







论文《Segment-Based Predominant Learning Swarm Optimizer for Large-Scale Optimization》阅读笔记。
1.SPL更新方法。对于种群P,随机选择两个粒子将其适应度值进行比较,划分RG (good)和RP(poor),相对较好的粒子RG和相对较差的粒子RP,大小分别为(粒子数/2)。(X_RG_RP_j)是RP中的粒子j在RG中的学习粒子的位置,(X_RG_rand)是RG中随机选择的粒子。
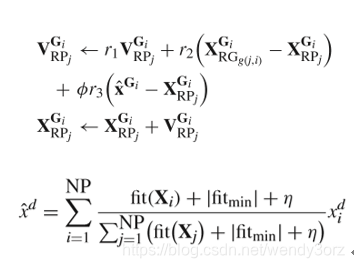
其中,(RP_j)是RP中第j个相对较差的粒子,总维度m被完全划分为:G={G_1,…G_i,…G_m }, g(j,i) 表示第j个相对较差的粒子将从G_i中学习的对应的相对较好的粒子,x ̂是种群的加权平均位置,r是[0,1]之间的随机数,φ=0.1为控制影响因子。η是用于避免零分母的小正值。
2. 动态分块。分解池S={1,10,20,50,100,250},相对性能改进R_S={r_1,…,r_t }初始化为1,集合S中元素选择概率为P_s={p_1,…,p_t }。
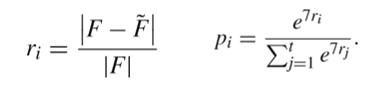
其中,F是指上一代的全局最优适应度值,F ̃是当代全局最优适应度值。得到集合P_s,使用轮盘赌的选择方式得到集合S中维度分块数目。
3. SPL策略使得进化过程中种群的多样性提高,收敛速度变缓。
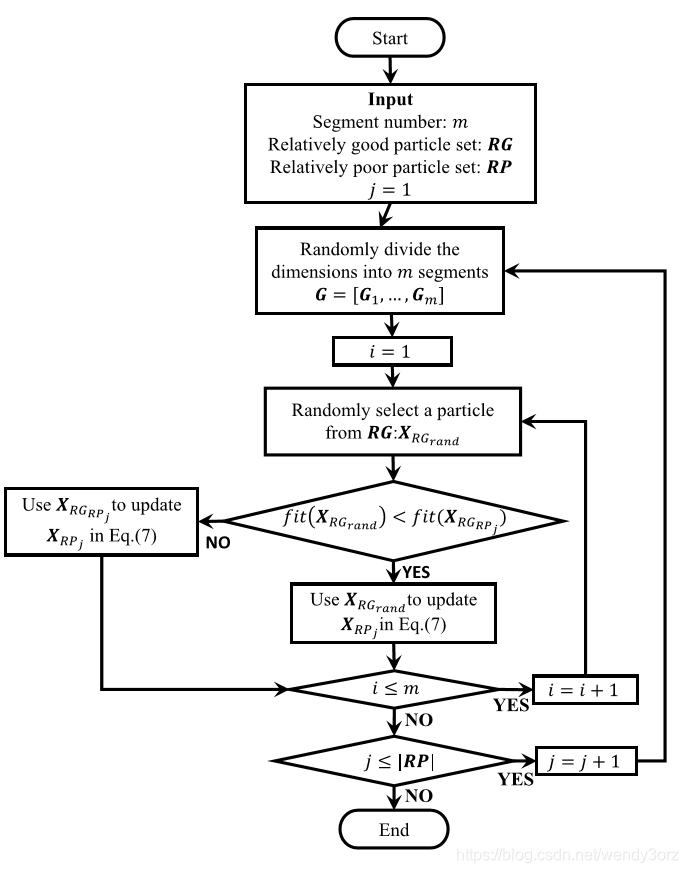
4.总算法流程图














 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









