具有自注意力机制机制的图卷积网络方法,将AIM问题作为回归任务来解决。该方法的自注意力机制机制充分利用全局拓扑信息和节点属性信息,自适应地为每个节点分配不同的注意权值,提高了节点表示的质量和表达能力,具有良好的泛化能力。同时,在自适应策略中,控制参数β可以平衡扩散延迟和影响扩散。为了展示自适应策略与非自适应策略相比的优势,并测试我们提出的方法的性能,在六个现实社会网络上进行了一系列实验。大量的实验结果表明,自适应策略可以充分利用播种预算来实现更大的影响传播,因此优于传统的自适应策略。在求解自适应影响最大化问题方面,该方法比这些基线方法具有更好的性能。


















 2205
2205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









