









目录
一、背景
二、tomcat线程池监控
三、tomcat线程池原理
四、总结
一、背景
我们都知道稳定性、高可用对于一个系统来讲是非常重要的,而为了保证系统的稳定性,我们一般都会进行各方面的监控,以便系统有任何异常情况时,开发人员能够及时的感知到,这些监控比如缓存服务redis的监控,数据库服务mysql的监控,系统流量监控,系统jvm监控等等,除了这些监控,还有一种监控也是很有必要的,那就是线程池的监控。
说起线程池的监控可能我们一般想到的是我们自定义的线程池或者接入的中间件比如hystrix的线程池监控,但是其实还有一个线程池其实一直伴随着我们的开发生涯,日日用而不知,那就是SpringBoot内嵌Tomcat的线程池。
今天,这篇文章就来介绍SpringBoot内嵌Tomcat线程池监控及Tomcat的线程池原理分析。
二、tomcat线程池监控
既然我们要监控Tomcat的线程池,那么很自然的思路就是我们怎么获取到Tomcat的线程池对象,如果我们能够获取到Tomcat的线程池对象,那么,线程池的各项指标信息我们就能获取了。
如果我们想看Tomcat使用的线程池,那么正常的做法就是看源码了,跟随SpringApplication.run(AppApplication.class, args)启动方法一路进行源码跟踪。
在这里我就不一一跟踪源码进行讲解了,感兴趣的同学可以自己动手调试下,这里我分享一个Tomcat的架构图,这对于跟踪 Tomcat的源码非常有帮助。

Tomcat的源码也都是基于架构一部分一部分进行实现的。
在这里我就直接给出答案了:
①、Tomcat线程池的创建是在AbstractEndpoint这个抽象类中执行的。
也就是下面这段源码:
AbstractEndpoint#createExecutor()
public void createExecutor() {
internalExecutor = true;
TaskQueue taskqueue = new TaskQueue();
TaskThreadFactory tf = new TaskThreadFactory(getName() + "-exec-", daemon, getThreadPriority());
#创建tomcat内置线程池
executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), 60, TimeUnit.SECONDS,taskqueue, tf);
taskqueue.setParent( (ThreadPoolExecutor) executor);
}②、Tomcat的Servlet容器实现了WebServerApplicationContext或者ApplicationContext这个接口,所以我们注入WebServerApplicationContext或者直接注入ApplicationContext就能获取到Tomcat线程池对象。
如下所示:
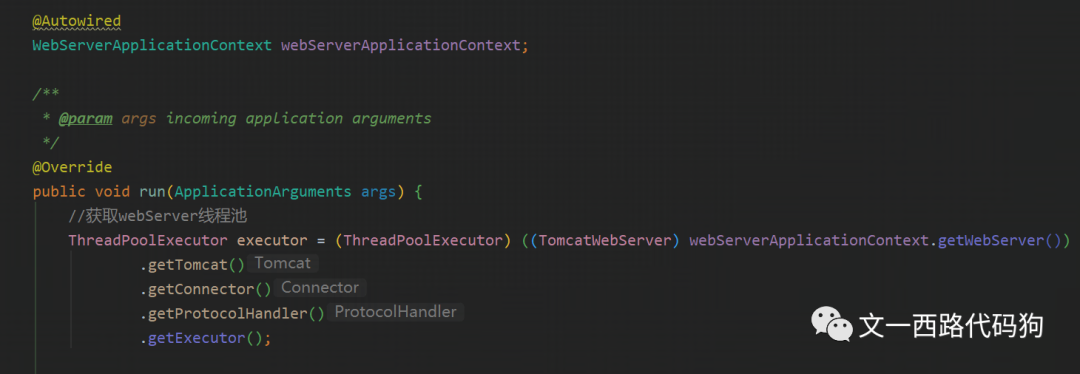
代码如下:
//获取webServer线程池
ThreadPoolExecutor executor = (ThreadPoolExecutor) ((TomcatWebServer) webServerApplicationContext.getWebServer())
.getTomcat()
.getConnector()
.getProtocolHandler()
.getExecutor();好了,到这里我们就获取到Tomcat线程池对象了,有了线程池对象我们就可以对其进行监控,定时获取其监控指标,以便在服务异常时能告警通知。
这里我再简单介绍下获取到的Tomcat线程池对象ThreadPoolExecutor executor的一些指标意义。
其各项监控指标如下:
//获取webServer线程池
ThreadPoolExecutor executor = (ThreadPoolExecutor) ((TomcatWebServer) webServerApplicationContext.getWebServer())
.getTomcat()
.getConnector()
.getProtocolHandler()
.getExecutor();
Map<String, String> returnMap = new LinkedHashMap<>();
returnMap.put("核心线程数", String.valueOf(executor.getCorePoolSize()));
returnMap.put("最大线程数", String.valueOf(executor.getMaximumPoolSize()));
returnMap.put("活跃线程数", String.valueOf(executor.getActiveCount()));
returnMap.put("池中当前线程数", String.valueOf(executor.getPoolSize()));
returnMap.put("历史最大线程数", String.valueOf(executor.getLargestPoolSize()));
returnMap.put("线程允许空闲时间/s", String.valueOf(executor.getKeepAliveTime(TimeUnit.SECONDS)));
returnMap.put("核心线程数是否允许被回收", String.valueOf(executor.allowsCoreThreadTimeOut()));
returnMap.put("提交任务总数", String.valueOf(executor.getSubmittedCount()));
returnMap.put("历史执行任务的总数(近似值)", String.valueOf(executor.getTaskCount()));
returnMap.put("历史完成任务的总数(近似值)", String.valueOf(executor.getCompletedTaskCount()));
returnMap.put("工作队列任务数量", String.valueOf(executor.getQueue().size()));
returnMap.put("拒绝策略", executor.getRejectedExecutionHandler().getClass().getSimpleName());三、tomcat线程池原理
在上面介绍了获取到的Tomcat线程池对象ThreadPoolExecutor executor,我们一看这个线程池类,竟然是ThreadPoolExecutor ,难道就是JUC并发包中的ThreadPoolExecutor ?聪明的我赶紧看看Tomcat的源码,非也非也,原来这个ThreadPoolExecutor 是Tomcat扩展了java.util.concurrent.ThreadPoolExecutor,Tomcat根据自己独特的业务场景定制实现的一个线程池。
如下图
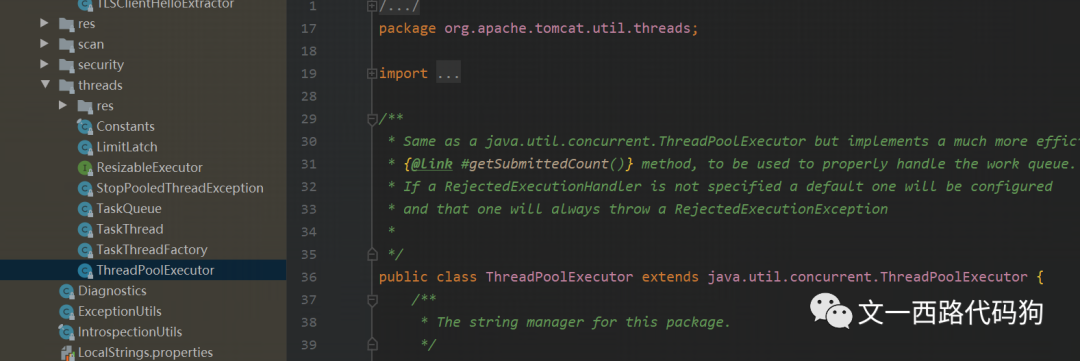
其实如果看下这个org.apache.tomcat.util.threads包里面的ThreadPoolExecutor的实现的话,我们会惊奇的发现,这个org.apache.tomcat.util.threads包里面的ThreadPoolExecutor和java.util.concurrent.ThreadPoolExecutor的实现大致都是相同的,在这里,我就详细介绍下两个ThreadPoolExecutor在执行具体的任务时是怎么实现的,有什么区别。
在这里先列出两个ThreadPoolExecutor的执行逻辑
org.apache.tomcat.util.threads包里面的ThreadPoolExecutor
public void execute(Runnable command, long timeout, TimeUnit unit) {
submittedCount.incrementAndGet();
try {
executeInternal(command);
} catch (RejectedExecutionException rx) {
if (getQueue() instanceof TaskQueue) {
// If the Executor is close to maximum pool size, concurrent
// calls to execute() may result (due to Tomcat's use of
// TaskQueue) in some tasks being rejected rather than queued.
// If this happens, add them to the queue.
final TaskQueue queue = (TaskQueue) getQueue();
try {
if (!queue.force(command, timeout, unit)) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException(sm.getString("threadPoolExecutor.queueFull"));
}
} catch (InterruptedException x) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} else {
submittedCount.decrementAndGet();
throw rx;
}
}
}
private void executeInternal(Runnable command) {
if (command == null) {
throw new NullPointerException();
}
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) {
return;
}
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) {
reject(command);
} else if (workerCountOf(recheck) == 0) {
addWorker(null, false);
}
}
else if (!addWorker(command, false)) {
reject(command);
}
}java.util.concurrent.ThreadPoolExecutor
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}相较于JDK 自带的ThreadPoolExecutor,上面多了 submittedCount.incrementAndGet() 和 catch 异常之后的那部分代码。
submittedCount,是一个 AtomicInteger ,意义是已提交但尚未完成的任务数,这包括队列中的任务和已交给工作线程但尚未执行完成的任务。catch 中的代码很好理解,作用是让被拒绝的请求再次加入到队列中,尽力处理任务。
然后再来看 executeInternal 方法,其实你会发现executeInternal 方法的执行逻辑和java.util.concurrent.ThreadPoolExecutor的execute()执行逻辑竟然完全相同,这令我们很迷惑,难道直接就是复用的java.util.concurrent.ThreadPoolExecutor的执行逻辑,假如说直接就是复用的java.util.concurrent.ThreadPoolExecutor的执行逻辑,那么直接super.execute()不就完了,还有必要重写一遍代码吗?
这个时候我们就要回到之前创建Tomcat的线程池的现场,看看创建线程池的时候和JUC里面到底有哪些不一样,因为看代码他们execute()执行逻辑完全一样,那肯定是具体执行的时候有些实现不一样。否则,Tomcat的开发者是绝对不会笨到重写一遍java.util.concurrent.ThreadPoolExecutor的执行逻辑的。
重新来到Tomcat创建线程池的时机,也即是下面这段代码。
AbstractEndpoint#createExecutor()
public void createExecutor() {
internalExecutor = true;
TaskQueue taskqueue = new TaskQueue();
TaskThreadFactory tf = new TaskThreadFactory(getName() + "-exec-", daemon, getThreadPriority());
#创建tomcat内置线程池
executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), 60, TimeUnit.SECONDS,taskqueue, tf);
taskqueue.setParent( (ThreadPoolExecutor) executor);
}我们看ThreadPoolExecutor构造方法的参数,核心线程数、最大线程数这些没有太大意义就不用看了,重点关注taskqueue这个参数。
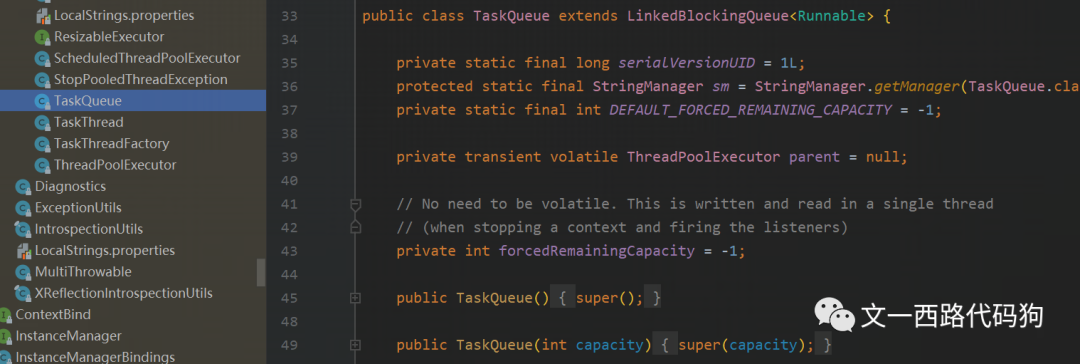
taskqueue是Tomcat根据自身的独特业务场景逻辑实现了阻塞队列LinkedBlockingQueue<Runnable>,然后我们结合之前Tomcat的execute()逻辑,看在execute()里面,taskqueue是怎么执行的。
也即是下面这段代码
@Override
public boolean offer(Runnable o) {
//we can't do any checks
if (parent==null) {
return super.offer(o);
}
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) {
return super.offer(o);
}
//we have idle threads, just add it to the queue
if (parent.getSubmittedCount()<=(parent.getPoolSize())) {
return super.offer(o);
}
//if we have less threads than maximum force creation of a new thread
if (parent.getPoolSize()<parent.getMaximumPoolSize()) {
return false;
}
//if we reached here, we need to add it to the queue
return super.offer(o);
}首先如果parent 为 null,直接入队,实际上这个 parent 就是ThreadPoolExecutor,在刚才Tomcat创建线程池的地方有这个代码。

然后,parent.getPoolSize() 的作用是返回当前线程池中的线程数,如果等于最大线程数,则直接入队,等待后续执行这个任务。
然后parent.getSubmittedCount()标识提交的任务数量,如果小于等于线程数量,标识有空闲的线程在等待任务,所以这个时候也是直接入队,让空闲线程立即去执行任务,
再然后,parent.getPoolSize()<parent.getMaximumPoolSize()表示线程池中的线程数量如果小于限制的最大线程数量,那么这个时候就强制开启新线程,去执行任务。这个时候就是返回false,我们看Tomcat的ThreadPoolExecutor的execute()在taskqueue.offer()方法,返回false了,就去执行addWorker()开启新线程了。
最后,执行到最后,默认就直接入队了。
好了,这就是Tomcat的线程池执行所有逻辑了,这个时候我们再反过来去看java.util.concurrent.ThreadPoolExecutor的execute()方法,虽然他的执行逻辑和Tomcat的org.apache.tomcat.util.threads包里面的ThreadPoolExecutor的execute()方法执行逻辑表面完全相同,但是他在执行taskqueue.offer()的时候,其实是直接执行的LinkedBlockingQueue或者其他阻塞队列的逻辑,直接入队了,这就是Tomcat的线程池和JUC线程池最大的一点不同。
四、总结
①、Tomcat线程池的创建是在AbstractEndpoint这个抽象类中执行的。
②、注入WebServerApplicationContext或者直接注入ApplicationContext就能获取到Tomcat线程池对象。
③、当有新任务时,Tomcat的线程池核心线程如果已经创建完了,Tomcat会尽最大努力开启新的非核心线程去执行新任务,而JUC的ThreadPoolExecutor则是入队,等待队列满了再创建新的非核心线程去执行任务。
以上是个人的亲身经历及总结经验,个人之见,难免考虑不全,如果大家有更好的建议欢迎大家私信留言。
如果觉得对你有一点点帮助,希望能够动动小手,你的点赞是对我最大的鼓励支持。
更多分享请移步至个人公众号,谢谢支持😜😜......

公众号:wenyixicodedog














 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









