







NameNode中几个关键的数据结构
FSImage
Namenode 会将 HDFS 的文件和目录元数据存储在一个叫 fsimage 的二进制文件中,每次保存 fsimage 之后到下次保存之间的所有 hdfs 操作,将会记录在 editlog 文件中,当 editlog 达到一定的大小( bytes ,由 fs.checkpoint.size 参数定义)或从上次保存过后一定时间段过后( sec ,由 fs.checkpoint.period 参数定义), namenode 会重新将内存中对整个 HDFS 的目录树和文件元数据刷到 fsimage 文件中。 Namenode 就是通过这种方式来保证 HDFS 中元数据信息的安全性。
Fsimage 是一个二进制文件,当中记录了 HDFS 中所有文件和目录的元数据信息,在我的 hadoop 的 HDFS 版中,该文件的中保存文件和目录的格式如下:

当 namenode 重启加载 fsimage 时,就是按照如下格式协议从文件流中加载元数据信息。从 fsimag 的存储格式可以看出, fsimage 保存有如下信息:
1. 首先是一个 image head ,其中包含:
a) imgVersion(int) :当前 image 的版本信息
b) namespaceID(int) :用来确保别的 HDFS instance 中的 datanode 不会误连上当前 NN 。
c) numFiles(long) :整个文件系统中包含有多少文件和目录
d) genStamp(long) :生成该 image 时的时间戳信息。
2. 接下来便是对每个文件或目录的源数据信息,如果是目录,则包含以下信息:
a) path(String) :该目录的路径,如 ”/user/build/build-index”
b) replications(short) :副本数(目录虽然没有副本,但这里记录的目录副本数也为 3 )
c) mtime(long) :该目录的修改时间的时间戳信息
d) atime(long) :该目录的访问时间的时间戳信息
e) blocksize(long) :目录的 blocksize 都为 0
f) numBlocks(int) :实际有多少个文件块,目录的该值都为 -1 ,表示该 item 为目录
g) nsQuota(long) : namespace Quota 值,若没加 Quota 限制则为 -1
h) dsQuota(long) : disk Quota 值,若没加限制则也为 -1
i) username(String) :该目录的所属用户名
j) group(String) :该目录的所属组
k) permission(short) :该目录的 permission 信息,如 644 等,有一个 short 来记录。
3. 若从 fsimage 中读到的 item 是一个文件,则还会额外包含如下信息:
a) blockid(long) :属于该文件的 block 的 blockid ,
b) numBytes(long) :该 block 的大小
c) genStamp(long) :该 block 的时间戳
当该文件对应的 numBlocks 数不为 1 ,而是大于 1 时,表示该文件对应有多个 block 信息,此时紧接在该 fsimage 之后的就会有多个 blockid , numBytes 和 genStamp 信息。
因此,在 namenode 启动时,就需要对 fsimage 按照如下格式进行顺序的加载,以将 fsimage 中记录的 HDFS 元数据信息加载到内存中。
BlockMap
从以上 fsimage 中加载如 namenode 内存中的信息中可以很明显的看出,在 fsimage 中,并没有记录每一个 block 对应到哪几个 datanodes 的对应表信息,而只是存储了所有的关于 namespace 的相关信息。而真正每个 block 对应到 datanodes 列表的信息在 hadoop 中并没有进行持久化存储,而是在所有 datanode 启动时,每个 datanode 对本地磁盘进行扫描,将本 datanode 上保存的 block 信息汇报给 namenode , namenode 在接收到每个 datanode 的块信息汇报后,将接收到的块信息,以及其所在的 datanode 信息等保存在内存中。 HDFS 就是通过这种块信息汇报的方式来完成 block -> datanodes list 的对应表构建。 Datanode 向 namenode 汇报块信息的过程叫做 blockReport ,而 namenode 将 block -> datanodes list 的对应表信息保存在一个叫 BlocksMap 的数据结构中。
BlocksMap 的内部数据结构如下:
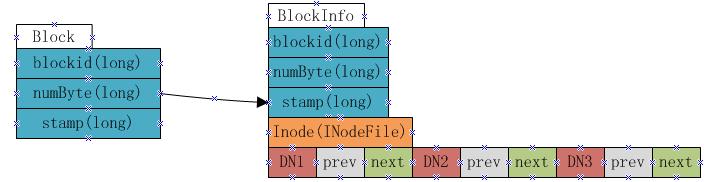
如上图显示, BlocksMap 实际上就是一个 Block 对象对 BlockInfo 对象的一个 Map 表,其中 Block 对象中只记录了 blockid , block 大小以及时间戳信息,这些信息在 fsimage 中都有记录。而 BlockInfo 是从 Block 对象继承而来,因此除了 Block 对象中保存的信息外,还包括代表该 block 所属的 HDFS 文件的 INodeFile 对象引用以及该 block 所属 datanodes 列表的信息(即上图中的 DN1 , DN2 , DN3 ,该数据结构会在下文详述)。
因此在 namenode 启动并加载 fsimage 完成之后,实际上 BlocksMap 中的 key ,也就是 Block 对象都已经加载到 BlocksMap 中,每个 key 对应的 value(BlockInfo) 中,除了表示其所属的 datanodes 列表的数组为空外,其他信息也都已经成功加载。所以可以说: fsimage 加载完毕后, BlocksMap 中仅缺少每个块对应到其所属的 datanodes list 的对应关系信息。所缺这些信息,就是通过上文提到的从各 datanode 接收 blockReport 来构建。当所有的 datanode 汇报给 namenode 的 blockReport 处理完毕后, BlocksMap 整个结构也就构建完成。
BlockMap中 datanode 列表数据结构
在 BlockInfo 中,将该 block 所属的 datanodes 列表保存在一个 Object[] 数组中,但该数组不仅仅保存了 datanodes 列表,还包含了额外的信息。实际上该数组保存了如下信息:

上图表示一个 block 包含有三个副本,分别放置在 DN1 , DN2 和 DN3 三个 datanode 上,每个 datanode 对应一个三元组,该三元组中的第二个元素,即上图中 prev block 所指的是该 block 在该 datanode 上的前一个 BlockInfo 引用。第三个元素,也就是上图中 next Block 所指的是该 block 在该 datanode 上的下一个 BlockInfo 引用。每个 block 有多少个副本,其对应的 BlockInfo 对象中就会有多少个这种三元组。
Namenode 采用这种结构来保存 block->datanode list 的目的在于节约 namenode 内存。由于 namenode 将 block->datanodes 的对应关系保存在了内存当中,随着 HDFS 中文件数的增加, block 数也会相应的增加, namenode 为了保存 block->datanodes 的信息已经耗费了相当多的内存,如果还像这种方式一样的保存 datanode->block list 的对应表,势必耗费更多的内存,而且在实际应用中,要查一个 datanode 上保存的 block list 的应用实际上非常的少,大部分情况下是要根据 block 来查 datanode 列表,所以 namenode 中通过上图的方式来保存 block->datanode list 的对应关系,当需要查询 datanode->block list 的对应关系时,只需要沿着该数据结构中 next Block 的指向关系,就能得出结果,而又无需保存 datanode->block list 在内存中。
NameNode启动过程
fsimage加载过程
Fsimage 加载过程完成的操作主要是为了:
1. 从 fsimage 中读取该 HDFS 中保存的每一个目录和每一个文件
2. 初始化每个目录和文件的元数据信息
3. 根据目录和文件的路径,构造出整个 namespace 在内存中的镜像
4. 如果是文件,则读取出该文件包含的所有 blockid ,并插入到 BlocksMap 中。
整个加载流程如下图所示:
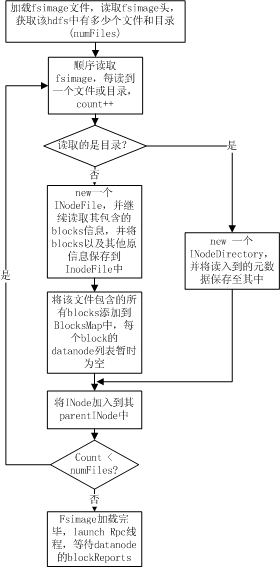
如上图所示, namenode 在加载 fsimage 过程其实非常简单,就是从 fsimage 中不停的顺序读取文件和目录的元数据信息,并在内存中构建整个 namespace ,同时将每个文件对应的 blockid 保存入 BlocksMap 中,此时 BlocksMap 中每个 block 对应的 datanodes 列表暂时为空。当 fsimage 加载完毕后,整个 HDFS 的目录结构在内存中就已经初始化完毕,所缺的就是每个文件对应的 block 对应的 datanode 列表信息。这些信息需要从 datanode 的 blockReport 中获取,所以加载 fsimage 完毕后, namenode 进程进入 rpc 等待状态,等待所有的 datanodes 发送 blockReports 。
blockReport阶段
每个 datanode 在启动时都会扫描其机器上对应保存 hdfs block 的目录下 (dfs.data.dir) 所保存的所有文件块,然后通过 namenode 的 rpc 调用将这些 block 信息以一个 long 数组的方式发送给 namenode , namenode 在接收到一个 datanode 的 blockReport rpc 调用后,从 rpc 中解析出 block 数组,并将这些接收到的 blocks 插入到 BlocksMap 表中,由于此时 BlocksMap 缺少的仅仅是每个 block 对应的 datanode 信息,而 namenoe 能从 report 中获知当前 report 上来的是哪个 datanode 的块信息,所以, blockReport 过程实际上就是 namenode 在接收到块信息汇报后,填充 BlocksMap 中每个 block 对应的 datanodes 列表的三元组信息的过程。其流程如下图所示:
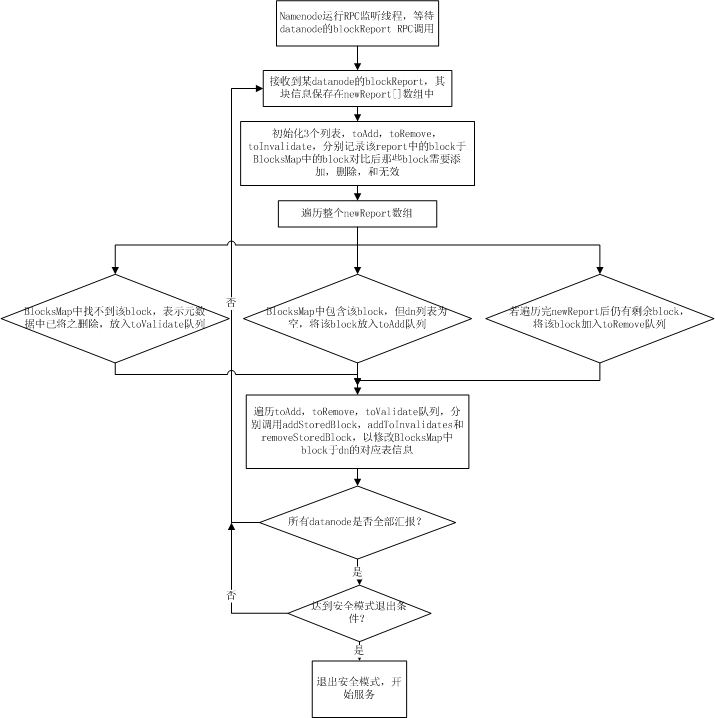
当所有的 datanode 汇报完 block , namenode 针对每个 datanode 的汇报进行过处理后, namenode 的启动过程到此结束。此时 BlocksMap 中 block->datanodes 的对应关系已经初始化完毕。如果此时已经达到安全模式的推出阈值,则 hdfs 主动退出安全模式,开始提供服务。
启动过程数据采集和瓶颈分析
对 namenode 的整个启动过程有了详细了解之后,就可以对其启动过程中各阶段各函数的调用耗时进行 profiling 的采集,数据的 profiling 仍然分为两个阶段,即 fsimage 加载阶段和 blockReport 阶段。
fsimage加载阶段性能数据采集和瓶颈分析
以下是对建库集群真实的 fsimage 加载过程的的性能采集数据:

从上图可以看出, fsimage 的加载过程那个中,主要耗时的操作分别分布在 FSDirectory.addToParent , FSImage.readString ,以及 PermissionStatus.read 三个操作,这三个操作分别占用了加载过程的 73% , 15% 以及 8% ,加起来总共消耗了整个加载过程的 96% 。而其中 FSImage.readString 和 PermissionStatus.read 操作都是从 fsimage 的文件流中读取数据(分别是读取 String 和 short )的操作,这种操作优化的空间不大,但是通过调整该文件流的 Buffer 大小来提高少许性能。而 FSDirectory.addToParent 的调用却占用了整个加载过程的 73% ,所以该调用中的优化空间比较大。
以下是 addToParent 调用中的 profiling 数据:

从以上数据可以看出 addToParent 调用占用的 73% 的耗时中,有 66% 都耗在了 INode.getPathComponents 调用上,而这 66% 分别有 36% 消耗在 INode.getPathNames 调用, 30% 消耗在 INode.getPathComponents 调用。这两个耗时操作的具体分布如以下数据所示:
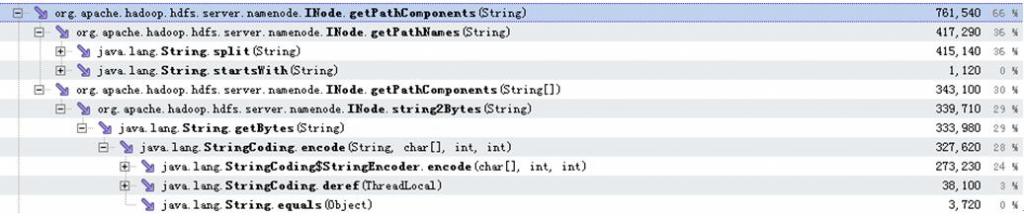
可以看出,消耗了 36% 的处理时间的 INode.getPathNames 操作,全部都是在通过 String.split 函数调用来对文件或目录路径进行切分。另外消耗了 30% 左右的处理时间在 INode.getPathComponents 中,该函数中最终耗时都耗在获取字符串的 byte 数组的 java 原生操作中。
blockReport阶段性能数据采集和瓶颈分析
由于 blockReport 的调用是通过 datanode 调用 namenode 的 rpc 调用,所以在 namenode 进入到等待 blockreport 阶段后,会分别开启 rpc 调用的监听线程和 rpc 调用的处理线程。其中 rpc 处理和 rpc 鉴定的调用耗时分布如下图所示:

而其中 rpc 的监听线程的优化是另外一个话题,在其他的issue中再详细讨论 ,且由于 blockReport 的操作实际上是触发的 rpc 处理线程,所以这里只关心 rpc 处理线程的性能数据。
在 namenode 处理 blockReport 过程中的调用耗时性能数据如下:

可以看出,在 namenode 启动阶段,处理从各个 datanode 汇报上来的 blockReport 耗费了整个 rpc 处理过程中的绝大部分时间 (48/49) , blockReport 处理逻辑中的耗时分布如下图:

从上图数据中可以发现, blockReport 阶段中耗时分布主要耗时在 FSNamesystem.addStoredBlock 调用以及 DatanodeDescriptor.reportDiff 过程中,分别耗时 37/48 和 10/48 ,其中 FSNamesystem.addStoredBlock 所进行的操作时对每一个汇报上来的 block ,将其于汇报上来的 datanode 的对应关系初始化到 namenode 内存中的 BlocksMap 表中。所以对于每一个 block 就会调用一次该方法。所以可以看到该方法在整个过程中调用了 774819 次,而另一个耗时的操作,即 DatanodeDescriptor.reportDiff ,该操作的过程在上文 中有详细介绍,主要是为了将该 datanode 汇报上来的 blocks 跟 namenode 内存中的 BlocksMap 中进行对比,以决定那个哪些是需要添加到 BlocksMap 中的 block ,哪些是需要添加到 toRemove 队列中的 block ,以及哪些是添加到 toValidate 队列中的 block 。由于这个操作需要针对每一个汇报上来的 block 去查询 BlocksMap ,以及 namenode 中的其他几个 map ,所以该过程也非常的耗时。而且从调用次数上可以看出, reportDiff 调用在启动过程中仅调用了 14 次 ( 有 14 个 datanode 进行块汇报 ) ,却耗费了 10/48 的时间。所以 reportDiff 也是整个 blockReport 过程中非常耗时的瓶颈所在。
同时可以看到,出了 reportDiff , addStoredBlock 的调用耗费了 37% 的时间,也就是耗费了整个 blockReport 时间的 37/48 ,该方法的调用目的是为了将从 datanode 汇报上来的每一个 block 插入到 BlocksMap 中的操作。从该方法调用的运行数据如下图所示:

从上图可以看出, addStoredBlock 中,主要耗时的两个阶段分别是 FSNamesystem.countNode 和 DatanodeDescriptor.addBlock ,后者是 java 中的插表操作,而 FSNamesystem.countNode 调用的目的是为了统计在 BlocksMap 中,每一个 block 对应的各副本中,有几个是 live 状态,几个是 decommission 状态,几个是 Corrupt 状态。而在 namenode 的启动初始化阶段,用来保存 corrput 状态和 decommission 状态的 block 的 map 都还是空状态,并且程序逻辑中要得到的仅仅是出于 live 状态的 block 数,所以,这里的 countNoes 调用在 namenode 启动初始化阶段并无需统计每个 block 对应的副本中的 corrrput 数和 decommission 数,而仅仅需要统计 live 状态的 block 副本数即可,这样 countNodes 能够在 namenode 启动阶段变得更轻量,以节省启动时间。
2.3 瓶颈分析总结
从 profiling 数据和瓶颈分歧情况来看, fsimage 加载阶段的瓶颈除了在分切路径的过程中不够优以外,其他耗时的地方几乎都是在 java 原生接口的调用中,如从字节流读数据,以及从 String 对象中获取 byte[] 数组的操作。
而 blockReport 阶段的耗时其实很大的原因是跟当前的 namenode 设计以及内存结构有关,比较明显的不优之处就是在 namenode 启动阶段的 countNode 和 reportDiff 的必要性,这两处在 namenode 初始化时的 blockReport 阶段有一些不必要的操作浪费了时间。可以针对 namenode 启动阶段将必要的操作抽取出来,定制成 namenode 启动阶段才调用的方式,以优化 namenode 启动性能。
本文转自:http://blog.csdn.net/AE86_FC/archive/2010/08/26/5842020.aspx















 3209
3209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









