







本文是纽约大学,David Eigen和Jason Rolfe等13年撰写的论文;和他们的上一篇通过deconvnet网络可视化来理解深度卷积网络不同的是,本文通过循环卷积网络来探究网络深度,参数个数,特征个数等网络结构对于网络性能的影响。
摘要:层数,特征个数,filter尺寸,间隔数,pooling方式,pooling尺寸,连接方式,归一化,参数个数等都是影响卷积网络性能的因素;本文通过循环卷积网络来探究层数,特征个数和参数这个3个因素的独立影响;通过实验发现层数和参数个数影响较大,特征个数对于结果影响较小。建议在设计网络事更多的应该关注深度和参数个数。
一:新型递归网络—递归卷积网络

图中红色的部分为第一个特征提取阶段卷积和Pooling构成;为了构成循环结构,从第一层提取以后的高层就剔除pooling结构,只是单纯的卷积结构,这样可以保证卷积循环结构(因为如果包含pooling结构,在子采样后每层的特征维数就会改变)。
循环卷积网络,图中a是正常的卷积网络,层间权值没有关系;图b,当正常的卷积网络,在绑定每层的权值后,由于高层之间的权值,特征个数,特征维数都相同,就可以看做是一个循环网络。就可以简化表示为图c的样式。
循环卷积网络可以梳理分开影响卷积网络结果的各个因素;正常卷积网络中,增加层数和特征个数都会增加网络总的参数个数;而循环网络增加层数,由于权值绑定,不会增加总的参数个数;但是增加特征个数,还是会增加参数个数。
二:CIFAR-10和SVNH分类网络结构及参数设置
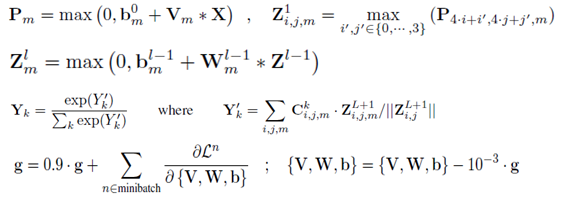
Vm代表第一层卷积,有m个fi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









