







本文中我们介绍一些GPU的基础知识,首先寄出一张PC的架构图。

所有的GPU设备通过PCI-E总线与处理器相连。PCI-E 2.0总线标准中传输速度为5.0GB/s,访问内存需要经过北桥,访问外设需要经过北桥和南桥。北桥服务于所有高度设备,南桥服务于低速设备。CDUA4.0 SDK提供的CPU直连技术诸如infiniBand等高速互联设备10kM以太网卡可以连接到PCI-E总线上。这是可以直接和CPU通信,无需先经过CPU转发。我们这里给出一些主流的CPU架构系统。
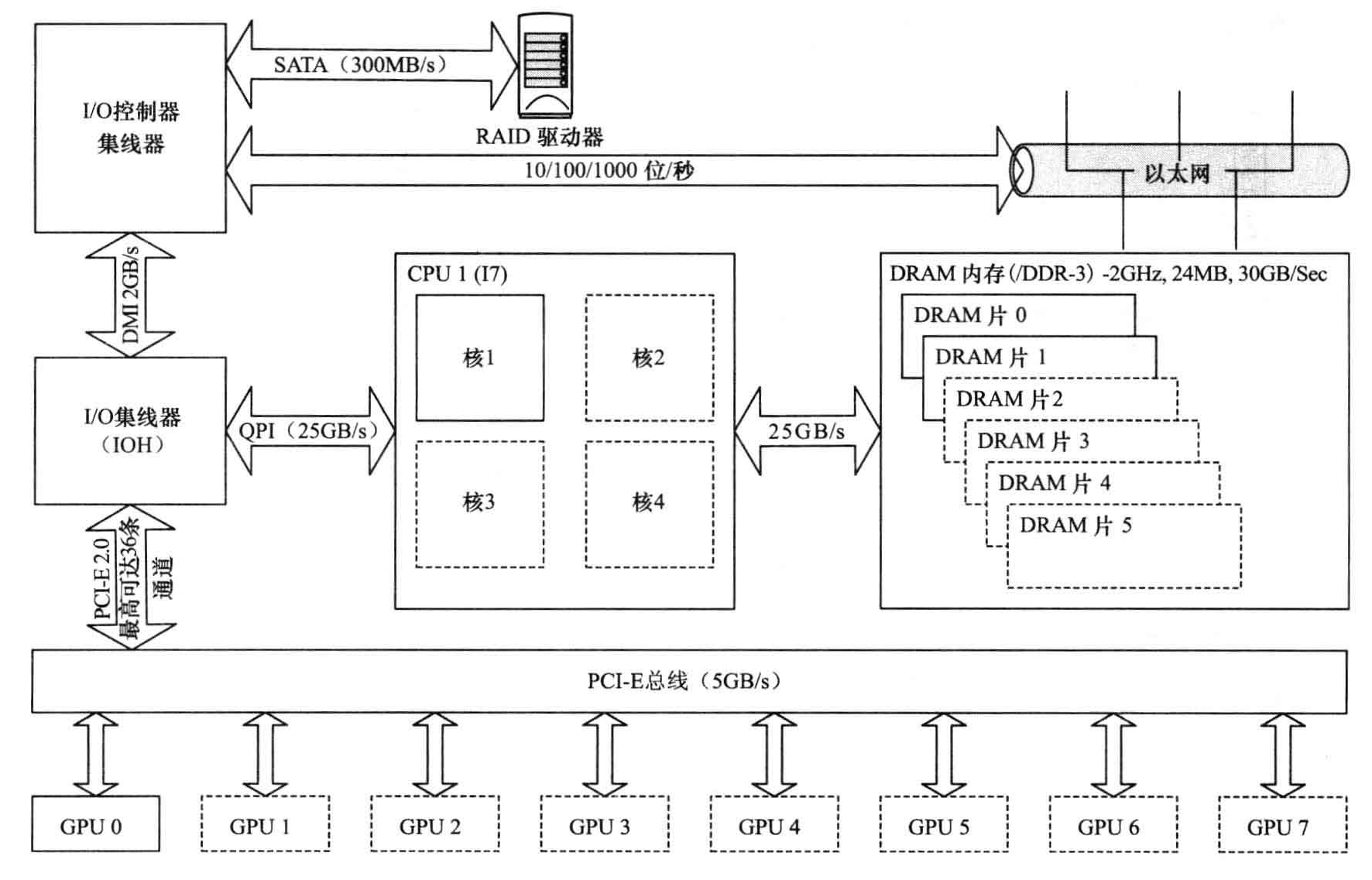
Nehalem_X58系统
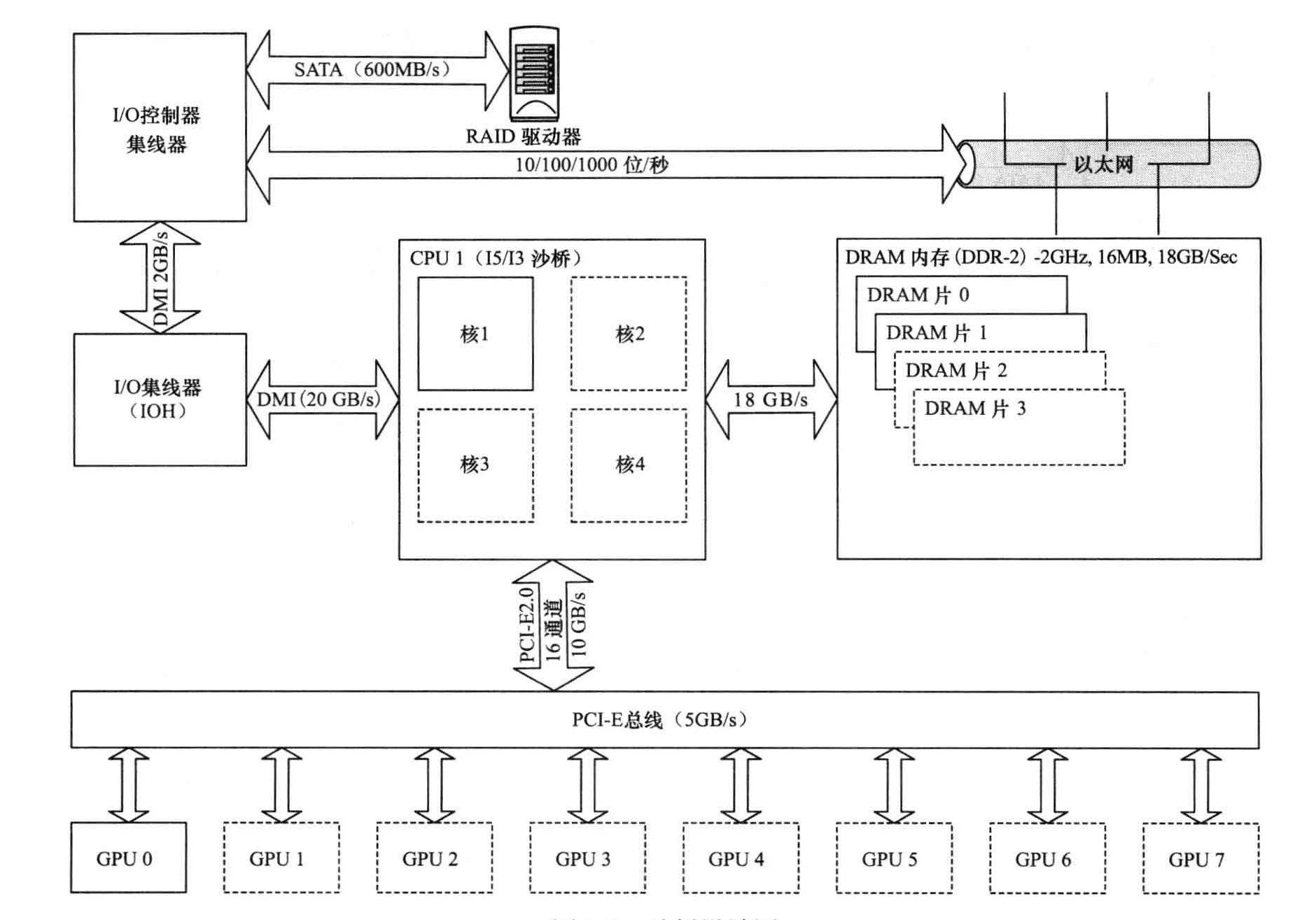
Sandy Bridge(Intel架构)
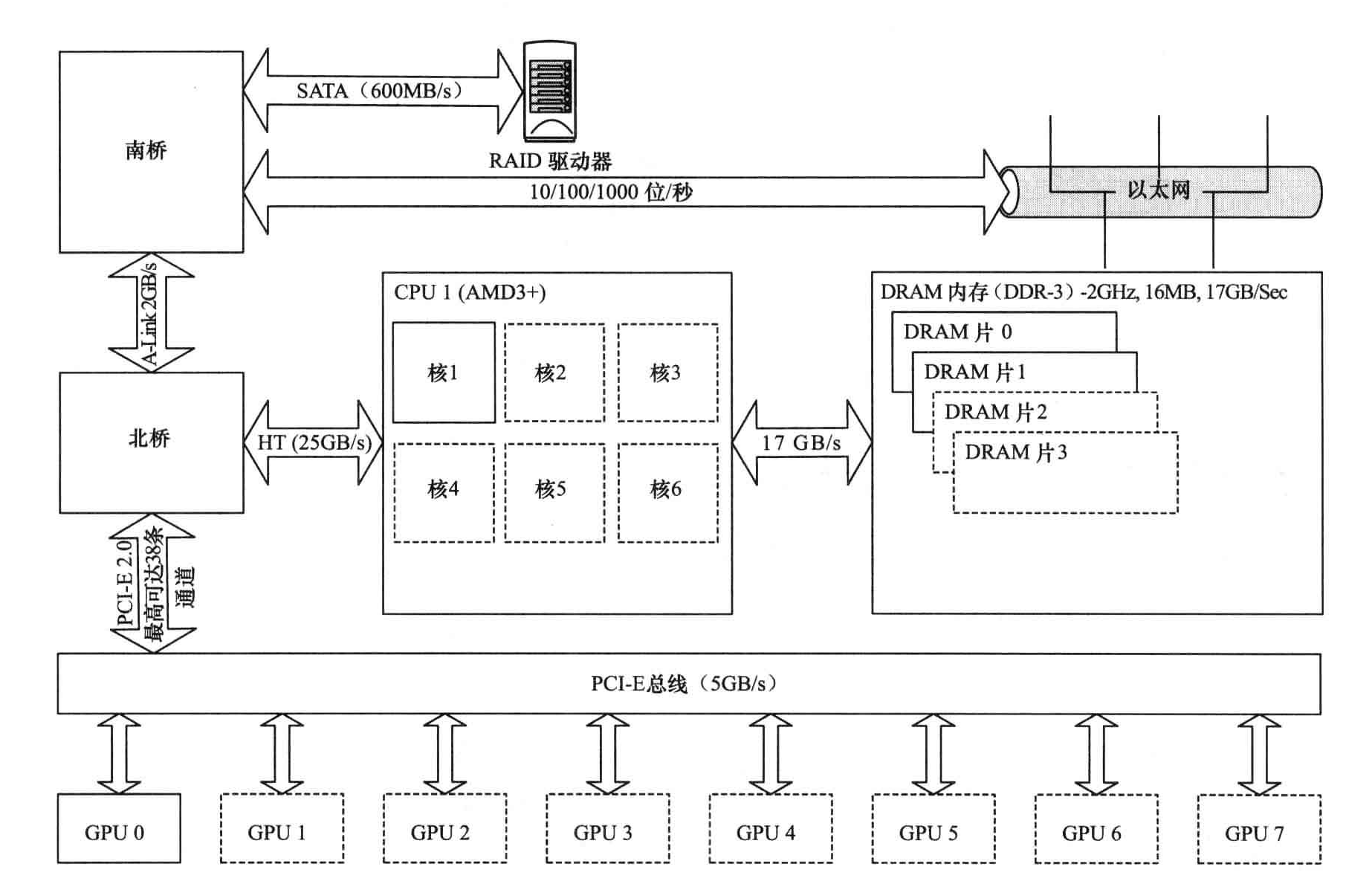
AMD架构
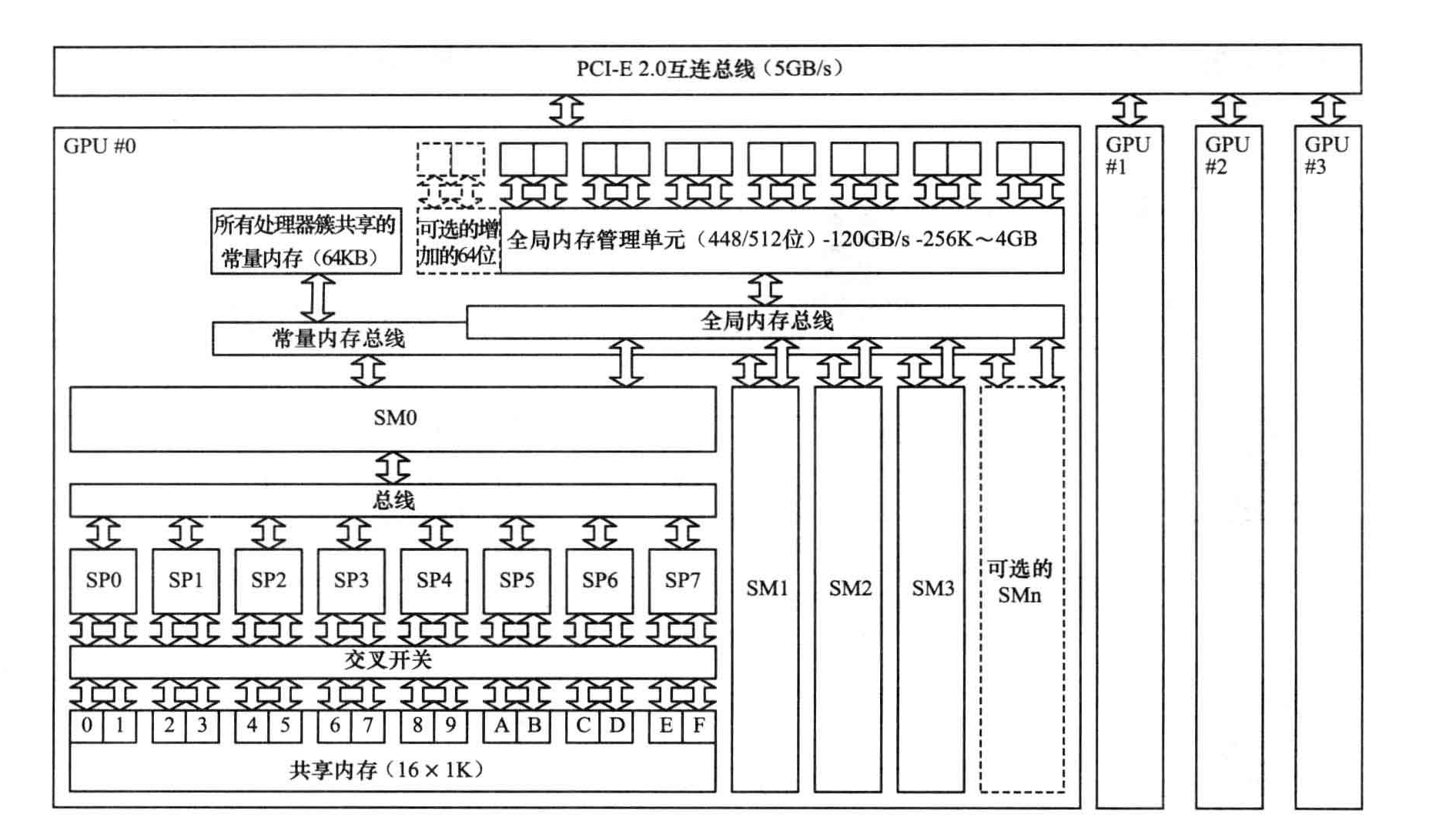
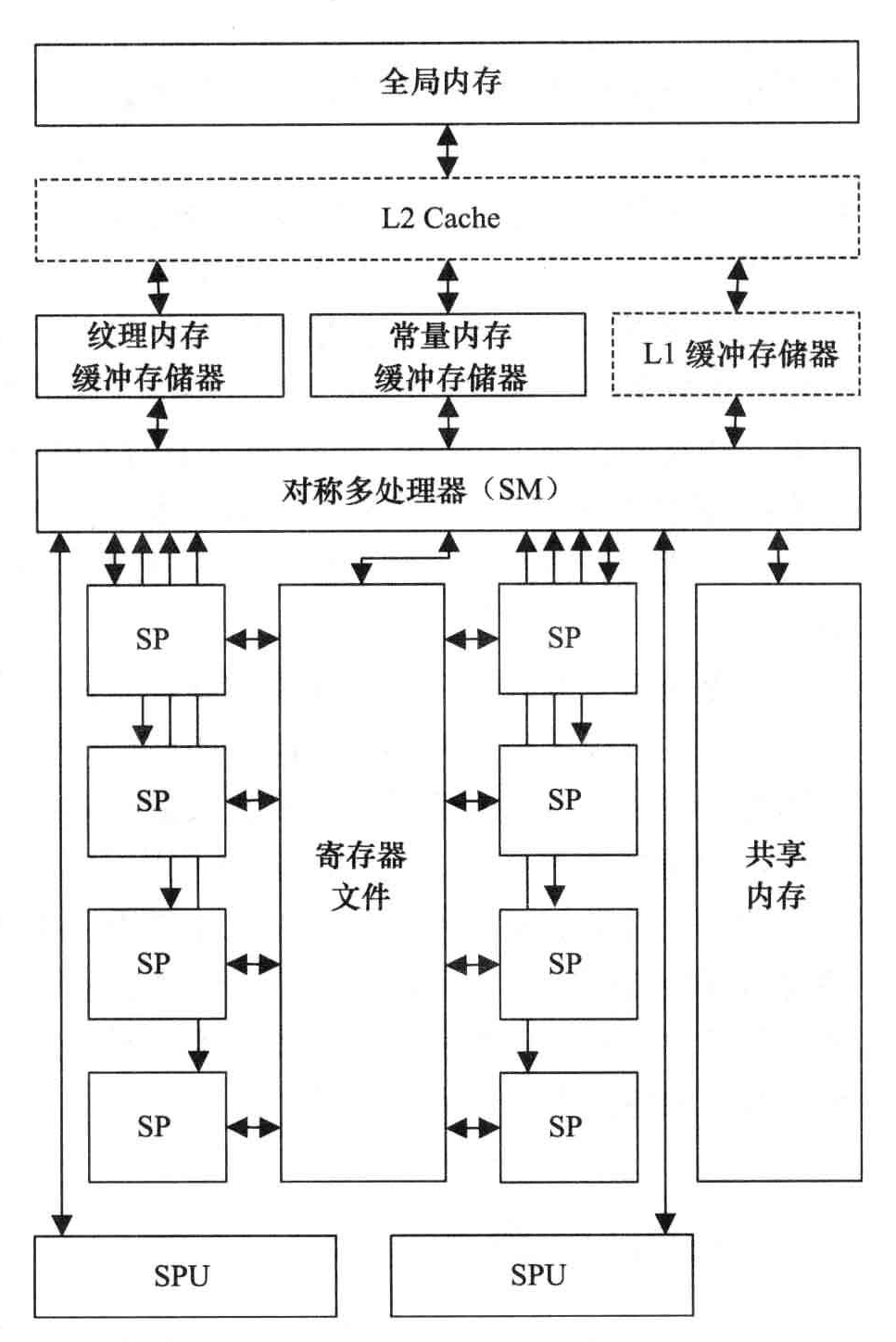
GPU硬件的关键模块
- 内存
- 流处理器(SM)
- 流处理器(SPE)
GPU实际上是一个SM的阵列,每个SM包含N个核。一个GPU中包含多个SM是GPU可扩展的关键因素。
每个SM都需要访问一个寄存器文件,这是一组能够以与SP形同速度工作的存储单元。寄存器文件用来存储SP上运行的线程内部数据的寄存器。
另外还有一个只供每个SM内部访问的共享内存,共享内存完全有程序员控制,没有自动完成数据替换的硬件逻辑。纹理寄存器是针对全局内存的特殊视图,用来存储插值计算所需的数据,常量内存用于存储那些只读的数据。
GPU的计算能力
CUDA支持多个级别的计算,G80系列图形卡配有CUDA的第一个版本上市。
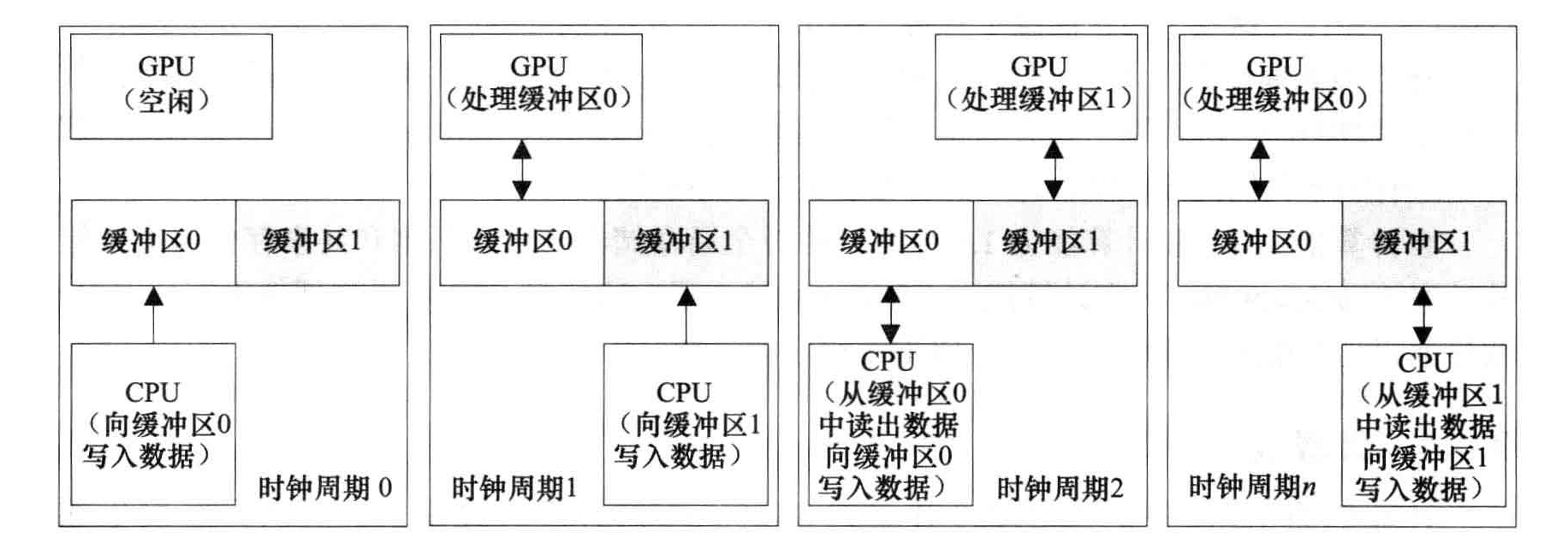
- 计算能力1.0的性能缺陷主要与原子操作有关。计算能力1.1带来的主要变化时支持数据传送和内核程序的重叠执行。双缓冲。
- 计算能力1.2多处理器数量增倍。计算能力1.3的主要变化时双精度浮点运算。
- 计算能力2.0的主要改进一级缓存,二级缓存,内存检查和纠错,
引入缓存,是程序员更容易编写出适合在GPU硬件上工作的程序,还允许应用程序不必遵守在编译时已知的存储器访问模式。由于新一代GPU引入了一级缓存和二级缓存,为优化访存耳提出的对齐要求更加严格,每次方未能缓存去除的最少数据为一个存储块。如果程序中每个每个线程的访问模式是稀疏耳分散,那么应该屏蔽掉这个对齐要求,转回32位的缓存操作模式。计算能力到今天已升级7.1。性能大大增强。















 2398
2398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









