







1读写CSV文件
- 原始CSV文件数据
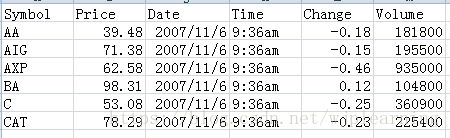
图1:股票数据stocks.csv
2将股票数据读取为元组序列
代码:
import csv
with open('stocks.csv') as f:
f_csv = csv.reader(f)
headers = next(f_csv)
print(headers)
for row in f_csv:
print(row)# type:list
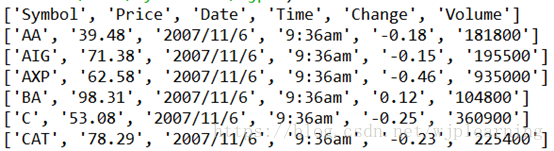
读取出第一行为headers,剩下一行一行读取为一个个list。可以用切片来进行选择自己想要的数据。但是:使用元组切片时候很可能混乱,下面提供了另一种可能的方案。
3命名元组
代码:
from collections import namedtuple
with open('stocks.csv') as f:
f_csv = csv.reader(f)
headings = next(f_csv)
Row = namedtuple('Row', headings)
for r in f_csv:
row = Row(*r)
print(row.Symbol, row)# 可直接通过row.Date等获取相应的元素。

4将数据读取为字典列表
代码:
with open('stocks.csv') as f:
f_csv = csv.DictReader(f)
for row in f_csv:
print(row['Symbol'], row)
注:第一列需要时表头,这样可以像字典一样通过表头关键字获取对应行的元素。

5写入CSV文件
数据格式1:
headers = ['Symbol', 'Price', 'Date', 'Time', 'Change', 'Volume']
rows = [('AA', 39.12, '2017/07/07', '9:36am', -0.18, 181800),
('AB', 49.12, '2017/07/07', '9:36am', -0.48, 281800),
('AC', 319.12, '2017/07/07', '9:36am', -0.28, 481800)]
with open('wstocks.csv', 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)# 写入一行
f_csv.writerows(rows)# 一次性写入多行
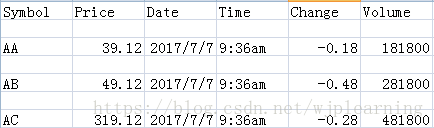
数据格式2:
headers = ['Symbol', 'Price', 'Date', 'Time', 'Change', 'Volume']
rows = [{'Symbol':'AA', 'Price':39.12, 'Date':'2017/07/07',
'Time':'9:36am', 'Change':-0.18, 'Volume':181800},
{'Symbol':'AB', 'Price':49.12, 'Date':'2017/07/07',
'Time':'9:36am', 'Change':-0.48, 'Volume':281800},
{'Symbol':'AC', 'Price':319.12, 'Date':'2017/07/07',
'Time':'9:36am', 'Change':-0.28, 'Volume':481800}]
with open('wstocks.csv', 'w') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader()# 写入头
f_csv.writerows(rows)# 一次性写入多行
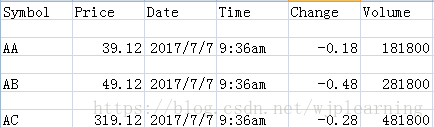
注:写文件有个缺陷就是结尾有换行符。只需要在打开文件的时候加上一个参数就OK了:with open('wstocks.csv', 'w', newline='') as f。

6.我们的读取代码
1. 很多时候我们根据实际需要大概这样读取CSV文件:
import re
with open('wstocks.csv', 'r') as f:
header = False # 是否打印headerTrue—打印
while True:
line = f.readline()
if header:
header = False
continue
if line:
line = re.sub('[\r\n]','',line)
lines = line.split(',')
print(lines)
else:
break

注:这样分割然后用索引对数据操作有时候会比较麻烦,比如某一个数据里面包含一个逗号,有的是被引号括起来的,这些需要自己去去除的。
- 当然我们也可以读取其他分隔符的文件:只需要改一行代码就OK:比如制表符分割的文件读取:
with open('wstocks.csv', ‘r’) as f:
f_csv = csv.reader(f, delimiter=’\t’)
- 还有一种情况需要注意的是,有时候表头里面可能含有Python里面的非法标志符,这时候就需要用正则表达式把非法标志符过滤掉。
例如:
数据:
处理:
import re
from collections import namedtuple
with open('geo.csv') as f:
f_csv = csv.reader(f)
headers = [re.sub('[^a-zA-Z_]', '_', h) for h in next(f_csv)]
Row = namedtuple('Row', headers)
print(headers)
for r in f_csv:
print(Row(*r))
- CSV模块不会尝试去解释数据或者将数据转换为出字符串之外的类型,这时候就需要我们手动操作了。
看代码1:
col_types = [str, float, str, str, float, int]
with open('stocks.csv') as f:
f_csv = csv.reader(f)
headers = next(f_csv)
for row in f_csv:
print(row)# 转换前
row = [convert(value) for convert, value in zip(col_types, row)]
print(row) # 转换后

看代码2:
print("Reading as dicts with type conversion")
field_types = [('Price', float),
('Change', float),
('Volume', int)]
with open('stocks.csv') as f:
for row in csv.DictReader(f):
print(row) # 转换前
row.update((key, conversion(row[key])) for key, conversion in field_types)
print(row) # 转换后

2读写JSON数据
1将数据结构转换为json
实例:
import json
data = {
'name':'ACME',
'shares':100,
'price':542.23}
json_str = json.dumps(data) # <class 'str'>
print(json_str)
2把json编码的字符串转换为对应的数据结构
data = json.loads(json_str) # <class 'dict'>
print(type(data), data)
3Json-Python相互转化对照表
| Python-----------àJson | Json -----------àJson | ||
| dict | object | object | dict |
| list, tuple | array | array | list |
| str, unicode | string | string | unicode |
| int, long, float | number | number (int) | int, long |
| True | true | number (real) | float |
| False | false | true | True |
| None | null | false | False |
看几个例子吧:

4Json读写Json文件
1.写文件
data = {
'name':'ACME',
'shares':100,
'price':542.23}
with open('./inputdata/data.json', 'w') as f:
json.dump(data, f)

2.读文件
with open('./inputdata/data.json', 'r') as f:
data = json.load(f)
print(data, type(data))
5通过读取json创建其他类型的对象
1.数据解码为有序字典保持数据的有序性。
from collections import OrderedDict
s = '{"name": "ACME", "shares": 100, "price": 542.23}'
data = json.loads(s, object_pairs_hook=OrderedDict) # 数据解码为有序字典
print(data)
2.将Json字典转换为Python对象。
class JSONobject(object):
def __init__(self, d):
self.__dict__ = d
s = '{"name": "ACME", "shares": 100, "price": 542.23}'
data = json.loads(s, object_hook=JSONobject)
print(data.name, data.shares, data.price)
注:类实例一般是无法序列化为Json对象,但是如果想序列化类实例,可以提供一个函数将类实例作为输入并返回一个可以被序列化处理的字典。
例如:
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def serialize_instance(obj):
d = {'__classname__':type(obj).__name__}
d.update(vars(obj))
return d
# 如果想取回一个实例,如下:
classes = {'Point':Point}
def unserialize_object(d):
clsname = d.pop('__classname__', None)
if clsname:
cls = classes[clsname]
obj = cls.__new__(cls)
for k, v in d.items():
setattr(obj, k, v)
return obj
else:
return d
P = Point(2, 3)
s = json.dumps(P, default=serialize_instance)
print(s)
a = json.loads(s, object_hook=unserialize_object)
print(a)
print(a.x)

3输出美化
data = {
'name':'ACME',
'shares':100,
'price':542.23}
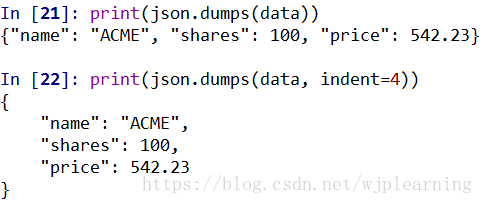
排序:

注:更详细的内容请参阅文档:https://docs.python.org/3/library/json.html














 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









