







List集合
1、list集合存储元素的特点:
有序可重复,有序值的是list集合中的元素有下标,从0开始以1递增;可重复指的是集合中可以存储相同元素;list集合是单例的,也就是说list集合内存的元素是单个的,而非键值对形式的。
2、list集合中的特有常用方法:
- void add(int index, Object element) //向集合中指定的位置添加元素
- Object set(int index, Object element) //修改指定位置的元素
- Object get(int index) //根据下标获取元素(所以list有自己特有的遍历方式)
- int indexOf(Object o) //获取指定对象第一次出现处的索引
- int lastIndexOf(Object o) //获取指定对象最后一次出现处的索引
- Object remove(int index) //删除指定下标位置的元素
3、list集合常用方法实例:
/**
* @author Jason
* @create 2020-07-08 17:12
* list集合常用方法
*/
public class ListTest01 {
public static void main(String[] args) {
//创建list集合
List myList = new ArrayList();
//在集合的末尾添加元素
myList.add("a");
myList.add("b");
myList.add("c");
myList.add("d");
myList.add("e");
//向集合中指定的位置添加元素
myList.add(1, "jason");
//创建迭代器
Iterator it = myList.iterator();
//遍历list集合
while (it.hasNext()) {
Object o = it.next();
System.out.println(o);
}
//根据下标获取元素
Object obj = myList.get(1);
System.out.println("根据下标获取指定元素:"+obj);
//list特有的遍历集合方式
for (int i = 0; i < myList.size(); i++) {
Object object = myList.get(i);
System.out.println("list特有遍历方式:"+object);
}
//获取指定对象第一次出现处的索引
System.out.println(myList.indexOf("jason"));
//获取指定对象最后一次出现处的索引
System.out.println(myList.lastIndexOf("jason"));
//删除指定下标位置的元素
myList.remove(1);
System.out.println("删除后还剩元素:"+myList.size());
//修改指定位置元素
myList.set(2, "g");
//遍历集合
for (int i = 0; i < myList.size(); i++) {
Object o1 = myList.get(i);
System.out.println("修改指定位置后的集合:"+o1);
}
}
}注意:list集合有自己特殊的遍历集合的方式,有别与迭代器遍历,当然他也可以采用迭代器遍历集合。
ArrayList集合
1、概述
ArrayList集合底层采用了数组这种数据结构,相当于动态数组,他有不同与普通数组,他的容量能动态的增长,自己实现了序列化,反序列化的方法,并且是一个非线程安全的集合。
它继承于AbstractList,实现了List, RandomAccess, Cloneable, java.io.Serializable这些接口
2、构造方法:
/**
* 构造一个初始容量为10的空列表
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 替换为空数组
this.elementData = EMPTY_ELEMENTDATA;
}
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
3、ArrayList集合的继承机构图
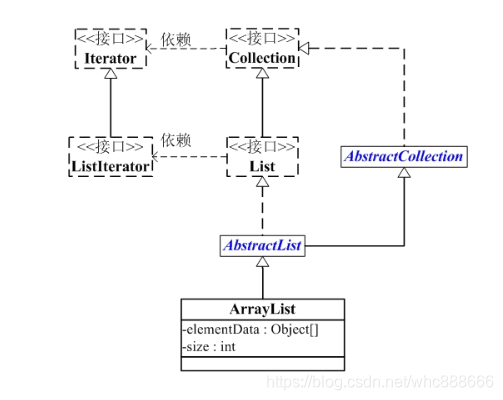
4、深入ArrayList集合
/**
* @author Jason
* @create 2020-07-09 9:48
* ArrayList集合深入
*/
public class ListTest02 {
public static void main(String[] args) {
List list = new ArrayList();
//输出是0
System.out.println(list.size());
}
}无参构造函数源码:
/**
* 构造一个初始容量为10的空列表
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}解析:通过上面的简单代码创建了一个集合,它自然会去调用底层的无参构造函数,上面明明输出的是0,为啥构造函数说初始化了一个容量为10的空列表呢?原因在于size()方法获取的是集合中元素的个数,不是集合容量。他的成员变量告诉你答案:
成员变量:
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 用于空实例的共享空数组实例
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 共享的空数组实例,用于默认大小的空实例。我们将其与EMPTY_ELEMENTDATA区别开来,以了解添加第一个元素时需要充气 * 多少。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 用于存储ArrayList元素的数组缓冲区。ArrayList的容量是此数组缓冲区的长度。添加第一个元素时,任何具有 * elementData ==DEFAULTCAPACITY_EMPTY_ELEMENTDATA 的空ArrayList都将扩展为DEFAULT_CAPACITY。
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* 集合大小
*/
private int size;当我开始往刚创建的集合中添加数据会怎么样呢?如果超过了容量会如何?这是ArrayList集合的核心。其实底层先创建了一个长度为0的数组,当我们添加第一个元素的时候,初始化为10,如果我们添加第十一个数的时候,集合开始通过grow方法扩容,他是将二进制相右移动一位,在加上原来的集合长度,相当于每次扩容为原来的1.5倍。ArrayList集合的底层是数组,我们在用的时候尽量的减少扩容,效率会比较低。
public void add(int index, E element) {
// 判断index 是否有效
rangeCheckForAdd(index);
// 计数+1,并确认当前数组长度是否足够
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index); //将index 后面的数据都往后移一位
elementData[index] = element; //设置目标数据
size++;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//增加容量以确保它至少可以容纳最小容量参数指定的元素数。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
注意:数组在检索的时候效率比较高,在末尾添加元素的效率也非常的高;但是数组在删除元素的时候效率很低。
LinkedList集合
1、概述
LInkedList集合底层是依赖于链表结构,元素在内存空间地址上是不连续的,可以随机的增删元素,不会有大量元素移动的问题。他是把增删发挥到了极致。但是它的检索查找某个元素的时候效率比较低,因为只能从头结点开始一个一个的遍历。
2、LinkedList集合继承结构图:
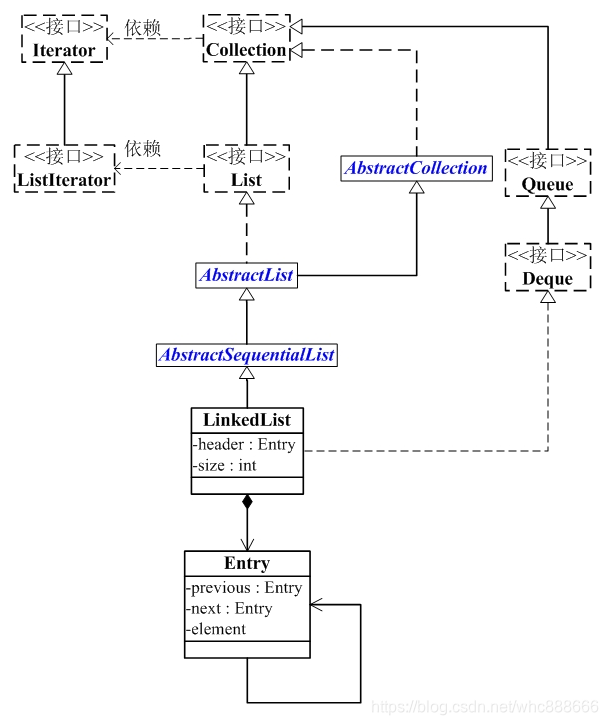
3、成员变量
transient int size = 0;
/**
* 指向第一个节点的指针
*/
transient Node<E> first;
/**
* 指向最后一个节点的指针
*/
transient Node<E> last;4、属性
header是双向链表的头节点,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。 size是双向链表中节点实例的个数。
5、构造方法
/**
* 无参构造
*/
public LinkedList() {
}
/**
* 有参构造
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
6、 LinkedList是AbstractSequentialList的子类
AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)这些骨干性函数。降低了List接口的复杂度。这些接口都是随机访问List的,LinkedList是双向链表;既然它继承于AbstractSequentialList,就相当于已经实现了“get(int index)这些接口”。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
7、添加元素
(1)public boolean add(E e)是在链表的尾部添加元素,其调用了自己的linkLast(E e),该方法首先将last的node引用指向了一个新的Node(l),然后根据l新建了一个newNode,其中的元素就是为要添加的e,然后,我们让last指向了newNode。
(2)public void add(int index, E element) 该方法是在指定 index 位置插入元素。如果 index 位置正好等于 size,则调用 linkLast(element) 将其插入末尾;否则调用 linkBefore(element, node(index))方法进行插入。
//普通的在尾部添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
//在指定位置添加元素
public void add(int index, E element) {
checkPositionIndex(index);
//指定位置也有可能是在尾部
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
//添加一个集合的元素
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
//把 要添加的集合转成一个 数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
//创建两个节点,分别指向要插入位置前面和后面的节点
Node<E> pred, succ;
//要添加到尾部
if (index == size) {
succ = null;
pred = last;
} else {
//要添加到中间, succ 指向 index 位置的节点,pred 指向它前一个
succ = node(index);
pred = succ.prev;
}
//遍历要添加内容的数组
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//创建新节点,头指针指向 pred
Node<E> newNode = new Node<>(pred, e, null);
//如果 pred 为空,说明新建的这个是头节点
if (pred == null)
first = newNode;
else
//pred 指向新建的节点
pred.next = newNode;
//pred 后移一位
pred = newNode;
}
//添加完后需要修改尾指针 last
if (succ == null) {
//如果 succ 为空,说明要插入的位置就是尾部,现在 pred 已经到最后了
last = pred;
} else {
//否则 pred 指向后面的元素
pred.next = succ;
succ.prev = pred;
}
//元素个数增加
size += numNew;
modCount++;
return true;
}
//添加到头部,时间复杂度为 O(1)
public void addFirst(E e) {
linkFirst(e);
}
//添加到尾部,时间复杂度为 O(1)
public void addLast(E e) {
linkLast(e);
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
vector集合
1、概述
vector集合跟ArrayList集合有些相似,底层也是一个数组结构,初始化容量为10,不同的是每次扩容都是原容量的2倍,并且该集合的线程是同步的。vector集合支持随机访问。
2、vector集合结构图及解析
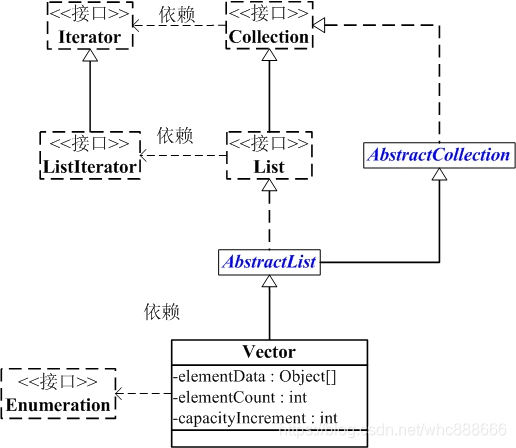
// 向量
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
/**
* 这个数组就是用来存储Vector中每个元素的。其数组大小可以扩展,并且数组的最小值都足以存储下已写入Vector集合的每一个元素
* 数组的大小也可以大于当前已写入Vector集合的所有元素的大小。如果是那样的话,那么多出来的数组位置上的值都为null
* 该数组的初始化大小由构造函数中的initialCapacity参数决定,initialCapacity参数的默认大小为10
*/
protected Object[] elementData;
/**
* 这个变量用于记录当前Vector集合中真实的元素数量,在后续的源代码阅读中会发现这个值在整个操作过程中更多起到的是验证作用。
* 例如判断元素的位置是否超过了最大位置。
*/
protected int elementCount;
/**
* Vector集合支持大小扩容,实际上也就是对其中的elementData进行“变长”操作。
* capacityIncrement变量表示每次扩容的大小,如果capacityIncrement的值小于等于0,那么扩容大小为其当前大小的一倍
*/
protected int capacityIncrement;
}
3、vector集合的构造函数
/**
* Constructs an empty vector with the specified initial capacity and capacity increment.
* @param initialCapacity the initial capacity of the vector
* @param capacityIncrement the amount by which the capacity is increased when the vector overflows
* @throws IllegalArgumentException if the specified initial capacity is negative
*/
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
// elementData 数组从null被重新指定了一个数组的地址,数组大小默认为10;
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
/**
* Constructs an empty vector with the specified initial capacity and
* with its capacity increment equal to zero.
* @param initialCapacity the initial capacity of the vector
* @throws IllegalArgumentException if the specified initial capacity is negative
*/
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
/**
* Constructs an empty vector so that its internal data array
* has size {@code 10} and its standard capacity increment is zero.
*/
public Vector() {
this(10);
}
4、vector集合的扩容
(1)何时扩容?
vector集合每次调用add()方法的时候都会调用这个方法private void ensureCapacityHelper(int minCapacity),对容量进行检查。
如果当前调用该私有方法时,入参所传入的最小容量(minCapacity)如果大于当前Vector集合elementData数组的大小,则进行扩容——调用grow(int)方法。而ensureCapacityHelper方法的调用广泛存在于那些“可能引起Vector集合内数据量发生变化”的方法中,例如:setSize()方法、insertElementAt()方法、addElement()方法、add()方法、addAll()方法等等,以及那些主动寻求容量验证的方法:ensureCapacity()方法。
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}(2)怎么扩容?
vector扩容主要是调用grow(minCapacity)方法。
private void grow(int minCapacity) {
// 将“扩容”操作前当前elementData数组的大小保存下来(保存成oldCapacity),后面可能用到。
int oldCapacity = elementData.length;
// 这句代码非常关键,确定新的容量有两种情况:
// 1、如果当前设定了有效的扩容大小(在Vector集合初始化时可以设定),那么新的容量 = 老的容量 + 设定的扩容值
// 2、如果当前没有设定有效的扩容大小(既是capacityIncrement的值 <= 0 ),那么新的容量 = 老的容量 * 2
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
// 如果当前新的容量 小于 grow方法调用时传入的最小容量,则新的容量以传入的最小容量为准
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果当前新的容量 大于 MAX_ARRAY_SIZE常量,这个常量为2147483639[0x7ffffff7]
// 那么调用hugeCapacity()方法确认新的容量,
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 最后使用Arrays工具类提供的copyOf方法完成真实的扩容过程
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 该私有方法的名字叫做:巨大的容量.......
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
// 如果当前方法调用传入的minCapacity的值,大于常量2147483639,那么取Java中整数类型的最大值2147483647
// 否则就取MAX_ARRAY_SIZE常量的值2147483639
return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}(3)重要方法详解
-
Arrays.copyOf(T[] original, int newLength)方法:该方法是一个工具性质的方法,其方法意义为复制指定数组(original)为一个新的数组对象,后者的长度为给定的新长度(newLength)。
-
hugeCapacity()方法: 该方法中出现了两个关键的常量MAX_ARRAY_SIZE和MAX_VALUE,MAX_ARRAY_SIZE的大小为2147483639(7FFF FFF7),表示支持的最大数组大小;MAX_VALUE的大小为2147483647(7FFF FFFF),标识32位int类型所代表的最大整数值。那么按照上文源代码的意义,Vector集合最大支持的数组容量就是2147483647。















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











