







IDEA Eclipse
下载Scala
下载地址
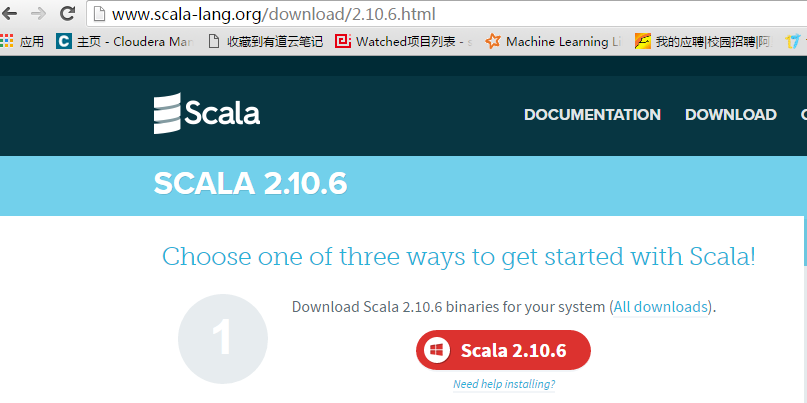
scala.msi
scala环境变量配置
(1)设置SCALA-HOME变量:如图,单击新建,在变量名一栏输入: SCALA-HOME 变量值一栏输入: D:\Program Files\scala 也就是scala的安装目录,根据个人情况有所不同,如果安装在E盘,将“D”改成“E”即可。
(2)设置path变量:找到系统变量下的“path”如图,单击编辑。在“变量值”一栏的最前面添加如下的 code: %scala_Home%\bin;%scala_Home%\jre\bin; 注意:后面的分号 ; 不要漏掉。
(3)设置classpath变量:找到找到系统变量下的“classpath”如图,单击编辑,如没有,则单击“新建”,
“变量名”:ClassPath “变量值“:
.;%scala_Home%\bin;%scala_Home%\lib\dt.jar;%scala_Home%\lib\tools.jar.; 注意:“变量值”最前面的 .; 不要漏掉。最后单击确定即可。
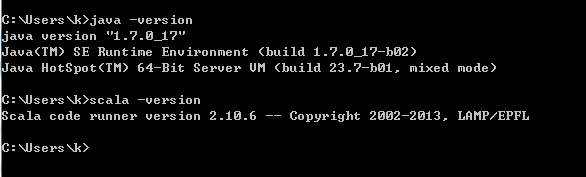
下载scala ide,scal-SDK-4.4.1-vfinal-2.11-win32.win32.x86.64.zip
下载地址
下载后解压,点击Eclipse,运行
第一步:修改依赖的Scala版本为Scala 2.10.x(默认2.11.7,要做修改)

第二步:加入Spark 1.6.0的jar文件依赖
下载spark对应的jar包,点击4,下载spark-1.6.1-bin-hadoop2.6.tgz
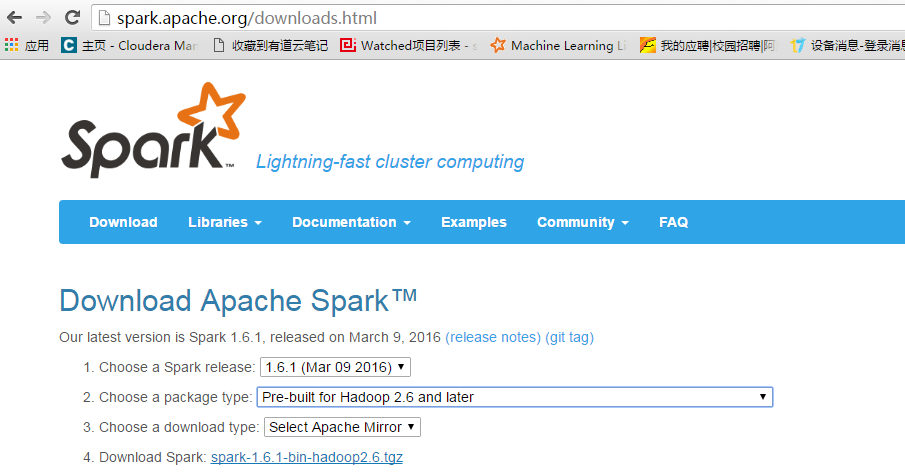
下载地址

下载Spark,在lib中找到依赖文件
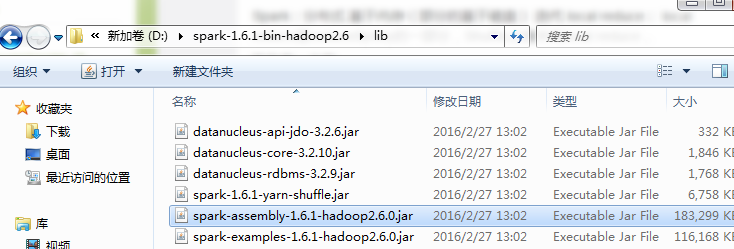
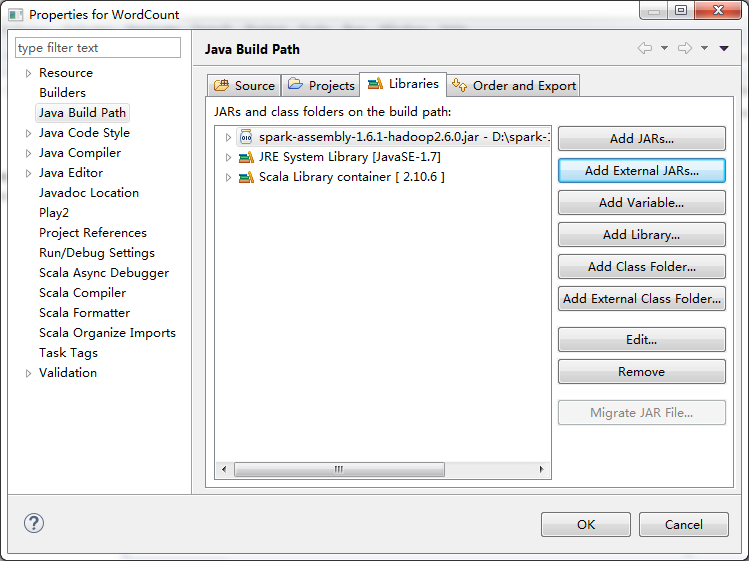
第三步:找到依赖的Spark Jar文件并导入到Eclipse中的Jar依赖
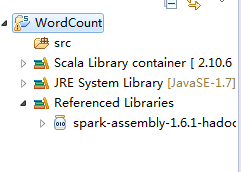
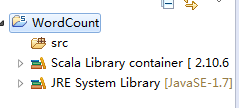
第四步:在src下建立Spark工程包
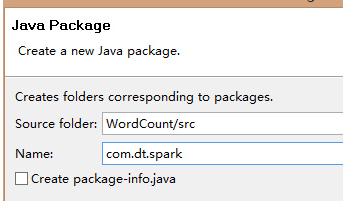
第五步:创建Scala入口类
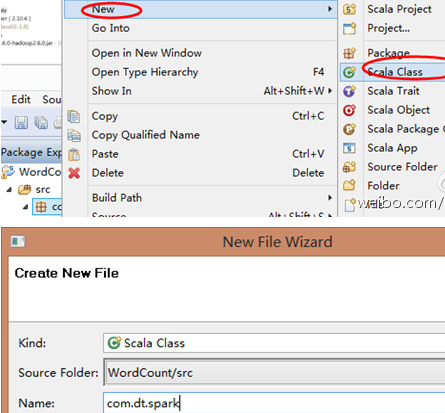
第六步:把class变成object并编写main入口方法

开发程序有两种模式:本地运行和集群运行
修改字体
本地模式
package com.test
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object WordCount {
def main(args: Array[String]){
/**
* 第一步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要连接的Spark集群的Master的URL,
* 如果设置为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差
* (例如只有1G的内存)的初学者
*/
val conf =new SparkConf()//创建SparkConf对象,由于全局只有一个SparkConf所以不需要工厂方法
conf.setAppName("wow,my first spark app")//设置应用程序的名称,在程序的监控界面可以看得到名称
conf.setMaster("local")//此时程序在本地运行,不需要安装Spark集群
/**
* 第二步:创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须要有一个
* SparkContext
* SparkContext核心作用:初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler,TaskScheduler,SchedulerBacked,
* 同时还会负责Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
val sc=new SparkContext(conf)//创建SpackContext对象,通过传入SparkConf实例来定制Spark运行的具体参数的配置信息
/**
* 第三步:根据具体的数据来源(HDFS,HBase,Local,FileSystem,DB,S3)通过SparkContext来创建RDD
* RDD的创建基本有三种方式,(1)根据外部的数据来源(例如HDFS)(2)根据Scala集合(3)由其它的RDD操作
* 数据会被RDD划分为成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*/
//读取本地文件并设置为一个Partition
val lines=sc.textFile("D://spark-1.6.1-bin-hadoop2.6//README.md", 1)//第一个参数为为本地文件路径,第二个参数minPartitions为最小并行度,这里设为1
//类型推断 ,也可以写下面方式
// val lines : RDD[String] =sc.textFile("D://spark-1.6.1-bin-hadoop2.6//README.md", 1)
/**
* 第四步:对初始的RDD进行Transformation级别的处理,例如map,filter等高阶函数
* 编程。来进行具体的数据计算
* 第4.1步:将每一行的字符串拆分成单个的单词
*/
//对每一行的字符串进行单词拆分并把所有行的结果通过flat合并成一个大的集合
val words = lines.flatMap { line => line.split(" ") }
/**
* 第4.2步在单词拆分的基础上,对每个单词实例计数为1,也就是word=>(word,1)tuple
*/
val pairs = words.map { word => (word,1) }
/**
* 第4.3步在每个单词实例计数为1的基础之上统计每个单词在文中出现的总次数
*/
//对相同的key进行value的累加(包括local和Reduce级别的同时Reduce)
val wordCounts = pairs.reduceByKey(_+_)
//打印结果
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + ":" +wordNumberPair._2))
//释放资源
sc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
run as ->Scala Application
运行结果
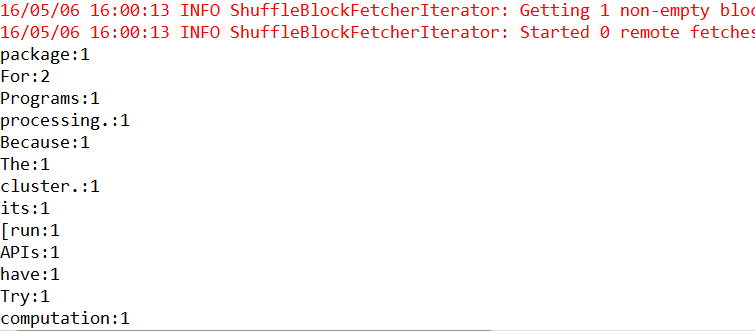
集群模式
package com.test
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object WordCountCluster {
def main(args: Array[String]){
/**
* 第一步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要连接的Spark集群的Master的URL,
* 如果设置为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差
* (例如只有1G的内存)的初学者
*/
val conf =new SparkConf()//创建SparkConf对象,由于全局只有一个SparkConf所以不需要工厂方法
conf.setAppName("wow,my first spark app")//设置应用程序的名称,在程序的监控界面可以看得到名称
// conf.setMaster("spark://Master:7077")//此时程序在Spark集群
/**
* 第二步:创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须要有一个
* SparkContext
* SparkContext核心作用:初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler,TaskScheduler,SchedulerBacked,
* 同时还会负责Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
val sc=new SparkContext(conf)//创建SpackContext对象,通过传入SparkConf实例来定制Spark运行的具体参数的配置信息
/**
* 第三步:根据具体的数据来源(HDFS,HBase,Local,FileSystem,DB,S3)通过SparkContext来创建RDD
* RDD的创建基本有三种方式,(1)根据外部的数据来源(例如HDFS)(2)根据Scala集合(3)由其它的RDD操作
* 数据会被RDD划分为成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*/
//读取HDFS文件并切分成不同的Partition
val lines=sc.textFile("hdfs://node1:8020/tmp/harryport.txt")
//val lines=sc.textFile("/index.html")
//类型推断 ,也可以写下面方式
// val lines : RDD[String] =sc.textFile("D://spark-1.6.1-bin-hadoop2.6//README.md", 1)
/**
* 第四步:对初始的RDD进行Transformation级别的处理,例如map,filter等高阶函数
* 编程。来进行具体的数据计算
* 第4.1步:将每一行的字符串拆分成单个的单词
*/
//对每一行的字符串进行单词拆分并把所有行的结果通过flat合并成一个大的集合
val words = lines.flatMap { line => line.split(" ") }
/**
* 第4.2步在单词拆分的基础上,对每个单词实例计数为1,也就是word=>(word,1)tuple
*/
val pairs = words.map { word => (word,1) }
/**
* 第4.3步在每个单词实例计数为1的基础之上统计每个单词在文中出现的总次数
*/
//对相同的key进行value的累加(包括local和Reduce级别的同时Reduce)
val wordCounts = pairs.reduceByKey(_+_)
//打印结果
wordCounts.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" +wordNumberPair._2))
//释放资源
sc.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
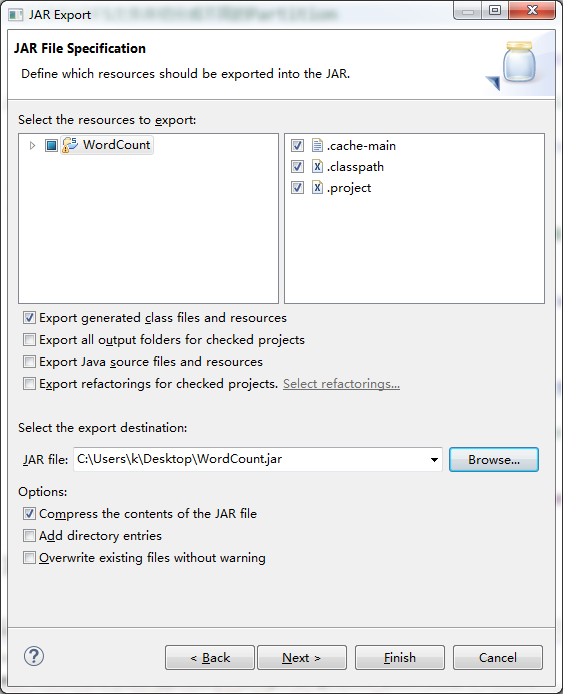
打包
右击,export,Java ,jar File
wordcoun.sh内容
./spark-submit --class com.test.WordCountCluster /root/WordCount.jar
- 1
- 1
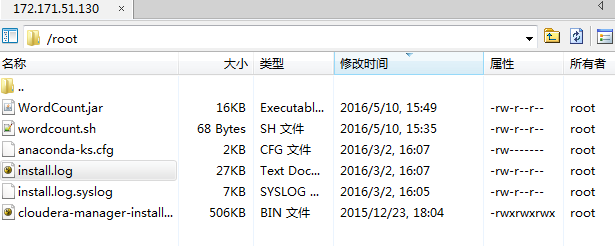
修改权限chmod 777 wordcount.sh
进入spark/bin目录下
cd /opt/cloudera/parcels/CDH-5.6.0-1.cdh5.6.0.p0.45/lib/spark/bin
- 1
- 1
执行脚本文件wordcount.sh
sh /root/wordcount.sh
- 1
- 1
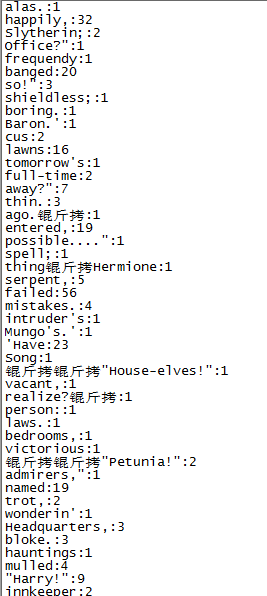
读取hdfs://node1:8020/tmp/harryport.txt目录下的单词并统计
运行结果如下:














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









