






目录
数据库约束
有时候对数据库的数据有一定要求, 相对于计算机来说, 人不靠谱, 数据库自动对数据的合法性进行校验检查的一系列机制, 目的是为了保证数据库中避免被插入/修改一些非法数据
MySQL中提供了一下约束:
NOT NULL : 指定某列不能存储NULL值
UNIQUE: 保证某列的每行必须有唯一的值
DEFAULT: 规定没有给列赋值时的默认值
PRIMARY KEY: NOT NULL 和 UNIQUE 的结合, 唯一标识
FOREIGN KEY: 保证一个表中的数据匹配另一个表中的值的参照完整性
CHECK: 保证列中的值符合指定的条件(了解)
举个例子:创建一个数据库, 和一个学生表
NOT NULL : 指定某列不能存储NULL值
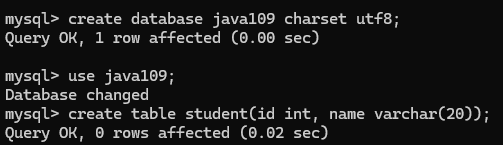
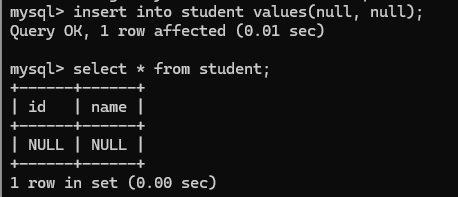
这时可以加入null这个数据
现在删除这个表加入约束条件 NOT NULL, 重新进行上述操作
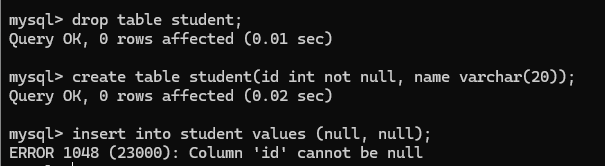
添加失败, 不但插入不能加入NULL数据, 修改也不行.
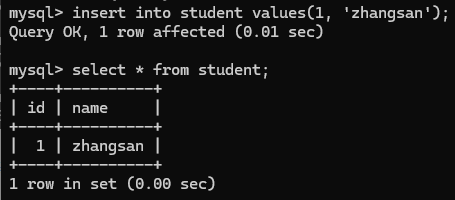
显示修改失败.
![]()
UNIQUE: 保证某列的每行必须有唯一的值
如图:重新创建一个学生表
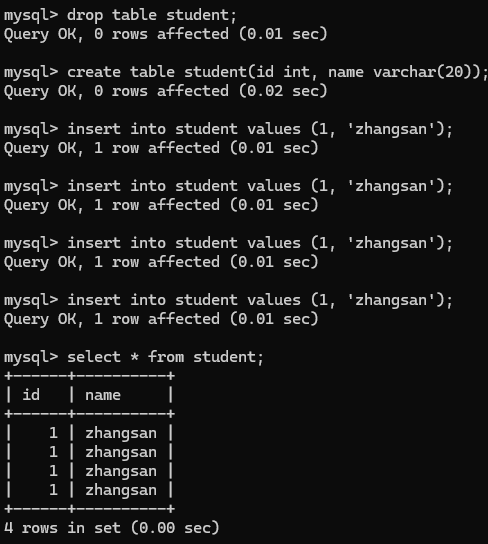
然后里面可以有重复的数据, 现在创建一个加入约束条件的表, 重复上述操作.
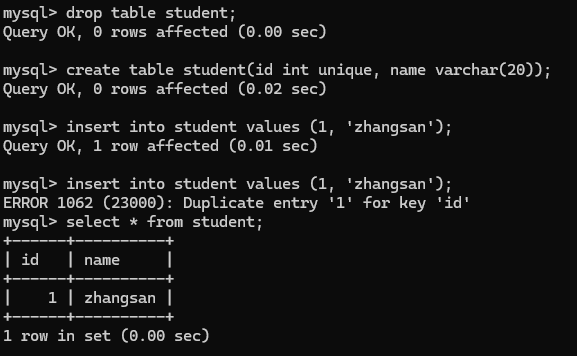
这时一个数据只能进行一次插入, 同样" 修改 " 操作也会限制.
unique 约束, 会让后续插入/ 修改数据的时候都会触发一次查询操作, 通过这个查询来确定这个记录是否已经存在, 数据引入约束后, 执行效率就会受到影响, 可能降低很多. 这就意味着数据库是比较慢的系统, 成为一整个系统的" 性能瓶颈 ".
DEFAULT: 规定没有给列赋值时的默认值
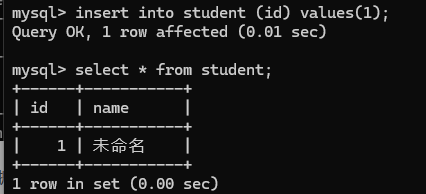
在第五列, 默认的默认值的值时null通过default约束修改默认值

这是修改过后的值.

后续插入数据的时候, default 就会在没有显式指定插入的值时生效了.如图:
上述设置约束都是先删除表再重新创建表, 也能不删除表直接设置约束, 但比较麻烦.
一个数据可以有多个约束
PRIMARY KEY: NOT NULL 和 UNIQUE 的结合, 唯一标识(最重要的约束)
![]()
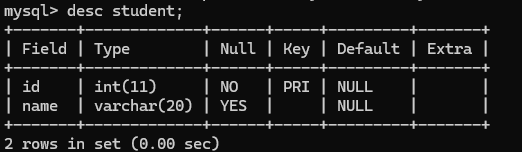
一张表里面只能有一个 primary key , 一张表里的纪录只能有一个作为身份标识的数据, 否则会报错.

虽然只能有一个主键, 但是主键不一定只是一个列, 也可以用多个列构成主键, (联合主键), 这个了解即可.
对于带有主键的表来说, 每次插入数据 / 修改数据, 也会涉及到进行先查询的操作.mysql 会把带有unique和primary key的列自动生成索引, 从而加快查询速度.

如何保证主键唯一呢?
mysql提供了 " 自增主键 "的机制
主键经常使用int / bigint 作为主键
插入数据时数据库服务器分配一个主键, 从1开始, 自己也可以指定
![]()
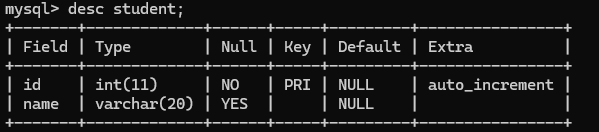
这时插入一个记录, 自动从一开始.我们指定一个10id插入后, 再次输入空值后, 选择最大的数值开始继续往后分配.

此处id的自动分配有局限性, 如果是单个MySQL服务器没问题, 如果时分布式系统(就是多台机器),多个MySQL服务器构成的集群, 依靠自主增键就不行了, 分布式系统中生成唯一 id 的算法有很多, 公式: id = 时间戳 + 机房编号/主机编号 + 随机因子
FOREIGN KEY: 保证一个表中的数据匹配另一个表中的值的参照完整性
创建班级表, id和name, 其中id为主键, 创建学生表, id, name和 classId, 一个学生对应一个班级, 一个班级对应多个学生, id为主键, classId为外键 其中class表称为父表. student表 称为子表

其中froeign key(classId) 中的classId为当前表中的, 后面的值class表中的
 针对这个插入操作, 会触发对class表的查询, 看插入的数据在class中是否存在,修改操作同样如此
针对这个插入操作, 会触发对class表的查询, 看插入的数据在class中是否存在,修改操作同样如此
注意:
1>对父表进行修改/删除操作, 如果当前被修改/删除的值, 已经被子表引用了, 这样的操作也会失败, 外键约束要始终保持
2>如果想要删除父表, 需要先删除子表
3>指定外键约束的时候, 要求父表被关联的这一列得是主键或者 unique
表的设计
两个要点:
1> 梳理清楚需求中的" 实体 "
2> 确定好实体之间的关系
实体就是对象, 每个实体一个表, 表的列对应实体的属性
实体之间的关系三种, 一对一, 一对多, 多对多
1> 一对一 : 一个学生拥有一个账号, 一个账号只能被一个学生拥有

2> 一对多: 一个班级拥有多个学生, 一个学生只能拥有一个班级

3> 多对多: 一个学生拥有多个课程, 一个课程拥有多个学生

查询操作的进阶
查询搭配插入使用
把一个查询语句的查询结果插入
如图: 创建s1和s2然后把s的值放入s2中,刚开始为空
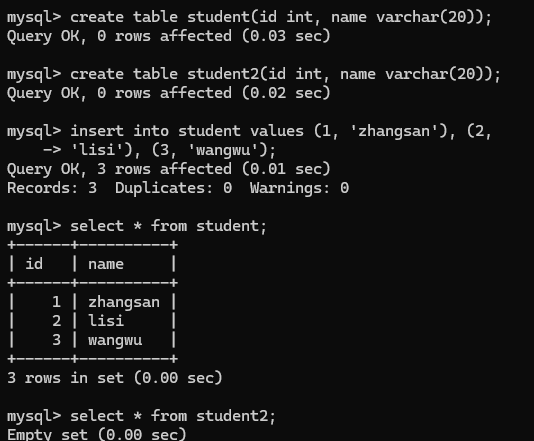
插入之后:
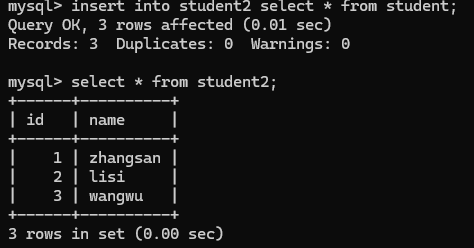
注意: 要求查询出来的结果集合, 列数/类型要和插入的表匹配;
聚合查询
表达式查询是针对 列 和 列 之间进行运算的
聚合查询相当于在 行 和 行 之间进行运算的
MySQL提供一些聚合函数进行运算
举个例子: 先创建一个表, 如图:
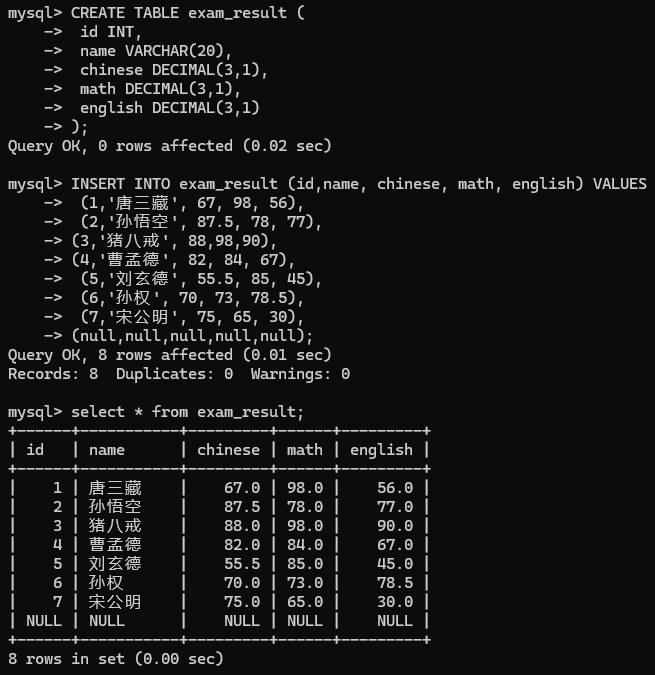
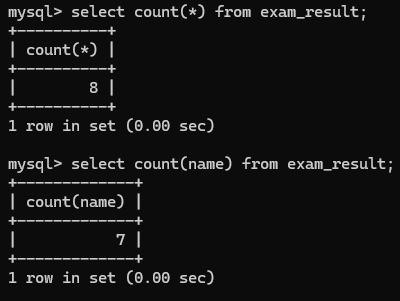
1>count(*)
获取行数, 先执行select *在针对结果几个进行统计

注意:
1) 如果当前列里面有null就不同了
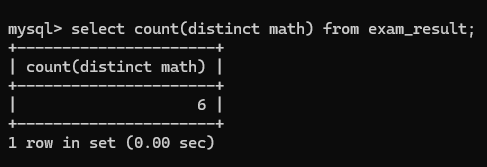
2) 指定具体列可以去重
如图:
name那一列有null显示查出了7行
数学那一列有两个98, 使用 distinct 指定这一列时会去重
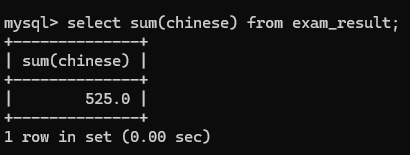
2>sum(*)
把这一列算数相加
sum(列)
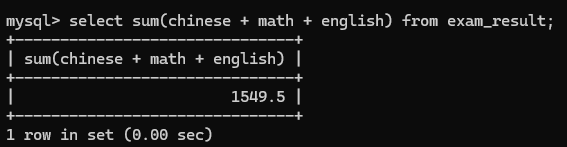
sum(表达式)
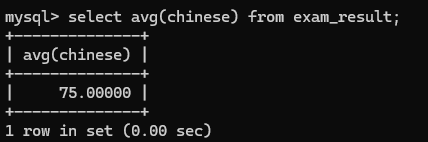
3>avg(*)
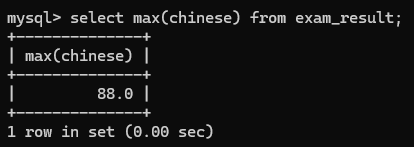
4>max(*)
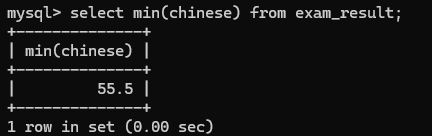
5>min(*)
group by分组分别进行聚合查询
针对指定的列进行分组, 把这一列中, 值相同的行, 分到一组中, 得到若干个组, 针对这些组分别使用聚合函数.
举个例子:如图
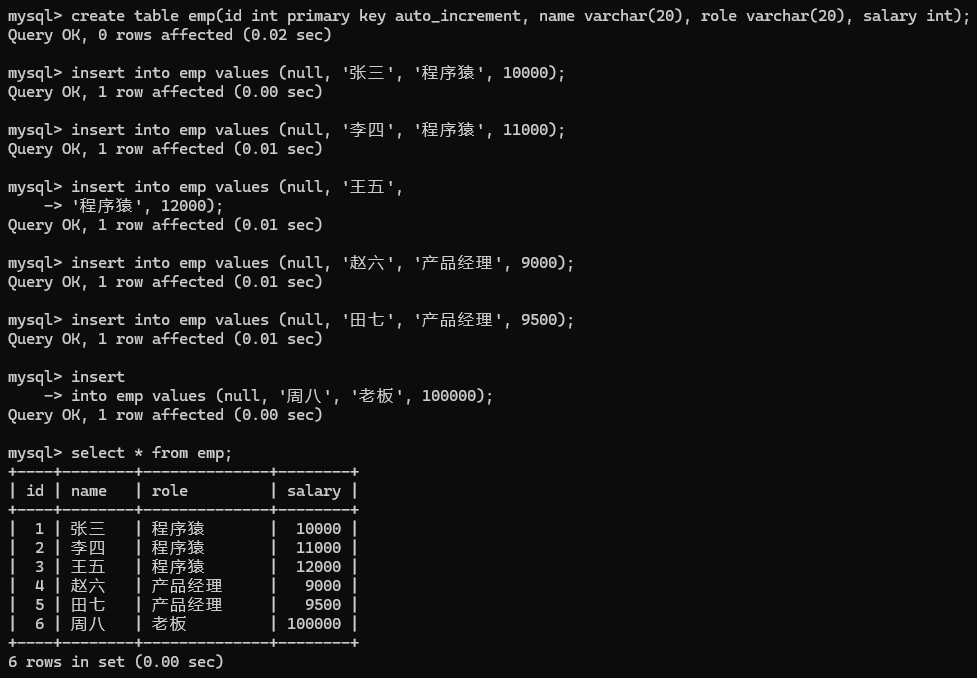
如果针对所有人算薪资的平均值是不准的, 应该让每个职位的人分组后在计算
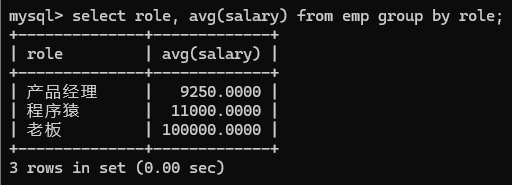
往往进行分组要和聚合函数搭配使用.
注意:
使用group by的时候, 还可以搭配条件, 需要区分清楚, 该条件是分组之前的条件还是分组之后的条件
例子:
1> 查询每个岗位的平均工资, 但是排除张三 (分组条件值之前)
直接使用where即可, where 字句写在group by之前
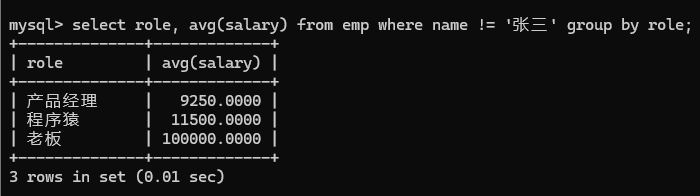
2> 查询每个岗位的平均薪资, 但是排除平均薪资超过2W的结果 (分组条件之后)
使用 having 描述条件, having 字句写在group by后面
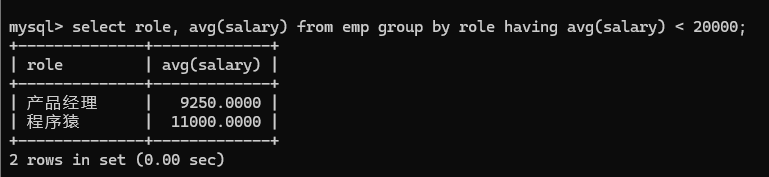
3> 在group by , 可以一个sql同时完成这两类条件的筛选
查询每个岗位的平均薪资, 不算张三, 并且保留 平均值 < 2W的结果

联合查询 / 多表查询[重点]
前面的查询针对一个表, 有些查询需要从多个表中进行查询
关键思路在于" 笛卡尔积 "工作过程
举例:
第一组: A B C
第二组: 1 2 3
计算笛卡尔积就是他们的排列组合: A1, A2, A3, B1, B2, B3, C1, C2, C3
笛卡尔积通过排列组合得到更大的表, 笛卡尔积的列数就是两个表的列数相加, 笛卡尔积的行数就是两个表的行数相乘.(其中有的数据是无意义的, 需要通过一个条件(连接条件)把有意义的数据筛选出来)
举个例子:如图,共4张表, 学生, 班级, 课程, 分数(学生和课程之间的关联表)
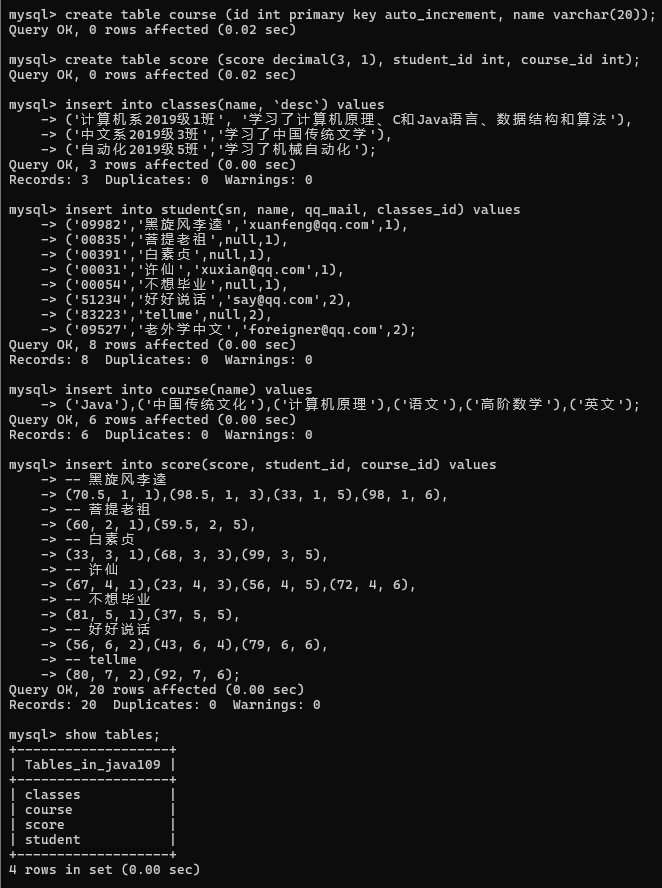
1> 查询许仙的成绩
先进行笛卡尔积(对学生和分数)
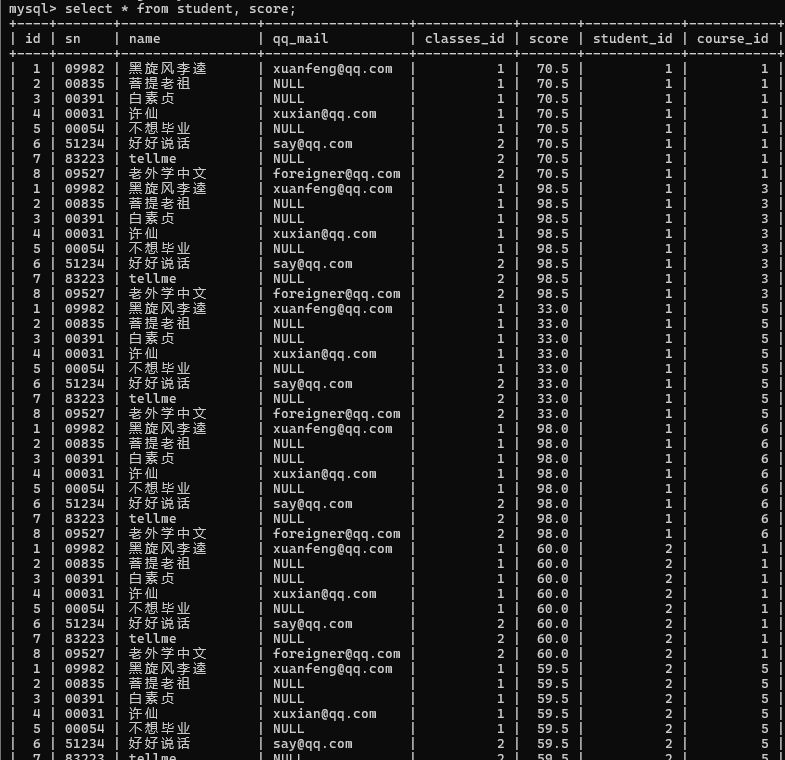
然后筛选学生表的ID和分数表的同学ID相同的行数
选择不同表中的列尽量加上两个表的名称.列名
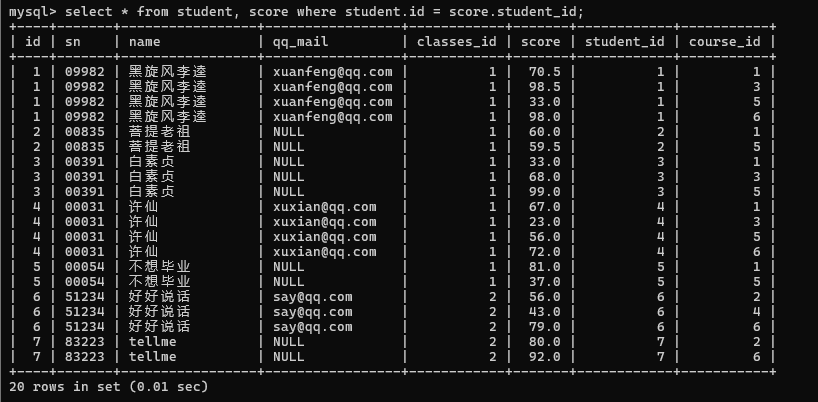
然后筛选出许仙同学的行
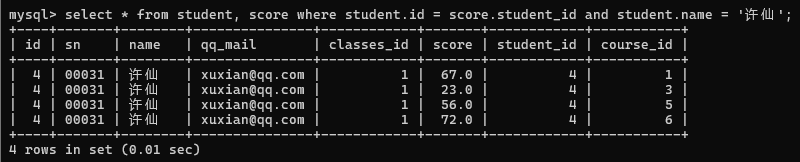
最后针对所需要的信息进行精简

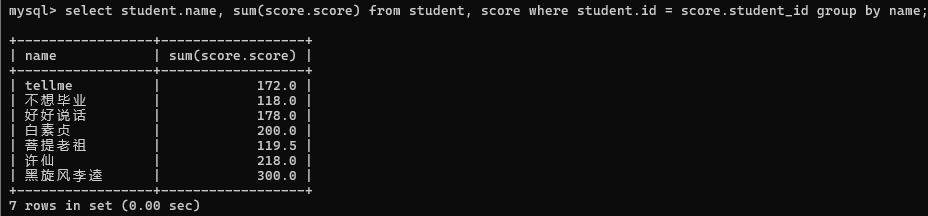
2>查询所有同学的总成绩, 以及同学的个人信息(多表查询和聚合查询综合运用)
先进行笛卡尔积
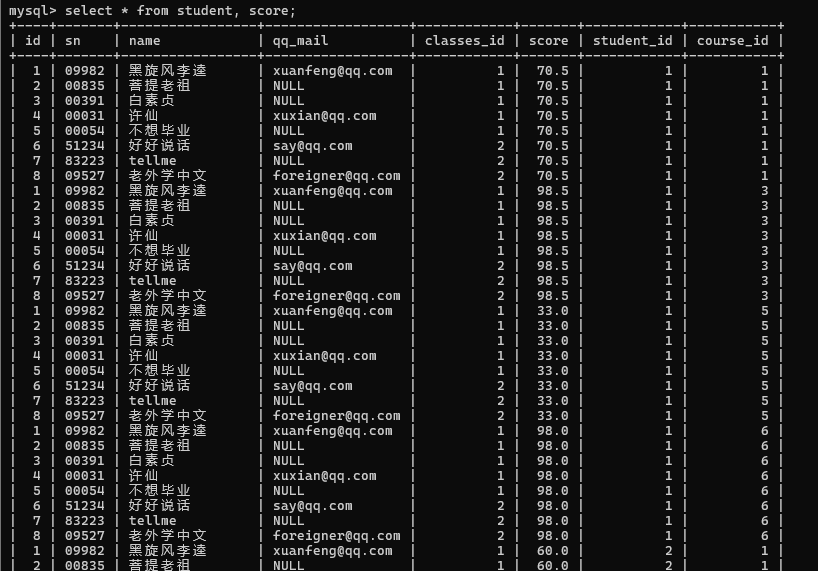
然后指定连接条件
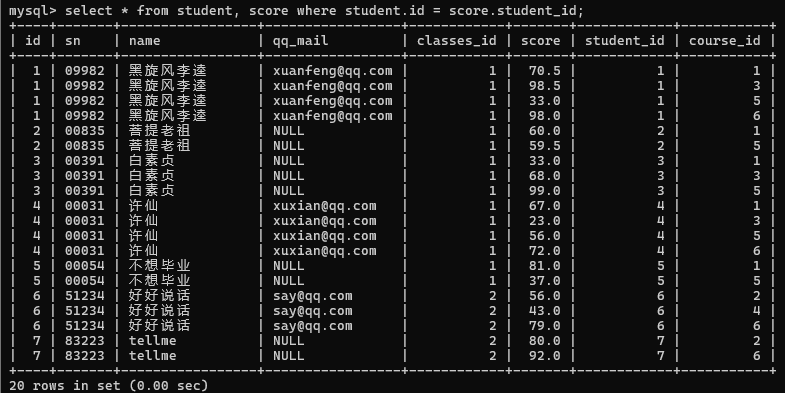
先精简列
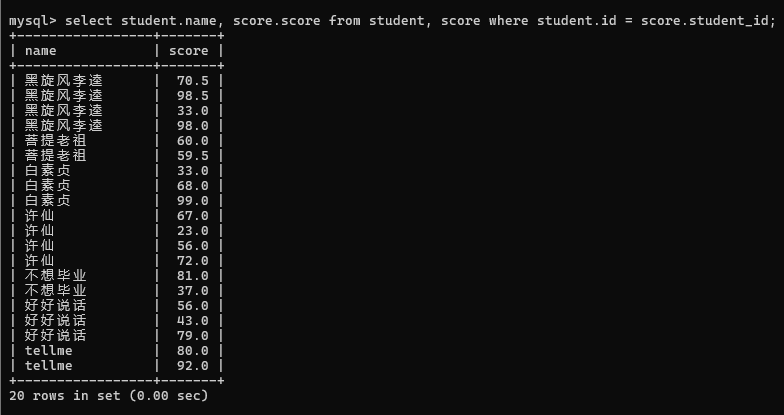
针对上述结果, 再进行 group by 聚合查询
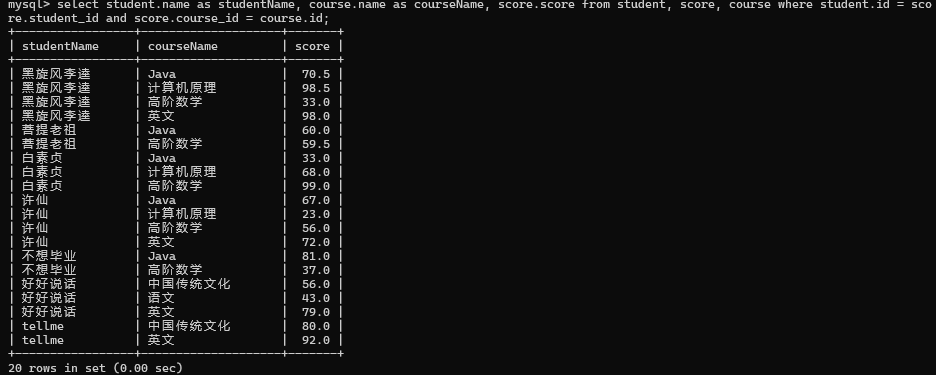
3>列出每个同学, 每门课程课程名字和分数
先进行笛卡尔积

然后指定连接条件

然后精简列
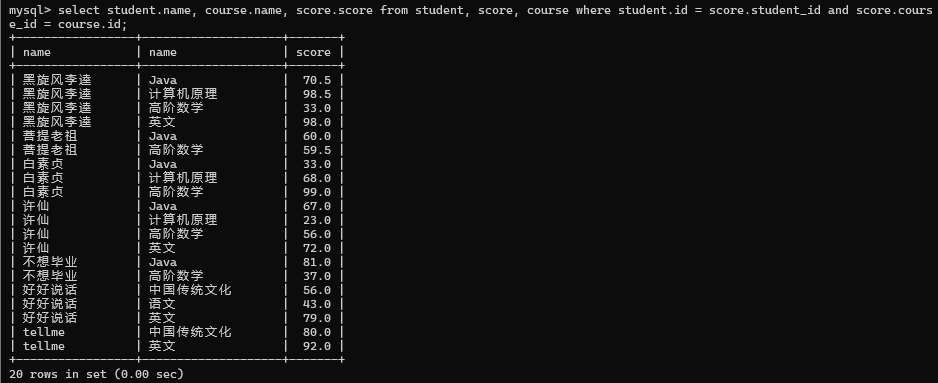
可以使用别名如下图:
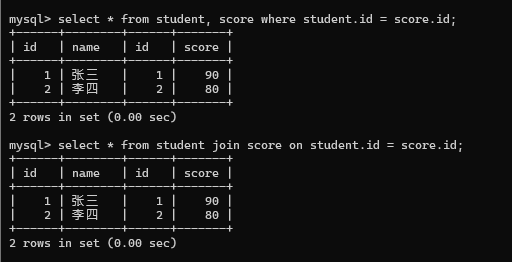
外连接
上述操作时" 内连接 ", MySQL进行多表查询, 还可以使用" 外连接 " (左外连接, 右外连接)
如果两个表里面的记录都是存在对应关系, 内连接和外连接的结果是一致的, 如果存在不对应的记录, 内连接和外连接就会出现差别.

这种情况内连接和外连接一样

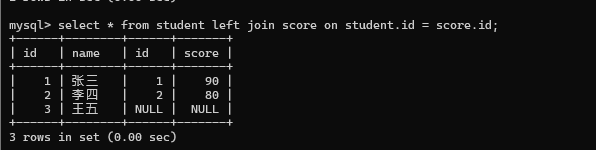
这种情况两者不一样

使用内连接情况一样
使用左外连接 left join, 保证左侧表的每个数据都会出现在最终结果里
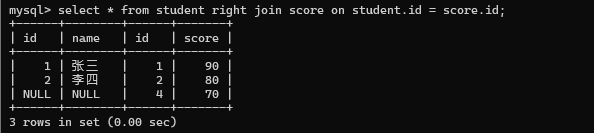
使用右连接 right join, 保证右侧表的每个数据都会出现在最终结果里
自连接
一张表自己和自己进行笛卡尔积
有时候需要去进行行和行之间的比较, 而MySQL只能进行列和列的比较, 使用自连接把行的关系转换成列的关系
举个例子: 显示所有计算机原理比java成绩好的成绩信息
首先进行自连接, 这时需要将score改变为别名, 否则会报错
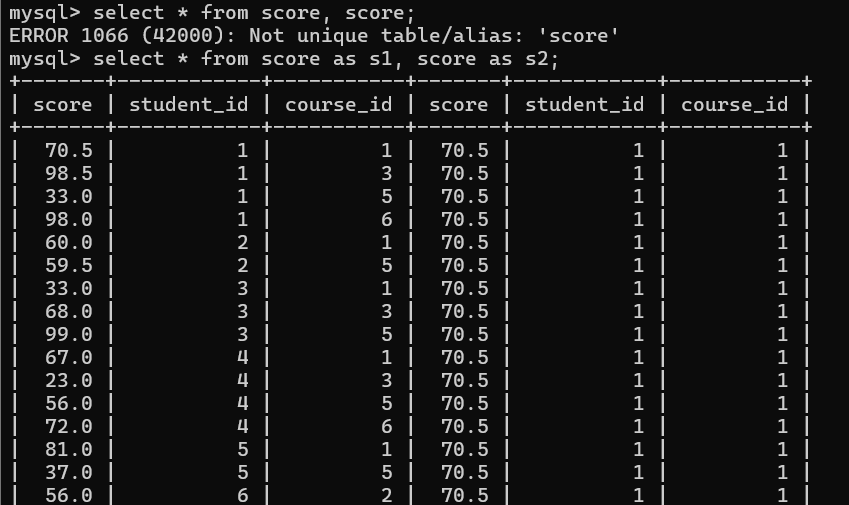
指定连接条件

精简

子查询
本质上实在" 套娃 ",把多个简单的MySQL拼成一个复杂的MySQL
单行子查询, 返回结果是一行记录
举个例子, 找到不想毕业同学的同班同学
分两步完成
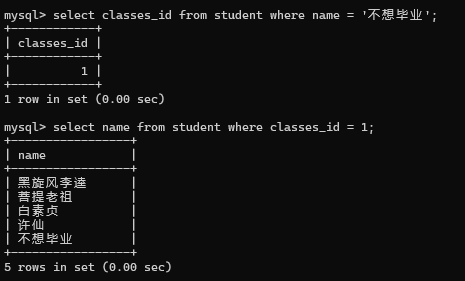
现在一步完成

二者结果一致
多行子查询: 返回多行记录的子查询
举个例子: 查询 " 语文 " 或 " 英文 " 课程的成绩信息
使用联合查询可以解决

使用子查询完成
分两步走
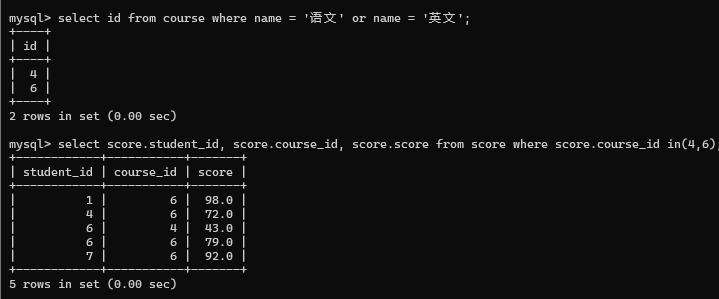

合并查询
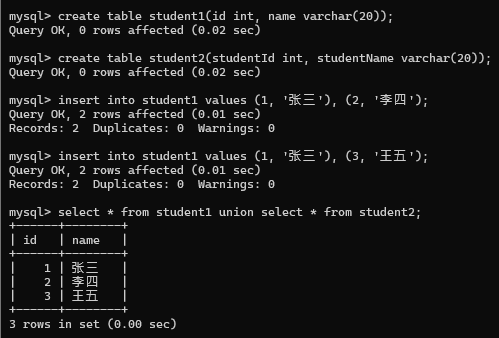
把多个sql查询的结果集合, 合并到一起. union关键字
查询id小于3, 或者名字为 " 英文 "的课程
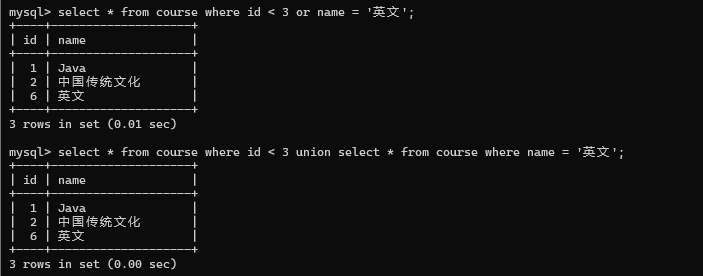
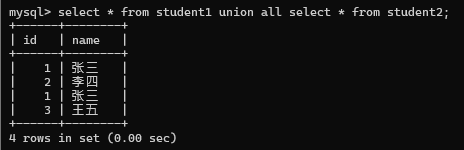
两种的结果一样.后者允许把两个不同的表, 查询结果合并在一起. 但是两个合并的sql的结果集(列的个数和类型) 要一样;(名字不用管)
合并的时候是会去重的, 但是使用union all就不会去重
小结:
1> 约束中, 主键约束 和外键约束 更难一点, 重点关注, 其他的也要动手敲一下
2> 表的设计(一对一, 一对多, 多对多)
3> 聚合查询 , 熟悉语法
4> 联合查询, 熟悉语法
加油, 很繁琐, 静下心来学.















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









