







文章目录
被视为“缺失”的值
pandas使用不同的标记值来表示缺失(也称为NA),具体取决于数据类型。
对于NumPy数据类型,使用numpy.nan。使用NumPy数据类型的缺点是原始数据类型将被强制转换为np.float64或object。
pd.Series([1, 2], dtype=np.int64).reindex([0, 1, 2])
Out[1]:
0 1.0
1 2.0
2 NaN
dtype: float64
pd.Series([True, False], dtype=np.bool_).reindex([0, 1, 2])
Out[2]:
0 True
1 False
2 NaN
dtype: object
对于NumPy的np.datetime64,np.timedelta64和PeriodDtype,使用NaT。对于类型应用,使用api.types.NaTType。
pd.Series([1, 2], dtype=np.dtype("timedelta64[ns]")).reindex([0, 1, 2])
Out[3]:
0 0 days 00:00:00.000000001
1 0 days 00:00:00.000000002
2 NaT
dtype: timedelta64[ns]
pd.Series([1, 2], dtype=np.dtype("datetime64[ns]")).reindex([0, 1, 2])
Out[4]:
0 1970-01-01 00:00:00.000000001
1 1970-01-01 00:00:00.000000002
2 NaT
dtype: datetime64[ns]
pd.Series(["2020", "2020"], dtype=pd.PeriodDtype("D")).reindex([0, 1, 2])
Out[5]:
0 2020-01-01
1 2020-01-01
2 NaT
dtype: period[D]
对于StringDtype,Int64Dtype(和其他位宽),Float64Dtype(和其他位宽),BooleanDtype和ArrowDtype,使用NA。这些类型将保持数据的原始数据类型。对于类型应用,使用api.types.NAType。
pd.Series([1, 2], dtype="Int64").reindex([0, 1, 2])
Out[6]:
0 1
1 2
2 <NA>
dtype: Int64
pd.Series([True, False], dtype="boolean[pyarrow]").reindex([0, 1, 2])
Out[7]:
0 True
1 False
2 <NA>
dtype: bool[pyarrow]
要检测这些缺失值,可以使用isna()或notna()方法。
ser = pd.Series([pd.Timestamp("2020-01-01"), pd.NaT])
ser
Out[9]:
0 2020-01-01
1 NaT
dtype: datetime64[ns]
pd.isna(ser)
Out[10]:
0 False
1 True
dtype: bool
注意
ser = pd.Series([1, None], dtype=object)
ser
Out[12]:
0 1
1 None
dtype: object
pd.isna(ser)
Out[13]:
0 False
1 True
dtype: bool
警告
None == None # noqa: E711
Out[14]: True
np.nan == np.nan
Out[15]: False
pd.NaT == pd.NaT
Out[16]: False
pd.NA == pd.NA
Out[17]: <NA>
因此,使用这些缺失值之一与DataFrame或Series进行相等比较不会提供与isna()或notna()相同的信息。
ser = pd.Series([True, None], dtype="boolean[pyarrow]")
ser == pd.NA
Out[19]:
0 <NA>
1 <NA>
dtype: bool[pyarrow]
pd.isna(ser)
Out[20]:
0 False
1 True
dtype: bool
NA的语义
警告
实验性的:NA的行为仍可能会发生变化。
从pandas 1.0开始,提供了一个实验性的NA值(单例)来表示标量缺失值。NA的目标是提供一种可以在各种数据类型中一致使用的“缺失”指示器(而不是根据数据类型使用np.nan,None或pd.NaT)。
例如,在具有可空整数dtype的Series中存在缺失值时,它将使用NA:
s = pd.Series([1, 2, None], dtype="Int64")
s
Out[22]:
0 1
1 2
2 <NA>
dtype: Int64
s[2]
Out[23]: <NA>
s[2] is pd.NA
Out[24]: True
目前,pandas尚未默认使用这些使用NA的数据类型的DataFrame或Series,因此需要显式指定dtype。在转换部分中解释了将其转换为这些数据类型的简单方法。
算术和比较运算中的传播
通常情况下,缺失值在涉及NA的操作中传播。当操作数之一未知时,操作的结果也是未知的。
例如,NA在算术运算中传播,类似于np.nan:
pd.NA + 1
Out[25]: <NA>
"a" * pd.NA
Out[26]: <NA>
在一些特殊情况下,即使其中一个操作数是NA,结果也是已知的。
pd.NA ** 0
Out[27]: 1
1 ** pd.NA
Out[28]: 1
在相等和比较运算中,NA也会传播。这与np.nan的行为不同,其中与np.nan的比较始终返回False。
pd.NA == 1
Out[29]: <NA>
pd.NA == pd.NA
Out[30]: <NA>
pd.NA < 2.5
Out[31]: <NA>
pd.isna(pd.NA)
Out[32]: True
注意
这个基本传播规则的一个例外是缩减(例如平均值或最小值),pandas默认跳过缺失值。有关更多信息,请参见计算部分。
逻辑运算
对于逻辑运算,NA遵循三值逻辑(或Kleene逻辑,类似于R、SQL和Julia)。这种逻辑意味着只有在逻辑上需要时才传播缺失值。
例如,对于逻辑“或”运算(|),如果其中一个操作数为True,我们已经知道结果将为True,而不管另一个值是True还是False(因此无论缺失值是True还是False)。在这种情况下,NA不会传播:
True | False
Out[33]: True
True | pd.NA
Out[34]: True
pd.NA | True
Out[35]: True
另一方面,如果其中一个操作数为False,结果取决于另一个操作数的值。因此,在这种情况下,NA会传播:
False | True
Out[36]: True
False | False
Out[37]: False
False | pd.NA
Out[38]: <NA>
逻辑“与”运算(&)的行为可以使用类似的逻辑推导出来(其中现在如果其中一个操作数已经是False,NA将不会传播):
False & True
Out[39]: False
False & False
Out[40]: False
False & pd.NA
Out[41]: False
True & True
Out[42]: True
True & False
Out[43]: False
True & pd.NA
Out[44]: <NA>
在布尔上下文中的NA
由于NA的实际值是未知的,将NA转换为布尔值是模棱两可的。
bool(pd.NA)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[45], line 1
----> 1 bool(pd.NA)
File missing.pyx:392, in pandas._libs.missing.NAType.__bool__()
TypeError: boolean value of NA is ambiguous
这也意味着NA不能在被评估为布尔值的上下文中使用,例如if condition: ...,其中condition可能是NA。在这种情况下,可以使用isna()来检查NA或避免condition为NA,例如通过事先填充缺失值。
NumPy 通用函数
pandas.NA 实现了 NumPy 的 __array_ufunc__ 协议。大多数通用函数都可以处理 NA,并且通常返回 NA:
np.log(pd.NA)
Out[46]: <NA>
np.add(pd.NA, 1)
Out[47]: <NA>
警告
目前,涉及 ndarray 和 NA 的通用函数将返回一个填充有 NA 值的 object-dtype 数组。
a = np.array([1, 2, 3])
np.greater(a, pd.NA)
Out[49]: array([<NA>, <NA>, <NA>], dtype=object)
这里的返回类型可能会在将来改变,返回不同的数组类型。
有关更多关于通用函数的信息,请参见 DataFrame 与 NumPy 函数的互操作性。
转换
如果你有一个使用 np.nan 的 DataFrame 或 Series,可以使用 DataFrame.convert_dtypes() 和 Series.convert_dtypes() 在 DataFrame 中将数据转换为使用 NA 的数据类型,例如 Int64Dtype 或 ArrowDtype。这在从 IO 方法读取数据集后,推断数据类型时特别有用。
在这个例子中,虽然所有列的数据类型都发生了变化,但我们只展示前 10 列的结果。
import io
data = io.StringIO("a,b\n,True\n2,")
df = pd.read_csv(data)
df.dtypes
Out[53]:
a float64
b object
dtype: object
df_conv = df.convert_dtypes()
df_conv
Out[55]:
a b
0 <NA> True
1 2 <NA>
df_conv.dtypes
Out[56]:
a Int64
b boolean
dtype: object
插入缺失数据
你可以通过简单地赋值给 Series 或 DataFrame 来插入缺失值。缺失值的标记将根据数据类型选择。
ser = pd.Series([1., 2., 3.])
ser.loc[0] = None
ser
Out[59]:
0 NaN
1 2.0
2 3.0
dtype: float64
ser = pd.Series([pd.Timestamp("2021"), pd.Timestamp("2021")])
ser.iloc[0] = np.nan
ser
Out[62]:
0 NaT
1 2021-01-01
dtype: datetime64[ns]
ser = pd.Series([True, False], dtype="boolean[pyarrow]")
ser.iloc[0] = None
ser
Out[65]:
0 <NA>
1 False
dtype: bool[pyarrow]
对于 object 类型,pandas 将使用给定的值:
s = pd.Series(["a", "b", "c"], dtype=object)
s.loc[0] = None
s.loc[1] = np.nan
s
Out[69]:
0 None
1 NaN
2 c
dtype: object
使用缺失数据进行计算
缺失值会在 pandas 对象之间的算术运算中传播。
ser1 = pd.Series([np.nan, np.nan, 2, 3])
ser2 = pd.Series([np.nan, 1, np.nan, 4])
ser1
Out[72]:
0 NaN
1 NaN
2 2.0
3 3.0
dtype: float64
ser2
Out[73]:
0 NaN
1 1.0
2 NaN
3 4.0
dtype: float64
ser1 + ser2
Out[74]:
0 NaN
1 NaN
2 NaN
3 7.0
dtype: float64
在 数据结构概述(列出在 这里 和 这里)中讨论的描述性统计和计算方法都会考虑到缺失数据。
在求和数据时,NA 值或空数据将被视为零。
pd.Series([np.nan]).sum()
Out[75]: 0.0
pd.Series([], dtype="float64").sum()
Out[76]: 0.0
在取乘积时,NA 值或空数据将被视为 1。
pd.Series([np.nan]).prod()
Out[77]: 1.0
pd.Series([], dtype="float64").prod()
Out[78]: 1.0
累积方法,如 cumsum() 和 cumprod(),默认情况下会忽略 NA 值,并在结果中保留它们。可以使用 skipna 参数更改此行为。
ser = pd.Series([1, np.nan, 3, np.nan])
ser
Out[80]:
0 1.0
1 NaN
2 3.0
3 NaN
dtype: float64
ser.cumsum()
Out[81]:
0 1.0
1 NaN
2 4.0
3 NaN
dtype: float64
ser.cumsum(skipna=False)
Out[82]:
0 1.0
1 NaN
2 NaN
3 NaN
dtype: float64
删除缺失数据
dropna() 可以删除具有缺失数据的行或列。
df = pd.DataFrame([[np.nan, 1, 2], [1, 2, np.nan], [1, 2, 3]])
df
Out[84]:
0 1 2
0 NaN 1 2.0
1 1.0 2 NaN
2 1.0 2 3.0
df.dropna()
Out[85]:
0 1 2
2 1.0 2 3.0
df.dropna(axis=1)
Out[86]:
1
0 1
1 2
2 2
ser = pd.Series([1, pd.NA], dtype="int64[pyarrow]")
ser.dropna()
Out[88]:
0 1
dtype: int64[pyarrow]
填充缺失数据
使用值填充
fillna() 用非 NA 数据替换 NA 值。
使用标量值替换 NA
data = {"np": [1.0, np.nan, np.nan, 2], "arrow": pd.array([1.0, pd.NA, pd.NA, 2], dtype="float64[pyarrow]")}
df = pd.DataFrame(data)
df
Out[91]:
np arrow
0 1.0 1.0
1 NaN <NA>
2 NaN <NA>
3 2.0 2.0
df.fillna(0)
Out[92]:
np arrow
0 1.0 1.0
1 0.0 0.0
2 0.0 0.0
3 2.0 2.0
向前或向后填充缺失值
df.ffill()
Out[93]:
np arrow
0 1.0 1.0
1 1.0 1.0
2 1.0 1.0
3 2.0 2.0
df.bfill()
Out[94]:
np arrow
0 1.0 1.0
1 2.0 2.0
2 2.0 2.0
3 2.0 2.0
限制填充的 NA 值数量
df.ffill(limit=1)
Out[95]:
np arrow
0 1.0 1.0
1 1.0 1.0
2 NaN <NA>
3 2.0 2.0
NA 值可以用与原始对象和填充对象之间的索引和列对齐的 Series 或 DataFrame 中的相应值替换。
dff = pd.DataFrame(np.arange(30, dtype=np.float64).reshape(10, 3), columns=list("ABC"))
dff.iloc[3:5, 0] = np.nan
dff.iloc[4:6, 1] = np.nan
dff.iloc[5:8, 2] = np.nan
dff
Out[100]:
A B C
0 0.0 1.0 2.0
1 3.0 4.0 5.0
2 6.0 7.0 8.0
3 NaN 10.0 11.0
4 NaN NaN 14.0
5 15.0 NaN NaN
6 18.0 19.0 NaN
7 21.0 22.0 NaN
8 24.0 25.0 26.0
9 27.0 28.0 29.0
dff.fillna(dff.mean())
Out[101]:
A B C
0 0.00 1.0 2.000000
1 3.00 4.0 5.000000
2 6.00 7.0 8.000000
3 14.25 10.0 11.000000
4 14.25 14.5 14.000000
5 15.00 14.5 13.571429
6 18.00 19.0 13.571429
7 21.00 22.0 13.571429
8 24.00 25.0 26.000000
9 27.00 28.0 29.000000
注意
DataFrame.where() 也可以用于填充 NA 值。与上面的结果相同。
dff.where(pd.notna(dff), dff.mean(), axis="columns")
Out[102]:
A B C
0 0.00 1.0 2.000000
1 3.00 4.0 5.000000
2 6.00 7.0 8.000000
3 14.25 10.0 11.000000
4 14.25 14.5 14.000000
5 15.00 14.5 13.571429
6 18.00 19.0 13.571429
7 21.00 22.0 13.571429
8 24.00 25.0 26.000000
9
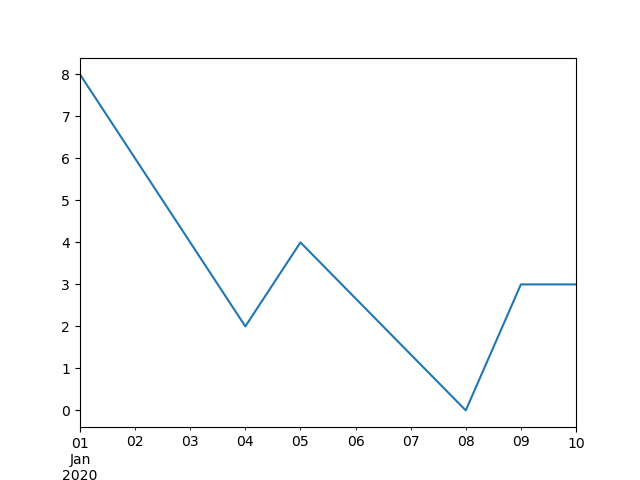
在 [`DatetimeIndex`](https://pandas.pydata.org/docs/reference/api/pandas.DatetimeIndex.html#pandas.DatetimeIndex) 中,相对于 [`Timestamp`](https://pandas.pydata.org/docs/reference/api/pandas.Timestamp.html#pandas.Timestamp) 的插值可以通过设置 `method="time"` 来实现。
```python
ts2 = ts.iloc[[0, 1, 3, 7, 9]]
ts2
Out[115]:
2020-01-01 8.0
2020-01-02 NaN
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 NaN
dtype: float64
ts2.interpolate()
Out[116]:
2020-01-01 8.0
2020-01-02 5.0
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 0.0
dtype: float64
ts2.interpolate(method="time")
Out[117]:
2020-01-01 8.0
2020-01-02 6.0
2020-01-04 2.0
2020-01-08 0.0
2020-01-10 0.0
dtype: float64
对于浮点索引,使用 method='values':
idx = [0.0, 1.0, 10.0]
ser = pd.Series([0.0, np.nan, 10.0], idx)
ser
Out[120]:
0.0 0.0
1.0 NaN
10.0 10.0
dtype: float64
ser.interpolate()
Out[121]:
0.0 0.0
1.0 5.0
10.0 10.0
dtype: float64
ser.interpolate(method="values")
Out[122]:
0.0 0.0
1.0 1.0
10.0 10.0
dtype: float64
如果已安装 scipy,可以将 1-d 插值方法的名称传递给 method 参数,如 scipy 插值文档中所述 documentation 和参考 guide。适当的插值方法将取决于数据类型。
提示
如果处理的时间序列以递增的速率增长,请使用 method='barycentric'。
如果有近似累积分布函数的值,请使用 method='pchip'。
要填充缺失值以实现平滑绘图,请使用 method='akima'。
df = pd.DataFrame(
{
"A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
"B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
}
)
df
Out[124]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
df.interpolate(method="barycentric")
Out[125]:
A B
0 1.00 0.250
1 2.10 -7.660
2 3.53 -4.515
3 4.70 4.000
4 5.60 12.200
5 6.80 14.400
df.interpolate(method="pchip")
Out[126]:
A B
0 1.00000 0.250000
1 2.10000 0.672808
2 3.43454 1.928950
3 4.70000 4.000000
4 5.60000 12.200000
5 6.80000 14.400000
df.interpolate(method="akima")
Out[127]:
A B
0 1.000000 0.250000
1 2.100000 -0.873316
2 3.406667 0.320034
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
在使用多项式或样条逼近进行插值时,还必须指定逼近的次数或阶数:
df.interpolate(method="spline", order=2)
Out[128]:
A B
0 1.000000 0.250000
1 2.100000 -0.428598
2 3.404545 1.206900
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
df.interpolate(method="polynomial", order=2)
Out[129]:
A B
0 1.000000 0.250000
1 2.100000 -2.703846
2 3.451351 -1.453846
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
比较几种方法。
np.random.seed(2)
ser = pd.Series(np.arange(1, 10.1, 0.25) ** 2 + np.random.randn(37))
missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
ser.iloc[missing] = np.nan
methods = ["linear", "quadratic", "cubic"]
df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
df.plot()
Out[136]: <Axes: >

使用 Series.reindex() 从扩展数据中插值新观测值。
ser = pd.Series(np.sort(np.random.uniform(size=100)))
# 在 new_index 上插值
new_index = ser.index.union(pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75]))
interp_s = ser.reindex(new_index).interpolate(method="pchip")
interp_s.loc[49:51]
Out[140]:
49.00 0.471410
49.25 0.476841
49.50 0.481780
49.75 0.485998
50.00 0.489266
50.25 0.491814
50.50 0.493995
50.75 0.495763
51.00 0.497074
dtype: float64
插值限制
interpolate() 接受一个 limit 关键字参数,用于限制自上次有效观测以来填充的连续 NaN 值的数量。
ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13, np.nan, np.nan])
ser
Out[142]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
ser.interpolate()
Out[143]:
0 NaN
1 NaN
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
ser.interpolate(limit=1)
Out[144]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 NaN
6 13.0
7 13.0
8 NaN
dtype: float64
默认情况下,NaN 值是向前填充的。使用 limit_direction 参数可以向 backward 或 both 方向填充。
ser.interpolate(limit=1, limit_direction="backward")
Out[145]:
0 NaN
1 5.0
2 5.0
3 NaN
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
ser.interpolate(limit=1, limit_direction="both")
Out[146]:
0 NaN
1 5.0
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 13.0
8 NaN
dtype: float64
ser.interpolate(limit_direction="both")
Out[147]:
0 5.0
1 5.0
2 5.0
3 7.0
4 9.0
5 11.0
6 13.0
7 13.0
8 13.0
dtype: float64
默认情况下,NaN 值是填充的,无论它们是否被现有有效值包围或超出现有有效值。limit_area 参数将填充限制为内部或外部值。
# 在两个方向上填充一个连续的内部值
ser.interpolate(limit_direction="both", limit_area="inside", limit=1)
Out[148]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
dtype: float64
# 向后填充所有连续的外部值
ser.interpolate(limit_direction="backward", limit_area="outside")
Out[149]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
dtype: float64
# 在两个方向上填充所有连续的外部值
ser.interpolate(limit_direction="both", limit_area="outside")
Out[150]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
dtype: float64
替换值
Series.replace() 和 DataFrame.replace() 可以像 Series.fillna() 和 DataFrame.fillna() 一样用于替换或插入缺失值。
df = pd.DataFrame(np.eye(3))
df
Out[152]:
0 1 2
0 1.0 0.0 0.0
1 0.0 1.0 0.0
2 0.0 0.0 1.0
df_missing = df.replace(0, np.nan)
df_missing
Out[154]:
0 1 2
0 1.0 NaN NaN
1 NaN 1.0 NaN
2 NaN NaN 1.0
df_filled = df_missing.replace(np.nan, 2)
df_filled
Out[156]:
0 1 2
0 1.0 2.0 2.0
1 2.0 1.0 2.0
2 2.0 2.0 1.0
可以通过传递一个列表来替换多个值。
df_filled.replace([1, 44], [2, 28])
Out[157]:
0 1 2
0 2.0 2.0 2.0
1 2.0 2.0 2.0
2 2.0 2.0 2.0
使用映射字典进行替换。
df_filled.replace({1: 44, 2: 28})
Out[158]:
0 1 2
0 44.0 28.0 28.0
1 28.0 44.0 28.0
2 28.0 28.0 44.0
正则表达式替换
注意
以 r 字符为前缀的 Python 字符串,如 r'hello world',是“原始”字符串。它们在反斜杠方面具有与没有此前缀的字符串不同的语义。原始字符串中的反斜杠将被解释为转义的反斜杠,例如 r'\' == '\\'。
用 NaN 替换 ‘.’。
d = {"a": list(range(4)), "b": list("ab.."), "c": ["a", "b", np.nan, "d"]}
df = pd.DataFrame(d)
df.replace(".", np.nan)
Out[161]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
用正则表达式替换 ‘.’,并删除周围的空格。
df.replace(r"\s*\.\s*", np.nan, regex=True)
Out[162]:
a b c
0 0 a a
1
所有的正则表达式示例也可以通过to_replace参数作为regex参数传递。在这种情况下,必须显式地通过名称传递value参数,或者regex必须是一个嵌套字典。
df.replace(regex=[r"\s*\.\s*", r"a|b"], value="placeholder")
Out[169]:
a b c
0 0 placeholder placeholder
1 1 placeholder placeholder
2 2 placeholder NaN
3 3 placeholder d
注意
来自re.compile的正则表达式对象也是有效的输入。
Pandas 2 使用指南导读
Pandas 2 使用指南:4、IO工具(文本、CSV、HDF5等)
Pandas 2 使用指南:8、写时复制(Copy-on-Write,CoW)
Pandas 2 使用指南:10、重塑和透视表ReShapingand Pivot Tables
Pandas 2 使用指南:11、处理文本数据 Working with text data
Pandas 2 使用指南:12、处理缺失数据Working with missing data
Pandas 2 使用指南: 13、重复标签 Duplicate Labels
Pandas 2 使用指南:14、分类数据 Categorical data
Pandas 2 使用指南:15、可空整数数据类型、可空布尔数据类型
Pandas 2 使用指南:18、Groupby:拆分-应用-合并 split-apply-combine
Pandas 2 使用指南:19、窗口操作 Windowing operations
Pandas 2 使用指南:20、时间序列/日期功能
Pandas 2 使用指南:21、时间差 Timedelta
Pandas 2 使用指南:23、提升性能 Enhancing performance
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











