









爬取豆瓣榜单遇到403错误
如图
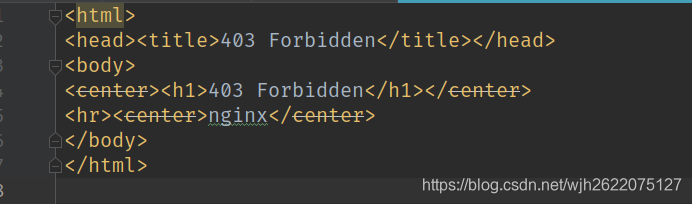
解决方法:
在setting.py中添加user agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
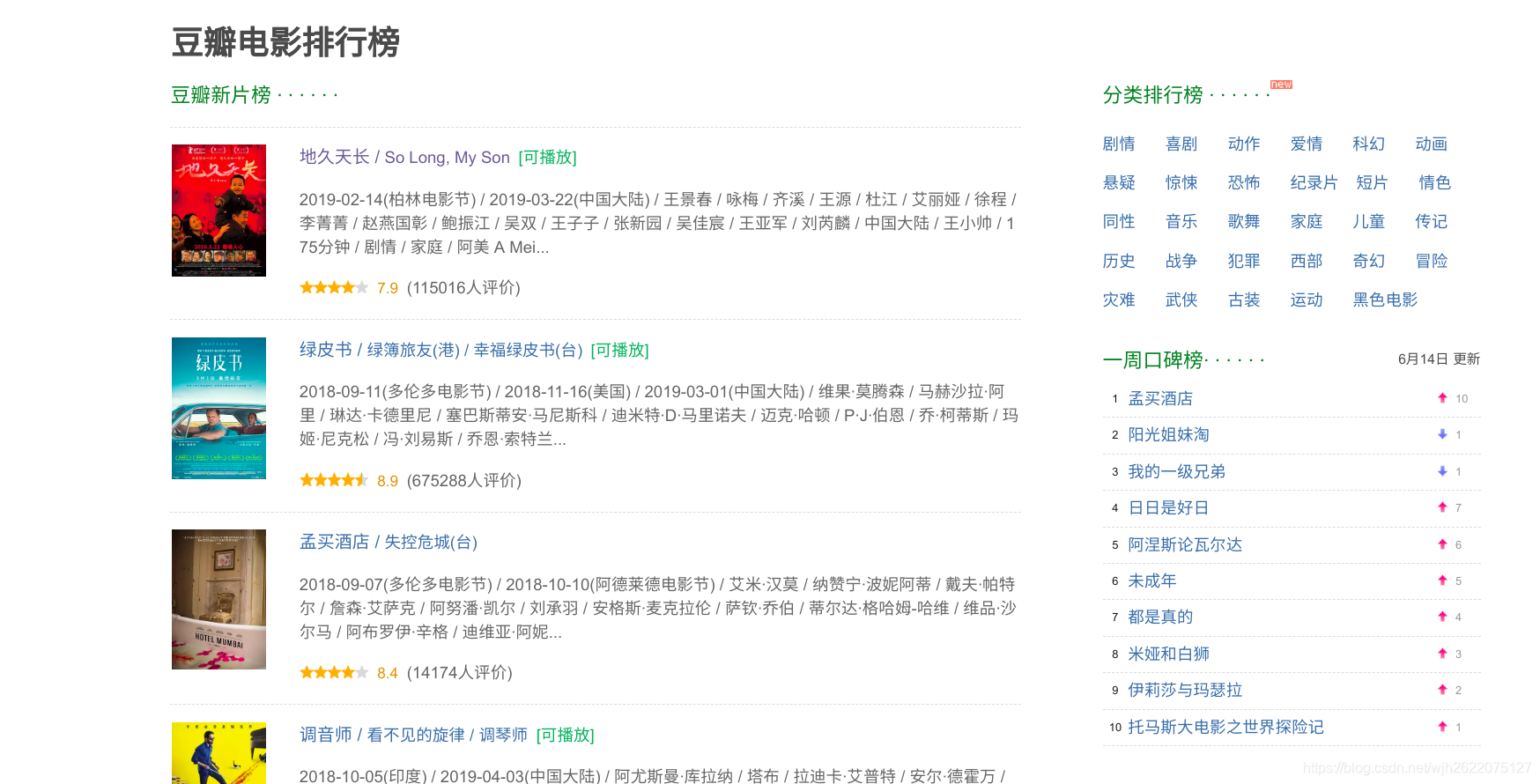
爬取成功
效果
这是新片榜
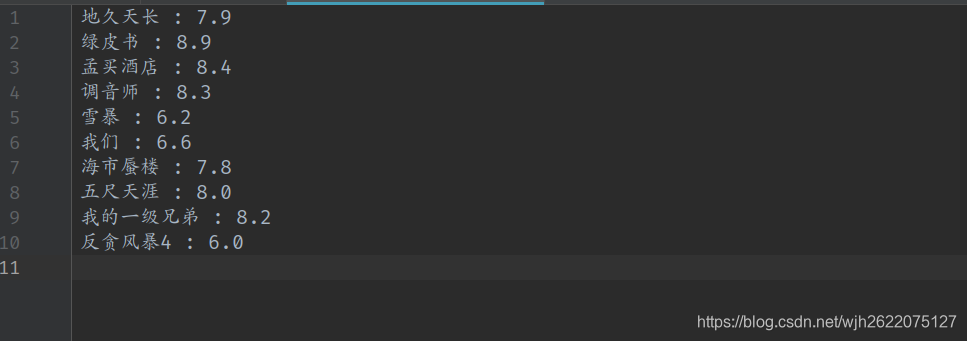
爬取结果
元素选择
使用xpath进行元素选择.
from lxml import etree
html = etree.parse('./douban.html', etree.HTMLParser())
result = html.xpath('//tr/td/a/@title') # 获取a节点的title属性
# result = html.xpath('//tr/td/a[@class='test']') # 获取a节点且class为test的元素
print(result)
test2 = html.xpath('//div[@class="star clearfix"]/span[@class="rating_nums"]/text()')
print(test2)
代码
scrapy对url的爬取可以并行的, 也就是说第二个url不用等第一个爬完, 也不会相互影响.
建立scrapy项目之后, 在spiders目录下新建自己的爬虫代码py文件.
写好后, 使用命令scrapy crawl douban_chat执行
代码如下
import scrapy
import re
class QuotesSpider(scrapy.Spider):
name = "douban_chat" # 爬虫名字, 在命令行下会用到
def start_requests(self):
urls = [
'https://movie.douban.com/chart',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# xpath 选择器 + 正则表达式找出电影标题和评分
titles_raw = response.xpath('//div/table/tr').getall()
titles = ""
for each in titles_raw:
try:
title = re.findall(r'title="(.+)">', each)[0]
score = re.findall(r'rating_nums">(.+)</span>', each)[0]
titles += title + " : " + score + '\n'
except:
pass
page = response.url.split("/")[-2]
filename = '%s.html' % page
with open(filename, 'w+', encoding='utf-8') as f:
f.write(titles)
self.log('Saved file %s' % filename)














 4021
4021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









