







CPU是如何执行程序的
我们知道CPU是用来处理、运算计算机所有数据的功能模块,而我们的程序在运行时会将数据保存在内存中,CPU会去内存中读取计算时所使用到的数据。随着CPU运算速度的升级,出现了CPU运算速度与内存读写速度不匹配的情况,为了解决CPU在运行时总是等待从内存中读写数据从而导致CPU空闲而影响效率的问题,在CPU内部集成了一定量的寄存器与高速缓存,来提高CPU在处理数据时的效率。现代CPU的架构模型虽然有多种,但是在本质上都是一样的,如下图所示:
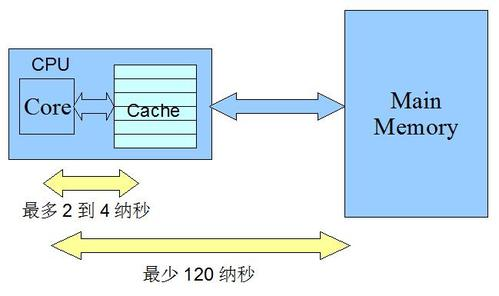
从上图看到,CPU从缓存中读取数据的速度远远快于从主存中读取数据的速度,所以在CPU进行计算时,会先将数据从主存中读取到缓存中,并利用缓存中的数据进行处理,然后定期将缓存中的数据刷新至主存中。
在单CPU核心计算下,这样的架构并不会出现问题而且速度很快,但是在多CPU核心处理数据时,就会出现并发问题,如CPU1对主存中的A元素进行了A = A + 1 的操作,而这个操作执行完后保存在缓存中,还没有来得及刷新到主存时,CPU2获取了从主存内获取A并对其进行了A = A - 1的操作,这样就会出现数据不一致的情况。因为CPU将其内部缓存数据刷新至主存的动作并不是实时的,也就是说对于如下代码:
int a = 0;
for(int i = 0; i < 100; i++){
a++;
}
很有可能是执行一次a++就刷新至主存中,也有可能是等a++循环100次时再刷新,所以在进行多线程并发操作时,需要考虑如下三点:
可见性:CPU1对主存中的数据的操作要对其他CPU是可见的。
原子性:将所需要执行的方法视为最小执行单元。要么不执行,要执行就全部执行,不会出现执行一半的情况。
有序性:代码的执行顺序是有序的。
上述内容是偏计算机底层,不同的平台,内存模型可能有差异,而jvm的内存模型规范是统一的,它帮我们屏蔽了底层平台的差异性。
java内存模型(java memory model:JMM)
JMM其实是对底层的一个抽象。我们知道在JAVA程序运行时,所有类的实例、静态域、数组元素都是存储在堆中,而堆内存中的数据是对所有的线程共享的,在线程内部还有各自的栈、计数器,这里还有一个工作内存,用于存储当前线程在计算时从主存中读/写共享变量的一个副本,上述都是线程私有的,对其他线程不可见,如下图所示:
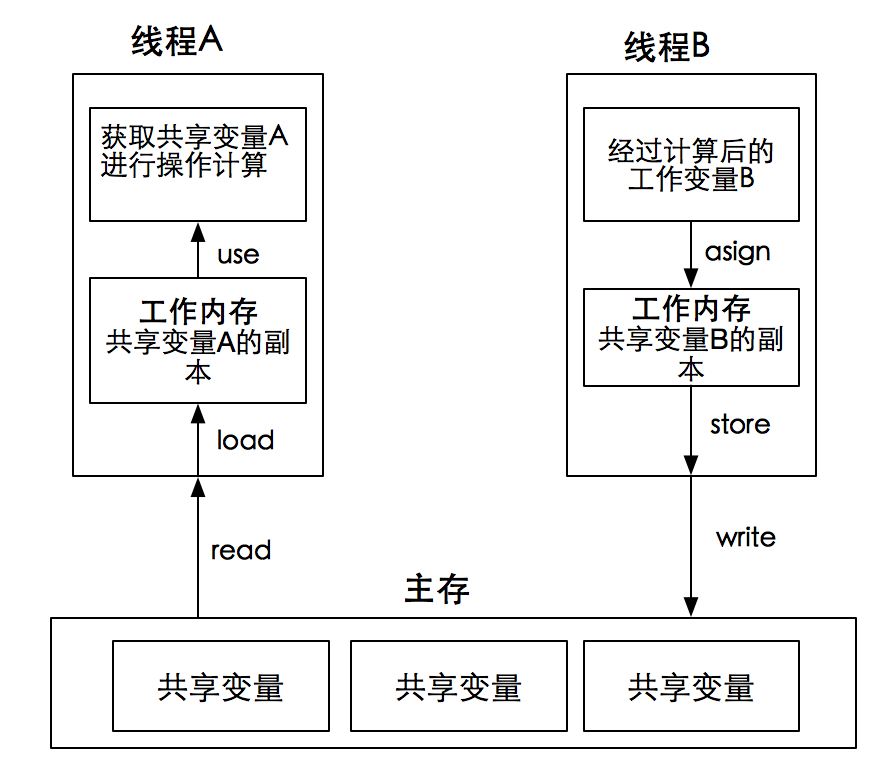
在线程读取共享变量时涉及六个操作:
1.读:
- read:作用于主存,从主存中获取共享变量,随后紧跟load操作。
read:作用于主存,从主存中获取共享变量,随后紧跟load操作。
load:作用于工作内存,它将read操作从主存中获取的共享变量写入工作内存中。
use:将工作内存中的共享变量副本取出,用于线程计算使用。
2.写:
asign:将处理完的共享变量存入工作内存。
store:作用于工作内存,将工作内存中的共享变量刷新至主存,随后紧跟write操作。
write:作用于主存,它将store操作从工作内存中的共享变量值刷新到主存变量中。
两个JAVA线程需要通信的话,包含以下两个步骤:
1. 线程A从主存中读取数据,存入本地工作内存中,然后从工作内存中读取数据进行计算,再将计算过的数据存入工作内存中,刷新工作内存的数据至主存中。
2. 线程B将主存中的数据更新至本地工作内存。
可以看到,如果两个线程需要进行通信或对同一共享变量进行操作,就必须经过主存,否则会出现并发问题。在下一章我会来说一下JAVA如何保障在多线程计算时的可见性、有序性以及原子性。














 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









