






文档系转载,便于整理和分类,原文地址:https://devnote.pro/posts/10000064041178
了解词典
在了解Redis如何实现dict之前,先梳理下dict特征以及使用。
词典数据结构通常用于以键值对的方式存储数据。词典存放了一组键,每个键关联一个值。词典存放的键是唯一的,通过查询词典里的键,可以获取键对应的值。如果存储重复的键,会导致新值覆盖键关联的旧值。
词典数据结构支持以下几种操作:
- addOrUpdate(K key, V v):以键值对的形式插入数据,如果key在词典中存在,会用新值覆盖旧值。
- search(K key):传入搜索的键作为参数,返回此键关联的值。
- delete(K key):删除指定键的条目。
词典的实现
根据词典的特征,有哪些实现方案呢。通常的实现方法有:
- 简单实现:以直接寻址的方式存放在有序或无序的序列中。
- Hash Table:对词典的key做哈希,存放在哈希表中。
- Tree:以树状数据结构实现,例如:
- 二叉查找树
- AVL树
- 红黑树
- B树
- 平衡树
Redis词典是基于Hash Table实现,Hash Table在增删查的平均时间复杂度是O(1),只有在发生了hash code碰撞差的情况才会到O(n)。但Hash Table需要预分配存储的空间,是以空间换时间的一种方案。
大部分的编程语言也比较常用Hash Table作为词典的内部实现。
Hash Table实现词典需要考虑的要点
Hash,中文称为散列,或音译为“哈希”,它会把任何长度的输入,通过哈希算法计算得到固定长度的hash值。相同的输入通过相同的哈希算法得到的hash值是相同,且通常hash值所占用的空间比输入值要小。
Hash Table把Hash的这个特点应用到存储上,这个过程简化是:使用hash算法计算输入hash值,再把hash值映射为存储的某个位置进行存储。
如图:

要高效存储查询,需要我们在这个映射的过程中考虑几点:
- 评估哈希算法的效率以及均衡性
- 哈希算法Hash Function计算要快,否在会影响存储以及查找效率
- 哈希算法计算得到的hash值,通过索引映射后,能够比较均匀的分配在存储上。
- 如何解决Hash碰撞:不同的输入计算得到的hash值可能是相同的,这种情况称为Hash碰撞。需要解决hash碰撞导致的存储位置冲突问题。
- 如何解决Hash Table的扩容:Hash Table一般会预分配好固定大小的存储空间,当存储不够时如何扩容。
带着这几个问题有助于我们去理解Redis的词典的实现。
Redis实现词典的数据结构
整个Redis实现词典的数据结构如图:
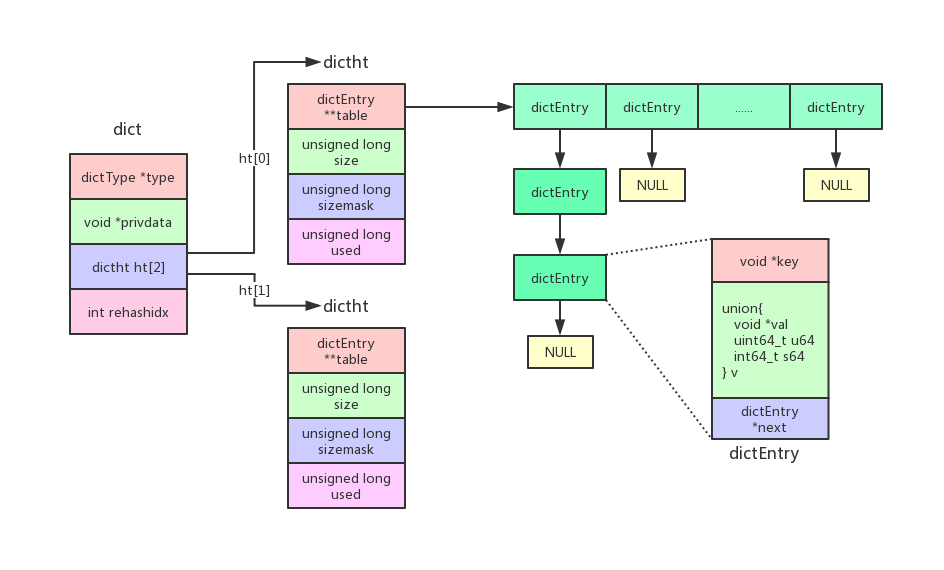
各个数据结构说明:
- dict:词典数据结构,它包含了两个哈希表,其中
ht[0]存放数据,ht[1]用于扩容的rehash(重新hash分配空间)。reshashidx存放rehash的索引。 - dictht:哈希表,实现了哈希的数据结构,包含用于存散列节点的数组table,数组大小size以及数组已使用索引数used。
- dictEntry:哈希表的节点,它存放了key-value的数据以及相同存储位置索引的链表的下一节点。
在后面章节带着问题再进一步了解Redis对词典的实现。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









