







陆陆续续学习H264有一段时间了,曾经以为自己可以在这方面大有作为,但是越是学习越发现,根本不存在能够大幅度提升H264性能的方案,对于我这种水平的人来讲。初次学习,概念的理解仍然很困难。在这里我只是简单浅显的讲一讲我最近的读书学习感想。
首先推荐三本书,《新一代视频压缩编码标准H.264(毕厚杰)》,《h264和mpeg-4视频压缩:新一代多媒体的视频编码技术》,《H264标准中文版》。
H264是什么?H264是一种视频流的标准,与MP4、FLV等的区别在于,MP4里面可以包含H264信息和音频信息和其他的视频的属性信息,所以无论H264放在MP4文件里还是放在FLV里面,H264就是H264,是视频的一种格式,就像MP3格式的音频,无论放在MP4文件中还是放在FLV文件中,它都是MP3。
我是在2015年末的时候学习H264的,对于这个时间来讲H264不是新技术,因为H265慢慢的普及之中,我相信H265在将来的一天会取代H264。那么我学习H264的原因是什么呢?了解视频编解码原理,据我了解H265只是对H264细节的改进,从H261开始视频编码的框架大体上是相同的。
下面这幅图是取自《新一代视频压缩编码标准H.264(毕厚杰)》中,这幅图将会伴随着学习H264的全过程,我没有办法用简短的语言清晰的描述下图中的清晰含义,因此写下本篇文章对其进行解释。
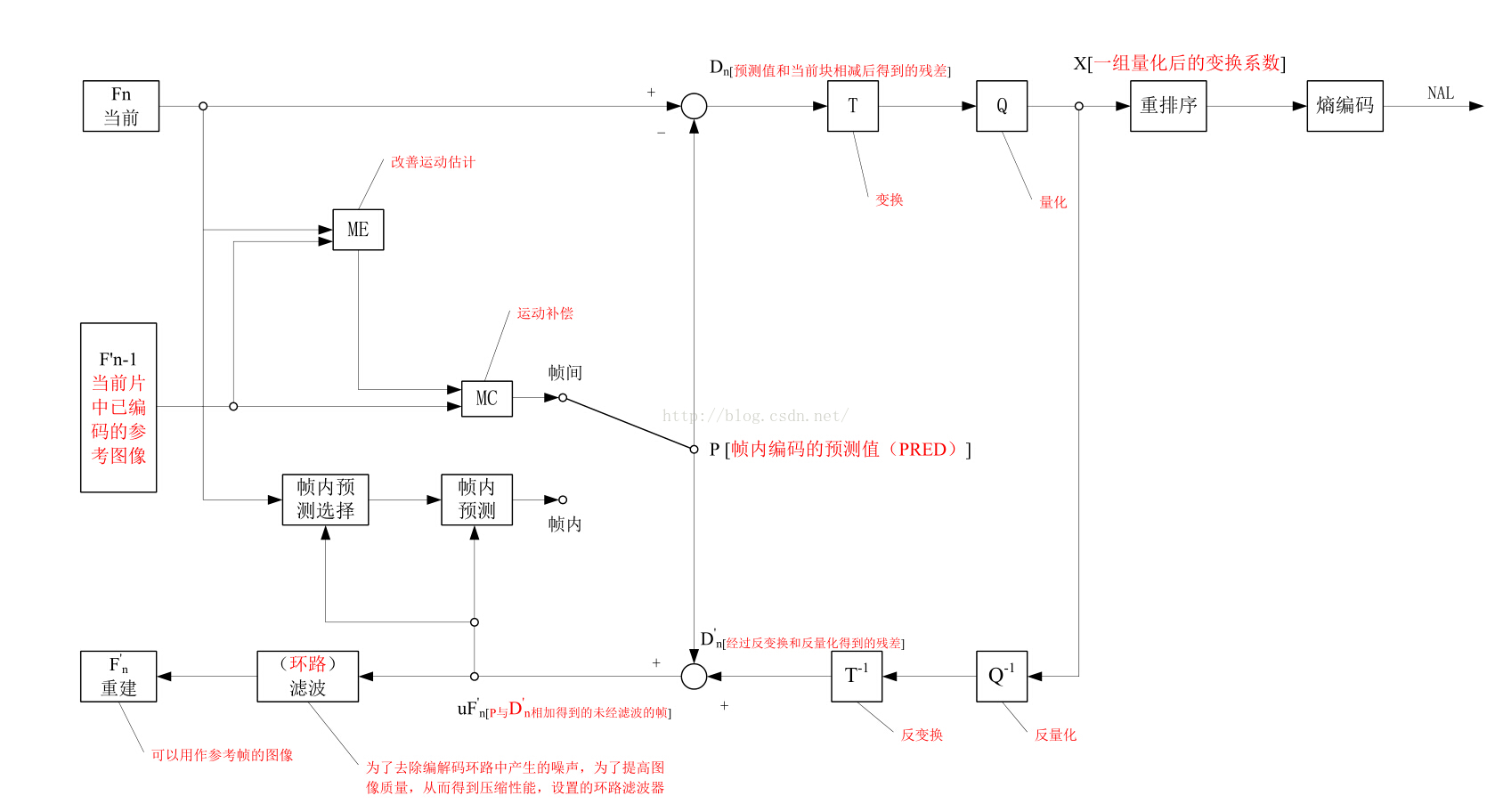
初次看来觉得这幅图比较复杂,的确有些复杂,不过,我接下来要描述的是概念,或者叫名词解释,之后再对这幅图进行详细的解释。
逐行扫描:图像可以看做是一个二维数组,逐行扫描是指在获取图像的时候从第0行开始,之后第1行....直至最后一行对图像进行采样。
隔行扫描:将一副图像按照奇偶分成两部分,0,2,4,6,8.....,和1,3,5,7,9......。这样分成两部分获取图像数据,那么一副图像因此可以分成两个部分,我们成为场,偶数行所构成的场成为顶场,奇数行构成的场成为底场。
帧:经过逐行扫描获得的图像数据称为帧。
场:经过隔行扫面获得的图像数据称为场。
图像:一帧或一场成为一幅图像。
条带:一幅图像内包含至少一个条带。
宏块:一个条带内包含若干个宏块。
预测编码:视频描述的是连续的图像的集合。经过大量的统计表明,前后两幅图像中有大量的数据是一样的,也就是存在着冗余数据,那么使用当前图像对前一张图像做“减法”,获得两个图像的“差值”。那么只需要“差值”即可从前一幅图像中获得当前的图像信息。这个差值我们称之为残差。并且这个差值可以看做是二维数组即看做是一个二维矩阵。使用一些数学上的方法对矩阵进行变换达到一定的压缩目的,一般我们常用的数学方法是DCT,也叫作离散余弦变换,变换的结果我们再次进行采样,比如:DCT变换结果中的值范围是从0,1000,那么我们用0,10去表示这个范围。这个过程叫做采样。比如离散余弦变换后的结果是{0,200,300,800,801,900,1000},我们对其进行重新采样之后可以用以下序列替换{0,2,3,8,8,9,10}。这样可以达到压缩的目的。之后再对量化后的序列进行无损压缩(熵编码)。
预测编码是对应的上图中最上面一行的过程,当前帧Fn和前一帧F'n-1计算出残差Dn,经过变换T,经过量化Q,重新排序,之后进行熵编码得到了压缩的图像数据。
差分脉冲编码DPCM:当前像素为X,左临近像素为A,上临近像素为B,上左临近像素为C。与X之间距离越近的像素,相关性越强,越远相关性越弱。以P作为预测值,按照与X的距离不同给以不同的权值,吧这项像素的加权和作为X的预测值,与实际值相减,得到差值q,由于临近像素的相关性较强,q值非常小,达到压缩编码的目的。接收端把差值q与预测值相加,恢复原始值X。这个过程称为差分脉冲编码DPCM。当前像素的实际值与预测值之间之间存在差值称为残差,对残差记性量化后,得到残差量化值。解码输出与原始信号之间有因为量化而产生的量化误差。
运动估计:由于活动图像临近帧中存在一定的相关性,因此将图像分成若干个宏块,并搜索出各个宏块在临近图像中的位置。并且得到宏块的相对偏移量。得到的相对偏移量称为运动矢量。得到运动矢量的过程称为运动估计。在帧间预测编码中,由于活动图像临近帧中景物存在一定的相关性,因此,可以将活动图像分成若干块或宏块,并设法搜索出每个块或宏块在临近帧图像中的位置,并得出亮着之间的控件位置相对偏移量,得到的相对偏移量就是通常所指的运动矢量,得到运动矢量的过程被称为运动估计。运动矢量和经过匹配后得到的预测误差共同发送到解码端,在解码端按照运动矢量指明的位置,从已经解码的临近参考帧图像中找到相应的块或宏块,和预测误差相加后就得到了块或宏块在当前帧中的位置。通过运动估计可以去除帧间的冗余度,使得视频传输的比特数大为减少,因此运动估计是视频压缩处理的一个重要组成部分。
运动表示法:由于在成像的场景中一般有多个物体作不同的运动,如果直接按照不同类型的运动,将图像分割成复杂区域是比较困难的,最直接和不受约束的方法是在每个像素都指定运动矢量,这就是基于像素表示法。对于任何类型图像都适用,但是需要顾及大量的未知量,并且解在物理上多是不正确的,除非在顾及过程中事假适当的物理约束。在具体实现的时候是不可能的,通常采用基于块的物体运动表示法。
块匹配法:一般对于包含多个运动物体的景物,实际中普遍采用的方法是把一个图像帧分成多个块,使得在每个区域中的运动可以很好地用一个参数化模型表征。即将图像分成若干个nxn块(如:16x16宏块),为每一个块妱运动矢量,并进行运动补偿预测编码。
亚像素位置内插:帧间编码宏块中的每个块或亚宏块分割区域都是根据参考帧中的同尺寸的区域预测得到的,他们之间的关系用运动矢量来表示,由于自然物体的连续性,相邻两帧之间的块运动矢量不是以整像素为基本单位的,可能是以1/4或1/8像素等亚像素作为单位的。
运动矢量中值预测:利用与当前块E相邻的左边块A,上边块B和右上方C的运动矢量,取其中值来作为当前块的运动矢量。运动矢量中值预测:利用与当前块E相邻的左边块A,上边块B和右上方C的运动矢量,取其中值来作为当前块的运动矢量。
空间域的上层块模式运动矢量:H264提供的块尺寸有16x16,8x16,16x8,8x8,8x4,4x8,4x4,他们的图像分割区域分别定义为搜索模式Model1-Model7.
前帧对应块运动矢量预测:利用前一帧与当前块相同坐标位置的块的运动矢量作为当前块的运动矢量
时间域的临近参考帧运动矢量预测:由于视频序列的连续性,当前块再不同的参考帧中的运动矢量也有一定的相干性。假设当前所在帧的时间为t,则当前在前面的参考帧t'中搜索.
当前块的最优匹配块时,可以利用当前块再参考帧t'+1中的运动矢量来估计当前块再帧t'的运动矢量。
变换编码:绝大多数图像都有一个共同的特征,平坦区域和内容缓慢变化的区域占据了一幅图像的大部分,而细节区域和突变区域占据较小部分。也就是说,图像中的低频直流占大部分,高频区域占小部分。这样空间域的图像变换到频域或所谓的变换域会产生相关性很小的变换系数,可以对其进行压缩编码。(关于时域频域概念,本文中不加以详细概述,请参考《傅立叶变换》和百度百科中《时域频域》的相关解释)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









