







集群测试
1. 进行简单的测试
dfs表示是对分布式文件系统进行操作;-put是将当前系统的目录放到Hadoop系统的文件系统的相应目录中。第二条命令中的字符”\”是多余的
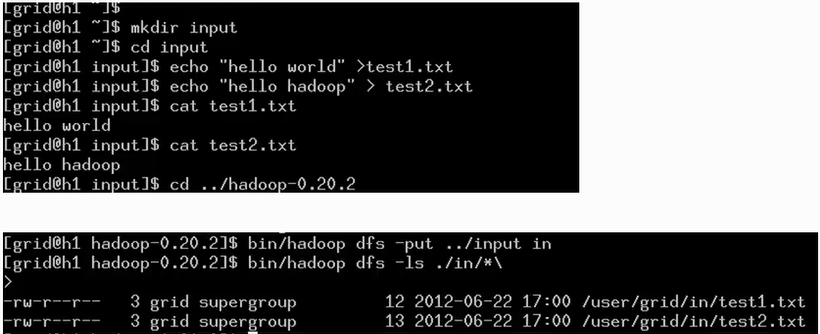
2. 运行wordcount程序,测试上面放进分布式文件系统中的文件,即相当于提交MapReduce的作业,是Java程序。
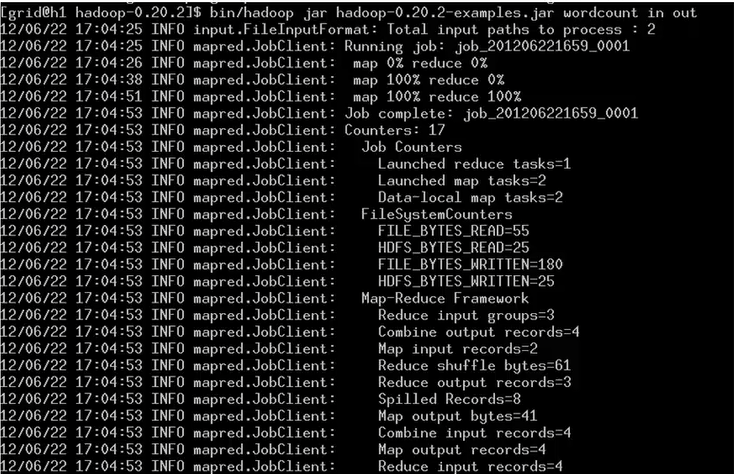
3. 检查程序运行结果
查看结果文件是在part-文件中,为了节省输入,这里输入cat ./out/目录中的内容是显示不出来的。

通过Web了解Hadoop的活动
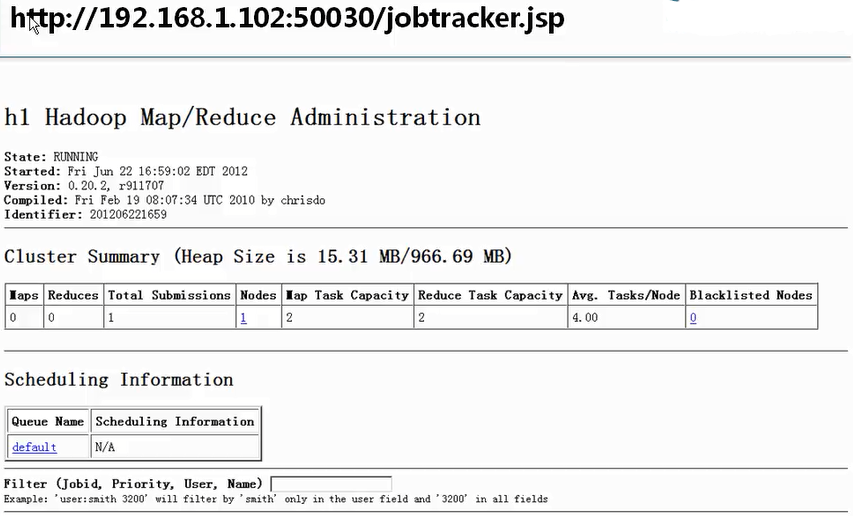
1. 通过http访问jobtracker所在节点的50030端口监控jobtracker,通过端口50070监控namenode节点的运行状况。
向DFS文件系统中写,写哪去了(从OS角度)

HDFS设计基础与目标
1. 硬件的错误是常态的,因此需要冗余。
2. 流式数据访问,即数据批量读取而非随机读取,Hadoop擅长做的是数据分析而不是事务处理。
3. 大规模数据集,采用简单一致模型。为了 降低系统的复杂度,对文件采用一次新写多次读的逻辑设计,即是文件一经写入,关闭就再也不能修改。
4. 程序采用”数据就近”原则分配节点执行。
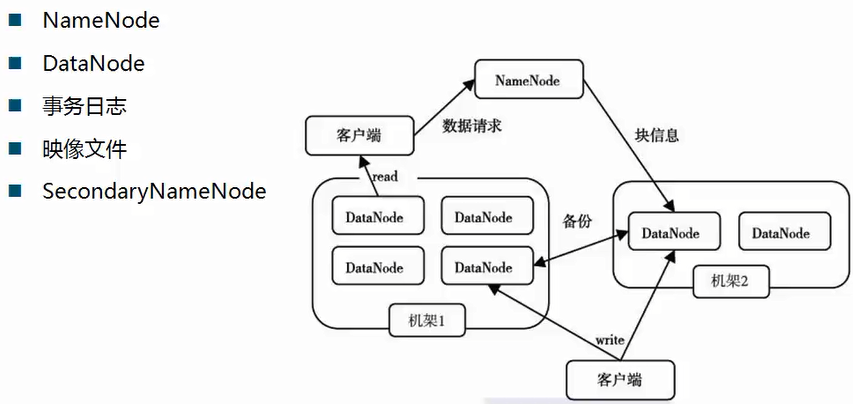
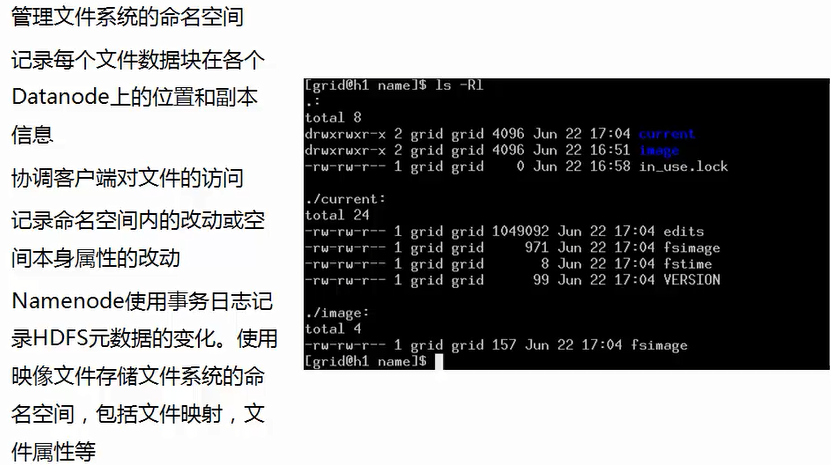
1. Namenode名称节点
2. Datanode
数据一次写入后就不允许修改。因此不需要考虑一致性。

3. 读取数据流程

HDFS的可靠性
冗余副本策略、机架策略、心跳机制、安全模式、检验和、回收站、元数据保护、快照机制。
1. 冗余副本策略
与空间的利用率和读取速度成反比,需要进行权衡。

然后namenode会根据其记录的元数据与datanode提供的blockreport进行对比然后才去相应的措施
2. 机架策略

3. 心跳机制

4. 安全模式

5. 回收站

6. 元数据保护

7. 快照机制

HDFS文件操作
操作方式主要有两种,命令方式和API方式。
hadoop没有当前目录的概念,也没有cd命令。
hadoop dfs -ls聊出当前目录中的内容。
hadoop dfs -put ../abc abc将当期系统的文件放入到dfs的root目录下的abc目录中。 上传文件到HDFS
删除HDFS下的文档hadoop dfs -rmr abc
查看文件内容hadoop dfs -cat abc/*
查看HDFS基本统计信息hadoop dfsadmin -report
进入和退出安全模式hadoop dfsadmin -safemode enter|leave
如何添加节点?
注意:不同的版本的hadoop其命令可能不同。
要想让数据在各个节点的存储效率差不多,可以使用start-balance.sh文件来重新散布文件数据。
















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









