









Berkeley DB(BDB)是一个高效的嵌入式数据库编程库,C语言、C++、Java、Perl、Python、Tcl以及其他很多语言都有其对应的API。Berkeley DB可以保存任意类型的键/值对(Key/Value Pair),而且可以为一个键保存多个数据。Berkeley DB支持让数千的并发线程同时操作数据库,支持最大256TB的数据,广泛用于各种操作系统,其中包括大多数类Unix操作系统、Windows操作系统以及实时操作系统。
Berkeley DB在06年被 Oracle 收购了,现在我们在 Oracle 网站上会看到: BerkeleyDB、BerkeleyDB XML 和 BerkeleyDB JAVA Edition 这个三个东东。简单的说最开始 BerkeleyDB 是只有 C 语言版本的,但是 JAVA 也可以使用,只不过需要通过 JNI 调用,效率可能有点影响。后来出了 JAVA Edition ,用纯 JAVA 实现了一遍,也就是我们看到的 BerkeleyDB JAVA Edition (简称 JE )。
JE是一个通用的事务保护的,100%纯Java(JE不作任何JNI调用)编写的嵌入式数据库。因此,它为Java开发人员提供了安全高效的对任意数据的存储和管理。
JE 适合于管理海量的,简单的数据。其中的记录都以简单的 键值对保存,即 key/value对。由于它操作简单,效率较高,因此受到了广泛的好评。
JE官网:http://www.oracle.com/technetwork/database/database-technologies/berkeleydb/overview/index.html
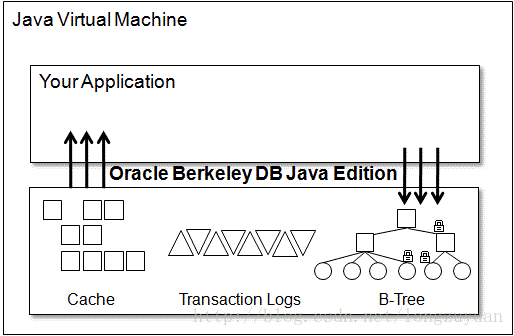
一些特性:
1. 大型数据库的支持:它支持从1到数百万级的数据量,数据库的大小限制基本上受限于你的硬件支持。
2. 多线程,多进程支持:JE读写操作都可以是多线程,使用记录级锁定为线程应用程序提供高并发性。此外,JE使用死锁超时检测的机制来确保不会有两个线程无限期的死锁。JE允许多个进程访问同一个DB,但在这种情况下, Berkeley 只允许一个线程进行写操作,读操作随意。
3. 事务:原子性,可恢复,隔离性。
4. 内存Cache:为了减少IO操作提高性能,将数据暂存在内存里面。
5. 索引。
简单读写操作:
Database.put(): 向数据库写入数据,如果不支持重复记录,则会覆盖更新key对应的已有记录
Database.putNoOverwrite():向数据库写入数据,但是如果key已经存在,不会覆盖已有数据(即使数据库支持重复key)
Database.putNoDupData():向数据库写入数据(该方法仅用于支持重复key的数据库),如果key和value对应的记录已经存在,那么操作结果是:OperationStatus.KEYEXIST
Database.get() :检索key对应的记录,如果没有找到,操作结果返回:OperationStatus.NOTFOUND
Database.getSearchBoth() :根据key和value 检索数据库记录,如果没有找到,操作结果返回:OperationStatus.NOTFOUND
属性配置
跟Environment一样,database也可以通过DatabaseConfig进行配置。DatabaseConfig.setAllowCreate()
设置当不存在该数据库的时候是否创建一个新的库
DatabaseConfig.setBtreeComparator()
设置用来决定数据库中记录顺序的排序器
DatabaseConfig.setDuplicateComparator()
设置用来比较重复数据的排序器
DatabaseConfig.setSortedDuplicates()
设置该数据库是否允许重复的数据
DatabaseConfig.setExclusiveCreate()
设置当存在该数据库的时候是否会打开数据库失败
DatabaseConfig.setReadOnly()
设置数据库是否只读
DatabaseConfig.setTransactional()
设置事务属性
DatabaseConfig.setDeferredWrite()
设置延迟写属性
DatabaseConfig.setTemporary()
设置该数据库是否为临时数据库(Temporary Databases)
延迟写数据库
默认情况下,数据库会在操作的时候写入变化到磁盘中,如果你使用了事务,那么将会在事务提交的时候写入变化。但是如果你启用了延迟写配置,数据库不会把变化立即写入,除非1.显式的调用了Database. sync()方法;2.缓存满了;3.到达了检查点(checkpoint)。延迟写可以带来以下两个好处:
1.在多线程情况下,可以减少写操作的瓶颈。
2.可以减少写操作数据库,比如你一条记录你多次修改了它,那只会最后一次的改变会被写入到数据库中。
数据库也可以在延迟写和普通库之间进行转换,比如你要加载很大量的数据到数据库中,明显的延迟写数据库相较于普通数据库有更好的性能,这时你可以在加载大数据的时候设置延迟写,在加载完毕之后一次性的写入到数据库中。然后关闭数据库,再使用普通数据库配置属性打开。
设置DatabaseConfig.setDeferredWrite(true),可以让数据库变成延迟写数据库。
临时数据库
这是一个很特殊的数据库,打开临时数据库后,你可以像一般的数据库一样对它进行操作,但是在关闭这个数据库后所有的数据将被清除。也就是说临时数据库中的数据不是持久性的。
并且临时数据库内部采用了延迟写,但是这并不意味着临时数据库将不会发生I/O操作,当缓存满的时候,数据库仍然会把数据写入到磁盘上。临时数据库拥有延迟写数据库的所有优点,但是有一点不同于延迟写数据库,它不会在到达检查点的时候进行写入。
设置DatabaseConfig.setTemporary(true),可以让数据库变成延迟写数据库。
//URL队列的实现,讲访问过的URL存到另外一个数组中,并删除队列中已经访问过的URL
package com.mycrawler.berkeleydb;
import java.io.File;
import com.sleepycat.je.Cursor;
import com.sleepycat.je.Database;
import com.sleepycat.je.DatabaseConfig;
import com.sleepycat.je.DatabaseEntry;
import com.sleepycat.je.DatabaseException;
import com.sleepycat.je.Environment;
import com.sleepycat.je.EnvironmentConfig;
import com.sleepycat.je.LockMode;
import com.sleepycat.je.OperationStatus;
import com.sleepycat.je.Transaction;
public class OperatingDB {
//讲URL写入队列中
public boolean writerURL(String fileName, String url,
String databaseDBName, String rankPage) {
boolean mark = false;
// 配置环境 https://community.oracle.com/thread/996592?start=0&tstart=0 问题地址
EnvironmentConfig envConfig = new EnvironmentConfig();
// 设置配置事务
envConfig.setTransactional(true);
// 如果不存在就创建环境
envConfig.setAllowCreate(true);
File file = new File(fileName);
file.mkdirs();
try {
Environment exampleEnv = new Environment(file, envConfig);
Transaction txn = exampleEnv.beginTransaction(null, null);
DatabaseConfig dbConfig = new DatabaseConfig();
dbConfig.setTransactional(true);
dbConfig.setAllowCreate(true);
dbConfig.setSortedDuplicates(false);
Database exampleDb = exampleEnv.openDatabase(txn, databaseDBName,
dbConfig);
txn.commit();
DatabaseEntry theKey = new DatabaseEntry(url.getBytes("utf-8"));
DatabaseEntry theData = new DatabaseEntry(
rankPage.getBytes("utf-8"));
exampleDb.put(null, theKey, theData);
exampleDb.close();
exampleEnv.close();
} catch (Exception e) {
e.printStackTrace();
mark = false;
}
return mark;
}
// 读取没有访问过的URL
public String readerURL(String fileName, String databaseDBName) {
// boolean mark = false;
// 配置环境
EnvironmentConfig envConfig = new EnvironmentConfig();
// 设置配置事务
envConfig.setTransactional(true);
// 如果不存在就创建环境
envConfig.setAllowCreate(true);
File file = new File(fileName);
String theKey = null;
// file.mkdirs();
try {
Environment exampleEnv = new Environment(file, envConfig);
// Transaction txn = exampleEnv.beginTransaction(null,null);
DatabaseConfig dbConfig = new DatabaseConfig();
dbConfig.setTransactional(true);
dbConfig.setAllowCreate(true);
dbConfig.setSortedDuplicates(false);
Database myDB = exampleEnv.openDatabase(null, databaseDBName,
dbConfig);
// txn.commit();
// txn = exampleEnv.beginTransaction(null,null);
Cursor cursor = myDB.openCursor(null, null);
DatabaseEntry foundKey = new DatabaseEntry();
DatabaseEntry foundValue = new DatabaseEntry();
// cursor.getPrev()与cursor.getNext()的区别:一个是从前往后读取,一个是从后往前读取
// 这里讲访问遍历数据库全部数据while循环噶为if判断,则就只读取第一条数据
if (cursor.getNext(foundKey, foundValue, LockMode.DEFAULT) == OperationStatus.SUCCESS) {
theKey = new String(foundKey.getData(), "UTF-8");
}
cursor.close();
myDB.close();
exampleEnv.close();
} catch (Exception e) {
e.printStackTrace();
}
return theKey;
}
// 读取已经爬取过的URL
public String readerUsedURL(String fileName, String databaseDBName,
String url) {
// 配置环境
EnvironmentConfig envConfig = new EnvironmentConfig();
// 设置配置事务
envConfig.setTransactional(true);
// 如果不存在就创建环境
envConfig.setAllowCreate(true);
File file = new File(fileName);
String theKey = null;
// file.mkdirs();
try {
Environment exampleEnv = new Environment(file, envConfig);
Transaction txn = exampleEnv.beginTransaction(null, null);
DatabaseConfig dbConfig = new DatabaseConfig();
dbConfig.setTransactional(true);
dbConfig.setAllowCreate(true);
dbConfig.setSortedDuplicates(false);
Database myDB = exampleEnv.openDatabase(txn, databaseDBName,
dbConfig);
txn.commit();
Cursor cursor = myDB.openCursor(null, null);
DatabaseEntry foundKey = new DatabaseEntry();
DatabaseEntry foundValue = new DatabaseEntry();
// cursor.getPrev()与cursor.getNext()的区别:一个是从前往后读取,一个是从后往前读取
// 这里讲访问遍历数据库全部数据while循环噶为if判断,则就只读取第一条数据
while (cursor.getNext(foundKey, foundValue, LockMode.DEFAULT) == OperationStatus.SUCCESS) {
theKey = new String(foundKey.getData(), "UTF-8");
if (theKey.equals(url)) {
return theKey;
}
}
cursor.close();
myDB.close();
exampleEnv.close();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
// 删除已经读取过的URL
public void deleteReadURL(String envHomePath, String databaseName,
String key) {
Environment mydbEnv = null;
Database myDatabase = null;
// 创建一个EnvironmentConfig配置对象
EnvironmentConfig envCfg = new EnvironmentConfig();
// 如果设置了true则表示当数据库环境不存在时候重新创建一个数据库环境,默认为false.
envCfg.setAllowCreate(true);
// 设置数据库缓存大小
// envCfg.setCacheSize(1024 * 1024 * 20);
// 事务支持,如果为true,则表示当前环境支持事务处理,默认为false,不支持事务处理。
envCfg.setTransactional(true);
try {
mydbEnv = new Environment(new File(envHomePath), envCfg);
DatabaseConfig dbCfg = new DatabaseConfig();
// 如果数据库不存在则创建一个
dbCfg.setAllowCreate(true);
// 如果设置为true,则支持事务处理,默认是false,不支持事务
dbCfg.setTransactional(true);
myDatabase = mydbEnv.openDatabase(null, databaseName, dbCfg);
DatabaseEntry keyEntry = new DatabaseEntry(key.getBytes("utf-8"));
// 删除
myDatabase.delete(null, keyEntry);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != myDatabase) {
try {
myDatabase.close();
} catch (DatabaseException e) {
e.printStackTrace();
}
}
if (null != mydbEnv) {
// 在关闭环境前清理下日志
try {
mydbEnv.cleanLog();
} catch (DatabaseException e) {
e.printStackTrace();
}
try {
mydbEnv.close();
} catch (DatabaseException e) {
e.printStackTrace();
}
mydbEnv = null;
}
}
}
public static void main(String[] args) {
OperatingDB odb = new OperatingDB();
// odb.writerURL( "c:/data/","www.163.com","data","123");
// odb.writerURL( "c:/data/","www.baidu.com","data","123");
String url = odb.readerURL("c:/data/", "data");
if(url != null){
odb.deleteReadURL("c:/data/","data",url);
}
else{
System.out.println("url is null !!!");
}
}
}















 4304
4304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









