






map ----> partition(分区默认,可修改) ----> sort(排序默认,可修改) -----> combiner(map阶段排序,可选) -----> spill (溢写,默认不可改) -----> meger(合并文件,默认,不可改) -----> compress(压缩,可选) -----> reduce
======================Shuffle===============================
MapReduce程序
** 离线数据分析、数据清洗(过滤脏数据)
** 执行命令:bin/yarn jar 包名.类名 参数
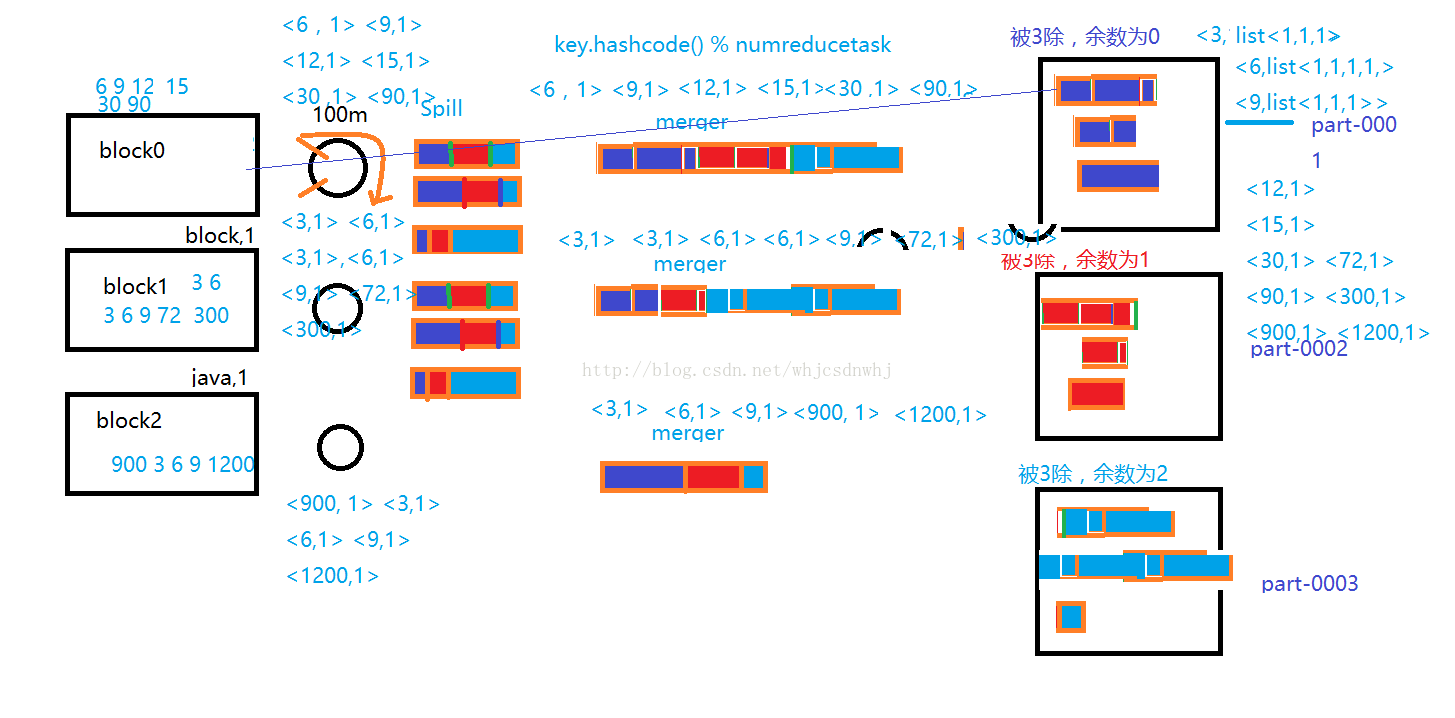
MapReduce Shuffle
数据从map task输出到reduce task输入的这段过程
** map的输入: split
** 默认情况下,一个block就是一个split,一个split对应一个map
** 尽量保证每个map的输入数据是来自同一个block
** 如果设计多个block为一个split,可能会造成大量额外流量
** 合理控制map个数
>>Input
<0,hadoop mapreduce>
<14,hbase hadoop>
>>map()
** map() --> value.toString().split("\t")
** output
<hadoop,1> <mapreduce,1> <hbase,1> <hadoop,1>
----Shuffle---------------
>>>>>>>> map shuffle
>>> 环形缓存区
默认大小100M mapreduce.task.io.sort.mb
>>> partition分区
** HashPartitioner
** 决定数据交给哪个reduce处理
1 hadoop hbase --> reduce1
2 mapreduce --> reduce2
3 ... --> reduce3
>>> sort
** 按照key进行字典顺序排序
>>> combine (可选,并非所有的情况都可以使用combine)
** 默认情况下,相当于map阶段局部reduce
>>> spill
** 当环形缓存区容量达到80M(0.8) mapreduce.map.sort.spill.percent
** 会将缓存区的数据写入本地磁盘临时目录(不是HDFS)
>>> merge
** 把很多小文件合并成一个大文件
>>> compress (可选)
** 减轻网络IO的压力
>>>>>>>> reduce shuffle (application master)
每个reduce会去map的输出结果中拉取自己对应的分区数据
merge合并
** 按照key进行文件合并
group分组
** 将相同key的value值放到一起,形成list
** <hadoop,(1,1)> <mapreduce,1> ...
----reduce-------------
>>reduce
<hadoop,(1,1)><mapreduce,1><hbase,1>
>>output
** 数据汇总
** hadoop 2,mapreduce 1,hbase 1 ...
设置reduce个数:
** 当前job任务
job.setNumReduceTasks(n);
** 永久生效
配置文件 mapred-site.xml














 5033
5033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









