







转自:http://www.sohu.com/a/134988666_206784
卷积神经网络原理浅析
卷积神经网络(Convolutional Neural Network,CNN)最初是为解决图像识别等问题设计的,当然其现在的应用不仅限于图像和视频,也可用于时间序列信号,比如音频信号、文本数据等。在早期的图像识别研究中,最大的挑战是如何组织特征,因为图像数据不像其他类型的数据那样可以通过人工理解来提取特征。
在股票预测等模型中,我们可以从原始数据中提取过往的交易价格波动、市盈率、市净率、盈利增长等金融因子,这即是特征工程。但是在图像中,我们很难根据人为理解提取出有效而丰富的特征。在深度学习出现之前,我们必须借助SIFT、HoG等算法提取具有良好区分性的特征,再集合SVM等机器学习算法进行图像识别。
SIFT对一定程度内的缩放、平移、旋转、视角改变、亮度调整等畸变,都具有不变性,是当时最重要的图像特征提取方法之一。然而SIFT这类算法提取的特征还是有局限性的,在ImageNet ILSVRC比赛的最好结果的错误率也有26%以上,而且常年难以产生突破。
卷积神经网络提取的特征则可以达到更好的效果,同时它不需要将特征提取和分类训练两个过程分开,它在训练时就自动提取了最有效的特征。CNN作为一个深度学习架构被提出的最初诉求,是降低对图像数据预处理的要求,以及避免复杂的特征工程。CNN可以直接使用图像的原始像素作为输入,而不必先使用SIFT等算法提取特征,减轻了使用传统算法如SVM时必需要做的大量重复、烦琐的数据预处理工作。
和SIFT等算法类似,CNN训练的模型同样对缩放、平移、旋转等畸变具有不变性,有着很强的泛化性。CNN的最大特点在于卷积的权值共享结构,可以大幅减少神经网络的参数量,防止过拟合的同时又降低了神经网络模型的复杂度。
卷积神经网络的概念最早出自19世纪60年代科学家提出的感受野(Receptive Field37)。当时科学家通过对猫的视觉皮层细胞研究发现,每一个视觉神经元只会处理一小块区域的视觉图像,即感受野。到了20世纪80年代,日本科学家提出神经认知机(Neocognitron38)的概念,可以算作是卷积网络最初的实现原型。
神经认知机中包含两类神经元,用来抽取特征的S-cells,还有用来抗形变的C-cells,其中S-cells对应我们现在主流卷积神经网络中的卷积核滤波操作,而C-cells则对应激活函数、最大池化(Max-Pooling)等操作。同时,CNN也是首个成功地进行多层训练的网络结构,即前面章节提到的LeCun的LeNet5,而全连接的网络因为参数过多及梯度弥散等问题,在早期很难顺利地进行多层的训练。
卷积神经网络可以利用空间结构关系减少需要学习的参数量,从而提高反向传播算法的训练效率。在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一个卷积操作只处理一小块图像,进行卷积变化后再传到后面的网络,每一层卷积(也可以说是滤波器)都会提取数据中最有效的特征。这种方法可以提取到图像中最基础的特征,比如不同方向的边或者拐角,而后再进行组合和抽象形成更高阶的特征,因此CNN可以应对各种情况,理论上具有对图像缩放、平移和旋转的不变性。
一般的卷积神经网络由多个卷积层构成,每个卷积层中通常会进行如下几个操作。
- 图像通过多个不同的卷积核的滤波,并加偏置(bias),提取出局部特征,每一个卷积核会映射出一个新的2D图像。
- 将前面卷积核的滤波输出结果,进行非线性的激活函数处理。目前最常见的是使用ReLU函数,而以前Sigmoid函数用得比较多。
- 对激活函数的结果再进行池化操作(即降采样,比如将2×2的图片降为1×1的图片),目前一般是使用最大池化,保留最显著的特征,并提升模型的畸变容忍能力。
一个卷积层中可以有多个不同的卷积核,而每一个卷积核都对应一个滤波后映射出的新图像,同一个新图像中每一个像素都来自完全相同的卷积核,这就是卷积核的权值共享。那我们为什么要共享卷积核的权值参数呢?答案很简单,降低模型复杂度,减轻过拟合并降低计算量。
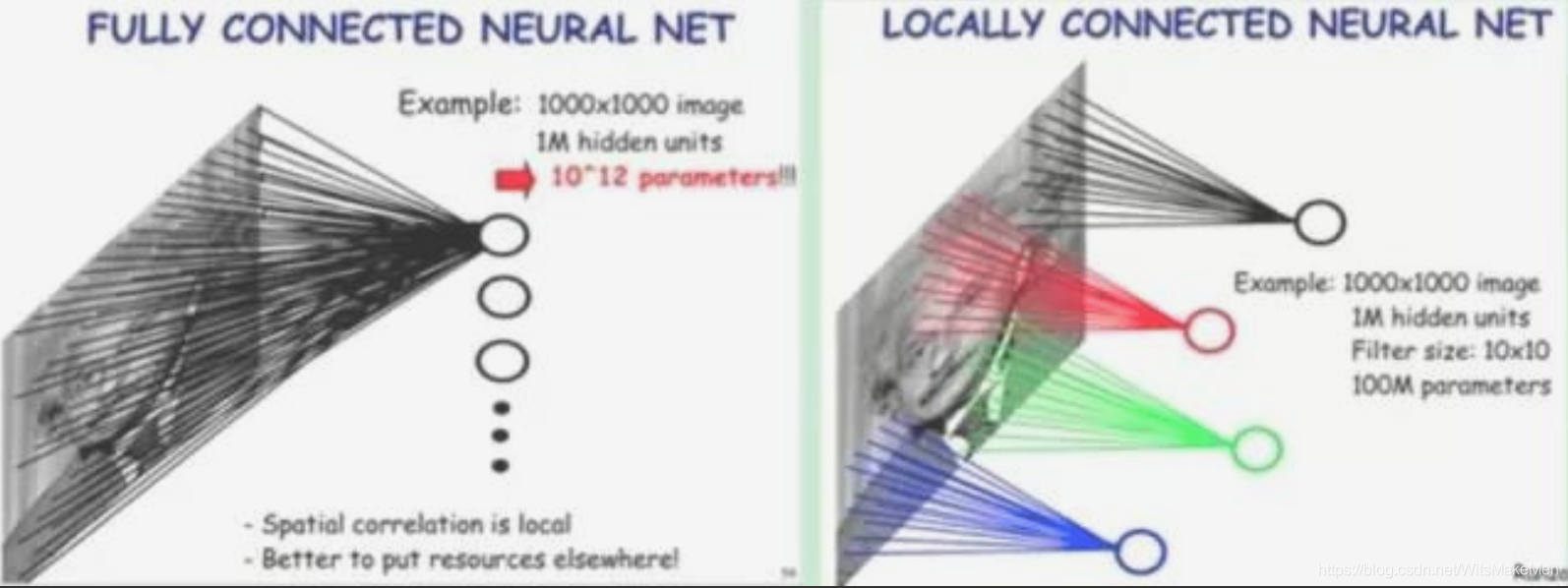
举个例子,如图5-2所示,如果我们的图像尺寸是1000像素×1000像素,并且假定是黑白图像,即只有一个颜色通道,那么一张图片就有100万个像素点,输入数据的维度也是100万。接下来,如果连接一个相同大小的隐含层(100万个隐含节点),那么将产生100万×100万=一万亿个连接。
仅仅一个全连接层(Fully Connected Layer),就有一万亿连接的权重要去训练,这已经超出了普通硬件的计算能力。我们必须减少需要训练的权重数量,一是降低计算的复杂度,二是过多的连接会导致严重的过拟合,减少连接数可以提升模型的泛化性。
图像在空间上是有组织结构的,每一个像素点在空间上和周围的像素点实际上是有紧密联系的,但是和太遥远的像素点就不一定有什么关联了。这就是前面提到的人的视觉感受野的概念,每一个感受野只接受一小块区域的信号。这一小块区域内的像素是互相关联的,每一个神经元不需要接收全部像素点的信息,只需要接收局部的像素点作为输入,而后将所有这些神经元收到的局部信息综合起来就可以得到全局的信息。
这样就可以将之前的全连接的模式修改为局部连接,之前隐含层的每一个隐含节点都和全部像素相连,现在我们只需要将每一个隐含节点连接到局部的像素节点。假设局部感受野大小是10×10,即每个隐含节点只与10×10个像素点相连,那么现在就只需要10×10×100万=1亿个连接,相比之前的1万亿缩小了10000倍。
简单说,全连接就是上图的左边部分,而局部连接就是上图的右边部分。局部连接可以大大降低神经网络参数量,从100M100M = 1万亿,到1010*100万=1亿。
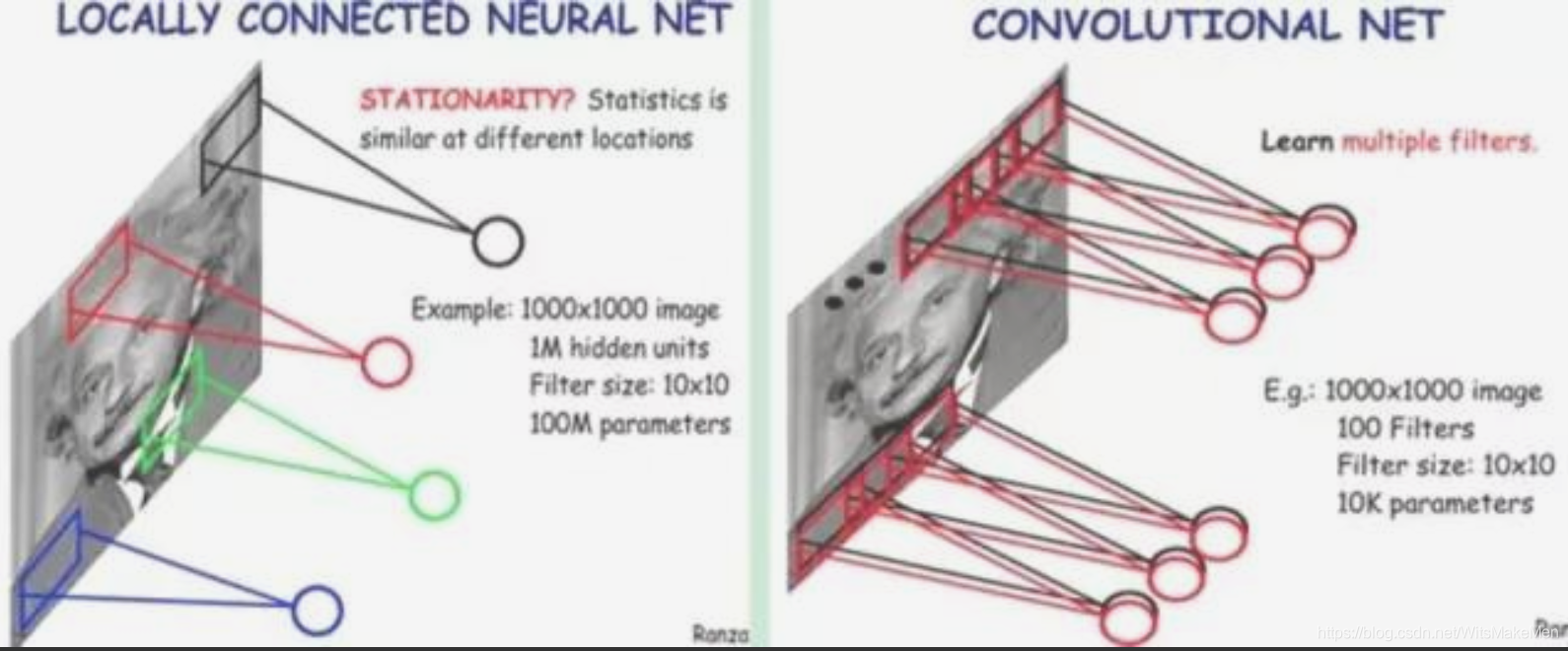
上面我们通过局部连接(Locally Connect)的方法,将连接数从1万亿降低到1亿,但仍然偏多,需要继续降低参数量。现在隐含层每一个节点都与10×10的像素相连,也就是每一个隐含节点都拥有100个参数。假设我们的局部连接方式是卷积操作,即默认每一个隐含节点的参数都完全一样,那我们的参数不再是1亿,而是100。不论图像有多大,都是这10×10=100个参数,即卷积核的尺寸,这就是卷积对缩小参数量的贡献。
简单说,卷积就是使用完全相同的(参数相同)的模板去进行局部连接,所以参数量可以继续骤降
我们不需要再担心有多少隐含节点或者图片有多大,参数量只跟卷积核的大小有关,这也就是所谓的权值共享。但是如果我们只有一个卷积核,我们就只能提取一种卷积核滤波的结果,即只能提取一种图片特征,这不是我们期望的结果。好在图像中最基本的特征很少,我们可以增加卷积核的数量来多提取一些特征。
图像中的基本特征无非就是点和边,无论多么复杂的图像都是点和边组合而成的。人眼识别物体的方式也是从点和边开始的,视觉神经元接受光信号后,每一个神经元只接受一个区域的信号,并提取出点和边的特征,然后将点和边的信号传递给后面一层的神经元,再接着组合成高阶特征,比如三角形、正方形、直线、拐角等,再继续抽象组合,得到眼睛、鼻子和嘴等五官,最后再将五官组合成一张脸,完成匹配识别。
因此我们的问题就很好解决了,只要我们提供的卷积核数量足够多,能提取出各种方向的边或各种形态的点,就可以让卷积层抽象出有效而丰富的高阶特征。每一个卷积核滤波得到的图像就是一类特征的映射,即一个Feature Map。一般来说,我们使用100个卷积核放在第一个卷积层就已经很充足了。
那这样的话,如上图所示,我们的参数量就是100×100=1万个,相比之前的1亿又缩小了10000倍。因此,依靠卷积,我们就可以高效地训练局部连接的神经网络了。卷积的好处是,不管图片尺寸如何,我们需要训练的权值数量只跟卷积核大小、卷积核数量有关,我们可以使用非常少的参数量处理任意大小的图片。每一个卷积层提取的特征,在后面的层中都会抽象组合成更高阶的特征。
我们再总结一下,卷积神经网络的要点就是局部连接(Local Connection)、权值共享(Weight Sharing)和池化层(Pooling)中的降采样(Down-Sampling)。
其中,局部连接和权值共享降低了参数量,使训练复杂度大大下降,并减轻了过拟合。同时权值共享还赋予了卷积网络对平移的容忍性,而池化层降采样则进一步降低了输出参数量,并赋予模型对轻度形变的容忍性,提高了模型的泛化能力。
卷积神经网络相比传统的机器学习算法,无须手工提取特征,也不需要使用诸如SIFT之类的特征提取算法,可以在训练中自动完成特征的提取和抽象,并同时进行模式分类,大大降低了应用图像识别的难度;相比一般的神经网络,CNN在结构上和图片的空间结构更为贴近,都是2D的有联系的结构,并且CNN的卷积连接方式和人的视觉神经处理光信号的方式类似。
下面介绍一下经典的卷积网络LeNet5。
大名鼎鼎的LeNet5 诞生于1994年,是最早的深层卷积神经网络之一,并且推动了深度学习的发展。从1988年开始,在多次成功的迭代后,这项由Yann LeCun完成的开拓性成果被命名为LeNet5。
LeCun认为,可训练参数的卷积层是一种用少量参数在图像的多个位置上提取相似特征的有效方式,这和直接把每个像素作为多层神经网络的输入不同。像素不应该被使用在输入层,因为图像具有很强的空间相关性,而使用图像中独立的像素直接作为输入则利用不到这些相关性。
LeNet5当时的特性有如下几点。
每个卷积层包含三个部分:卷积、池化和非线性激活函数
使用卷积提取空间特征
降采样(Subsample)的平均池化层(Average Pooling)
双曲正切(Tanh)或S型(Sigmoid)的激活函数
MLP作为最后的分类器
层与层之间的稀疏连接减少计算复杂度
LeNet5中的诸多特性现在依然在state-of-the-art卷积神经网络中使用,可以说LeNet5是奠定了现代卷积神经网络的基石之作。Lenet-5的结构下图所示。
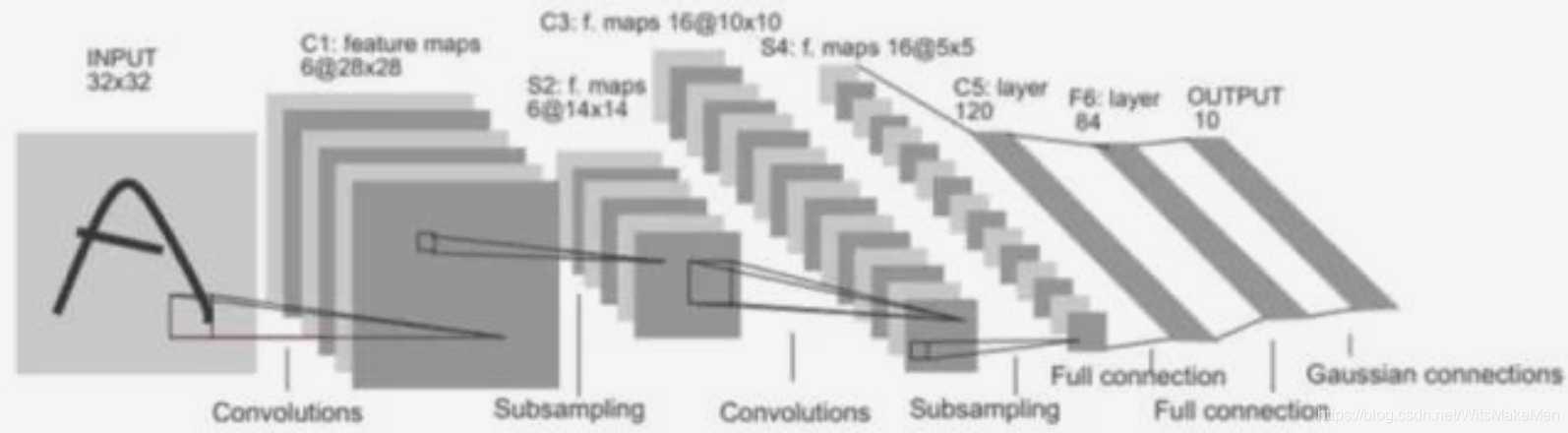
它的输入图像为32×32的灰度值图像,后面有3个卷积层,1个全连接层和1个高斯连接层。
下面我们来介绍一些其他几个经典的卷积网络结构,AlexNet、VGGNet、Google Inception Net和ResNet,这4种网络依照出现的先后顺序排列,深度和复杂度也依次递进。
它们分别获得了ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛分类项目的2012年冠军(AlexNet, top-5错误率16.4%,使用额外数据可达到15.3%,8层神经网络)、2014年亚军(VGGNet,top-5错误率7.3%,19层神经网络),2014年冠军(InceptionNet,top-5错误率6.7%,22层神经网络)和2015年的冠军(ResNet,top-5错误率3.57%,152层神经网络)。
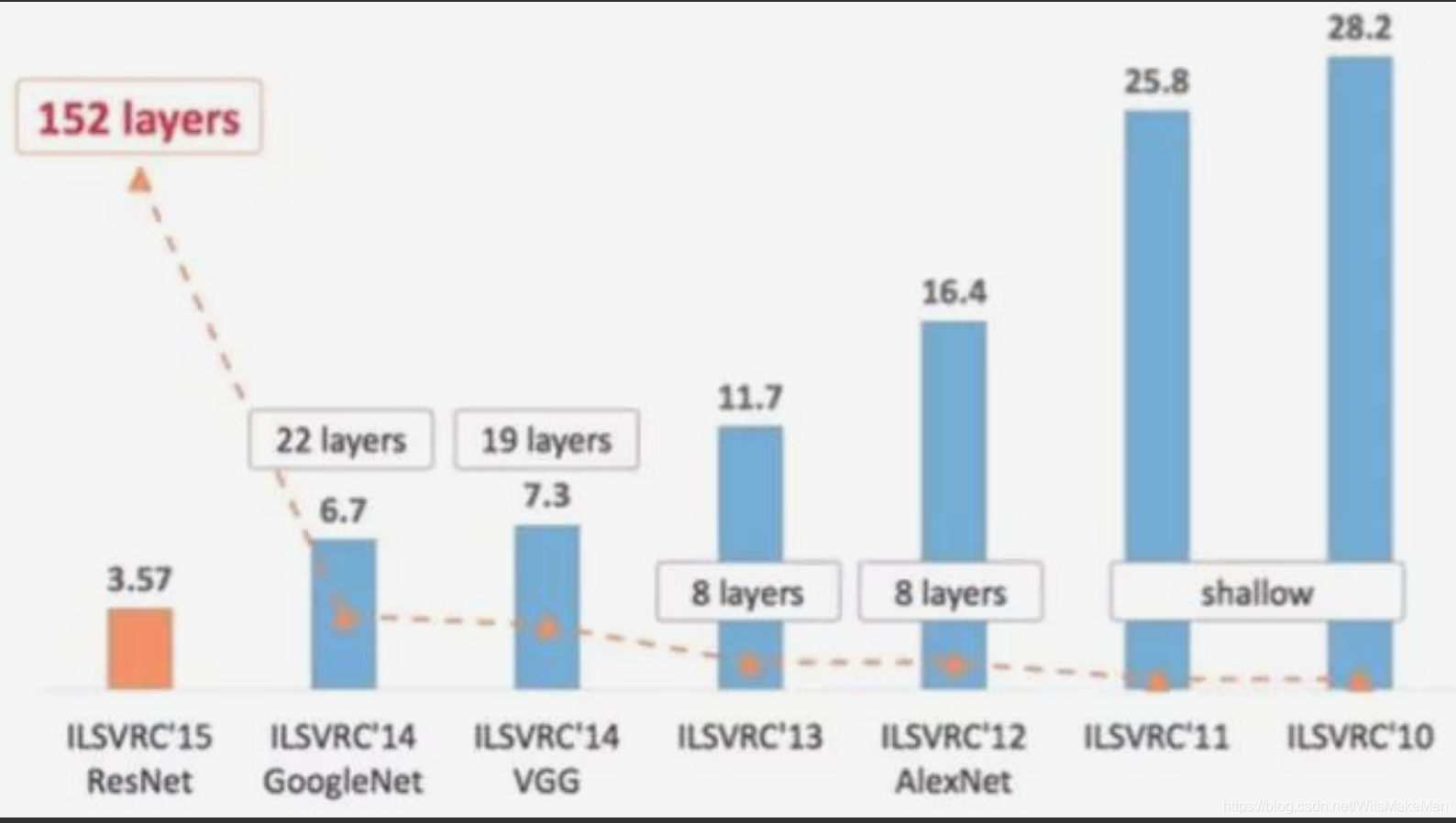
如图所示,ILSVRC的top-5错误率在最近几年取得重大突破,而主要的突破点都是在深度学习和卷积神经网络,成绩的大幅提升几乎都伴随着卷积神经网络的层数加深。

前面提到的计算机视觉比赛ILSVRC使用的数据都来自ImageNet,如上图所示。ImageNet项目于2007年由斯坦福大学华人教授李飞飞创办,目标是收集大量带有标注信息的图片数据供计算机视觉模型训练。ImageNet拥有1500万张标注过的高清图片,总共拥有22000类,其中约有100万张标注了图片中主要物体的定位边框。

每年度的ILSVRC比赛数据集中大概拥有120万张图片,以及1000类的标注,是ImageNet全部数据的一个子集。比赛一般采用top-5和top-1分类错误率作为模型性能的评测指标,上图所示为AlexNet识别ILSVRC数据集中图片的情况,每张图片下面是分类预测得分最高的5个分类及其分值。
原文链接:














 59万+
59万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









