







python_Lasso _线性模型_L1 正则化
Lasso。与岭回归相同,使用 lasso 也是约束系 # 数使其接近于 0,但用到的方法不同,叫作 L1 正则化。
L1 正则化的结果是,使用 lasso 时 某些系数刚好为 0
这样模型更容易解释,也可以呈现模型最重要的特征
# 4. lasso
# 除了 Ridge,还有一种正则化的线性回归是 Lasso。与岭回归相同,使用 lasso 也是约束系
# 数使其接近于 0,但用到的方法不同,叫作 L1 正则化。8 L1 正则化的结果是,使用 lasso 时
# 某些系数刚好为 0。这说明某些特征被模型完全忽略。这可以看作是一种自动化的特征选
# 择。某些系数刚好为 0,这样模型更容易解释,也可以呈现模型最重要的特征
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso.score(X_test, y_test)))
print("Number of features used: {}".format(np.sum(lasso.coef_ != 0)))
Training set score: 0.29
Test set score: 0.21
Number of features used: 4
# 如你所见, Lasso 在训练集与测试集上的表现都很差。这表示存在欠拟合,我们发现模型
# 只用到了 105 个特征中的 4 个。与 Ridge 类似, Lasso 也有一个正则化参数 alpha,可以控
# 制系数趋向于 0 的强度。在上一个例子中,我们用的是默认值 alpha=1.0。为了降低欠拟
# 合,我们尝试减小 alpha。这么做的同时,我们还需要增加 max_iter 的值(运行迭代的最
# 大次数):
# we increase the default setting of "max_iter",
# otherwise the model would warn us that we should increase max_iter.
lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso001.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso001.score(X_test, y_test)))
print("Number of features used: {}".format(np.sum(lasso001.coef_ != 0)))
Training set score: 0.90
Test set score: 0.77
Number of features used: 33
# alpha 值变小,我们可以拟合一个更复杂的模型,在训练集和测试集上的表现也更好。模
# 型性能比使用 Ridge 时略好一点,而且我们只用到了 105 个特征中的 33 个。这样模型可能
# 更容易理解。
# 但如果把 alpha 设得太小,那么就会消除正则化的效果,并出现过拟合,得到与
# LinearRegression 类似的结果:
lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso00001.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso00001.score(X_test, y_test)))
print("Number of features used: {}".format(np.sum(lasso00001.coef_ != 0)))
Training set score: 0.95
Test set score: 0.64
Number of features used: 96
# 查看学习曲线
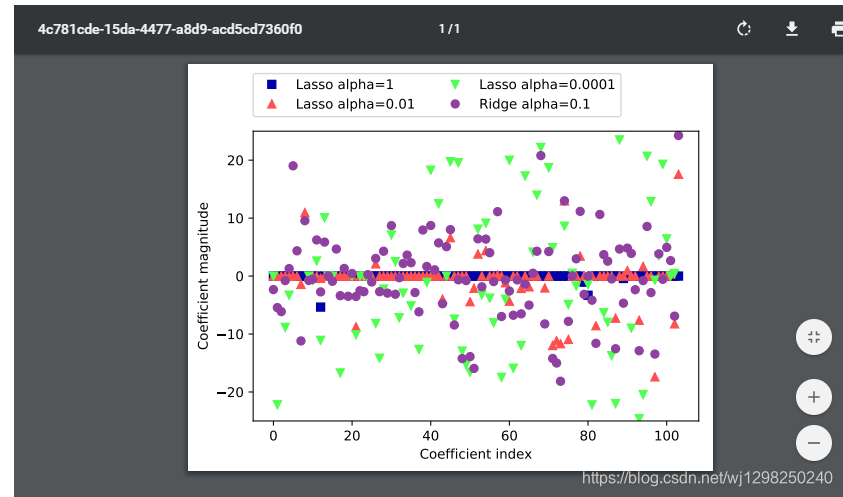
plt.plot(lasso.coef_, 's', label="Lasso alpha=1")
plt.plot(lasso001.coef_, '^', label="Lasso alpha=0.01")
plt.plot(lasso00001.coef_, 'v', label="Lasso alpha=0.0001")
plt.plot(ridge01.coef_, 'o', label="Ridge alpha=0.1")
plt.legend(ncol=2, loc=(0, 1.05))
plt.ylim(-25, 25)
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")
# 在 alpha=1 时,我们发现不仅大部分系数都是 0(我们已经知道这一点),而且其他系
# 数也都很小。将 alpha 减小至 0.01,我们得到图中向上的三角形,大部分特征等于 0。
# alpha=0.0001 时,我们得到正则化很弱的模型,大部分系数都不为 0,并且还很大。为
# 了便于比较,图中用圆形表示 Ridge 的最佳结果。 alpha=0.1 的 Ridge 模型的预测性能与
# alpha=0.01 的 Lasso 模型类似,但 Ridge 模型的所有系数都不为 0。
# 在实践中,在两个模型中一般首选岭回归。但如果特征很多,你认为只有其中几个是重要
# 的,那么选择 Lasso 可能更好。同样,如果你想要一个容易解释的模型, Lasso 可以给出
# 更容易理解的模型,因为它只选择了一部分输入特征。 scikit-learn 还提供了 ElasticNet
# 类,结合了 Lasso 和 Ridge 的惩罚项。在实践中,这种结合的效果最好,不过代价是要调
# 节两个参数:一个用于 L1 正则化,一个用于 L2 正则化。
Text(0,0.5,'Coefficient magnitude')














 4665
4665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









