









在这篇文章中简单介绍了数据源的使用,本文会进一步介绍数据源的使用细节,可以让我们更好的使用它。
一 数据源API
数据源的API有以下几个,
UA_StatusCode
UA_Server_addDataSourceVariableNode(UA_Server *server, const UA_NodeId requestedNewNodeId,
const UA_NodeId parentNodeId, const UA_NodeId referenceTypeId,
const UA_QualifiedName browseName, const UA_NodeId typeDefinition,
const UA_VariableAttributes attr, const UA_DataSource dataSource,
void *nodeContext, UA_NodeId *outNewNodeId);
UA_StatusCode
UA_Server_setVariableNode_dataSource(UA_Server *server, const UA_NodeId nodeId,
const UA_DataSource dataSource);
UA_StatusCode
UA_Server_setNodeContext(UA_Server *server, UA_NodeId nodeId,
void *nodeContext);
从API的名称可以看出,
- 第一个函数可以创建变量节点,并同时添加数据源callback和nodeContext
- 第二个函数是给已经存在的变量节点添加数据源回调
- 第三个函数是给已经存在的变量节点添加nodeContext
第二个和第三个函数适用于变量节点已经创建的情况下。本文先介绍第一个API,再介绍后2个。
二 代码解释
首先,我们写一个函数用来给变量添加数据源,如下,
static UA_StatusCode addDataSourceForVariable(UA_Server *server, UA_NodeId varId,
UA_NodeId parentNodeId, UA_NodeId referenceType, const char *name)
{
UA_StatusCode retval;
/*
** 设置变量属性,变量的data type是UA_INT32
*/
UA_VariableAttributes attr = UA_VariableAttributes_default;
attr.description = UA_LOCALIZEDTEXT((char*)"en-US", (char*)name);
attr.displayName = UA_LOCALIZEDTEXT((char*)"en-US", (char*)name);
attr.dataType = UA_TYPES[UA_TYPES_INT32].typeId;
attr.accessLevel = UA_ACCESSLEVELMASK_READ | UA_ACCESSLEVELMASK_WRITE;
/*
** 设置变量的qualified name
*/
UA_QualifiedName variableName = UA_QUALIFIEDNAME(1, (char*)name);
UA_NodeId variableTypeNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_BASEDATAVARIABLETYPE);
/*
** 准备数据源
*/
UA_DataSource varDataSource;
varDataSource.read = readForVariable;
varDataSource.write = writeForVariable;
/*
** 给nodeContext分配内存空间
*/
UA_Int32 *nodeContext = (UA_Int32 *)UA_malloc(sizeof(UA_Int32));
(*nodeContext) = 0;
/*
** 给变量添加数据源
*/
retval = UA_Server_addDataSourceVariableNode(server, varId, parentNodeId,
referenceType, variableName,
variableTypeNodeId, attr,
varDataSource, nodeContext, NULL);
return retval;
}
函数开始是初始化变量节点的属性,准备添加一个UA_Int32变量。
然后是设置数据源,其类型是结构体UA_DataSource,该结构体里只有2个函数指针,一个用来读,一个用来写,读指针传递的是函数readForVariable,写指针传递的是writeForVariable。
接着是设置nodeContext,这里使用UA_malloc分配一个UA_Int32的内存空间,用来存放该变量的值(也可以根据需要随意分配),注意nodeContext必须是动态分配的内存空间或者一个静态变量,因为是回调,肯定是在后续执行,要保证这段内存空间在回调被调用时还存在。
最后就是调用UA_Server_addDataSourceVariableNode()来添加数据源
readForVariable()和writeForVariable()的定义如下,
static UA_StatusCode readForVariable(UA_Server *server,
const UA_NodeId *sessionId, void *sessionContext,
const UA_NodeId *nodeId, void *nodeContext,
UA_Boolean sourceTimeStamp, const UA_NumericRange *range,
UA_DataValue *dataValue)
{
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_USERLAND, "read variable value");
UA_Int32 * currentVal = (UA_Int32*)nodeContext;
UA_Variant_setScalarCopy(&dataValue->value, currentVal,
&UA_TYPES[UA_TYPES_INT32]);
dataValue->hasValue = true;
(*currentVal) += 1;
return UA_STATUSCODE_GOOD;
}
static UA_StatusCode writeForVariable(UA_Server *server,
const UA_NodeId *sessionId, void *sessionContext,
const UA_NodeId *nodeId, void *nodeContext,
const UA_NumericRange *range, const UA_DataValue *data)
{
UA_Int32 * currentVal = (UA_Int32*)nodeContext;
if (data->value.type == &UA_TYPES[UA_TYPES_INT32])
{
UA_Int32 updateVal = *(UA_Int32 *)data->value.data;
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_USERLAND,
"write variable value: %d", updateVal);
(*currentVal) = updateVal;
}
return UA_STATUSCODE_GOOD;
}
两个函数都从nodeContext参数里获取添加数据源时分配的内存空间,然后对这段内存空间进行读和写。对于读来说,会把nodeContext上存放的值传递给参数dataValue;对于写来说,写入的值是在参数dataValue里,然后把里面包含的值传递给nodeContext
注意,还有个参数nodeId,存放的是变量节点的NodeId,用来表示回调是被哪个变量调用,本例子暂时没有用到。具体可以结合实际情况来决定是否需要这个参数。
main函数如下,
int main(void)
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_StatusCode retval;
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
UA_NodeId varNodeId = UA_NODEID_NUMERIC(1, 8888);
UA_NodeId parentNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER);
UA_NodeId referenceType = UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES);
retval = addDataSourceForVariable(server, varNodeId, parentNodeId,
referenceType, "testVariable1");
if (retval != UA_STATUSCODE_GOOD)
{
return retval;
}
varNodeId = UA_NODEID_NUMERIC(1, 9999);
retval = addDataSourceForVariable(server, varNodeId, parentNodeId,
referenceType, "testVariable2");
if (retval != UA_STATUSCODE_GOOD)
{
return retval;
}
retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
这里添加了2个变量,testVariable1和testVariable2
三 整体代码及使用
整体代码如下,
#include <signal.h>
#include <stdlib.h>
#include "open62541.h"
UA_Boolean running = true;
static void stopHandler(int sign) {
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_SERVER, "received ctrl-c");
running = false;
}
static UA_StatusCode readForVariable(UA_Server *server,
const UA_NodeId *sessionId, void *sessionContext,
const UA_NodeId *nodeId, void *nodeContext,
UA_Boolean sourceTimeStamp, const UA_NumericRange *range,
UA_DataValue *dataValue)
{
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_USERLAND, "read variable value");
UA_Int32 * currentVal = (UA_Int32*)nodeContext;
UA_Variant_setScalarCopy(&dataValue->value, currentVal,
&UA_TYPES[UA_TYPES_INT32]);
dataValue->hasValue = true;
(*currentVal) += 1;
return UA_STATUSCODE_GOOD;
}
static UA_StatusCode writeForVariable(UA_Server *server,
const UA_NodeId *sessionId, void *sessionContext,
const UA_NodeId *nodeId, void *nodeContext,
const UA_NumericRange *range, const UA_DataValue *data)
{
UA_Int32 * currentVal = (UA_Int32*)nodeContext;
if (data->value.type == &UA_TYPES[UA_TYPES_INT32])
{
UA_Int32 updateVal = *(UA_Int32 *)data->value.data;
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_USERLAND,
"write variable value: %d", updateVal);
(*currentVal) = updateVal;
}
return UA_STATUSCODE_GOOD;
}
static UA_StatusCode addDataSourceForVariable(UA_Server *server, UA_NodeId varId,
UA_NodeId parentNodeId, UA_NodeId referenceType, const char *name)
{
UA_StatusCode retval;
UA_VariableAttributes attr = UA_VariableAttributes_default;
attr.description = UA_LOCALIZEDTEXT((char*)"en-US", (char*)name);
attr.displayName = UA_LOCALIZEDTEXT((char*)"en-US", (char*)name);
attr.dataType = UA_TYPES[UA_TYPES_INT32].typeId;
attr.accessLevel = UA_ACCESSLEVELMASK_READ | UA_ACCESSLEVELMASK_WRITE;
UA_QualifiedName variableName = UA_QUALIFIEDNAME(1, (char*)name);
UA_NodeId variableTypeNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_BASEDATAVARIABLETYPE);
UA_DataSource varDataSource;
varDataSource.read = readForVariable;
varDataSource.write = writeForVariable;
UA_Int32 *nodeContext = (UA_Int32 *)UA_malloc(sizeof(UA_Int32));
(*nodeContext) = 0;
retval = UA_Server_addDataSourceVariableNode(server, varId, parentNodeId,
referenceType, variableName,
variableTypeNodeId, attr,
varDataSource, nodeContext, NULL);
return retval;
}
int main(void)
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_StatusCode retval;
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
UA_NodeId varNodeId = UA_NODEID_NUMERIC(1, 8888);
UA_NodeId parentNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER);
UA_NodeId referenceType = UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES);
retval = addDataSourceForVariable(server, varNodeId, parentNodeId, referenceType, "testVariable1");
if (retval != UA_STATUSCODE_GOOD)
{
return retval;
}
varNodeId = UA_NODEID_NUMERIC(1, 9999);
retval = addDataSourceForVariable(server, varNodeId, parentNodeId, referenceType, "testVariable2");
if (retval != UA_STATUSCODE_GOOD)
{
return retval;
}
retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
CMakeLists.txt内容如下,
cmake_minimum_required(VERSION 3.5)
project(myDataSource)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin)
add_definitions(-std=c99)
include_directories(${PROJECT_SOURCE_DIR}/open62541)
include_directories(${PROJECT_SOURCE_DIR}/src)
find_library(OPEN62541_LIB libopen62541.a HINTS ${PROJECT_SOURCE_DIR}/open62541)
add_executable(server ${PROJECT_SOURCE_DIR}/src/server.c)
target_link_libraries(server ${OPEN62541_LIB})
工程结构如下,
cd到build目录下,执行cmake .. && make,编译OK后运行,然后使用UaExpert连接,显式如下,
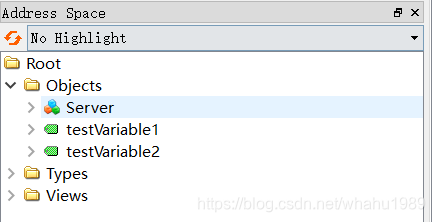
通过不断切换点击testVariable1和testVariable2,可以在右侧的Attributes窗口中看到它们的值在不断加1,在server端也可以看到打印,

说明读的回调被触发了。
我们在testVariable2的右侧Attributes窗口中双击Value属性,把当前值改成400,
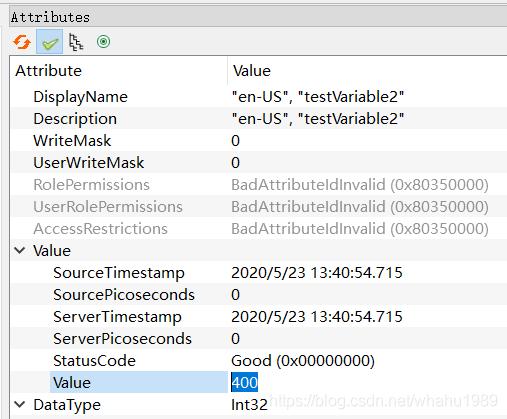
然后在server端就会出现如下打印,说明写的回调被触发。

因为使用了nodeContext,这2个变量节点的值不会互相影响,因为每个节点都有自己的nodeContext
还需要注意一个问题,使用这个API添加数据源后,server启动时会去主动读取这个变量,还读了2次(因为是2个变量,所以出现4次read的回调打印),

至于为什么,暂时不清楚,如果不想出现这种情况,可以参考下一节的,即先添加变量再添加数据源和nodeContext。
四 对已经添加变量的处理
这里使用前面提到的第二个和第三个API来处理已经添加的变量,即,
UA_StatusCode
UA_Server_setVariableNode_dataSource(UA_Server *server, const UA_NodeId nodeId,
const UA_DataSource dataSource);
UA_StatusCode
UA_Server_setNodeContext(UA_Server *server, UA_NodeId nodeId,
void *nodeContext);
如果搞懂第一个API的使用,那么第二个和第三个就很好理解了。代码如下,
#include <signal.h>
#include <stdlib.h>
#include "open62541.h"
UA_Boolean running = true;
static void stopHandler(int sign) {
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_SERVER, "received ctrl-c");
running = false;
}
/*
** 添加变量
*/
static UA_NodeId addIntegerVariable(UA_Server *server, UA_NodeId parentNodeId,
UA_NodeId referenceType, const char *name)
{
UA_StatusCode retval;
/* Define the attribute of the myInteger variable node */
UA_VariableAttributes attr = UA_VariableAttributes_default;
UA_Int32 myInteger = 0;
UA_Variant_setScalar(&attr.value, &myInteger, &UA_TYPES[UA_TYPES_INT32]);
attr.description = UA_LOCALIZEDTEXT((char*)"en-US", (char*)name);
attr.displayName = UA_LOCALIZEDTEXT((char*)"en-US", (char*)name);
attr.dataType = UA_TYPES[UA_TYPES_INT32].typeId;
attr.accessLevel = UA_ACCESSLEVELMASK_READ | UA_ACCESSLEVELMASK_WRITE;
/* Add the variable node to the information model */
UA_NodeId myIntegerNodeId ;
UA_QualifiedName myIntegerName = UA_QUALIFIEDNAME(1, (char*)name);
retval = UA_Server_addVariableNode(server, UA_NODEID_NULL, parentNodeId,
referenceType, myIntegerName,
UA_NODEID_NUMERIC(0, UA_NS0ID_BASEDATAVARIABLETYPE),
attr, NULL, &myIntegerNodeId);
if (retval == UA_STATUSCODE_GOOD)
{
return myIntegerNodeId;
}
else
{
return UA_NODEID_NULL;
}
}
static UA_StatusCode readForVariable(UA_Server *server,
const UA_NodeId *sessionId, void *sessionContext,
const UA_NodeId *nodeId, void *nodeContext,
UA_Boolean sourceTimeStamp, const UA_NumericRange *range,
UA_DataValue *dataValue)
{
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_USERLAND, "read variable value");
UA_Int32 * currentVal = (UA_Int32*)nodeContext;
UA_Variant_setScalarCopy(&dataValue->value, currentVal,
&UA_TYPES[UA_TYPES_INT32]);
dataValue->hasValue = true;
(*currentVal) += 1;
return UA_STATUSCODE_GOOD;
}
static UA_StatusCode writeForVariable(UA_Server *server,
const UA_NodeId *sessionId, void *sessionContext,
const UA_NodeId *nodeId, void *nodeContext,
const UA_NumericRange *range, const UA_DataValue *data)
{
UA_Int32 * currentVal = (UA_Int32*)nodeContext;
if (data->value.type == &UA_TYPES[UA_TYPES_INT32])
{
UA_Int32 updateVal = *(UA_Int32 *)data->value.data;
UA_LOG_INFO(UA_Log_Stdout, UA_LOGCATEGORY_USERLAND,
"write variable value: %d", updateVal);
(*currentVal) = updateVal;
}
return UA_STATUSCODE_GOOD;
}
int main(void)
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_StatusCode retval;
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
UA_NodeId parentNodeId = UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER);
UA_NodeId referenceType = UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES);
// 添加变量
UA_NodeId retNodeId = addIntegerVariable(server, parentNodeId,
referenceType, "myTestVariable");
if (UA_NodeId_equal(&retNodeId, &UA_NODEID_NULL))
{
return -1;
}
// 准备数据源
UA_DataSource varDataSource;
varDataSource.read = readForVariable;
varDataSource.write = writeForVariable;
// 给变量添加数据源
UA_Server_setVariableNode_dataSource(server, retNodeId, varDataSource);
// 给nodeContext分配内存空间
UA_Int32 *nodeContext = (UA_Int32 *)UA_malloc(sizeof(UA_Int32));
(*nodeContext) = 0;
// 给变量设置nodeConetext
UA_Server_setNodeContext(server, retNodeId, nodeContext);
retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
main函数首先使用addIntegerVariable()添加一个变量myTestVariable,然后使用UA_Server_setVariableNode_dataSource()给其添加数据源,最后再使用UA_Server_setNodeContext添加nodeContext
编译ok后使用UaExpert进行连接,
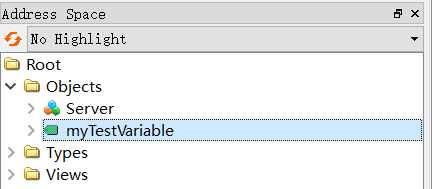
通过来回在Server和myTestVariable之间进行切换点击,可以看到myTestVariable的值在不断加1,同理,也可以修改其值。
五 总结
本质主要讲述了如何使用数据源的相关API,以及一些注意事项,还有一些细微差异。总的来说,数据源是比较灵活的,用的也比较多。
如果有写的不对的地方,希望能留言指正,谢谢阅读。














 4310
4310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









