









YOLACT:https://arxiv.org/abs/1904.02689
YOLACT++:https://arxiv.org/abs/1912.06218
DCN:https://arxiv.org/abs/1703.06211
YOLACT Code:https://github.com/dbolya/yolact/
DCN Code: https://github.com/msracver/Deformable-ConvNets
声明:本文是参考另外的两篇帖子进行整合得到,对其中叙述不当的地方进行修改,并增加了一些内容和提出了自己的看法。
近年来的实例分割可以分为两类:一类是two-stage的方法,即“先检测后分割”的方法,首先定位到目标物体的边框,然后在边框内分割目标物体,典型的代表是Mask R-CNN;另一类是one-stage的方法,这里面又细分为两个流派,一个是anchor-based,另一个是anchor-free,而本文的YOLACT是anchor-base方向的。(看题目YOLACT颇具致敬目标检测模型YOLO的意思。)
-
本文的主要贡献:
YOLACT是2019年发表在ICCV上面的一个实时实例分割的模型,它主要是通过两个并行的子网络来实现实例分割的。(1)Prediction Head分支生成各个anchor的类别置信度、位置回归参数以及mask的掩码系数;(2)Protonet分支生成一组原型mask。然后将原型mask和mask的掩码系数相乘,从而得到图片中每一个目标物体的mask。论文中还提出了一个新的NMS算法叫Fast-NMS,和传统的NMS算法相比只有轻微的精度损失,但是却大大提升了分割的速度。 -
YOLACT模型:
YOLACT是一个one-stage模型,它和two-stage的模型(Mask R-CNN)相比起来,速度更快,但是精度稍差一些。YOLACT模型的框架如图1所示。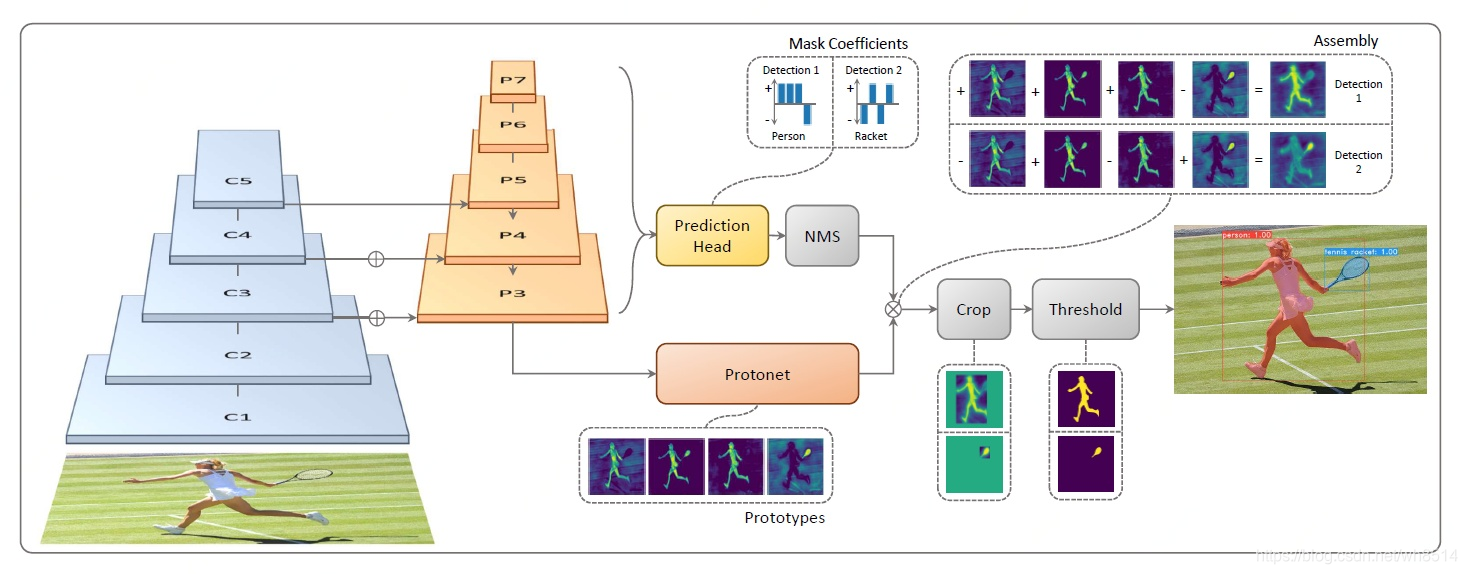
1)Backbone:
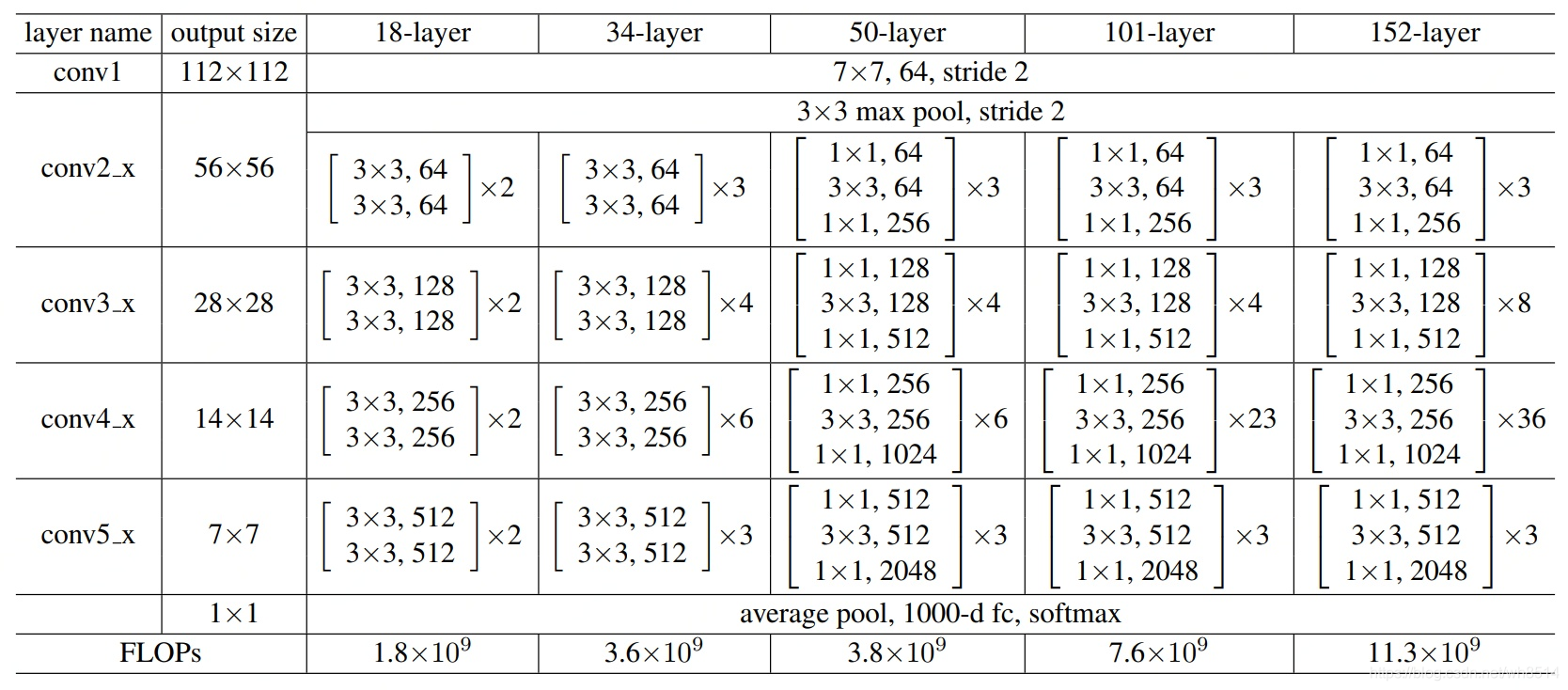
YOLACT模型输入的图像大小为550*550,采用的Backbone为ResNet101,源代码中作者还使用了ResNet50和DarkNet53,ResNet的网络结构如图2所示。从图中可以看出,ResNet的卷积模块一共有5个从conv1,conv2_x到conv5_x,分别对应图1 YOLACT模型中的C1,C2到C5。YOLACT和SSD一样采用了多尺度的特征图, 从而可以检测到不同尺寸的物体,也就是在大的特征图上检测小的物体,在小的特征图上检测大的物体。
2)FPN:
图1中的P3-P7是FPN网络,它是由C5经过1个卷积层得到P5,然后对P5采用双线性插值使特征图扩大一倍,与经过卷积的C4相加得到P4,再采用同样的方法即可得到P3。再然后,对P5进行卷积和下采样得到P6,对P6进行同样的卷积和下采样得到P7,从而建立FPN网络。接下来是并行的操作。P3 被送入 Protonet,P3-P7 也被同时送到 Prediction Head 中。(采用FPN的好处就是模型学习到特征更丰富,更有利于分割不同大小的目标物体。)3)Protonet 分支:
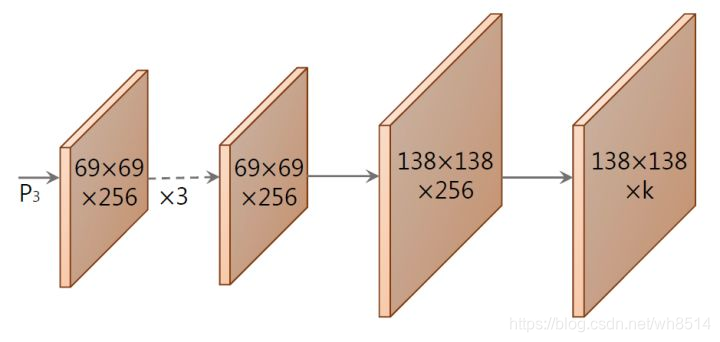
Protonet分支的网络结构如下图3所示,它是由由若干卷积层组成。其输入是 P3,其输出的mask维度是 138 * 138 * k (k=32),即 32 个 prototype mask,每个大小是 138 * 138。
4)Prediction Head分支:
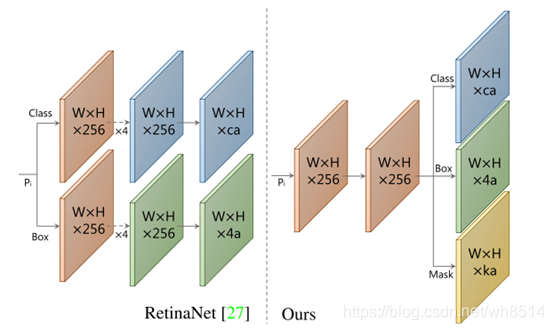
Prediction Head分支的网络结构如图4所示,它是在RetinaNet的基础上改进得到的,采用共享卷积网络,从而可以提高速度,达到实时分割的目的。它的输入是 P3-P7 共五个特征图,每个特征图先生成anchor,每个像素点生成3个anchor,比例是 1:1、1:2和2:1。五个特征图的anchor基本边长分别是24、48、96、192和384。基本边长根据不同比例进行调整,确保 anchor 的面积相等。
为了便于理解,接下来以 P3 为例进行解释说明。假设P3的维度是 W3 * H3 * 256,那么它的anchor个数就是 a3 = W3 * H3 * 3。接下来 Prediction Head 为其生成三类输出:
类别置信度,由于 COCO 中共有 81 类(包括背景),所以其维度为 a3 * 81;
位置偏移,维度为 a3 * 4;
mask 置信度,维度为 a3 * 32。
对 P4-P7 进行的操作是相同的,最后将这些结果拼接起来,标记 a = a3 + a4 + a5 + a6 + a7,得到:
全部类别置信度,由于 COCO 中共有 81 类(包括背景),所以其维度为 a * 81;
全部位置偏移,维度为 a * 4;
全部 mask 置信度,维度为 a * 32。
5)Fast NMS:
通过Prediction Head分支网络后会得到很多anchor,可以在anchor的位置加上位置偏移得到RoI位置。由于RoI存在重叠,NMS 是常用的筛选算法,而本文提出了一种新的筛选算法叫Fast-NMS,在保证精度的前提下,减少了筛选的时间。
接下来,通过举例详细介绍Fast NMS算法。假设我们有5个RoI,对于 person这一类,按分类置信度由高到低排序得到b1、b2、b3、b4和 b5。接下来通过矩阵运算得到5个ROI相互之间的IoU,假设结果如下图5所示:
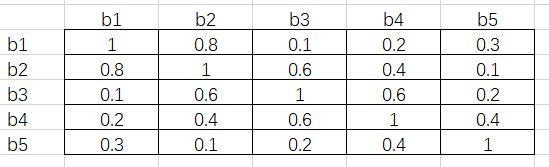
可以看出这是一个对称矩阵,接下来将这个对称阵的对角线和下三角元素删掉,得到结果如下图6所示:
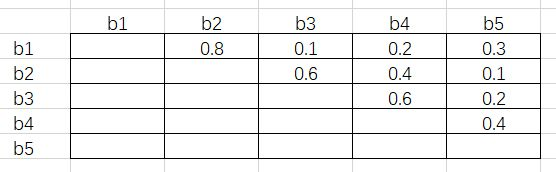
接下来对每一列取最大值,得到结果[-, 0.8, 0.6, 0.6, 0.4]。假设阈值为0.5,那么IoU超过0.5的RoI需要舍弃掉。根据刚才得到的结果,b2、b3和b4对应的列都超出了阈值,所以这三个RoI会舍去。这样做的原因是,由于每一个元素都是行号小于列号,而序号又是按分类置信度从高到低降序排列的,因此任一元素大于阈值,代表着这一列对应的 RoI 与一个比它置信度高的 RoI 过于重叠了,需要将它舍去。
6)Crop & Threshold
将通过Prediction Head分支得到的mask coefficient和Protonet分支得到的 prototype mask 做矩阵乘法,就可以得到图像中每一个目标物体的mask。Crop指的是将边界外的mask清零,训练阶段的边界是ground truth bounding box,评估阶段的边界是预测的bounding box。Threshold指的是以0.5为阈值对生成的 mask进行图像二值化处理。
7)Loss: YOLACT模型使用的loss是由边框的分类loss、边框的位置回归loss和mask的二分类交叉熵loss构成。
其中mask loss在计算时,因为mask的大小是138*138,需要先将原图的mask数据通过双线性插值缩小到这一尺寸。
8)实验结果:
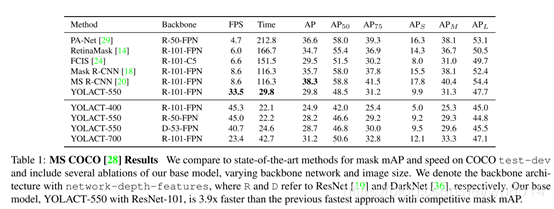
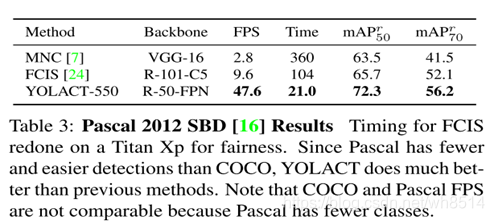
从图7和图8中,我们可以得到YOLACT虽然分割的精度不是最高的,比Mask R-CNN差一些,但是其分割时间大大减少了,是第一个真正意义上的实时实例分割模型(33.5FPS)。图9和图10是分割的可视化结果图。


YOLAC++:
YOLACT++在保证实时性(大于或等于30fps)的前提下,对原版的YOLACT做出几点改进,大幅提升mAP。主要改进有以下三点:
(1)在Backbone中引入可变形卷积:
可变形卷积(DCNs)通过使用自由形式的采样代替了传统CNN中使用的刚性网格采样,从而全面刷新了各个检测分割模型的精度。可变形卷积的实现方式如下图11所示,从图中我们可以看出,就是在不同的卷积层后面加入一个卷积层来学习输入特征图中每个像素点的位置偏移,然后将学到的X轴和Y轴上的位置偏移加入到输入特征图中,在进行后续的卷积。
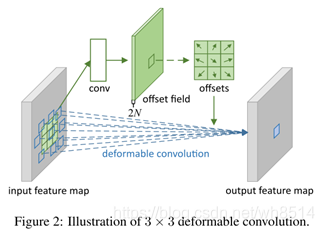
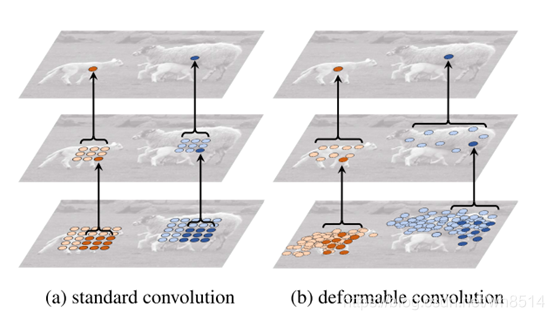
可变形卷积和普通卷积的区别的直观感受可以见图12所示,从图中我们可以看出:在顶层的feature map上取两个激活点(分别在大羊和小羊身上),代表的是不同尺度和形状,然后将顶层的feature map经过33的卷积后,在第二层上得到需要抽样的一些点,第二层的feature map接着在经过一个33的卷积,在底层上得到需要采样的点。通过对比可以看出,可变形卷积通过学习位置偏移得到的采样点更符合物体本身的形状和尺寸,而标准卷积却是固定的采样点。
在YOLACT++ 中,作者参考Deformable ConvNets v2的思路,将ResNet的C3-C5中的各个标准3x3卷积换成3x3可变性卷积,但没有使用堆叠的可变形卷积模块,因为延迟太高。作者做了三组实验,最后选择每隔3个卷积层,替换一个标准卷积为可变形卷积,这样在时间和性能方面实现trade-off。作者认为DCN在YOLACT上表现良好,有以下两点原因:
1)DCN通过与目标实例对齐,增强了网络处理具有不同比例,旋转和纵横比的实例的能力;
2)YOLACT是一种one-stage模型,相对于Mask R-CNN 等two-stage模型,YOLACT缺乏一个重采样过程,也没有办法恢复次优采样。
(2)优化Prediction Head分支:
由于YOLACT是anchor-based的,所以对anchor设计进行优化。经过实验,选择在每个FPN 层上乘3种大小(1, 、),这样相当于anchor数量较原来的YOLACT增加了3倍。
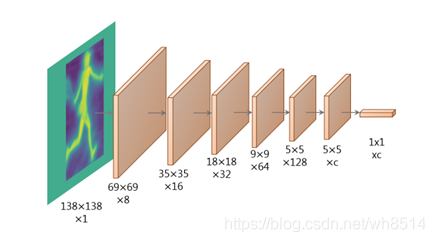
(3)YOLACT++受MS R-CNN的启发,高质量的mask并不一定就对应着高的分类置信度,换句话说,以包围框得分来评价mask好坏并不合理,所以在模型后添加了Mask Re-Scoring分支,该分支使用YOLACT生成的裁剪后的原型mask(未作阈值化)作为输入,输出对应每个类别的GT-mask的IoU。Fast Mask Re-Scoring分支的模型结构如下图13所示,由6个卷积层和1个全局均值池化层组成。
YOLACT++与MS R-CNN的区别:
1)YOLACT++直接使用全尺寸的mask作为scoring分支的输入,而MS R-CNN使用的是ROI Align后的特征再与其经过mask预测分支计算后的特征拼接后的组成的特征;
2)YOLACT++的scoring分支没有使用FC层,这使得分割的速度提高。
作者通过对比实验得出:使用YOLACT++中提出的scoring分支单帧耗时只增加了1.2ms,而使用MS R-CNN中的scoring分支则会将单帧耗时提高28ms。主要是由于ROI Align、FC层和拼接操作造成的极大时延。
参考链接:
(1)【ICCV 2019】一文读懂实时实例分割模型 YOLACT:https://zhuanlan.zhihu.com/p/76470432
(2)论文学习笔记-YOLACT++:https://blog.csdn.net/sinat_37532065/article/details/103603919
(3)Deformable Convolution v1, v2 总结:
https://zhuanlan.zhihu.com/p/77644792














 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









