







1.结构体的参数传递
首先结构体做函数参数有三种传递方式
一是传递结构体变量,这是值传递,二是传递结构体指针,这是地址传递,三是传递结构体成员,当然这也分为值传递和地址传递。
以传引用调用方式传递结构比用传值方式传递结构效率高。以传值方式传递结构需要对整个结构做一份拷贝。
#include <stdio.h>
int main(){
int n = 1;
printf(“实参n的值:%d,地址:%#x\n”, n, &n);
void change(int i);//函数声明
change(n);
printf(“函数调用后实参n的值:%d,地址:%#x\n”, n, &n);
return 0;
}
void change(int i){
printf(“形参i的值:%d,地址:%#x\n”,i,&i);
i++;
printf(“自增操作后形参i的值:%d,地址:%#x\n”,i,&i);
}
编译后执行结果如下:
实参n的值:1,地址:0x5fcb0c
形参i的值:1,地址:0x5fcae0
自增操作后形参i的值:2,地址:0x5fcae0
函数调用后实参n的值:1,地址:0x5fcb0c
可以看到,在调用函数 change 时,会在内存中单独开辟一个空间用于存放形式参数 i ,实参 n 的值会复制给形参 i 。对于形参的任何操作都不会影响到主调函数中的实参 n 。这种参数传递方式是便是典型的值传递。
上例中的参数类型是int型,实际上,对于整形(int、short、long、long long)、浮点型(float、double、long double)、字符型(char)等基本类型的参数都是值传递。
2.文件的包含
在编译时包含其他源文件、定义宏,根据条件决定编译时是否包含某些代码。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序.但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行相应的转换。预处理过程还会删除程序中的注释和多余的空白字符。
预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#号后是指令关键字.在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,陔指令将在编译器进行编译之前对源代码做某些转换。
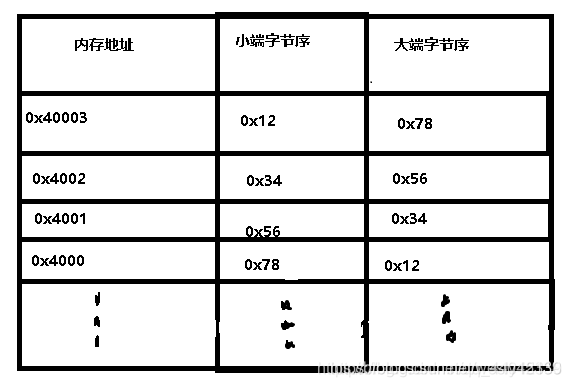
3.大小端和字节序
字节序,简单来说,就是指的超过一个字节的数据类型在内存中存储的顺序,那么就很明显了,像char这样的类型,肯定不存在字节序的问题了。
例如:0x12345678,其中0x12为高地址位,0x78为低地址位。
字节序分为哪几类
1.大端字节序:
高位字节数据存放在低地址处,低位数据存放在高地址处;
2.小段字节序:
高位字节数据存放在高地址处,低位数据存放在低地址处;
如图
大小字节序的判断:
方法 一:
#include <stdio.h>
15
16 int main (int argc, char **argv)
17 {
18 unsigned int a = 0x12345678;
19 unsigned char *c = (unsigned char *)&a;
20
21 if(*c == 0x78)
22 printf(“Little endian\n”);
23 else if(*c == 0x12)
24 printf(“Big endian\n”);
25 else
26 printf(“Not know”);
27 return 0;
28 }
方法二:
14 #include <stdio.h>
15 union u_is_lsb
16 {
17 unsigned int a;
18 unsigned char b;
19 }is_lsb;
20 int main (int argc, char **argv)
21 {
22 is_lsb.a = 0x12345678;
23 if(is_lsb.b == 0x78)
24 printf(“Little endian!\n”);
25 else if(is_lsb.b == 0x12)
26 printf(“Big endian!\n”);
27 else
28 printf(“Not know!”);
29 return 0;
30 }
4.位域
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可。例如开关只有通电和断电两种状态,用0和1表示足以,也就是用一个二进位。正是基于这种考虑,C语言又提供了一种数据结构,叫做“位域”或“位段”。
位域是操控位的一种方法(操控位的另一种方法是使用按位运算符,按位运算符将在之后的笔记中做介绍)。
位域通过一个结构声明来建立:该结构声明为每个字段提供标签,并确定该字段的宽度。例如,下面的声明建立了个4个1位的字段:
struct
{
unsigned int autfd:1;
unsigned int bldfc:1;
unsigned int undin:1;
unsigned int itals:1;
}prnt;
根据该声明, prnt包含4个1位的字段。现在,可以通过普通的结构成员运算符(.)单独给这些字段赋值:
prnt.itals = 0:
prnt.undin = 1;
由于每个字段恰好为1位,所以只能为其赋值1或0。变量prnt被储存在int大小的内存单元中,但是在本例中只使用了其中的4位。
:后面的数字用来限定成员变量占用的位数。位域的宽度不能超过它所依附的数据类型的长度。通俗地讲,成员变量都是有类型的,这个类型限制了成员变量的最大长度,:后面的数字不能超过这个长度。
如上述结构中autfd、bldfc、undin、itals后面的数字不能超过unsigned int的位数,即在32bit环境中就是不能超过32。
位域的取值范围非常有限,数据稍微大些就会发生溢出,请看下面的例子:
#include <stdio.h>
struct pack
{
unsigned a:2; // 取值范围为:0~3
unsigned b:4; // 取值范围为:0~15
unsigned c:6; // 取值范围为:0~63
};
int main(void)
{
struct pack pk1;
struct pack pk2;
// 给pk1各成员赋值并打印输出
pk1.a = 1;
pk1.b = 10;
pk1.c = 50;
printf("%d, %d, %d\n", pk1.a, pk1.b, pk1.c);
// 给pk2各成员赋值并打印输出
pk2.a = 5;
pk2.b = 20;
pk2.c = 66;
printf("%d, %d, %d\n", pk2.a, pk2.b, pk2.c);
return 0;
}
程序输出结果为:
pk1.a = 1, pk1.a = 10, pk1.c = 5
pk2.a = 1, pk2.b = 4, pk2.c = 2
显然,结构体变量pk1的各成员都没有超出限定的位数,能够正常输出。而结构体变量pk2的各成员超出了限定的位数,并发生了上溢(溢出中的一种)
C语言标准规定,只有有限的几种数据类型可以用于位域。在ANSI C 中,这几种数据类型是signed int和unsigned int;到了C99、C11新增了_Bool 的位字段。
5.函数指针
函数名为函数的入口地址,定义一个指针指向这个函数入口地址即函数指针。
函数为: int func1(int a, int *b)
那定义的函数指针: int (*p)(int ,int *)定义时只需说明参数类型即可。
然后再将函数名字赋值给函数指针,通过函数指针调用函数即 p(a , b)
有时为了方便书写:
我们在main函数前,给我们的函数指针用typedef 定义一下,在使用该函数指针类型,便可直接声明并调用函数。相当于给一个int返回类型的两个参数的指针函数取了个名字叫T。
定义: typedef int(*T)( int , int *); // 起外号
调用时:T p2(声明);p2 = func1(赋值);p2(传参) ;即可调用
程序如下:
#include <stdio.h>
typedef void(*T)(int); //T为函数指针类型
typedef unsigned char uchar;
void func1()
{
printf(“func1 \n”);
}
void func2(int b)
{
printf(“func2 %d \n”,b);
}
int main()
{
void (*p1)();
p1 = func1;
p1();
int a= 100;
void (*p2)(int);
p2 = func2;
p2(a);
T p3;
p3 = func2;
p3(1000);
return 0;
}














 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









