







K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
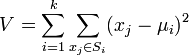
算法过程如下:
1)从N个文档随机选取K个文档作为质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
具体如下:
输入:k, data[n];
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
python代码如下:
# file name: K_means
# function: K_均值聚类算法
# author: 宋志勇
# time:2017.10.07
# -*- coding: UTF-8 -*-
import numpy
import random
import matplotlib.pyplot as plt
def findCentroids(data_get, k): # 随机获取k个质心
return random.sample(data_get, k)
def calculateDistance(vecA, vecB): # 计算向量vecA和向量vecB之间的欧氏距离
return numpy.sqrt(numpy.sum(numpy.square(vecA - vecB)))
def minDistance(data_get, centroidList):
# 计算data_get中的元素与centroidList中k个聚类中心的欧式距离,找出距离最小的
# 将该元素加入相应的聚类中
clusterDict = dict() # 用字典存储聚类结果
for element in data_get:
vecA = numpy.array(element) # 转换成数组形式
flag = 0 # 元素分类标记,记录与相应聚类距离最近的那个类
minDis = float("inf") # 初始化为最大值
for i in range(len(centroidList)):
vecB = numpy.array(centroidList[i])
distance = calculateDistance(vecA, vecB) # 两向量间的欧式距离
if distance < minDis:
minDis = distance
flag = i # 保存与当前item距离最近的那个聚类的标记
if flag not in clusterDict.keys(): # 簇标记不存在,进行初始化
clusterDict[flag] = list()
clusterDict[flag].append(element) # 加入相应的类中
return clusterDict # 返回新的聚类结果
def getCentroids(clusterDict):
centroidList = list()
for key in clusterDict.keys():
centroid = numpy.mean(numpy.array(clusterDict[key]), axis=0) # 求聚类中心即求解每列的均值
centroidList.append(centroid)
return numpy.array(centroidList).tolist()
def calculate_Var(clusterDict, centroidList):
# 计算聚类间的均方误差
# 将类中各个向量与聚类中心的距离进行累加求和
sum = 0.0
for key in clusterDict.keys():
vecA = numpy.array(centroidList[key])
distance = 0.0
for item in clusterDict[key]:
vecB = numpy.array(item)
distance += calculateDistance(vecA, vecB)
sum += distance
return sum
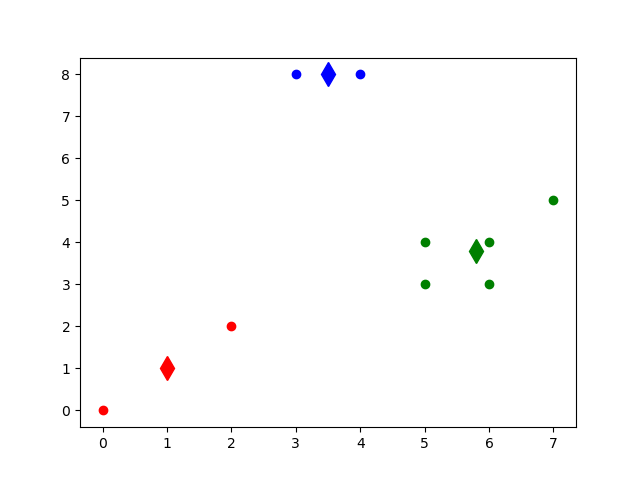
def showCluster(centroidList, clusterDict):
# 画聚类结果
colorMark = ['or', 'ob', 'og', 'ok', 'oy', 'ow'] # 元素标记
centroidMark = ['dr', 'db', 'dg', 'dk', 'dy', 'dw'] # 聚类中心标记
for key in clusterDict.keys():
plt.plot(centroidList[key][0], centroidList[key][1], centroidMark[key], markersize=12) # 画聚类中心
for item in clusterDict[key]:
plt.plot(item[0], item[1], colorMark[key]) # 画类下的点
plt.show()
data = [[0.0, 0.0], [3.0, 8.0], [2.0, 2.0], [1.0, 1.0], [5.0, 3.0],
[4.0, 8.0], [6.0, 3.0], [5.0, 4.0], [6.0, 4.0], [7.0, 5.0]]
if __name__ == '__main__':
centroidList = findCentroids(data, 3) # 随机获取3个聚类中心
clusterDict = minDistance(data, centroidList) # 第一次聚类迭代
newVar = calculate_Var(clusterDict, centroidList) # 计算均方误差值,通过新旧均方误差来获得迭代终止条件
oldVar = -0.0001 # 初始化均方误差
print('***** 第1次迭代 *****')
for key in clusterDict.keys():
print('聚类中心: ', centroidList[key])
print('对应聚类: ',clusterDict[key])
print('平均均方误差: ', newVar)
showCluster(centroidList, clusterDict) # 展示聚类结果
k = 2
while abs(newVar - oldVar) >= 0.0001: # 当连续两次聚类结果差距小于0.0001时,迭代结束
centroidList = getCentroids(clusterDict) # 获得新的聚类中心
clusterDict = minDistance(data, centroidList) # 新的聚类结果
oldVar = newVar
newVar = calculate_Var(clusterDict, centroidList)
print('***** 第%d次迭代 *****' % k)
for key in clusterDict.keys():
print('聚类中心: ', centroidList[key])
print('对应聚类: ', clusterDict[key])
print('平均均方误差: ', newVar)
showCluster(centroidList, clusterDict) # 展示聚类结果
k += 1得到的结果如下














 5969
5969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









